






 本文介绍了一种结合结构方法和图神经网络的新型方法,用于高维时间序列数据的异常检测。方法通过SensorEmbedding获取传感器特性和图结构学习确定传感器间关系,利用注意力机制提高预测的可解释性。实验结果显示,这种方法在异常检测性能上优于基线,且具有良好的可解释性和异常定位能力。
本文介绍了一种结合结构方法和图神经网络的新型方法,用于高维时间序列数据的异常检测。方法通过SensorEmbedding获取传感器特性和图结构学习确定传感器间关系,利用注意力机制提高预测的可解释性。实验结果显示,这种方法在异常检测性能上优于基线,且具有良好的可解释性和异常定位能力。
1、问题描述
对于高维时间序列数据,这些数据之间还存在某种联系(例如,在水处理厂中,可以有许多传感器测量水位、流速、水质、阀门状态等,在它们的许多部件中的每一个部件中。来自这些传感器的数据可能以不复杂、非线性的方式相关。打开水阀会使得水位升高,流速增加),以前的方法不能获取数据之间的联系。本篇论文将学习结构方法和图神经网络相结合,并且还使用注意力权重来提供检测到的异常的可解释性。
要将图神经网络应用到时间序列异常检测上需要克服2个困难:
1.1、不同的传感器有着不一样的行为(典型的GNN使用相同的模型参数对每个节点的行为进行建模)
1.2、图的边也就是传感器之间的关系是未知的
2、这篇论文的核心思想:
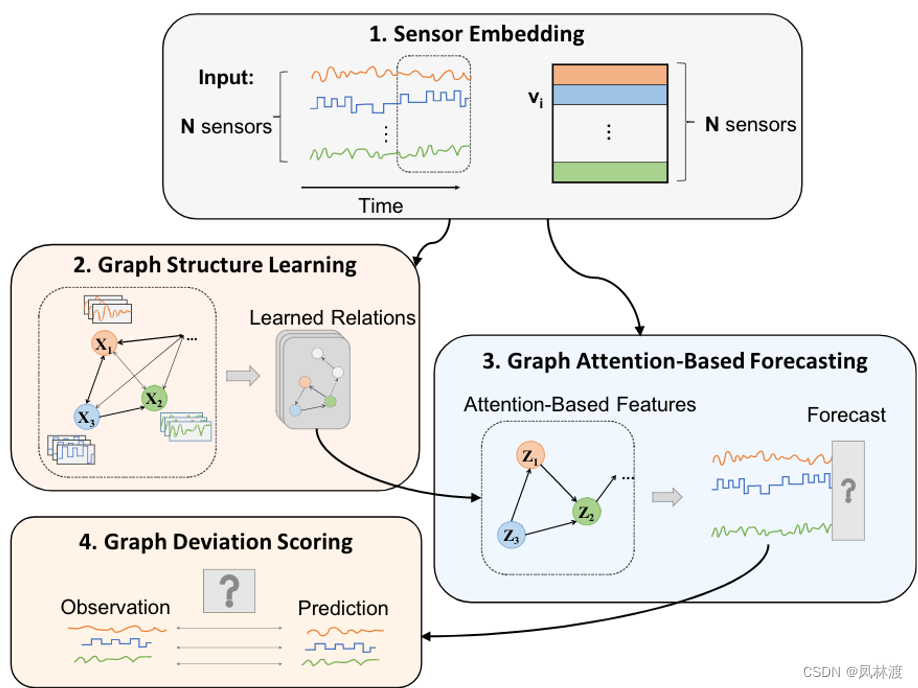
2.1、Sensor Embedding传感器嵌入
使用嵌入向量来获得每个传感器的独特特性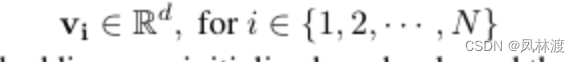
嵌入向量的相似程度代表着传感器之间的相似程度,这些嵌入向量是随机初始化的,随着模型的其他部分长期训练,这些嵌入向量的相似性就会代表着传感器之间的相似性。
作用:图结构的学习来确定哪些传感器之间相互关联;降低不同类型传感器的异质效应的方式对邻居进行注意力
2.2、Graph Structure Learning图结构学习
使用的是有向图,点代表传感器,边代表传感器之间的依赖关系(并不是对称的),矩阵A表示邻接矩阵。
首先计算传感器i和其他传感器之间的余弦相似度,再将余弦相似度前k个的邻接矩阵的值修改为1,其中,1{·}为示性函数,即1{ 值为真的表达式} = 1,1{ 值为假的表达式} = 0 。如下图
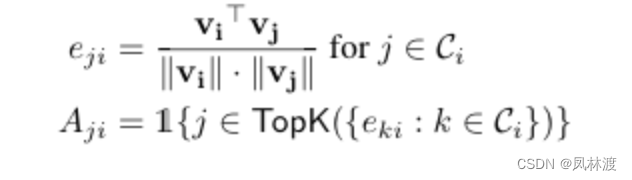
这个灵活的学习框架适用于没有先验知识的情况或者是一些已知的相互作用小的先验知识。
如果没有先验知识的话,,传感器i 依赖于除本身之外的所有的传感器。
2.3、Graph Attention-based Forecasting基于图注意力的预测
目的:基于图中相邻传感器的注意力函数来预测传感器未来的行为
为了对异常现象提供有用的解释,让模型告诉我们:1、哪些传感器偏离了正常行为?2、他们在哪些方面偏离了正常行为?
为了实现这个,基于预测的方法,在t时刻,定义一个大小为w的滑动窗口大小的输入数据X,预测的输出是当前时刻的传感器的数据。用就可以很容易的识别出与预期行为有很大偏差的传感器。
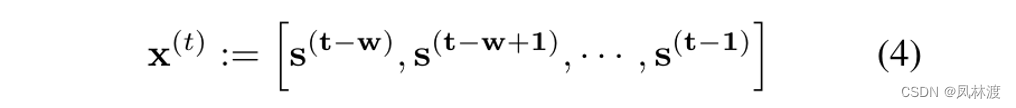
表示t时刻传感器的前w个历史数据,作为输入以此来预测表示t时刻传感器的前w个历史数据,作为输入以此来预测t时刻的传感器数据
2.3.1、特征提取(注意力的计算):
GNN的注意力的计算:
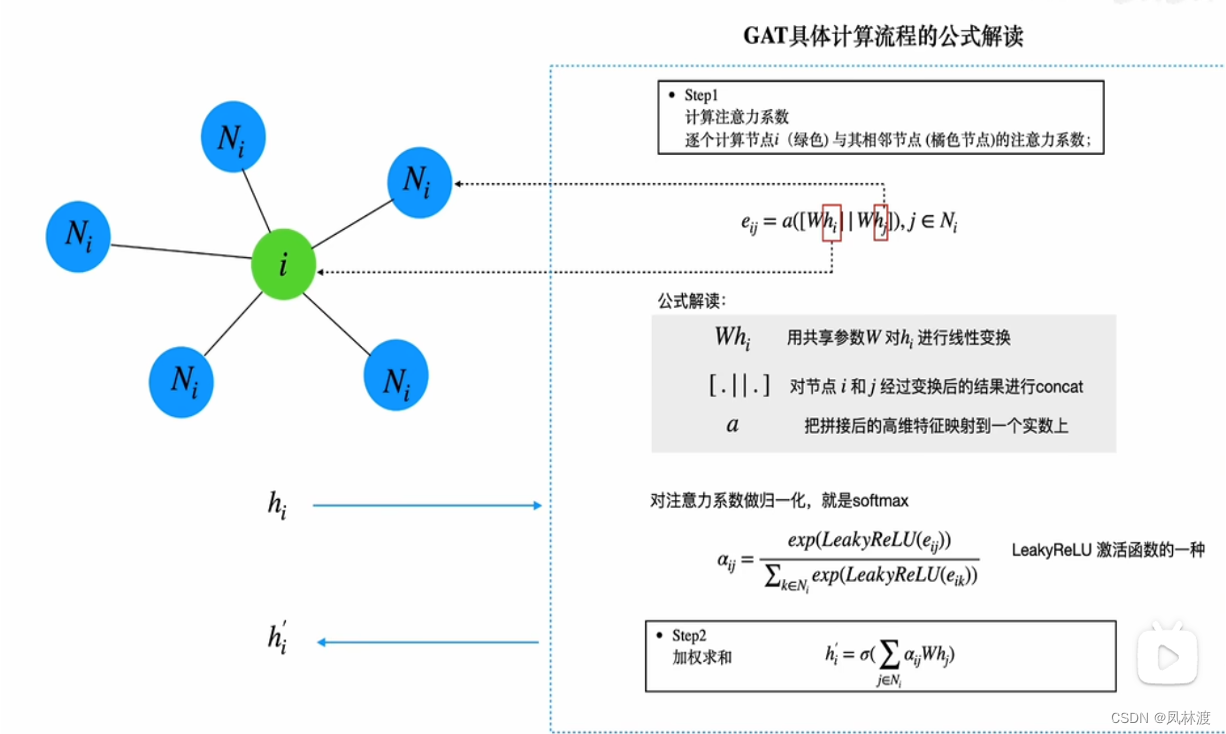
第一步是对节点i和他的邻居节点j线性变换后连接起来,乘上矩阵a把拼接后的矩阵映射到一个实数上面。
第二步是激活函数
第三步是softmax归一化操作
第四步是相乘,对所有的邻居节点的值进行求和。
以下是GDN的注意力的计算:
为了获取传感器之间的关系引入图注意力的特征提取器,目的是将节点信息和它的节点融合。
下面是计算t时刻节点i的注意力的计算:
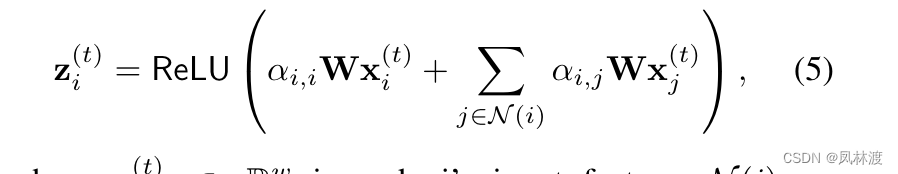
N(i)指的是从邻接矩阵里面获得的i的邻居信息,j是i的邻居。W是一个对每个节点共享线性变换的可训练权重矩阵,是注意力系数,公式5的注意力系数是通过公式8获得的
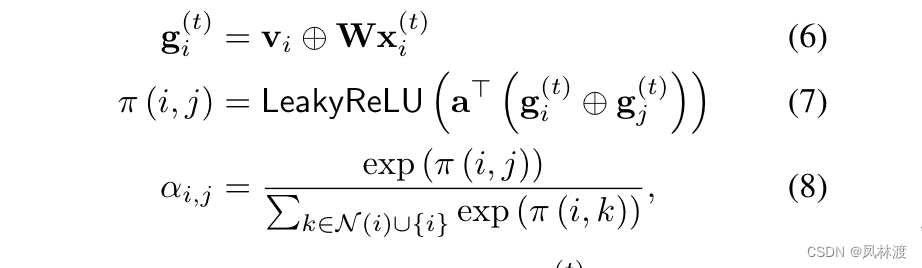
这里的➕号表示串联,将嵌入向量和转换特征矩阵连接起来,是一个注意力机制的学习系数向量。用LeakyReLU非线形激活函数来计算注意力系数,在使用softmax对注意力系数做归一化。
2.3.2、输出层: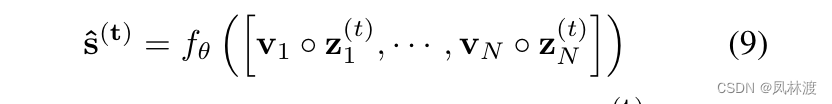
将N个节点的聚合表示和嵌入向量相乘,作为堆叠全通层的输入,用来预测t时刻传感器的值,即公式9得到传感器的预测值。
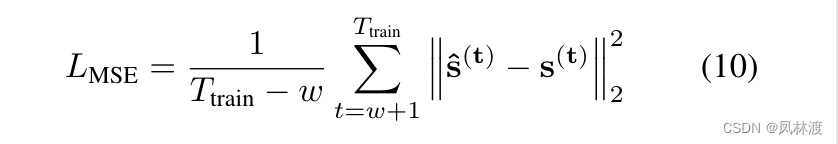
用预测值和观测值之间的均方误差作为最小化的损失函数
2.4、Graph Deviation Scoring图的偏差评分
识别图表中学习到的传感器关系的偏差
为了检测和排除异常的关系,计算每个传感器的个体异常分数,如此用户可以确定哪些传感器是异常的,如下:
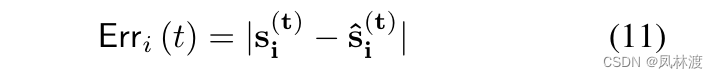
不同传感器不同偏差所代表的偏差程度也是不一样的,为了使传感器的偏差程度不会偏差太大,进行近似归一化处理,如下:
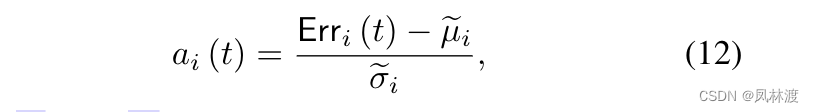
μi和σ分别是Erri(t)值在时间刻度上的中值和四分位间距,为什么这么选择,因为更具有鲁棒性(鲁棒性就是健壮性)。
然后为了计算t时刻的总体异常,用max函数对传感器进行聚合,如下: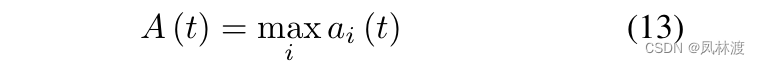
为了防止数值的突然变化,使用简单移动平均值(SMA)来生成平滑的分数As(t),如果这个分数超过了阈值,则在t时刻就被标记为异常;将阈值设置为验证数据上的最大值As(t)
为了检测异常,我们使用评估数据集上的最大异常分数来设置阈值。在测试时,任何异常分数超过阈值都将被重新归类为异常
3、实验
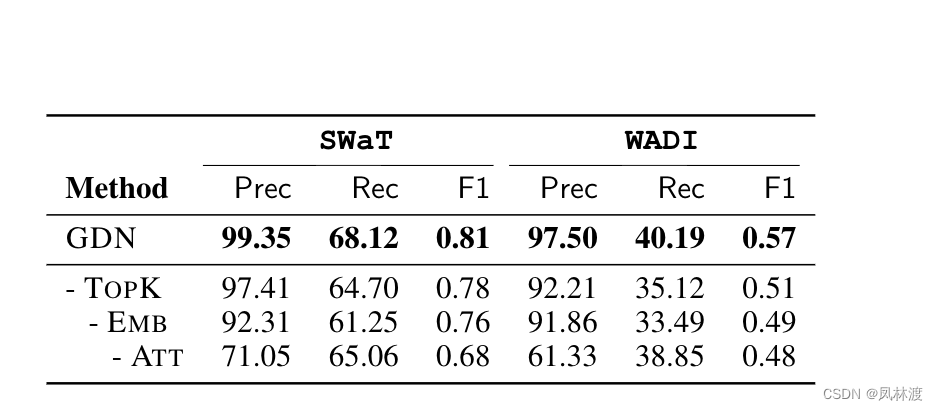
3.1、(对比实验):基于地面实况标记的异常,我们的方法在多变量时间序列中的异常检测准确性方面是否优于基线方法?
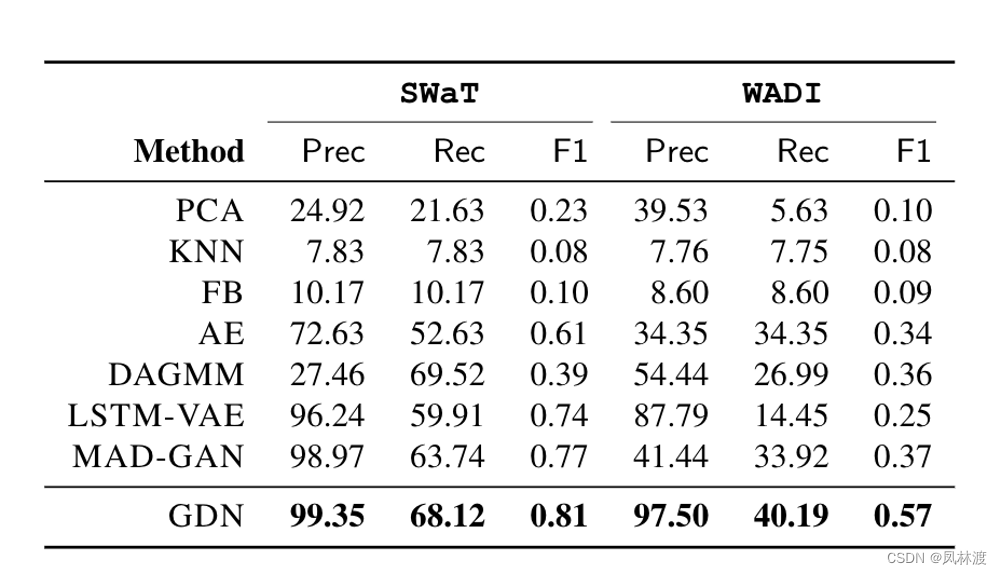
用测试数据集的精度(Prec)、召回率(Rec)和F1分数(F1)及其基本真值来评估GDN和基线模型的性能:显示了我们的GDN方法和基线在Wa和WADI数据集上的异常检测精度,包括精度、召回率和F1分数。结果表明,GDN在两个数据集中都优于基线。
上图所示,WADI比SWaTand更不平衡,并且具有比SWaTas更高的维度。因此,我们的方法即使在不平衡和高维的攻击场景中也是有效的
3.2、(消融实验):该方法的各个组成部分对其性能有何贡献?
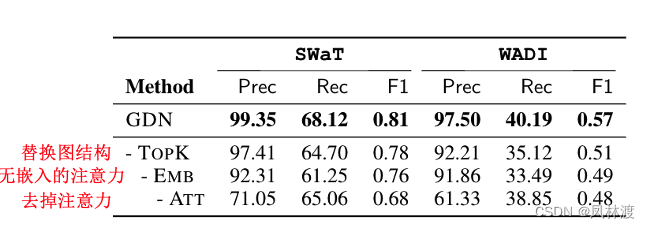
静态完全图代替由向图;没有传感器嵌入的注意力机制;禁用了注意力机制,分配给所有邻居的相等权重进行聚合。
由上图可见,去除注意力机制(第三个)对模型性能的影响最大。由于传感器具有非常不同的行为,平等对待所有邻居会引入噪声并误导模型。这验证了图注意力机制的重要性
3.3、RQ3(模型的可解释性):我们如何根据模型的嵌入和学习图结构来理解模型?
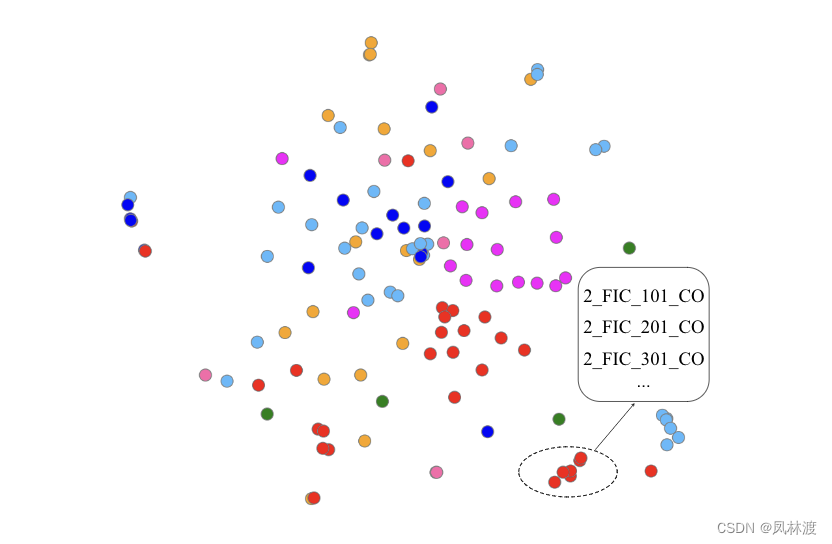
如上图的数据集类似的聚集在一块,可以可视化传感器嵌入向量。该图中嵌入空间中的相似性表示的是传感器行为之间的相似性。
3.4、(定位异常):我们的方法能否定位异常并帮助用户识别受影响的传感器,以及了解异常如何偏离预期行为?
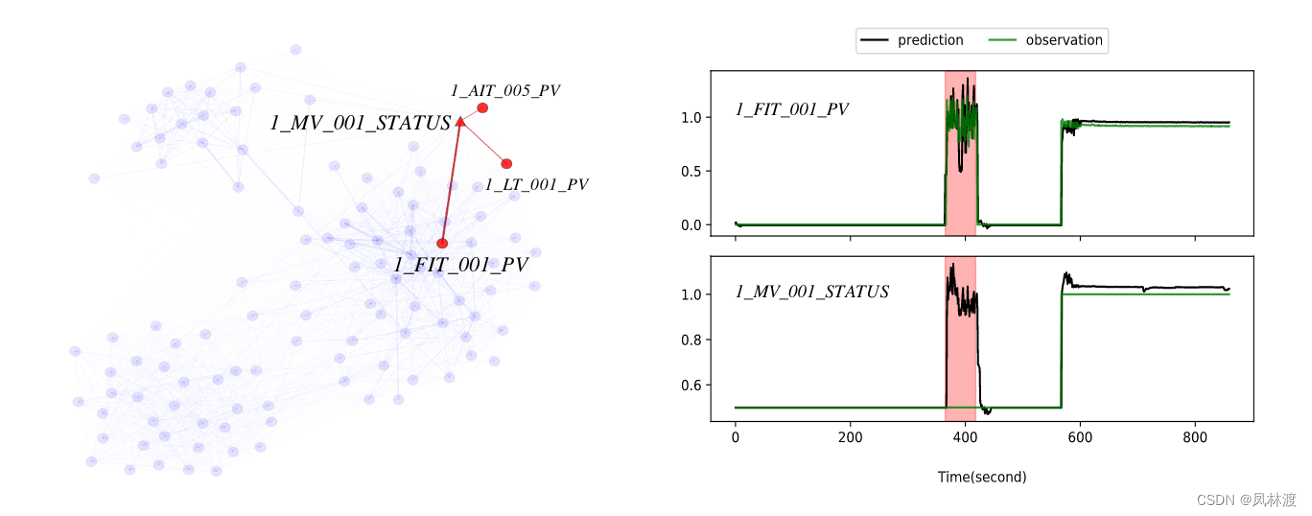
在WADI数据集的,该异常源于流量传感器1FIT001PV受到错误读数的攻击,也就是图中最下面的这个传感器的读写功能发生了异常,使得观测值在短时间内发生暴涨,由于“1_FIT_001_PV”这个sensor与“1_MV_001_STATUS”具有非常强的关联,理论上“1_MV_001_STATUS”的值也应该对应骤增,并且模型也学习到了这一点,对应prediction值确实是骤增的他的上面的邻居节点被标记为异常。实验证明,大偏差的传感器可能是受攻击(即异常)的传感器或者是受攻击(异常)传感器密切相关。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









