







Hadoop是一个适合海量数据的分布式存储和分布式计算的框架
分布式存储,可以简单理解为存储数据的时候,数据不只存在一台机器上面,它会存在多台机器上面
分布式计算简单理解,就是由很多台机器并行处理数据
Hadoop版本演变历史
hadoop1.x:HDFS+MapReduce
hadoop2.x:HDFS+YARN+MapReduce
hadoop3.x:HDFS+YARN+MapReduce

从Hadoop1.x升级到Hadoop2.x,架构发生了比较大的变化,这里面的HDFS是分布式存储,MapRecue是分布式计算,咱们前面说了Hadoop解决了分布式存储和分布式计算的问题,对应的就是这两个模块
在Hadoop2.x的架构中,多了一个模块 YARN,这个是一个负责资源管理的模块,那在Hadoop1.x中就也是需要的,只不过是在Hadoop1.x中,分布式计算和资源管理都是MapReduce负责的,从Hadoop2.x开始把资源管理单独拆分出来了,拆分出来的好处就是,YARN变成了一个公共的资源管理平台,在它上面不仅仅可以跑MapReduce程序,还可以跑很多其他的程序,只要你的程序满足YARN的规则即可
Hadoop 2中的HDFS最多支持两个NameNode,一主一备,而Hadoop 3中的HDFS支持多个NameNode,一主多备
Hadoop主要包含三大组件:HDFS+MapReduce+YARN
- HDFS负责海量数据的分布式存储
- MapReduce是一个计算模型,负责海量数据的分布式计算
- YARN主要负责集群资源的管理和调度
HDFS
HDFS的全称是Hadoop Distributed File System ,Hadoop的 分布式 文件 系统。
通过前面的学习,我们对HDFS有了基本的了解,下面我们就想实际操作一下,来通过实操加深对HDFS的理解:
1.针对HDFS,我们可以在shell命令行下进行操作,就类似于我们操作linux中的文件系统一样,但是具体命令的操作格式是有一些区别的
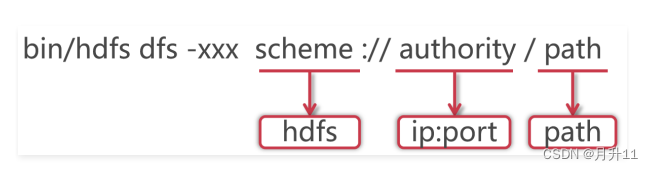
2.使用hadoop bin目录的hdfs命令,后面指定dfs,表示是操作分布式文件系统的,这些属于固定格式。
3.如果在PATH中配置了hadoop的bin目录,那么这里可以直接使用hdfs就可以了
4.这里的xxx是一个占位符,具体我们想对hdfs做什么操作,就可以在这里指定对应的命令了
5.大多数hdfs 的命令和对应的Linux命令类似
6.HDFS的schema是hdfs,authority是集群中namenode所在节点的ip和对应的端口号,把ip换成主机名
也是一样的,path是我们要操作的文件路径信息
7.其实后面这一长串内容就是core-site.xml配置文件中fs.defaultFS属性的值,这个代表的是HDFS的地址。
HDFS 的常见shell操作
-ls
-get
-put
-cat
-rm[-r]
[root@bigdata01 hadoop-3.2.0]#hdfs dfs
[root@bigdata01 hadoop-3.2.0]#hdfs dfs -ls hdfs://bigdata01:9000/
[root@bigdata01 hadoop-3.2.0]# hdfs dfs -ls /
-ls:查询指定路径信息
-put :从本地上传文件
向hdfs中上传一个文件,使用Hadoop中的README.txt,直接上传到hdfs的根目录即可
[root@bigdata01 hadoop-3.2.0]# hdfs dfs -put README.txt /
确认一下刚才上传的文件
root@bigdata01 hadoop-3.2.0]# hdfs dfs -ls /
Found 1 items
-rw-r--r-- 2 root supergroup 1361 2020-04-08 15:34 /README.txt
在这里可以发现使用hdfs中的ls查询出来的信息和在linux中执行ll查询出来的信息是类似的
在这里能看到这个文件就说明刚才的上传操作是成功的
-cat :查看HDFS文件内容
[root@bigdata01 hadoop-3.2.0]# hdfs dfs -cat /README.txt
For the latest information about Hadoop, please visit our website at:
http://hadoop.apache.org/
and our wiki, at:
http://wiki.apache.org/hadoop/
...........
-get:下载文件到本地
[root@bigdata01 hadoop-3.2.0]# hdfs dfs -get /README.txt .
-mkdir[-p]:创建文件夹
来创建一个文件夹,hdfs中使用mkdir命令
[root@bigdata01 hadoop-3.2.0]# hdfs dfs -mkdir /test
[root@bigdata01 hadoop-3.2.0]# hdfs dfs -ls /
Found 2 items
-rw-r--r-- 2 root supergroup 1361 2020-04-08 15:34 /README.txt
drwxr-xr-x - root supergroup 0 2020-04-08 15:43 /test
如果要递归创建多级目录,还需要再指定-p参数
[root@bigdata01 hadoop-3.2.0]# hdfs dfs -mkdir -p /abc/xyz
Found 3 items
-rw-r--r-- 2 root supergroup 1361 2020-04-08 15:34 /README.txt
drwxr-xr-x - root supergroup 0 2020-04-08 15:44 /abc
drwxr-xr-x - root supergroup 0 2020-04-08 15:43 /test
想要递归显示所有目录的信息,可以在ls后面添加-R参数
[root@bigdata01 hadoop-3.2.0]# hdfs dfs -ls -R /
-rw-r--r-- 2 root supergroup 1361 2020-04-08 15:34 /README.txt
drwxr-xr-x - root supergroup 0 2020-04-08 15:44 /abc
drwxr-xr-x - root supergroup 0 2020-04-08 15:44 /abc/xyz
drwxr-xr-x - root supergroup 0 2020-04-08 15:43 /test
-rm[-r]:删除文件、文件夹
如果想要删除hdfs中的目录或者文件,可以使用rm
删除文件
[root@bigdata01 hadoop-3.2.0]# hdfs dfs -rm /README.txt
Deleted /README.txt
删除目录,需要指定-r参数
[root@bigdata01 hadoop-3.2.0]# hdfs dfs -rm /test
rm: `/test': Is a directory
[root@bigdata01 hadoop-3.2.0]# hdfs dfs -rm -r /test
Deleted /test
多级目录,递归删除
[root@bigdata01 hadoop-3.2.0]# hdfs dfs -rm -r /abc
Deleted /abc
操作篇
先向HDFS中上传几个文件,把hadoop目录中的几个txt文件上传上去
[root@bigdata01 hadoop-3.2.0]# hdfs dfs -put LICENSE.txt /
[root@bigdata01 hadoop-3.2.0]# hdfs dfs -put NOTICE.txt /
[root@bigdata01 hadoop-3.2.0]# hdfs dfs -put README.txt /
统计根目录下文件的个数
[root@bigdata01 hadoop-3.2.0]# hdfs dfs -ls / |grep /| wc -l
3
/LICENSE.txt 150569
/NOTICE.txt 22125
/README.txt 1361
java代码操作HDFS
上传文件
package com.imooc.hdfs;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import java.io.FileInputStream;
import java.net.URI;
/**
* Java代码操作HDFS
* 文件操作:上传文件、下载文件、删除文件
* Created by xuwei
*/
public class HdfsOp {
public static void main(String[] args) throws Exception{
//创建一个配置对象
Configuration conf = new Configuration();
//指定HDFS的地址
conf.set("fs.defaultFS","hdfs://bigdata01:9000");
//获取操作HDFS的对象
FileSystem fileSystem = FileSystem.get(conf);
//获取HDFS文件系统的输出流
FSDataOutputStream fos = fileSystem.create(new Path("/user.txt"));
//获取本地文件的输入流
FileInputStream fis = new FileInputStream("D:\\user.txt");
//上传文件:通过工具类把输入流拷贝到输出流里面,实现本地文件上传到HDFS
IOUtils.copyBytes(fis,fos,1024,true);
}
}
问题出现!!!
如果报错 提示权限拒绝,说明windows中的这个用户没有权限向HDFS中写入数据
解决办法有两个
第一种:去掉hdfs的用户权限检验机制,通过在hdfs-site.xml中配置dfs.permissions.enabled为false即
可
第二种:把代码打包到linux中执行
在这里为了在本地测试方便,我们先使用第一种方式
1.:停止Hadoop集群
[root@bigdata01 ~]# cd /data/soft/hadoop-3.2.0
[root@bigdata01 hadoop-3.2.0]# sbin/stop-all.sh
2.:修改hdfs-site.xml配置文件
注意:集群内所有节点中的配置文件都需要修改,先在bigdata01节点上修改,然后再同步到另外
两个节点上
[root@bigdata01 hadoop-3.2.0]# vi etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>bigdata01:50090</value>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
</configuration>
同步到另外两个节点中
[root@bigdata01 hadoop-3.2.0]# scp -rq etc/hadoop/hdfs-site.xml bigdata02:/d
[root@bigdata01 hadoop-3.2.0]# scp -rq etc/hadoop/hdfs-site.xml bigdata03:/d
3:启动Hadoop集群
[root@bigdata01 hadoop-3.2.0]# sbin/start-all.sh
Starting namenodes on [bigdata01]
Last login: Wed Apr 8 20:25:49 CST 2020 on pts/1
Starting datanodes
Last login: Wed Apr 8 20:29:57 CST 2020 on pts/1
Starting secondary namenodes [bigdata01]
Last login: Wed Apr 8 20:29:59 CST 2020 on pts/1
Starting resourcemanager
Last login: Wed Apr 8 20:30:04 CST 2020 on pts/1
Starting nodemanagers
Last login: Wed Apr 8 20:30:10 CST 2020 on pts/1
重新再执行代码,没有报错,到hdfs上查看数据
[root@bigdata01 hadoop-3.2.0]# hdfs dfs -ls /
Found 4 items
-rw-r--r-- 2 root supergroup 150569 2020-04-08 15:55 /LICENSE.txt
-rw-r--r-- 2 root supergroup 22125 2020-04-08 15:55 /NOTICE.txt
-rw-r--r-- 2 root supergroup 1361 2020-04-08 15:55 /README.txt
-rw-r--r-- 3 yehua supergroup 17 2020-04-08 20:31 /user.txt
[root@bigdata01 hadoop-3.2.0]# hdfs dfs -cat /user.txt
jack
tom
jessic
下面还需要实现其他功能,对代码进行封装提取
package com.imooc.hdfs;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import java.io.FileInputStream;
import java.io.IOException;
import java.net.URI;
/**
* Java代码操作HDFS
* 文件操作:上传文件、下载文件、删除文件
* Created by xuwei
*/
public class HdfsOp {
public static void main(String[] args) throws Exception{
//创建一个配置对象
Configuration conf = new Configuration();
//指定HDFS的地址
conf.set("fs.defaultFS","hdfs://bigdata01:9000");
//获取操作HDFS的对象
FileSystem fileSystem = FileSystem.get(conf);
put(fileSystem);
}
/**
* 文件上传
* @param fileSystem
* @throws IOException
*/
private static void put(FileSystem fileSystem) throws IOException {
//获取HDFS文件系统的输出流
FSDataOutputStream fos = fileSystem.create(new Path("/user.txt"));
//获取本地文件的输入流
FileInputStream fis = new FileInputStream("D:\\user.txt");
//上传文件:通过工具类把输入流拷贝到输出流里面,实现本地文件上传到HDFS
IOUtils.copyBytes(fis,fos,1024,true);
}
}
下载文件
/**
* 下载文件
* @param fileSystem
* @throws IOException
*/
private static void get(FileSystem fileSystem) throws IOException{
//获取HDFS文件系统的输入流
FSDataInputStream fis = fileSystem.open(new Path("/README.txt"));
//获取本地文件的输出流
FileOutputStream fos = new FileOutputStream("D:\\README.txt");
//下载文件
IOUtils.copyBytes(fis,fos,1024,true);
}
删除文件
/**
* 删除文件
* @param fileSystem
* @throws IOException
*/
private static void delete(FileSystem fileSystem) throws IOException{
//删除文件,目录也可以删除
//如果要递归删除目录,则第二个参数需要设置为true
//如果是删除文件或者空目录,第二个参数会被忽略
boolean flag = fileSystem.delete(new Path("/LICENSE.txt"),true);
if(flag){
System.out.println("删除成功!");
}else{
System.out.println("删除失败!");
}
}
然后到hdfs中验证文件是否被删除,从这里可以看出来/LICENSE.txt文件已经被删除
[root@bigdata01 hadoop-3.2.0]# hdfs dfs -ls /
Found 3 items
-rw-r--r-- 2 root supergroup 22125 2020-04-08 15:55 /NOTICE.txt
-rw-r--r-- 2 root supergroup 1361 2020-04-08 15:55 /README.txt
-rw-r--r-- 3 yehua supergroup 17 2020-04-08 20:31 /user.txt
如果出现很多红色警告
1:pom.xml中增加log4j依赖
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.7.10</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.10</version>
</dependency>
2.resources目录下添加log4j.properties文件
在项目的src\main\resources目录中添加log4j.properties
log4j.properties文件内容如下:
log4j.rootLogger=info,stdout
log4j.appender.stdout = org.apache.log4j.ConsoleAppender
log4j.appender.stdout.Target = System.out
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss,SSS} [%t















 1350
1350











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









