






@文章目录
零、本讲学习目标
1.了解Spark发展史
2.了解Spark的特点
3.了解Spark存储层次
4.了解Spark生态圈
5.了解Spark应用场景
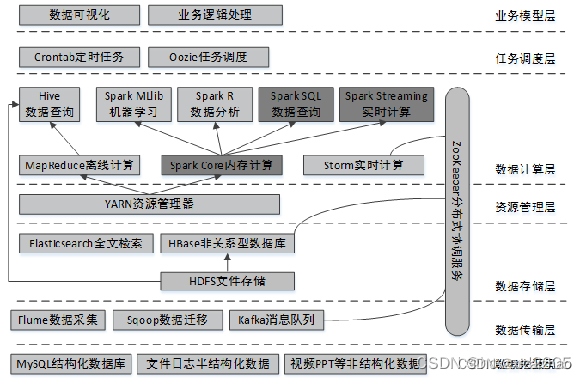
一、大数据开发总体架构
二、Spark简介
- Apache Spark™ is a multi-language engine for executing data engineering, data science, and machine learning on single-node machines or clusters.
- Apache Spark是一个快速通用的集群计算系统,是一种与Hadoop相似的开源集群计算环境,但是Spark在某些工作负载方面表现得更加优越。它提供了Java、Scala、Python和R的高级API,以及一个支持通用的执行图计算的优化引擎。它还支持一组丰富的高级工具,包括使用SQL进行结构化数据处理的Spark SQL、用于机器学习的MLlib、用于图处理的GraphX,以及用于实时流处理的Spark Streaming。
- Spark作为下一代大数据处理引擎,现已成为当今大数据领域非常活跃、高效的大数据计算平台,很多互联网公司都使用Spark来实现公司的核心业务,例如阿里的云计算平台、京东的推荐系统等,只要和海量数据相关的领域,都有Spark的身影。Spark提供了Java、Scala、Python和R的高级API,支持一组丰富的高级工具,包括使用SQL进行结构化数据处理的SparkSQL,用于机器学习的MLlib,用于图处理的GraphX,以及用于实时流处理的Spark Streaming。这些高级工具可以在同一个应用程序中无缝地组合,大大提高了开发效率,降低了开发难度。
三、功Spark发展史
-
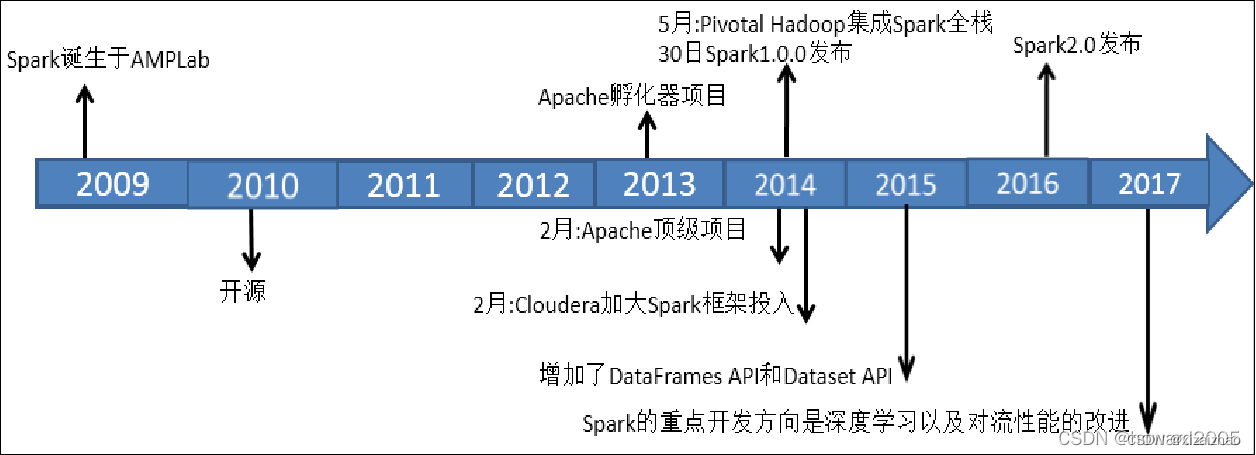
对于一个具有相当技术门槛与复杂度的平台,Spark从诞生到正式版本的成熟,经历的时间如此之短,让人感到惊诧。2009年,Spark诞生于伯克利大学AMPLab,最开初属于伯克利大学的研究性项目。它于2010年正式开源,并于2013年成为了Aparch基金项目,并于2014年成为Aparch基金的顶级项目,整个过程不到五年时间。
-
Spark目前最新版本是2022年1月26日发布的Spark3.2.1
四、Spark特点
- Spark官网上给出Spark的特点
-
(一)快速
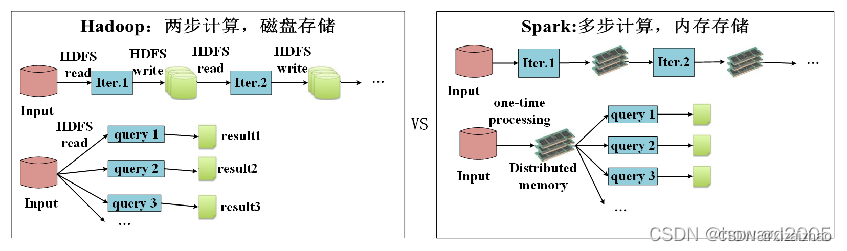
- 与MapReduce相比,Spark可以支持包括Map和Reduce在内的更多操作,这些操作相互连接形成一个有向无环图(Directed Acyclic Graph,简称DAG),各个操作的中间数据则会被保存在内存中。因此处理速度比MapReduce更加快。Spark通过使用先进的DAG调度器、查询优化器和物理执行引擎,从而能够高性能的实现批处理和流数据处理。

(二)易用
-Spark支持使用Scala、Python、Java及R语言快速编写应用。同时Spark提供超过80个高级运算符,使得编写并行应用程序变得容易并且可以在Scala、Python或R的交互模式下使用Spark。

(三)通用
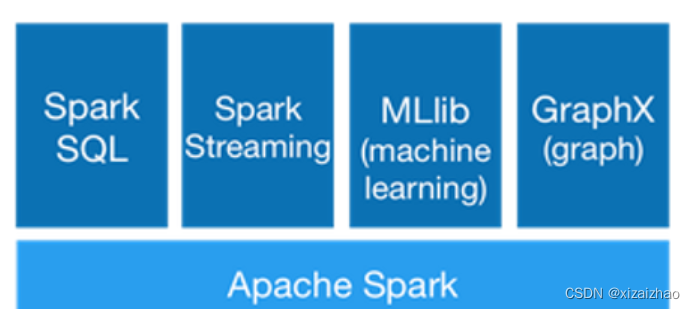
- Spark可以与SQL、Streaming及复杂的分析良好结合。Spark还有一系列的高级工具,包括Spark SQL、MLlib(机器学习库)、GraphX(图计算)和Spark Streaming,并且支持在一个应用中同时使用这些组件。
(四)随处运行
- 用户可以使用Spark的独立集群模式运行Spark,也可以在EC2(亚马逊弹性计算云)、Hadoop YARN或者Apache
Mesos上运行Spark。并且可以从HDFS、Cassandra、HBase、Hive、Tachyon和任何分布式文件系统读取数据。

(五)代码简洁
- 参看【采用多种方式实现词频统计】
1、采用MR实现词频统计
- 编写WordCountMapper
package net.zx.wc;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**
* Created by howard on 2018/2/6.
*/
public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
int count = 0;
for (IntWritable value : values) {
count = count + value.get();
}
context.write(key, new IntWritable(count));
}
}
- 编写WordCountReducer
package net.zx.wc;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**
* Created by howard on 2018/2/6.
*/
public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
int count = 0;
for (IntWritable value : values) {
count = count + value.get();
}
context.write(key, new IntWritable(count));
}
}
- 编写WordCountDriver
package net.zx.wc;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.net.URI;
/**
* Created by howard on 2018/2/6.
*/
public class WordCountDriver {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(WordCountDriver.class);
job.setMapperClass(WordCountMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setReducerClass(WordCountReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
String uri = "hdfs://hadoop:9000";
Path inputPath = new Path(uri + "/word");
Path outputPath = new Path(uri + "/word/result");
FileSystem fs = FileSystem.get(new URI(uri), conf);
fs.delete(outputPath, true);
FileInputFormat.addInputPath(job, inputPath);
FileOutputFormat.setOutputPath(job, outputPath);
job.waitForCompletion(true);
System.out.println("统计结果:");
FileStatus[] fileStatuses = fs.listStatus(outputPath);
for (int i = 1; i < fileStatuses.length; i++) {
System.out.println(fileStatuses[i].getPath());
FSDataInputStream in = fs.open(fileStatuses[i].getPath());
IOUtils.copyBytes(in, System.out, 4096, false);
}
}
}
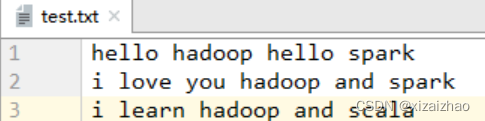
- 运行程序WordCountDriver,查看结果
2、采用Spark实现词频统计
- 编写编写WordCount
package net.zx.spark.wc
import org.apache.spark.{SparkConf, SparkContext}
/**
* Created by howard on 2018/2/6.
*/
object WordCount {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local").setAppName("wordcount")
val sc = new SparkContext(conf)
val rdd = sc.textFile("test.txt")
.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _)
rdd.foreach(println)
rdd.saveAsTextFile("result")
}
}
-
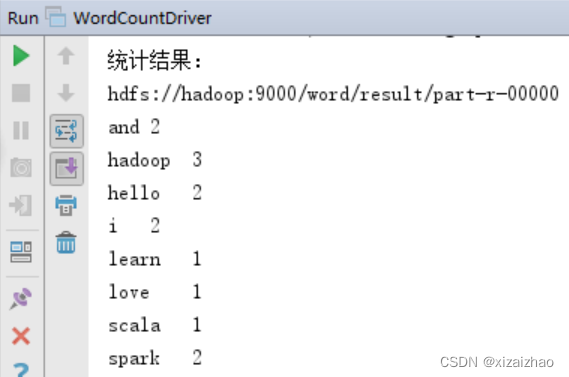
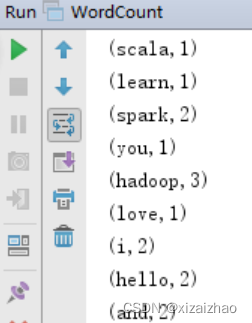
启动WordCount,查看结果
-
大家可以看出,完成同样的词频统计任务,Spark代码比MapReduce代码简洁很多。
五、Spark主要组件
-
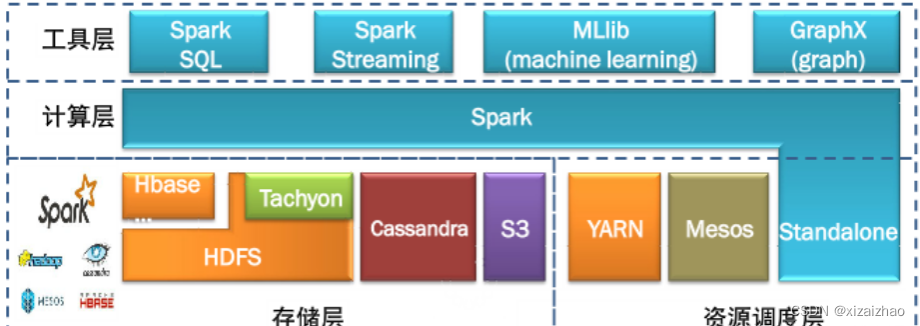
Spark是由多个组件构成的软件栈,Spark 的核心(Spark Core)是一个对由很多计算任务组成的、运行在多个工作机器或者一个计算集群上的应用进行调度、分发以及监控的计算引擎。
-
在Spark Core的基础上,Spark提供了一系列面向不同应用需求的组件,例如Spark SQL结构化处理和MLlib机器学习等。这些组件关系密切并且可以相互调用,这样可以方便地在同一应用程序中组合使用。
-
Spark自带一个简易的资源调度器,称为独立调度器(Standalone)。若集群中没有任何资源管理器,则可以使用自带的独立调度器。当然,Spark也支持在其他的集群管理器上运行,包括Hadoop YARN、Apache Mesos等。
-
Spark本身并没有提供分布式文件系统,因此Spark的分析大多依赖于HDFS,也可以从HBase和Amazon S3等持久层读取数据。
(一)Spark Core -
Spark Core是Spark的核心模块,主要包含两部分功能:一是负责任务调度、内存管理、错误恢复、与存储系统交互等;二是其包含对弹性分布式数据集(Resilient Distributed Dataset,RDD)的API定义。RDD表示分布在多个计算节点上可以并行操作的元素集合,是Spark主要的编程抽象。SparkCore提供了创建和操作这些集合的多个API。
(二)Spark SQL -
Spark Core是Spark的核心模块,主要包含两部分功能:一是负责任务调度、内存管理、错误恢复、与存储系统交互等;二是其包含对弹性分布式数据集(Resilient Distributed Dataset,RDD)的API定义。RDD表示分布在多个计算节点上可以并行操作的元素集合,是Spark主要的编程抽象。SparkCore提供了创建和操作这些集合的多个API。
-
Spark SQL还支持开发者将SQL语句融入Spark应用程序开发过程中,使用户可以在单个应用中同时进行SQL查询和复杂的数据分析。

(三)Spark Streaming
-
Spark Streaming是Spark提供的对实时数据进行流式计算的组件(比如生产环境中的网页服务器日志,以及网络服务中用户提交的状态更新组成的消息队列,都是数据流),它是将流式的计算分解成一系列短小的批处理作业,支持对实时数据流进行可伸缩、高吞吐量、容错的流处理。数据可以从Kafka、Flume、Kinesis和TCP套接字等许多来源获取,可以对数据使用map、reduce、join和window等高级函数表示的复杂算法进行处理。最后,可以将处理后的数据发送到文件系统、数据库和实时仪表盘。事实上,也可以将Spark的机器学习和图形处理算法应用于数据流。
-
Spark Streaming提供了用来操作数据流的API,并且与Spark Core中的RDD API高度对应,可以帮助开发人员高效地处理数据流中的数据。从底层设计来看,Spark Streaming支持与Spark Core同级别的容错性、吞吐量以及可伸缩性。
-
Spark Streaming通过将流数据按指定时间片累积为RDD,然后将每个RDD进行批处理,进而实现大规模的流数据处理。

-
Spark Streaming接收Kafka、Flume、HDFS等各种来源的实时输入数据,进行处理后,处理结构保存在HDFS、DataBase等各种地方。
-
Find words with higher frequency than historic data

(三)MLlib
- MLlib fits into Spark’s APIs and interoperates with NumPy in Python (as of Spark 0.9) and R libraries (as of Spark 1.5). You can use any Hadoop data source (e.g. HDFS, HBase, or local files), making it easy to plug into Hadoop workflows.
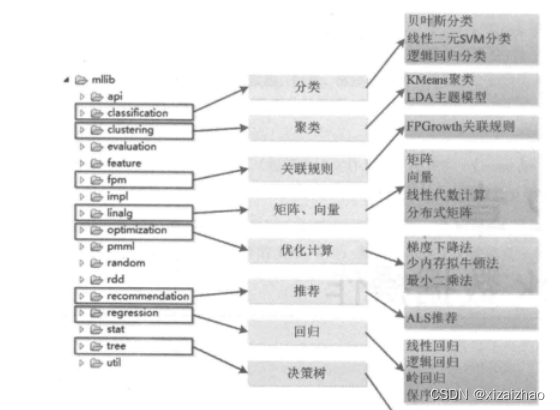
- MLlib是Spark的机器学习(Machine Learning,ML)库。它的目标是使机器学习具有可扩展性和易用性。其中提供了分类、回归、聚类、协同过滤等常用机器学习算法,以及一些更加底层的机器学习原语。
(四)GraphX
- Seamlessly work with both graphs and collections. GraphX unifies ETL, exploratory analysis, and iterative graph computation within a single system. You can view the same data as both graphs and collections, transform and join graphs with RDDs efficiently, and write custom iterative graph algorithms using the Pregel API.
- GraphX是Spark中图形和图形并行计算的一个新组件,可以用其创建一个顶点和边都包含任意属性的有向多重图。此外,GraphX还包含越来越多的图算法和构建器,以简化图形分析任务。
六、Spark应用场景
(一)腾讯
-广点通是最早使用Spark的应用之一。腾讯大数据精准推荐借助Spark快速迭代的优势,围绕“数据+算法+系统”这套技术方案,实现了在“数据实时采集、算法实时训练、系统实时预测”的全流程实时并行高维算法,最终成功应用于广点通pCTR (Predict Click-Through Rate) 投放系统上,支持每天上百亿的请求量。
(二)Yahoo
-Yahoo将Spark用在Audience Expansion中。Audience Expansion是广告中寻找目标用户的一种方法,首先广告者提供一些观看了广告并且购买产品的样本客户,据此进行学习,寻找更多可能转化的用户,对他们定向广告。Yahoo采用的算法是Logistic Regression。同时由于某些SQL负载需要更高的服务质量,又加入了专门跑Shark的大内存集群,用于取代商业BI/OLAP工具,承担报表/仪表盘和交互式/即席查询,同时与桌面BI工具对接。
(三)淘宝
-
淘宝技术团队使用了Spark来解决多次迭代的机器学习算法、高计算复杂度的算法等,将Spark运用于淘宝的推荐相关算法上,同时还利用GraphX解决了许多生产问题,包括以下计算场景:基于度分布的中枢节点发现、基于最大连通图的社区发现、基于三角形计数的关系衡量、基于随机游走的用户属性传播等。
(四)优酷土豆 -
目前Spark已经广泛使用在优酷土豆的视频推荐,广告业务等方面,相比Hadoop,Spark交互查询响应快,性能比Hadoop提高若干倍。一方面,使用Spark模拟广告投放的计算效率高、延迟小(同Hadoop比延迟至少降低一个数量级)。另一方面,优酷土豆的视频推荐往往涉及机器学习及图计算,而使用Spark解决机器学习、图计算等迭代计算能够大大减少网络传输、数据落地等的次数,极大地提高了计算性能。














 4802
4802











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









