







目录
2. 编辑文件test1.txt,放入本地文件夹 /opt/user/myfile
3. 使用moveFromLocal命令将本地文件test1.txt复制到HDFS文件系统的/temp/myfile/txt文件夹下。
4. 查看文件内容,查看HDFS文件系统上test1.txt的文件内容,仅显示文件的前两行。
5. 修改HDFS文件系统上test1.txt的权限,将其修改为用户可读可写,本组用户可读可写,其他用户只可读。
6. 将HDFS文件系统上test1.txt文件拷贝至HDFS文件系统的根目录下
7. 将根目录下的test1.txt移动至“/user/账户名” 下
8. 将“/user/账户名”下的test1.txt文件从HDFS文件系统拷贝至本地文件系统的“/home/账户名/Desktop”文件夹下。
10. 将sogou_500w_utf数据上传至HDFS文件系统,并在HDFS系统上查看文件内容的后10行。
二、在虚拟机安装eclipse,并完成HDFS API示例程序的编辑运行。
1. 使用SSH SHELL CLIENT将eclipse安装包上传至虚拟机hadoop01,如下图所示。
2. 在CentOS中安装eclipse,安装包为压缩文件直接输入tar命令解压缩即可完成安装。
4.启动eclipse,完成示例程序的编辑和运行,并检查运行结果。
4.1 在eclipse新建Java Project,输入项目名,完成项目创建。
4.3 添加依赖库,将hadoop安装文件夹下的以下子目录文件夹中的jar包加进来
5. 在项目内新建类,类名自定义,并输入以下参考代码(注意修改类名),以下代码的功能是完成从本地文件系统上传一个文件到HDFS文件系统。
6. 运行上述程序,检验文件是否正确上传。通过在本地目录和HDFS文件系统查看检验。
一、按照下述要求写出相应的文件操作命令,执行并观察结果
启动HDFS文件系统,并按要求完成以下操作。
1. 新建目录
1.1 在本地文件系统按要求创建如下的文件夹
sudo mkdir -p user/myfile
ls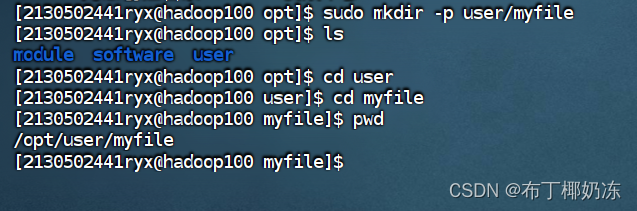
1.2 在HDFS文件系统按要求创建如下的文件夹
hdfs dfs -mkdir -p /temp/myfile/txt
hdfs dfs -ls /
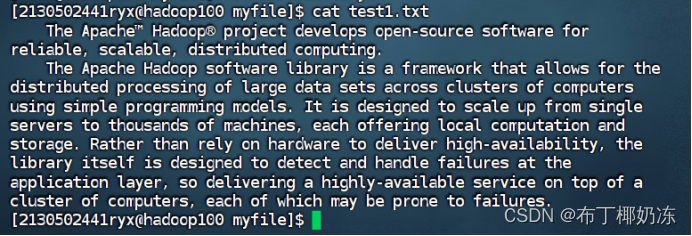
2. 编辑文件test1.txt,放入本地文件夹 /opt/user/myfile
文件内容如下:
The Apache™ Hadoop® project develops open-source software for reliable, scalable, distributed computing.
The Apache Hadoop software library is a framework that allows for the distributed processing of large data sets across clusters of computers using simple programming models. It is designed to scale up from single servers to thousands of machines, each offering local computation and storage. Rather than rely on hardware to deliver high-availability, the library itself is designed to detect and handle failures at the application layer, so delivering a highly-available service on top of a cluster of computers, each of which may be prone to failures.

3. 使用moveFromLocal命令将本地文件test1.txt复制到HDFS文件系统的/temp/myfile/txt文件夹下。
hdfs dfs -moveFromLocal /opt/user/myfile/test1.txt /temp/myfile/txt
4. 查看文件内容,查看HDFS文件系统上test1.txt的文件内容,仅显示文件的前两行。
hdfs dfs -cat /temp/myfile/txt/test1.txt | head -2
5. 修改HDFS文件系统上test1.txt的权限,将其修改为用户可读可写,本组用户可读可写,其他用户只可读。
hadoop fs -chmod 764 /temp/myfile/txt/test1.txt
6. 将HDFS文件系统上test1.txt文件拷贝至HDFS文件系统的根目录下
hdfs dfs -cp /temp/myfile/txt/test1.txt /
hdfs dfs -ls /
7. 将根目录下的test1.txt移动至“/user/账户名” 下
hdfs dfs -mv /test1.txt /user/2130502441ryx/
8. 将“/user/账户名”下的test1.txt文件从HDFS文件系统拷贝至本地文件系统的“/home/账户名/Desktop”文件夹下。
hdfs dfs -get /user/2130502441ryx/test1.txt /home/2130502441ryx/Desktop/
9. 将HDFS文件系统上的/temp文件夹删除。
hdfs dfs -rm -r temp
hdfs dfs -ls / 
10. 将sogou_500w_utf数据上传至HDFS文件系统,并在HDFS系统上查看文件内容的后10行。
hdfs dfs -put /home/2130502441ryx/sogou/sogou.500w.utf8 /
hdfs dfs -tail /sogou.500w.utf8
二、在虚拟机安装eclipse,并完成HDFS API示例程序的编辑运行。
1. 使用SSH SHELL CLIENT将eclipse安装包上传至虚拟机hadoop01,如下图所示。
在我上传的资源中,文件名为eclipse-standard-luna-SR2-linux-gtk-x86_64.tar.gz。

2. 在CentOS中安装eclipse,安装包为压缩文件直接输入tar命令解压缩即可完成安装。
tar -zxvf eclipse-standard-luna-SR2-linu.gz![]()
3. 完成安装以后将安装目录重命名为eclipse。

4.启动eclipse,完成示例程序的编辑和运行,并检查运行结果。
进入eclipse安装目录,运行eclipse可执行文件,启动eclipse,命令如下所示。
./eclipse
4.1 在eclipse新建Java Project,输入项目名,完成项目创建。
4.2 在项目中新建一个package,包名请自定义。
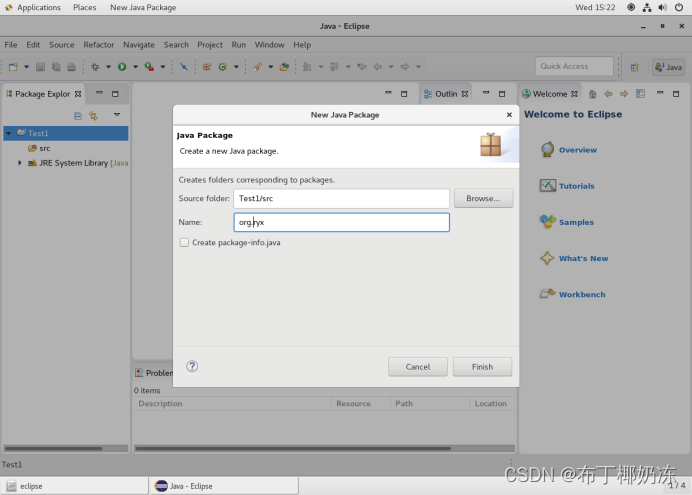
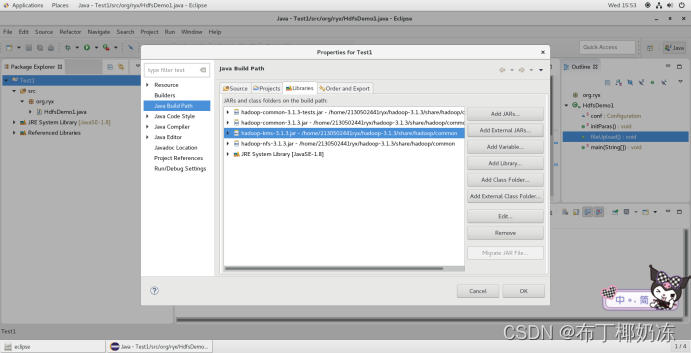
4.3 添加依赖库,将hadoop安装文件夹下的以下子目录文件夹中的jar包加进来
share/hadoop/common
share/hadoop/common/lib
share/hadoop/hdfs
share/hadoop/hdfs/lib
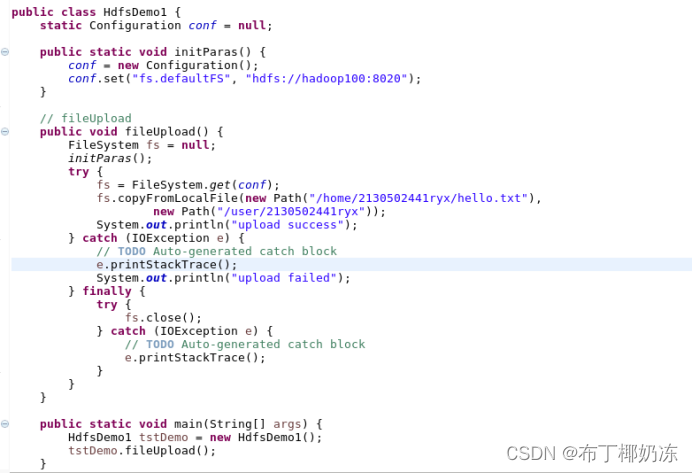
5. 在项目内新建类,类名自定义,并输入以下参考代码(注意修改类名),以下代码的功能是完成从本地文件系统上传一个文件到HDFS文件系统。
6. 运行上述程序,检验文件是否正确上传。通过在本地目录和HDFS文件系统查看检验。
这是本地的hello.txt文件(/home/2130502441ryx/hello.txt)

运行截图:
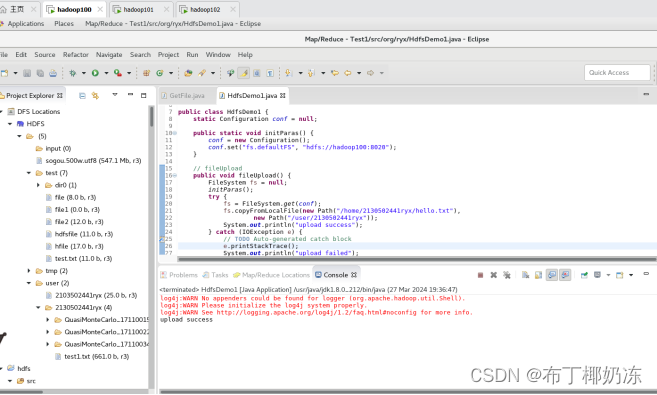
在HDFS文件系统查看:

三、总结
1. 遇到的问题
Eclipse控制台报错:Exception in thread "main" java.lang.NoClassDefFoundError: com/ctc/wstx/io/InputBootstrapper
2. 解决办法
原因是导入的jar包不全,需要将/comon和/hdfs下的包都导进去,之后运行即可。

















 1961
1961

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









