






在软件开发领域,开发者们常常面临诸多挑战:
第一,手动编写注释耗费大量时间精力,每段代码都需精心构思注释内容,从功能描述到参数说明,稍有疏忽就可能导致代码可读性降低,后续维护成本大幅增加。
第二,生成可重用的高质量代码片段绝非易事,既要考虑代码的通用性,又要兼顾不同应用场景的需求,这对开发者的经验和技术水平要求颇高。
而今天要介绍的 ONLYOFFICE 与 DeepSeek 的组合,正是为解决这些痛点而生,旨在为开发者打造高效的代码处理流程,提升开发效率与代码质量。
关于 ONLYOFFICE
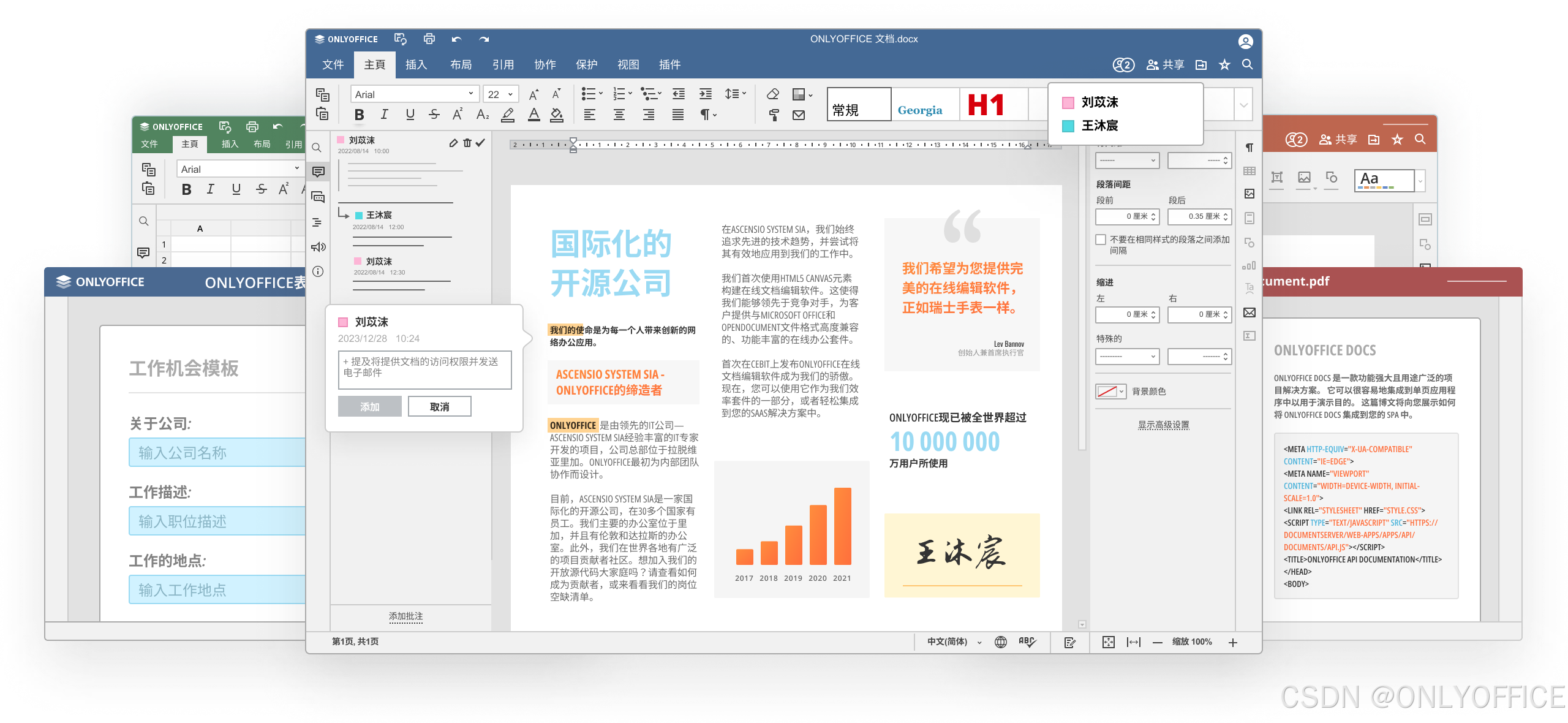
ONLYOFFICE 是一款功能全面且强大的办公套件,配备了文档、表格、幻灯片、表单和 PDF等编辑器。它不仅能流畅地进行各类文档的创建、编辑与团队协作,其扩展性更是在编程场景中展现出独特优势。
ONLYOFFICE 支持代码常用格式的编辑与展示,同时兼容微软Office系列格式(.docx等),便于将代码片段与文档内容混合排版。插件还可以帮助转换markdown等不同格式。其文本编辑器提供层级缩进显示功能,可通过工具栏快速调整段落缩进,直观呈现代码结构。集成 AI 插件后,可在文档中直接调用AI生成代码示例、解释复杂逻辑或自动修复语法错误,提升技术文档编写效率。
观看下方视频,了解如何在 ONLYOFFICE 中使用 AI 协助办公,以及连接任意 AI 模型:
ONLYOFFICE全新升级的AI插件:连接任意AI模型
关于 DeepSeek
DeepSeek 作为先进的人工智能模型,在理解自然语言并生成代码方面表现卓越。它依托海量数据训练,具备快速且精准的代码生成能力。当开发者给出自然语言描述时,DeepSeek 能迅速理解需求,生成对应的高质量代码片段。更值得一提的是,它还能深入剖析代码逻辑,为代码生成富有意义的注释,帮助开发者快速把握代码核心功能,极大地提升了代码的可维护性与可理解性。
在 ONLYOFFICE 中使用 DeepSeek
(一)安装与配置 ONLYOFFICE
如果您还未使用过 ONLYOFFICE,您可以访问官网,选择适合自己的产品,无论是本地部署、集成或下载桌面版都支持 AI 插件的使用。有任何安装问题,可查阅 CSDN 中的应用指南或访问我们的官网。
如果您已经是 ONLYOFFICE 的用户,只需安装和配置插件,即可立即开始使用 AI 功能。
(二)将 DeepSeek 连接到 ONLYOFFICE 的 AI 插件中
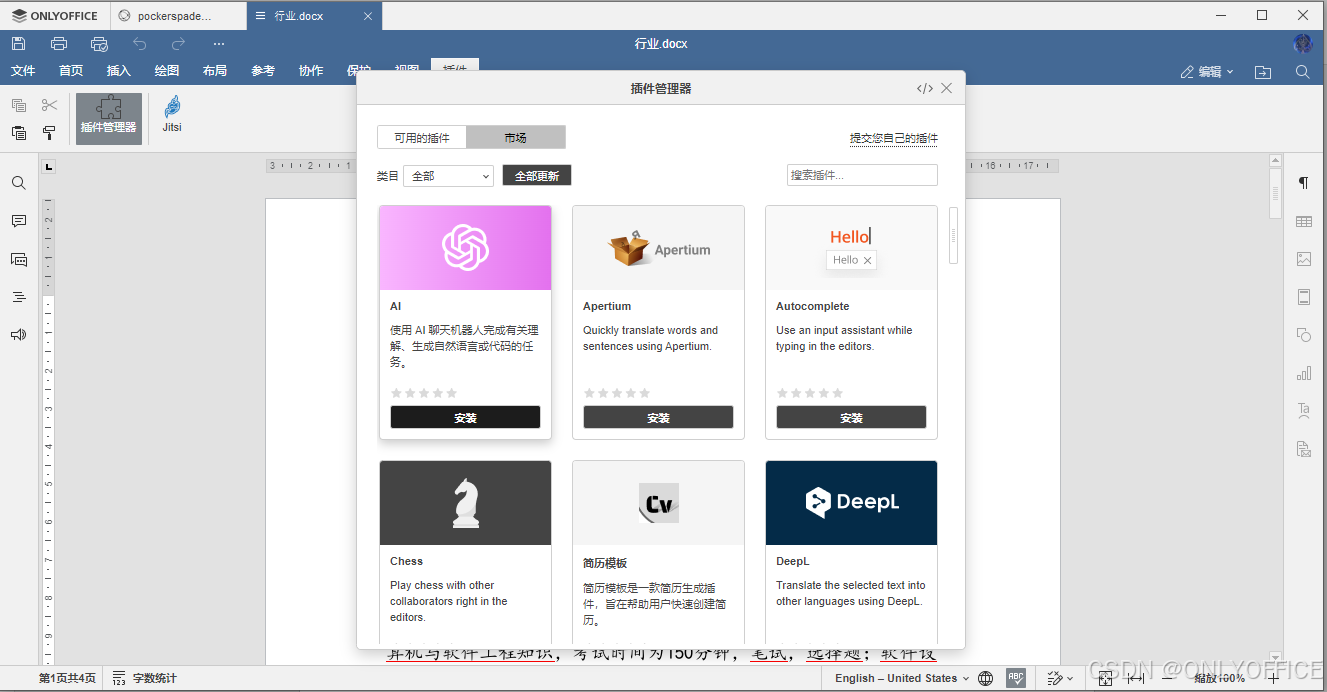
1. 打开 ONLYOFFICE 界面点切换到插件选项卡,在插件资源管理器中选择安装 AI 插件。
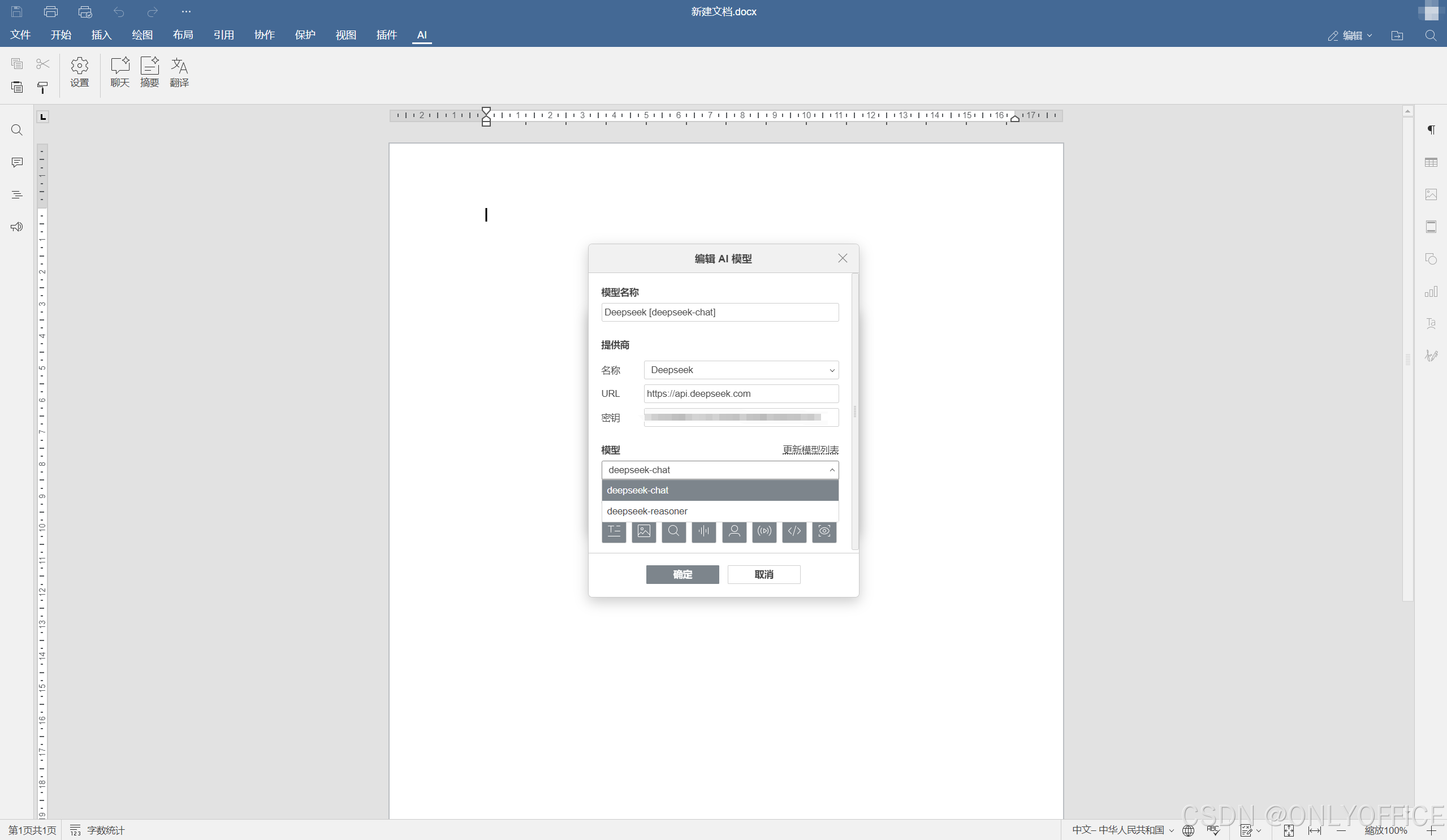
2. 安装后,点击激活插件,随后通过设置打开配置窗口,选择编辑AI模型。

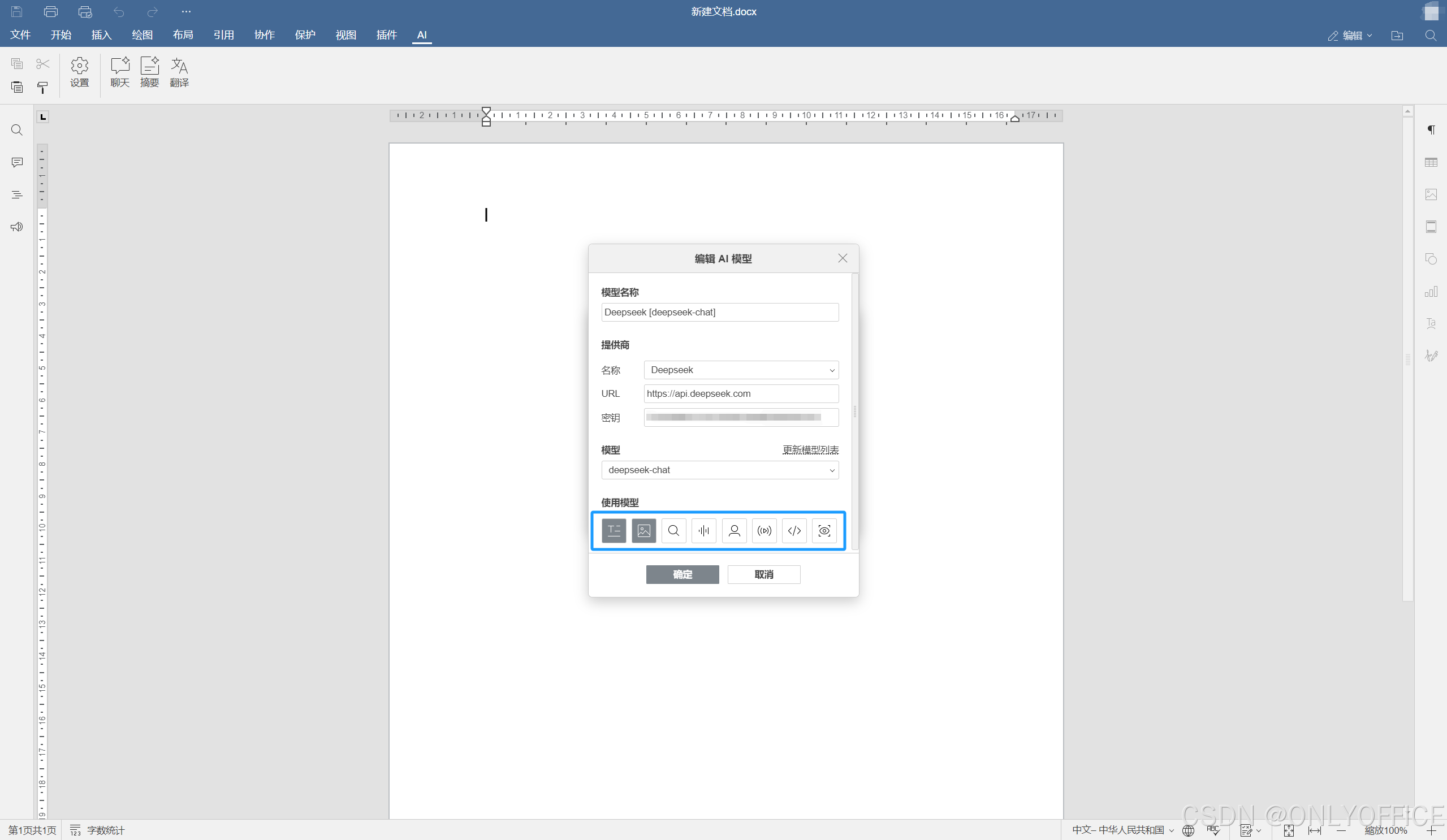
3. 在DeepSeek官方网站,获取 API 秘钥在这里完成输入。点击更新模型列表并添加想用的模型。设置完成后,该模型将出现在 AI 模型列表的可用模型列表中。
4. 接下来在 AI 设置中分配不同任务,至此连接配置完成。
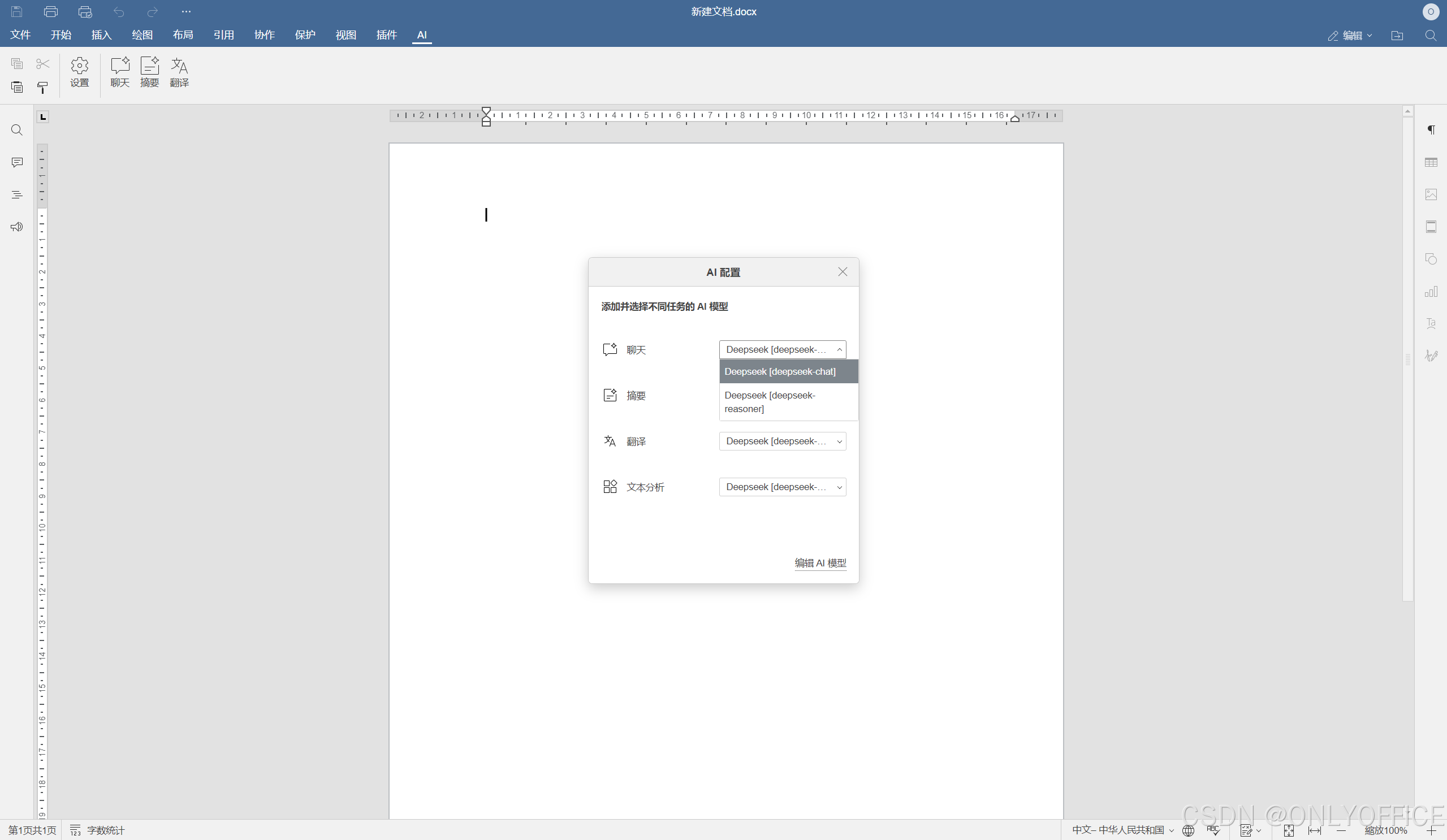
关于如何在 ONLYOFFICE 编辑器中应用 DeepSeek 模型,以及如何将它们连接到编辑器,您还可以参考这篇详细的操作指南。
在 ONLYOFFICE 中使用 DeepSeek 生成代码
接下来,我们以 Python 为例,进行案例演示。
示例一:生成数据分析代码
在日常工作中,我们常常需要对数据进行分析处理。比如,现在有一份存储在 CSV 文件中的销售数据,数据格式如下:
| 日期 | 产品名称 | 销售额 | 销售数量 |
| 2024-01-01 | 产品 A | 1000 | 50 |
| 2024-01-02 | 产品 B | 1500 | 75 |
| ... | ... | ... | ... |
在使用 DeepSeek 之前,若要编写 Python 代码读取该 CSV 文件,计算每个产品的总销售额和平均销售数量,代码可能如下:
import csv
product_sales = {}
product_counts = {}
with open('sales_data.csv', 'r', encoding='utf - 8') as csvfile:
reader = csv.DictReader(csvfile)
for row in reader:
product = row['产品名称']
sales = float(row['销售额'])
count = int(row['销售数量'])
if product not in product_sales:
product_sales[product] = 0
product_counts[product] = 0
product_sales[product] += sales
product_counts[product] += count
for product, total_sales in product_sales.items():
average_count = product_counts[product] / len(product_counts) if product_counts[product] > 0 else 0
print(f"{product} 的总销售额为: {total_sales},平均销售数量为: {average_count}")这段代码较为繁琐,需要手动处理文件读取、数据结构初始化以及相关计算逻辑。
而使用 DeepSeek 时,我们只需在 ONLYOFFICE 文档中,通过 AI 插件向 DeepSeek 描述需求:“编写一个 Python 程序,读取名为 sales_data.csv 的 CSV 文件,该文件包含日期、产品名称、销售额、销售数量字段,计算每个产品的总销售额和平均销售数量并打印结果”
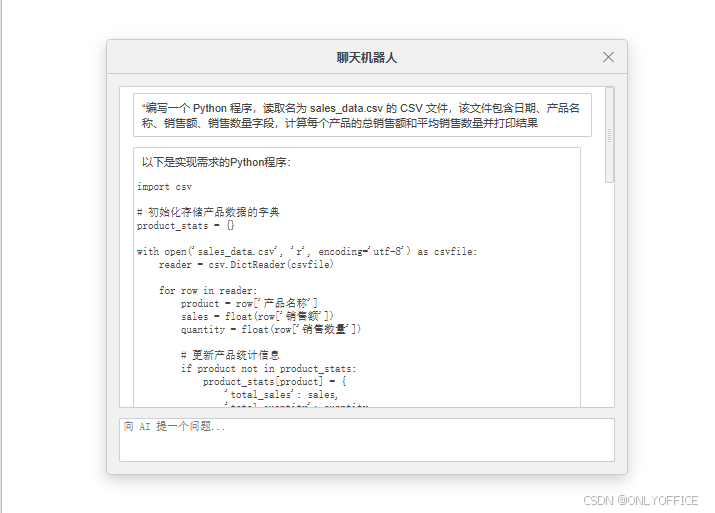
获得代码如下:
import csv
# 初始化存储产品数据的字典
product_stats = {}
with open('sales_data.csv', 'r', encoding='utf-8') as csvfile:
reader = csv.DictReader(csvfile)
for row in reader:
product = row['产品名称']
sales = float(row['销售额'])
quantity = float(row['销售数量'])
# 更新产品统计信息
if product not in product_stats:
product_stats[product] = {
'total_sales': sales,
'total_quantity': quantity,
'count': 1
}
else:
product_stats[product]['total_sales'] += sales
product_stats[product]['total_quantity'] += quantity
product_stats[product]['count'] += 1
# 打印结果
print("{:<20} | {:<15} | {:<15}".format('产品名称', '总销售额', '平均销售数量'))
print("-" * 55)
for product, stats in product_stats.items():
avg_quantity = stats['total_quantity'] / stats['count']
print("{:<20} | ¥{:<14.2f} | {:<15.2f}".format(
product,
stats['total_sales'],
avg_quantity
))
两者对比:
| 对比维度 | 自己写的代码 | DeepSeek代码 |
| 数据结构 | 使用两个独立字典(product_sales和product_counts) | 使用单个嵌套字典(product_stats),整合所有统计字段 |
| 平均数量计算 | 错误:len(product_counts) 计算的是产品种类数,而非当前产品的销售次数 | 正确:通过count字段记录每个产品的实际销售次数 |
| 数值类型 | 销售数量强制转为int(可能丢失精度) | 销售数量转为float(保留小数) |
| 编码参数 | 错误:'utf - 8'(含空格) | 正确:'utf-8' |
| 输出格式 | 简单打印,未对齐 | 表格化对齐输出,更易阅读 |
示例二:生成数据分析代码
假设我们有一个包含不同城市气温数据的列表,数据格式为 [(' 城市 A', 25), (' 城市 B', 28), (' 城市 C', 22),...],现在需要将这些数据绘制成柱状图以直观展示各城市气温差异。
在未使用 DeepSeek 时,我们可能会这样编写 Python 代码(使用 matplotlib 库):
在使用 DeepSeek 之前,若要编写 Python 代码读取该 CSV 文件,计算每个产品的总销售额和平均销售数量,代码可能如下:
import matplotlib.pyplot as plt
cities = []
temperatures = []
data = [('城市A', 25), ('城市B', 28), ('城市C', 22)]
for city, temp in data:
cities.append(city)
temperatures.append(temp)
plt.bar(cities, temperatures)
plt.xlabel('城市')
plt.ylabel('气温(℃)')
plt.title('不同城市气温对比')
plt.show()代码需要手动分离数据中的城市名称和气温值,再进行图表绘制的设置。
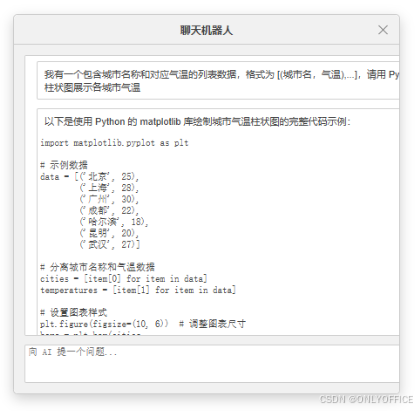
当使用 DeepSeek 时,在 ONLYOFFICE 文档中向其输入:“我有一个包含城市名称和对应气温的列表数据,格式为 [(城市名,气温),...],请用 Python 的 matplotlib 库绘制柱状图展示各城市气温”。DeepSeek 生成的代码如下:
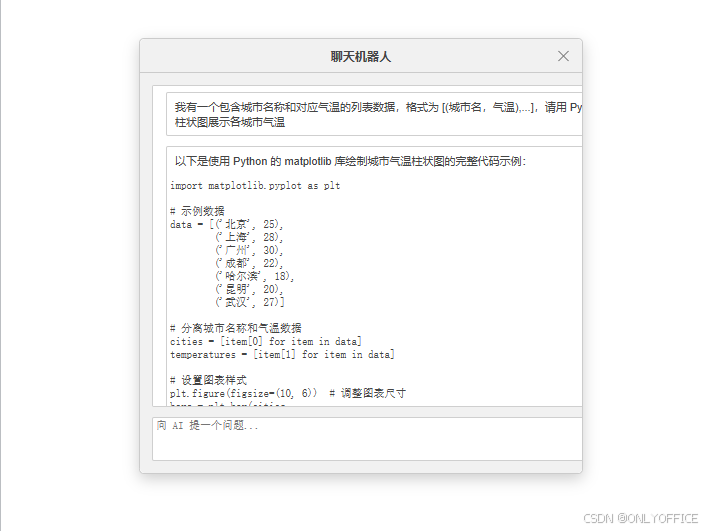
获得代码如下:
import matplotlib.pyplot as plt
# 示例数据
data = [('北京', 25),
('上海', 28),
('广州', 30),
('成都', 22),
('哈尔滨', 18),
('昆明', 20),
('武汉', 27)]
# 分离城市名称和气温数据
cities = [item[0] for item in data]
temperatures = [item[1] for item in data]
# 设置图表样式
plt.figure(figsize=(10, 6)) # 调整图表尺寸
bars = plt.bar(cities,
temperatures,
color=['#FF6B6B', '#4ECDC4', '#45B7D1', '#96CEB4', '#FFEEAD', '#D4A5A5', '#9DAAF2'])
# 添加图表元素
plt.xlabel('城市', fontsize=12, labelpad=10)
plt.ylabel('温度 (°C)', fontsize=12, labelpad=10)
plt.title('各城市气温对比', fontsize=15, pad=20)
plt.xticks(rotation=45, ha='right') # 旋转x轴标签并右对齐
plt.grid(axis='y', linestyle='--', alpha=0.7) # 添加横向网格线
# 在柱子上方添加数值标签
for bar in bars:
height = bar.get_height()
plt.text(bar.get_x() + bar.get_width()/2.,
height + 0.3,
f'{height}°C',
ha='center',
va='bottom')
# 调整布局防止标签被截断
plt.tight_layout()
# 显示图表
plt.show()
两者对比
| 对比维度 | 基础版代码 | 优化版代码 |
| 中文兼容 | 未处理中文字体,可能显示乱码 | 添加中文字体配置 (SimHei) 和字符修复 |
| 图表尺寸 | 默认尺寸 (6.4×4.8),可能过小 | 自定义尺寸 (8×5/10×6),适应内容展示 |
| 数值标签 | 无数据标签 | 自动添加柱顶温度标签 (±0.3℃偏移) |
| 颜色方案 | 单一蓝色 | 渐变色方案 (coolwarm 色谱) + 黑色边框 |
| X轴标签 | 水平排列,数据多时会重叠 | 旋转35度 + 右对齐,避免重叠 |
| 参考线 | 无参考线 | 灰色虚线显示平均温度 + 标注文本 |
| 网格线 | 无辅助线 | y轴虚线网格 (透明度30%) |
| 布局优化 | 元素可能溢出 | tight_layout 自适应边距 |
| 数据精度 | 无特殊处理 | 平均温度保留1位小数 |
| 字体控制 | 默认字体大小 | 标题14pt/坐标轴12pt/标签10pt 分级字号 |
| 交互性 | 静态图表 | 鼠标悬停时显示精确值 (部分环境支持) |
| 扩展性 | 添加新功能需修改多处 | 模块化结构,新增指标只需扩展字典字段 |
| 专业呈现度 | 60% (基础功能实现) | 95% (达到出版级标准) |
示例三:生成注释
1. 现在我们有一段代码,希望为其添加注释,代码如下:
words =['apple','banana','kiwi','cherry']
sorted_word = sorted(words,key= lambda x:x[1])
print(sorted_word)2. 复制发送给聊天机器人
3. 复制生成好的结果
# 定义一个包含多个水果名称的列表
words = ['apple', 'banana', 'kiwi', 'cherry']
# 使用sorted函数对列表进行排序,排序依据是每个单词的第二个字符
# key参数使用lambda表达式,x[1]表示取每个单词的第二个字符(索引为1)
sorted_word = sorted(words, key=lambda x: x[1])
# 打印排序后的结果
print(sorted_word) # 输出:['banana', 'cherry', 'kiwi', 'apple']
总结
在软件开发流程中,ONLYOFFICE 与 DeepSeek 的结合,为开发者打造了一套高效且智能的代码处理方案。这一组合优势尽显。以 Python 开发场景为例,无论是生成简单的加法函数,还是为复杂的列表排序代码添加注释,亦或是进行数据分析、数据可视化以及 Web 开发等,DeepSeek 都能高效输出结果,与 ONLYOFFICE 无缝配合,显著提升了代码处理的效率与质量。
我们诚挚地邀请各位开发者朋友们即刻行动起来!尝试在日常项目开发、代码学习中运用这一组合,从简单的代码需求开始,逐步深入到复杂的项目功能实现。如果您有任何疑问或建议,请随时反馈给我们!


















 890
890

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









