






1、MySQL文件说明
1.1 MySQL文件夹文件
linux服务器上MySQL安装好之后都有如下文件:

- auto.cnf:每一个MySQL实例都有一个唯一ID

- 蓝色文件夹:表示数据库,每个数据库对应一个目录
- hostname.log:机器名.log 通用日志文件,默认关闭
- /var/log/mysqld.log:错误日志文件配置在/etc/my.conf文件中 log-error=/var/log/mysqld.log
- ib_logfile0、ib_logfile1 :redolog 重做日志文件,参与数据存储
- ibdata1:数据文件,系统表空间存储在此文件中
1.2、主要日志文件
1)错误日志(errorlog)
默认是开启的,而且从5.5.7以后无法关闭错误日志,错误日志记录了运行过程中遇到的所有严重的错误信息,以及 MySQL每次启动和关闭的详细信息。
默认的错误日志名称:hostname.err。
错误日志所记录的信息是可以通过log-error和log-warnings来定义的,其中log-err是定义是否启用错误日志的功能和错误日志的存储位置,log-warnings是定义是否将警告信息也定义至错误日志中。
#可以直接定义为文件路径,也可以为ON|OFF
log_error=/var/log/mysqld.log
#只能使用1|0来定义开关启动,默认是启动的
log_warings=1 2)二进制日志(bin log)
默认是关闭的,需要通过以下配置进行开启。:
log-bin=mysql-bin 其中mysql-bin是binlog日志文件的basename,binlog日志文件的完整名称:mysql-bin-000001.log
binlog记录了数据库所有的ddl语句和dml语句,但不包括select语句内容,语句以事件的形式保存,描述了数据的变更顺序,binlog还包括了每个更新语句的执行时间信息。如果是DDL语句,则直接记录到binlog日志,而DML语句,必须通过事务提交才能记录到binlog日志中。
binlog主要用于实现mysql主从复制、数据备份、数据恢复。
3)通用查询日志(general query log)
默认情况下通用查询日志是关闭的。
由于通用查询日志会记录用户的所有操作,其中还包含增删查改等信息,在并发操作大的环境下会产生大量的信息从而导致不必要的磁盘IO,会影响mysql的性能的。如若不是为了调试数据库的目的建议不要开启查询日志。
mysql> show global variables like 'general_log'; 开启方式:
#启动开关
general_log={ON|OFF}
#日志文件变量,而general_log_file如果没有指定,默认名是host_name.log
general_log_file=/PATH/TO/file
#记录类型
log_output={TABLE|FILE|NONE} 4)慢查询日志(slow query log)
默认是关闭的。
需要通过以下设置进行开启:
#开启慢查询日志
slow_query_log=ON
#慢查询的阈值
long_query_time=10
#日志记录文件如果没有给出file_name值, 默认为主机名,后缀为-slow.log。如果给出了文件名, 但不是绝对路径名,文件则写入数据目录。
slow_query_log_file= file_name 记录执行时间超过long_query_time秒的所有查询,便于收集查询时间比较长的SQL语句
查询多少SQL超过了慢查询时间的阈值: SHOW GLOBAL STATUS LIKE '%Slow_queries%';
1.3、数据文件

MyIsam引擎创建的表:
tablename.frm 表结构定义文件
tablename.MYD 数据文件
tablename.MYI 索引文件
InnoDB 引擎创建的表:
tablename.frm 表结构定义文件
tablename.ibd 数据文件和索引文件
2、逻辑架构图

Connectors
- 连接器,指的是不同语言中与SQL的交互
Management Serveices & Utilities
- 系统管理和控制工具
Connection Pool: 连接池
- 管理用户连接,等待处理连接请求。
- 负责监听对 MySQL Server 的各种请求,接收连接请求,转发所有连接请求到线程管理模块。每一个连接上 MySQL Server 的客户端请求都会被分配(或创建)一个连接线程为其单独服务。
- 而连接线程的主要工作就是负责 MySQL Server 与客户端的通信,接受客户端的命令请求,传递Server 端的结果信息等。线程管理模块则负责管理维护这些连接线程。包括线程的创建,线程的cache 等。
SQL Interface: SQL接口
- 接受用户的SQL命令,并且返回用户需要查询的结果。比如select from就是调用SQL Interface
Parser: 解析器
- SQL命令传递到解析器的时候会被解析器验证和解析。
主要功能:
- 将SQL语句进行词法分析和语法分析,解析成语法树,然后按照不同的操作类型进行分类,然后做出针对性的转发到后续步骤,以后SQL语句的传递和处理就是基于这个结构的。
- 如果在分解过程中遇到错误,那么就说明这个sql语句是不合理的。
Optimizer: 查询优化器
- SQL语句在查询之前会使用查询优化器对查询进行优化。explain语句查看的SQL语句执行计划,就是由查询优化器生成的。
Cache和Buffer: 查询缓存
- 他的主要功能是将客户端提交给MySQL的 select请求的返回结果集 cache 到内存中,与该 query 的一个 hash 值 做一个对应。该 Query 所取数据的基表发生任何数据的变化之后, MySQL 会自动使该query 的Cache 失效。在读写比例非常高的应用系统中, Query Cache 对性能的提高是非常显著的。当然它对内存的消耗也是非常大的。
- 如果查询缓存有命中的查询结果,查询语句就可以直接去查询缓存中取数据。这个缓存机制是由一系列小缓存组成的。比如表缓存,记录缓存,key缓存,权限缓存等
Pluggable Storage Engines:存储引擎
- 与其他数据库例如Oracle 和SQL Server等数据库中只有一种存储引擎不同的是,MySQL有一个被称为“Pluggable Storage Engine Architecture”(可插拔的存储引擎架构)的特性,也就意味着MySQL数据库提供了多种存储引擎。
- 而且存储引擎是针对表的,用户可以根据不同的需求为数据表选择不同的存储引擎,用户也可以根据自己的需要编写自己的存储引擎。也就是说,同一数据库不同的表可以选择不同的存储引擎 creat table xxx()engine=InnoDB/Memory/MyISAM
简而言之,存储引擎就是如何存储数据、如何为存储的数据建立索引和如何更新、查询数据等技术的实现方法。
3、MySqlServer层对象
3.1、Sql语句执行流程
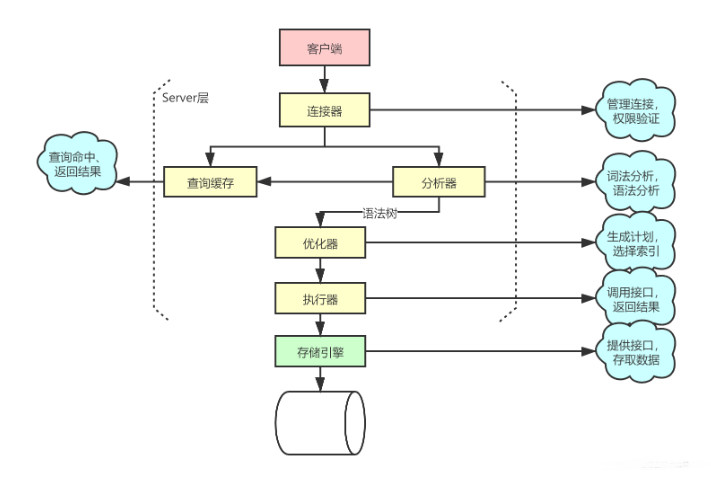
3.2、连接器
**第一步,你会先连接到这个数据库上,这时候接待你的就是连接器。连接器负责跟客户端建立连接、获取权限、维持和管理连接。**连接命令一般是这么写的:
mysql -h$ip -P$port -u$user -p输完命令之后,你就需要在交互对话里面输入密码。虽然密码也可以直接跟在 -p 后面写在命令行中,但这样可能会导致你的密码泄露。如果你连的是生产服务器,强烈建议你不要这么做。
连接命令中的 mysql 是客户端工具,用来跟服务端建立连接。在完成经典的 TCP 握手后,连接器就要开始认证你的身份,这个时候用的就是你输入的用户名和密码。
- 如果用户名或密码不对,你就会收到一个"Access denied for user"的错误,然后客户端程序结束执行。
- 如果用户名密码认证通过,连接器会到权限表里面查出你拥有的权限。之后,这个连接里面的权限判断逻辑,都将依赖于此时读到的权限。
这就意味着,一个用户成功建立连接后,即使你用管理员账号对这个用户的权限做了修改,也不会影响已经存在连接的权限。修改完成后,只有再新建的连接才会使用新的权限设置。
连接完成后,如果你没有后续的动作,这个连接就处于空闲状态,你可以在 show processlist 命令中看到它。文本中这个图是 show processlist 的结果,其中的 Command 列显示为“Sleep”的这一行,就表示现在系统里面有一个空闲连接。

客户端如果太长时间没动静,连接器就会自动将它断开。这个时间是由参数 wait_timeout 控制的,默认值是 8 小时。
如果在连接被断开之后,客户端再次发送请求的话,就会收到一个错误提醒: Lost connection to MySQL server during query。这时候如果你要继续,就需要重连,然后再执行请求了。
数据库里面,长连接是指连接成功后,如果客户端持续有请求,则一直使用同一个连接。短连接则是指每次执行完很少的几次查询就断开连接,下次查询再重新建立一个。
建立连接的过程通常是比较复杂的,所以我建议你在使用中要尽量减少建立连接的动作,也就是尽量使用长连接。
但是全部使用长连接后,你可能会发现,有些时候 MySQL 占用内存涨得特别快,这是因为 MySQL 在执行过程中临时使用的内存是管理在连接对象里面的。这些资源会在连接断开的时候才释放。所以如果长连接累积下来,可能导致内存占用太大,被系统强行杀掉(OOM),从现象看就是 MySQL 异常重启了。
怎么解决这个问题呢?你可以考虑以下两种方案。
- 定期断开长连接。使用一段时间,或者程序里面判断执行过一个占用内存的大查询后,断开连接,之后要查询再重连。
- 如果你用的是 MySQL 5.7 或更新版本,可以在每次执行一个比较大的操作后,通过执行mysql_reset_connection 来重新初始化连接资源。这个过程不需要重连和重新做权限验证,但是会将连接恢复到刚刚创建完时的状态。
3.3、查询缓存(MySql 8.0 已经舍弃缓存这个功能)
连接建立完成后,你就可以执行 select 语句了。执行逻辑就会来到第二步:查询缓存。
MySQL 拿到一个查询请求后,会先到查询缓存看看,之前是不是执行过这条语句。之前执行过的语句及其结果可能会以 key-value 对的形式,被直接缓存在内存中。key 是查询的语句hash之后的值,value 是查询的结果。如果你的查询能够直接在这个缓存中找到 key,那么这个 value 就会被直接返回给客户端。
如果语句不在查询缓存中,就会继续后面的执行阶段。执行完成后,执行结果会被存入查询缓存中。你可以看到,如果查询命中缓存,MySQL 不需要执行后面的复杂操作,就可以直接返回结果,这个效率会很高。
但是大多数情况下我会建议你不要使用查询缓存,为什么呢?因为查询缓存往往弊大于利。
查询缓存非常容易失效,若是对某个表有修改,则会清空有关这个表的所有查询缓存。对于常修改的表来说,缓存命中率会非常低。所以,只有系统配置表这种不经常修改的表才适合使用查询缓存。
查询缓存默认关闭
show variables like 'query_cache_type'; 
查询缓存命中次数
SHOW STATUS LIKE 'Qcache_hits'值为 0或OFF 会禁止使用缓存。
值为 1或ON 将启用缓存,但以 SELECT SQL_NO_CACHE 开头的语句除外。
值为 2或DEMAND 时,只缓存以 SELECT SQL_CACHE 开头的语句。
需要修改配 my.cnf 置文件,在文件中增加如下内容开启缓存:
query_cache_type=2 那么要如何清空查询缓存呢
- FLUSH QUERY CACHE; // 清理查询缓存内存碎片。
- RESET QUERY CACHE; // 从查询缓存中移出所有查询。
- FLUSH TABLES; //关闭所有打开的表,同时该操作将会清空查询缓存中的内容。
然而 MySQL 8.0 版本直接将查询缓存的整块功能删掉了
3.4、分析器
若是没有命中缓存,则继续进行执行语句,这个时候首先是对语句进行解析。
这个阶段就是 MySQL 的 Parser 解析器和 Preprocessor预处理模块的功能。
首先判断文本的语法是否正确,然后从文本中将要查询的表,列和各种查询 条件都提取出来,本质上是对一个SQL语句编译的过程,涉及词法解析、语法分析、语义分析等阶段。
解析器先会做“词法分析”。
就是把完整的SQL分割成字符串:
select customer_id,first_name,last_name from customer where customer_id=14; 分割成10个字符串:
select,customer_id,first_name,last_name,from,customer,where,customer_id, =,14 MySQL 从"select"这个关键字识别出来,这是一个查询语句,把字符串“customer”识别成“表名 customer”,把字符串“customer_id识别成“列 customer_id”。
然后解析器做“语法分析”。
这一步就是针对词法分析的结果,语法分析器进行语法检查,判断是否符合MySQL语法。
若是语法正确,则会根据MySQL定义的语法规则,生成一个解析树:
比如sql
select customer_id,first_name,last_name from customer where customer_id=14; 
预处理器
预处理器则会进一步检查解析树是否合法,如表名是否存在、列是否存在等、同时会检验用户是否有表的操作权限。
3.5、优化器
在开始执行SQL之前,还要先经过优化器的处理。
查询优化器的作用就是根据解析树生成不同的执行计划,然后选择一种最优的执行计划,MySQL 里面使用的是基于成本模型的优化器,哪种执行计划执行时成本最小就用哪种。而且它是io_cost和cpu_cost的开销总和,它通常也是我们评价一个查询的执行效率的一个常用指标。
#查看上次查询成本开销 show status like 'Last_query_cost'; 优化器的优化处理:
- 当有多个索引可用的时候,决定使用哪个索引。
- 在一个语句有多表关联(join)的时候,决定各个表的连接顺序,以哪个表为基准表。
3.6、执行器
MySQL 通过分析器知道了你要做什么,通过优化器知道了该怎么做,得到了一个查询计划。于是就进入了执行器阶段,开始执行语句。
(1)开始执行的时候,要先判断一下你对这个表customer有没有执行查询的权限,如果没有,就会返回没有权限的错误。 (在工程实现上,如果命中查询缓存,会在查询缓存返回结果的时候,做权限验证。
(2)如果有权限,就使用指定的存储引擎打开表开始查询。执行器会根据表的引擎定义,去使用这个引擎提供的查询接口,提取数据。
比如我们这个例子中的表 customer中,customer_id 字段是主键,那么执行器的执行流程是这样的:
- 调用 InnoDB 引擎接口,从主键索引中检索customer_id=14的记录。
- 主键索引等值查询只会查询出一条记录,直接将该记录返回客户端。
至此,这个语句就执行完成了。
假设customer_id 字段不是索引,这时查询只能全表扫描。那么执行器的执行流程是这样的:
- 调用 InnoDB 引擎接口取这个表的第一行,判断customer_id 值是不是 14,如果不是则跳过,如果是则将这行缓存在结果集中;
- 调用引擎接口取“下一行”,重复相同的判断逻辑,直到取到这个表的最后一行。
- 执行器将上述遍历过程中所有满足条件的行组成的结果集返回给客户端。
至此,这个语句就执行完成了
作者:奔跑的毛球
链接:
https://juejin.cn/post/6914301427355484174
来源:掘金














 316
316











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









