








👑作者主页:@安 度 因
🏠学习社区:StackFrame
📖专栏链接:有营养的算法笔记
如果无聊的话,就来逛逛 我的博客栈 吧! 🌹
今天正式开启算法笔记专栏。本文是专栏的第一篇笔记。主要讲解了快排模板和练习题,让我们一起学习算法吧!
一、思路
快速排序,简称快排,是一个常用的算法。
但是对于快排来说,边界问题是比较难处理的,所以写快排时,背出算法模板,可以帮助我们快速的解决问题。通过板子我们也不需要处理很繁琐的bug。
今天的模板不仅简洁,并且可以完美的解决边界问题。
接下来说一下 快排的主要思想:
快排的思想为 分治 ,说白了就是递归,按照区间,通过递归的方式将序列排成有序。
我们将快排的步骤分为三步:
- 确定分界点:左边界点
q[l]或 右边界点q[r]或 中间点q[l + r >> 1],其中任意一个位置的值为key - 调整区间:小于等于
key的值在左边,大于等于key的值在右边 - 递归处理左右区间,主要方法为使用双指针法分别在左边找不符合条件的值和右边不符合条件的值,然后对它们进行交换,递归处理从而使序列有序。
二、模板讲解
通用模板:
void quick_sort(int q[], int l, int r)
{
if (l >= r) return;
int key = q[l + r >> 1], i = l - 1, j = r + 1;
while (i < j)
{
while (q[++i] < key) ;
while (q[--j] > key) ;
if (i < j) swap(q[i], q[j]);
}
quick_sort(q, l, j);
quick_sort(q, j + 1, r);
}
时间复杂度:O(N * logN) 最差O(N^2) 空间复杂度:O(N)
看完板子,我们提出几个问题:
- 快排递归的截止条件是什么?
key为什么取中间值,这样可以规避什么问题?- 为什么
i和j初始化的值在l - 1和r + 1,如果不这么初始化会有什么问题? - 处理左右区间的主体思路是什么?为什么要
++i,不这样写有什么问题,能不能这么写:while (q[i] < key) i++;? - 如果取的分界点不同时,
quick_sort处理的区间分别可以是什么?一些区间划分为什么不对?
我们接下来带着这些问题来剖析这个板子:
问题1:快排递归的截止条件是什么?
当递归处理区间,截止条件那么就是无需递归,常见情况就是只有一个数,所以理论上是 l == r 就可以截止,但是板子中为了更加严谨,写成了 l >= r也是完全没有问题的。
问题2:
key为什么取中间值,这样可以规避什么问题?
我们设想一下如果 key 取左边界点 q[l],那么当 序列的数全部相同 或 有序 的时候,那么时间复杂度就退化到了 O(N^2) ,当进行排序时,就可能超时。
比如:1 2 3 4 5 6 7 8 9
1 2 3 4 5 6 7 8 9
key
l r
对于这种情况,每一次 key 都会取在左边界点,第一次处理左右边界的时候,就会不断的++i,--j,交换值
对于当前情况就是一直在 --j
那么最后循环停止后,递归处理左右区间时,也是相同情况
就相当于把所有情况都走了一遍,这时 时间复杂度为 O(N^2)
当数据量足够大时,就会超时,我们简单画一下图,就拿这个序列来说
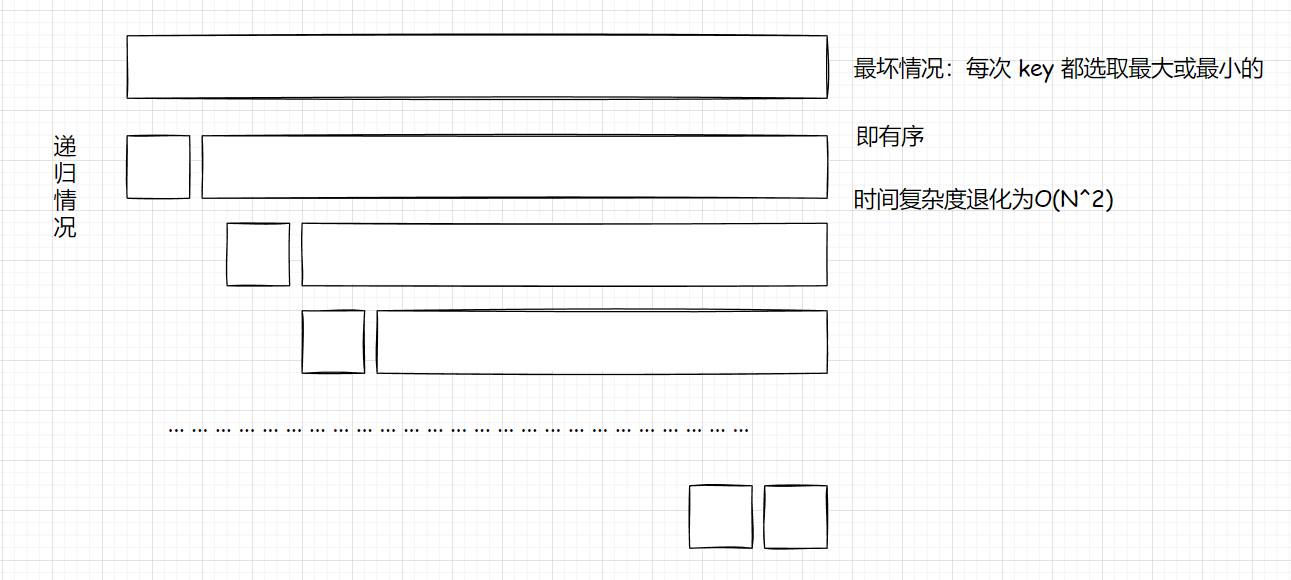
所以当我们 边界点取中 时就可以尽可能规避掉这个问题。
问题3:为什么
i和j初始化的值在l - 1和r + 1,如果不这么初始化会有什么问题?
初始化 l - 1 和 r + 1 就是让 i 和 j 在序列 最左边的前一个位置 和 序列最右边的后一个位置 。
设想一下,如果初始化为 i 和 j 再套用这个模板,会出现什么情况?第一个数必定会错过。就算加以改进,可能还会有很多潜在的问题。
另外初始化为 l 和 r 的某个弊端在下个问题就会提及。
问题4:处理左右区间的主体思路是什么?为什么要
++i,不这样写有什么问题,能不能这么写:while (q[i] < key) i++;?
处理左右区间的主题思路就是 双指针 。
i 用来找 >= x 的值,遇到就停止;j 用来找 <= x 的值,遇到就停止;然后用 swap 库函数交换它们的值,就这么处理达到在每一层函数中左右区间都有序。
那么我们为什么要 ++i ,能不能写成这样?
i = l, j = r;
while (i < j)
{
while (q[i] < key) i++; // 1
while (q[j] > key) j--; // 2
if (i < j) swap(q[i], q[j]);
}
这种情况是可能会导致死循环的,比如序列:3 1 3 6 3
l = 0,q = 4key = q[l + r >> 1] = 3i = 0, j = 4q[i] = 3, q[j] = 3, key = 3
那么在循环处就会卡死,1处走不了,跳到2,但是2也走不了,也无法交换,总的循环条件又满足,所以就会造成 死循环 。这样写是 典型的错误 。
为了规避这个问题,和让 i 和 j 落到相应的位置,于是就有了我们板子里的方案:
i = l - 1, j = r + 1;
while (i < j)
{
while (q[++i] < key) ;
while (q[--j] > key) ;
if (i < j) swap(q[i], q[j]);
}
另外其实 do...while 循环其实更好理解,就是先让 i 和 j 走一步。所以这种模板也可以:
i = l - 1, j = r + 1;
while (i < j)
{
do i++; while (q[i] < key) ;
do j--; while (q[j] > key) ;
if (i < j) swap(q[i], q[j]);
}
问题5:如果取的分界点不同时,
quick_sort处理的区间分别可以是什么?一些区间划分为什么不对?
常见情况 :
-
当 分界点为右边界点
q[r]或 中间点q[l + r + 1 >> 1]时,区间为[l ~ i - 1]和[i ~ r]。 -
当 分界点为左边界点
q[l]或 中间点q[l + r >> 1]时,区间为[l ~ j]和[j + 1 ~ r]。
上面两种为常见的区间的划分,由于博主能力有限,就不深入证明了。下面就举一个简单的例子,说明为什么要这么划分:
我们拿 情况1 举例:
假设我们当前分界点为 中界点 q[l + r >> 1] ,序列为:1 2
l = 0, r = 1l + r >> 1 = 0 key = q[l + r >> 1] = 0
第一次快排
1 2
i key j
while (q[++i] < key) ;i 往后走一步,不满足循环条件,i 在 0 下标处停住;while (q[--j] > key) ;j 往前走一步,满足循环条件,继续循环;while (q[--j] > key) ;j 往前走一步,不满足循环条件,j 在 0 下标处停住;
此刻下标位置情况
1 2
key
ij
i == j 不进行 swap 交换,接下来就要开始划分区间递归;
接下来再看区间的划分:
-
quick_sort(q, l, i - 1);划分区间为[0 ~ -1]区间不存在,这边递归不用进行; -
quick_sort(q, i, r);划分区间为[0 ~ 1],又是第一次快排开始时的区间,这就是 死递归 ,如果测试会 内存超限 ,就是典型的Memory Limit Exceeded错误。
所以我们要加以改进 key = q[l + r + 1 >> 1] ,让其进行 上取整 ,防止下取整到错误情况。
(其他边界情况如果大家有兴趣的话可以自己下去证明一下,博主比较菜…就不献丑了,目前只要背住我们当前这个板子,对大多数情况都是没有问题的)
三、模板测试
我们用一道OJ测试我们的模板是否正确:
描述:
给定你一个长度为 n 的整数数列。
请你使用快速排序对这个数列按照从小到大进行排序。
并将排好序的数列按顺序输出。
输入格式:
输入共两行,第一行包含整数 n 。
第二行包含 n 个整数(所有整数均在 1∼10^9 范围内),表示整个数列。
输出格式:
输出共一行,包含 nn 个整数,表示排好序的数列。
数据范围:
1≤ n ≤ 100000
输入样例:
5
3 1 2 4 5
输出样例:
1 2 3 4 5
代码:
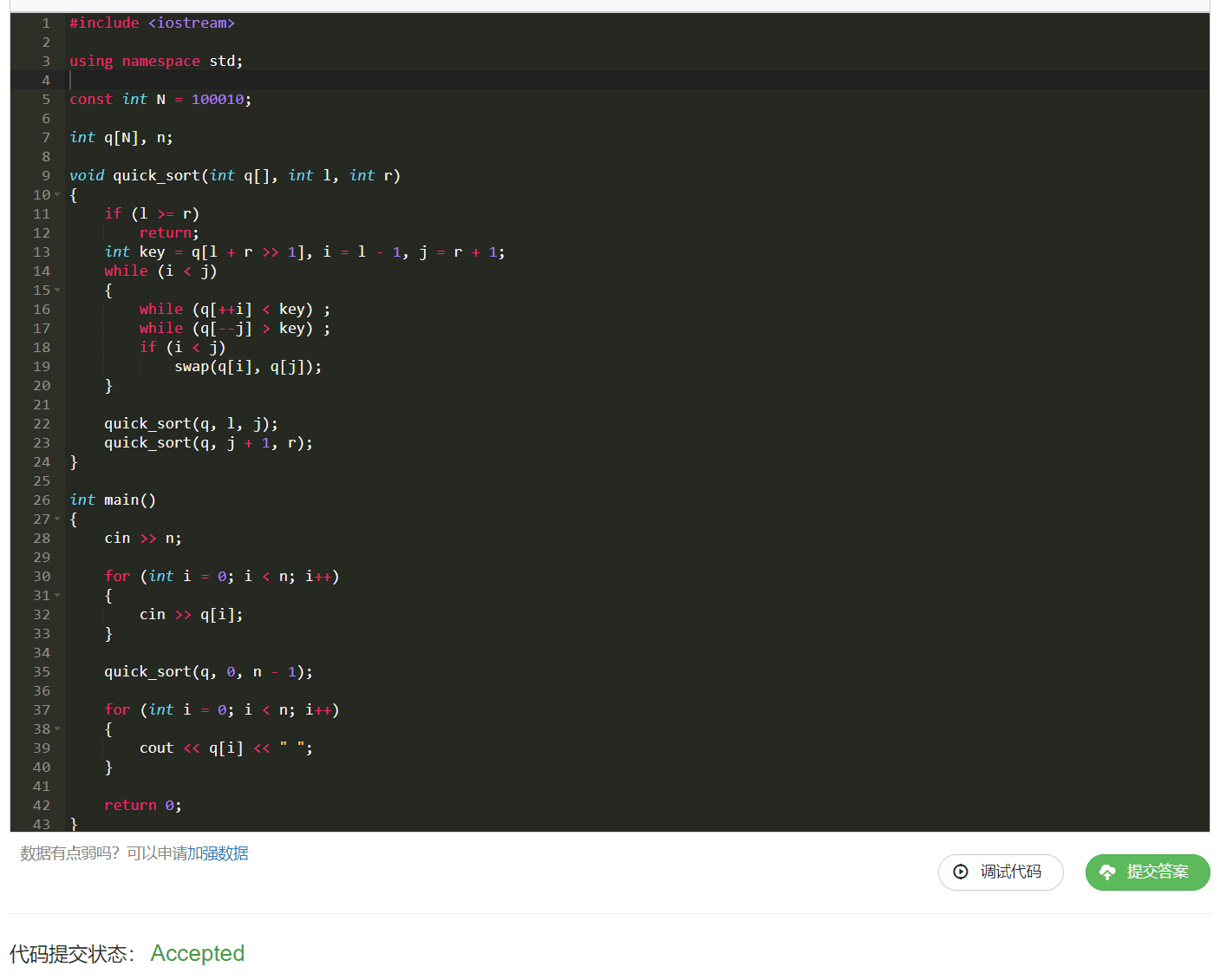
AC了,那么说明是没有问题的
四、加练 —— 第 K 个数
描述:
给定一个长度为 n 的整数数列,以及一个整数 k,请用 快速选择算法 求出数列从小到大排序后的第 k 个数。
输入格式:
第一行包含两个整数 n 和 k。
第二行包含 n 个整数(所有整数均在 1∼10^9 范围内),表示整数数列。
输出格式:
输出一个整数,表示数列的第 k 小数。
数据范围:
1 ≤ n ≤ 1000001 ≤ k ≤ n
输入样例:
5 3
2 4 1 5 3
输出样例:
3
思路:
对于 快速选择算法 ,其实就是 快排的一个变形 。
对于 快速选择算法 我们这里主要分三步:
- 确定分界点:左边界点
q[l]或 右边界点q[r]或 中间点q[l + r >> 1],其中任意一个位置的值为key - 调整区间:小于等于
key的值在左边,大于等于key的值在右边 - 根据左右区间元素个数,确定 k 所在区间,对单个区间进行递归
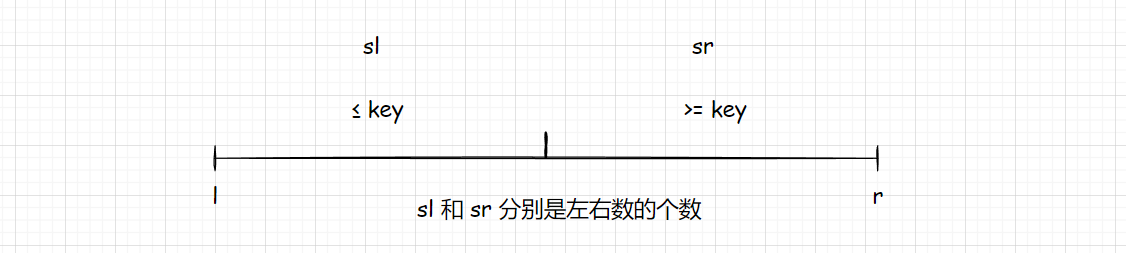
这里分情况讨论:
k ≤ sl,则递归 左区间 ,由于 k 在 左半区间 ,所以依然是找的 第k个数k > sl,则递归 右区间 ,由于 k 在 右半区间 ,所以找的是 第k - sl个数
那么到这里,我们也可以计算出它的时间复杂度:由于我们只需要一边递归,那么我们的总执行次数大约为:n + n/2 + n/4.... < 2n ,时间复杂度为 O(N)。
接下来我们看一下代码怎么写:
#include <iostream>
using namespace std;
const int N = 100010;
int q[N], n, k;
int quick_sort(int l, int r, int k)
{
if (l >= r)
return q[l];
int key = q[l + r >> 1], i = l - 1, j = r + 1;
while (i < j)
{
while (q[++i] < key) ;
while (q[--j] > key) ;
if (i < j)
swap(q[i], q[j]);
}
int sl = j - l + 1; // 左半区间的元素个数
if (k <= sl)
return quick_sort(l, j, k); // 递归左半区间
else
return quick_sort(j + 1, r, k - sl); // 递归右半区间
}
int main()
{
cin >> n >> k;
for (int i = 0; i < n; i++)
{
cin >> q[i];
}
cout << quick_sort(0, n - 1, k) << endl;
return 0;
}
这里递归到最后会只剩下一个数的,所以结果是一定会找到的,不用担心找不到,不太理解的话可以画一下图。
这里还有一个更加容易理解的版本,我比较推荐:
我们求 第 k 个数,其实就是求 k - 1 下标的值。
那么的主体思路的第三步就可以改为:
每次判断 k 是在 左半区间 还是 右半区间 ,递归查找 k 所在区间,递归到最后只剩一个数时,q[k]就是答案。
#include <iostream>
using namespace std;
const int N = 100010;
int q[N], n, k;
int quick_sort(int l, int r, int k)
{
if (l >= r)
return q[k];
int key = q[l + r >> 1], i = l - 1, j = r + 1;
while (i < j)
{
while (q[++i] < key) ;
while (q[--j] > key) ;
if (i < j)
swap(q[i], q[j]);
}
if (k <= j) // k 在左半区间
return quick_sort(l, j, k);
else
return quick_sort(j + 1, r, k);
}
int main()
{
cin >> n >> k;
for (int i = 0; i < n; i++)
{
cin >> q[i];
}
// k - 1 就是 第 k 个数 的下标
cout << quick_sort(0, n - 1, k - 1) << endl;
return 0;
}
到这里,本篇博客就到此结束了。建议看完博客后可以把模板通过理解的方式背住,下去再多练几遍代码,加深记忆。这样可以很快提高熟练度。
如果觉得anduin写的还不错的话,还请一键三连!如有错误,还请指正!
我是anduin,一名C语言初学者,我们下期见!
















 342
342











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











