






问题描述:
线上ES入库任务存在积压,执行/_cluster/health发现status为red,有两个未分配分片,而查询未分配分片为某个索引的某个主分片和该主分片的副分片。执行/_cluster/allocation/explain 查具体分片,错误信息如下:
{
“index” : “XXXX”,
“shard” : 1,
“primary” : true,
“current_state” : “unassigned”,
“unassigned_info” : {
“reason” : “ALLOCATION_FAILED”,
“at” : “2023-09-10T13:13:09.289Z”,
“failed_allocation_attempts” : 1,
“details” : “failed shard on node [1Pk0_xS-R96rLbH-4MxC9A]: shard failure, reason [already closed by tragic event on the index writer], failure CorruptIndexException[compound sub-files must have a valid codec header and footer: codec header mismatch: actual header=0 vs expected header=1071082519 (resource=BufferedChecksumIndexInput(NIOFSIndexInput(path=”/home/sdaa/elasticsearch/data/nodes/0/indices/wDRpSVH0Rzav0fWZ85Zz4w/1/index/_l.fdt")))]",
“last_allocation_status” : “no_valid_shard_copy”
},
“can_allocate” : “no_valid_shard_copy”,
“allocate_explanation” : “cannot allocate because all found copies of the shard are either stale or corrupt”,
“node_allocation_decisions” : [
{
“node_id” : “1Pk0_xS-R96rLbH-4MxC9A”,
“node_name” : “node19”,
“transport_address” : “XXXX:9300”,
“node_attributes” : {
“ml.machine_memory” : “202551648256”,
“ml.max_open_jobs” : “20”,
“xpack.installed” : “true”
},
…
而对应副分片报错“PRIMARY FAILED”,所以显然是主分片错误引起的。
解决过程
在网上搜了一圈没搜到相关信息,第一次出现这个问题的时候,我尝试了/_cluster/reroute?retry_failed=true 无果,临时解决方案是强制分配空分片,如下:
curl -XPOST 'XXX/_cluster/reroute' -H 'Content-Type: application/json' -d '{
"commands": [
{
"allocate_empty_primary": {
"index": "XXX",
"shard": '0',
"node": "node06",
"accept_data_loss": true
}
}
]
}'
但这会损失该分片之前的数据,所以我一直在找这个问题出现的根本原因,不然也只是治标不治本。
直到这个问题第二次出现甚至第三次出现的时候,我发现每次报错都是同一个节点的同一个磁盘,都是node19的/home/sdaa,虽然看不懂这个报错是啥意思,但是分析了一下可能就是这个磁盘的问题。而同时我在官方社区的提问也得到了回答,是官方文档对这个报错的解释:
https://www.elastic.co/guide/en/elasticsearch/reference/current/corruption-troubleshooting.html
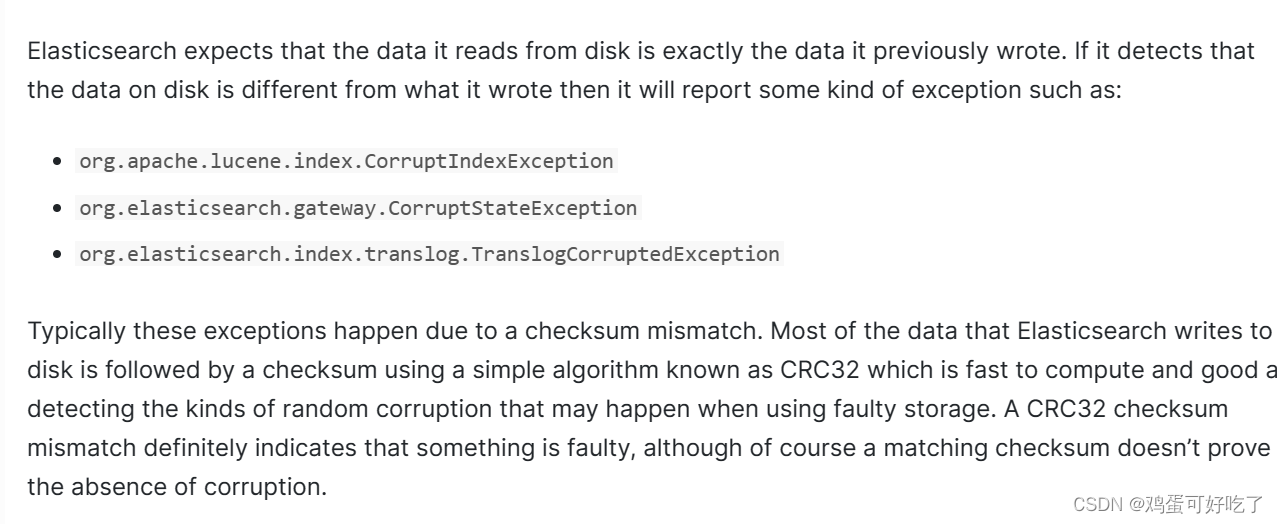
虽然官网说的是checksum mismatch,我的报错是codec header mismatch,但是都是CorruptIndexException,归根结底都是磁盘的数据和写入时的数据相比发生了变化,所以不匹配。官方给出的原因有几种,可能是文件系统的问题,可能是三方程序修改了数据,还有些其他原因。
分析我们线上的问题,每次出问题都出在node19的/home/sdaa,所以应该就是这块盘出了问题,而不是一些其他的原因。最终我的解决方案是在这个节点上修改es的配置,剔除/home/sdaa。
目前为止还没有再出现这个报错,应该是解决对了吧。。。。。如果后续仍然出了问题,我再来更















 1136
1136











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









