






数据预处理
忽略警告
import warnings warnings.filterwarnings("ignore")
读取数据
df = pd.read_csv(r"D:\统计建模比赛\house_price.tsv", sep='\t', header=0)
跳过错误的行:error_bad_lines=False
adv_data = pd.read_csv(r"D:\国赛\准备国赛资料\多元线性回归数据.xlsx",encoding='ISO-8859-1',error_bad_lines=False)
将数据导出
df.to_csv('I:/SneakerData/intermediateResult/sneaker.csv',encoding='utf_8_sig') #其中encoding可以用来解决中文乱码的问题
保存图片
plt.savefig('out.jpg')
用来对齐读取的表格
from tabulate import tabulate print(tabulate(df, headers='keys', tablefmt='psql',)) # 可以看到较上面相比是更加美观的
用来正常显示中文
matplotlib.rcParams['font.family'] = 'STSong'
用来正常显示负号
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
改变行列里面的信息显示不全的问题
pd.set_option('display.max_rows', 100,'display.max_columns', 1000,"display.max_colwidth",1000,'display.width',1000)
df.iloc[]

输出一列的不同类型数量(分布情况)
print(df['梯户比例'].value_counts())
列出基本信息
df.info()
数据大小
df.shape
检查重复值:
# 检查是否存在重复值 duplicates = df.duplicated() print(duplicates) 重复的行被标记为 True,否则为 False。
删除重复值:
# 删除重复值 df_no_duplicates = df.drop_duplicates() print(df_no_duplicates) 将删除所有重复的行,并返回一个新的 DataFrame df_no_duplicates,其中不包含重复值的行。
检查空值:
df['tk'].isnull().sum()
处理NAN
df.fillna(0)
将特定数据指定为某个值
# 指定NaN值为"电力、煤气及水的生产和供应业" df.iloc[1:11] = df.iloc[1:11].fillna("电力、煤气及水的生产和供应业") # 指定NaN值为"房地行业" df.iloc[12:26] = df.iloc[12:26].fillna("房地行业") # 指定NaN值为"信息技术业 df.iloc[26:] = df.iloc[26:].fillna("信息技术业 ") print(df)
提取特定数据
df[df['梯户比例'] == '暂无数据']#把暂无数据的数据提取出来
删除无效数据
del df['梯户比例']#移除一栏
正则表达式提取信息
由于建筑面积的信息不是数值型,而且建筑面积里含有‘平’这个字,不能直接用于计算
- \d+:匹配0-9中一个及其以上数字
- .:转义,匹配点
- (\d+.\d+)用括号括起来,提取括号中的信息
方法一:
df['建筑面积'] = df['建筑面积'].str.extract('(\d+\.\d+)平', expand =False)
str.replace()
方法一:直接中文替换
data['区域位置'] = data['区域位置'].str.replace('西湖-','')
方法二:用正则表达式替换
df['小区名称']= df['小区名称'].str.replace('[\[\'.\'\]]', '').str.extract('(\D+)')[0]
方法三:连续进行替换(data也是数据集的名字)
data['产权所属'] = data['产权所属'].replace("非共有", 0).replace("共有", 1)
数据类型中转换
df[['建筑面积']] = df[['建筑面积']].astype(float)
建立数据透视表
df2 = df.pivot_table(index = '位置', columns='装修情况', values='均价', fill_value='0')#默认均价,比较出各个地区价格
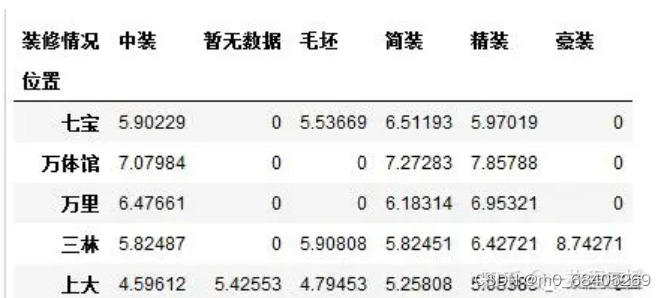
无意义的值转换为缺失值
df['装修情况'] = df['装修情况'].replace('暂无数据',np.NaN)
删除缺失值
df.dropna()
排序
df1 = df.sort_values(by='价格',ascending=False)
分组
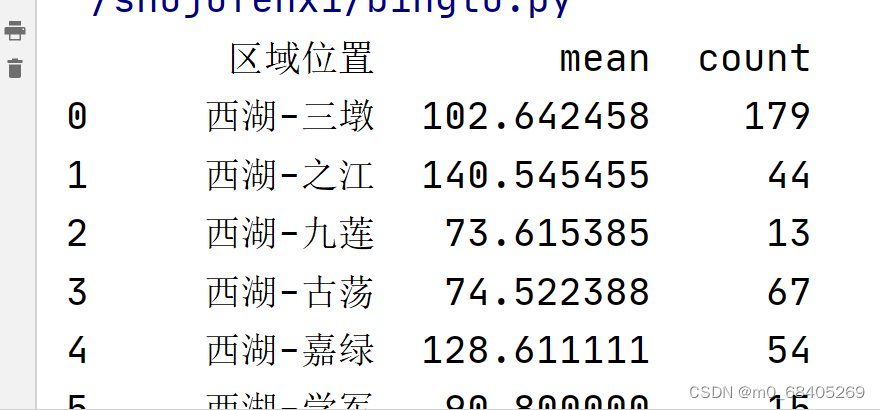
group_district_area = df.groupby('区域位置')['建筑面积'].mean().sort_values(ascending=False).reset_index()
a=df.groupby('区域位置')['建筑面积'].agg(['mean','count'])
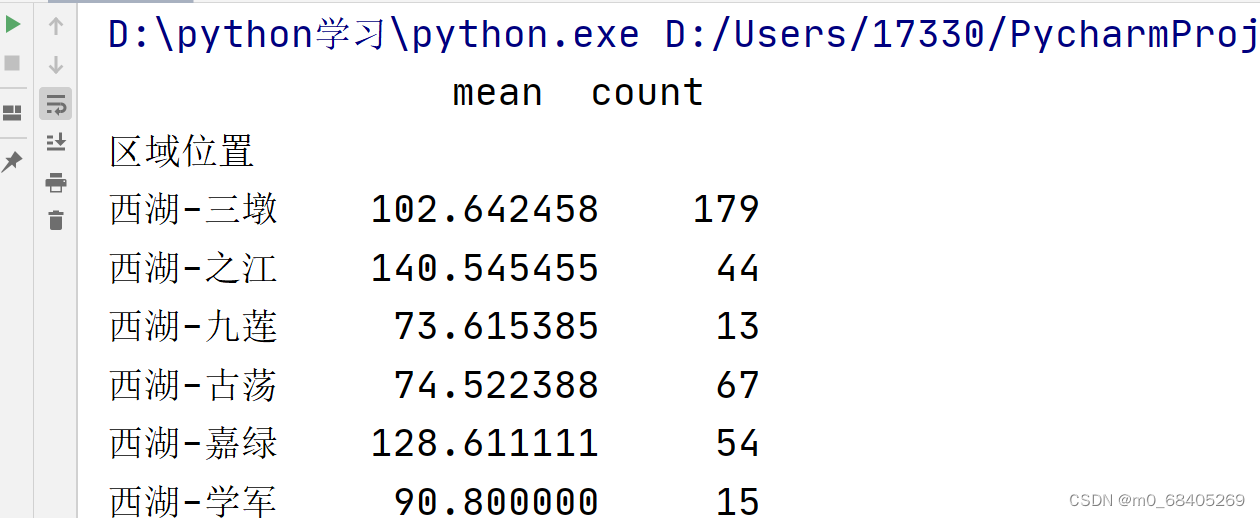
rest_index()
a.reset_index(inplace=True)
用于热编码时,解决一列中类别太多的情况:
def calChaoxiang(df): chaoxiangCol = ['南 北', '南', '东南', '西南', '北 南', '东 南 北', '西北', '西', '东', '南 西 北', '东北', '北', '东 西', '南 北 西', '东 北', '南 北 东'] if df['房屋朝向'] not in chaoxiangCol: return "其他朝向" else: return df['房屋朝向'] data['房屋朝向'] = data.apply(lambda x:calChaoxiang(x), axis=1) 直接对数据运用该函数
np.array()的用法
将其它类型的数据转换成数组
x0 = np.array([0, 3, 5, 7, 9, 11, 12, 13, 14, 15]) y0 = np.array([0, 1.2, 1.7, 2.0, 2.1, 2.0, 1.8, 1.2, 1.0, 1.6])
np.arange()

x1 = np.arange(0, 15, 0.1)#numpy.arange(start, stop, step, dtype) np.linspace(start, stop, num=50, endpoint=True, retstep=False, dtype=None)
.shape()
shape[0]就是读取矩阵第一维度的长度,相当于行数

np.random.randint()的用法
- low: int 生成的数值的最小值(包含),默认为0,可省略。
- high: int 生成的数值的最打值(不包含)。
- size: int or tuple of ints 随机数的尺寸, 默认是返回单个,输入 10 返回 10个,输入 (3,4) 返回的是一个 3*4 的二维数组。(可选)。
numpy.random.randint(low, high=None, size=None, dtype=int)
data=np.random.randint(0,27,(9,3))

np.meshgrid(): 简介来讲就是拉下来,推过去
从X二维矩阵可以看出来:7行3列(M行N列)
每一行显示[-2 0 2]即为x一维矩阵,行数对应于M值。
简单理解,就是把x一维矩阵扩展(向下)成二维矩阵,扩展到y的维数:M。
从Y从X二维矩阵可以看出来,也是7行3列(M行N列)
但是,先把y一维矩阵转置后扩展(向右)成二维矩阵,扩展到x的维数:N。
import numpy as np N = 3 M=7 x = np.linsp
ace(-2, 2, N) y = np.linspace(-3, 3,M) X,Y = np.meshgrid(x,y) print('X'); print(X); print('Y'); print(Y) print(x) print(y)
np.linspace()
x=np.linspace(-1,1,5)#图像仅在-1到1之间显示,显示5个点
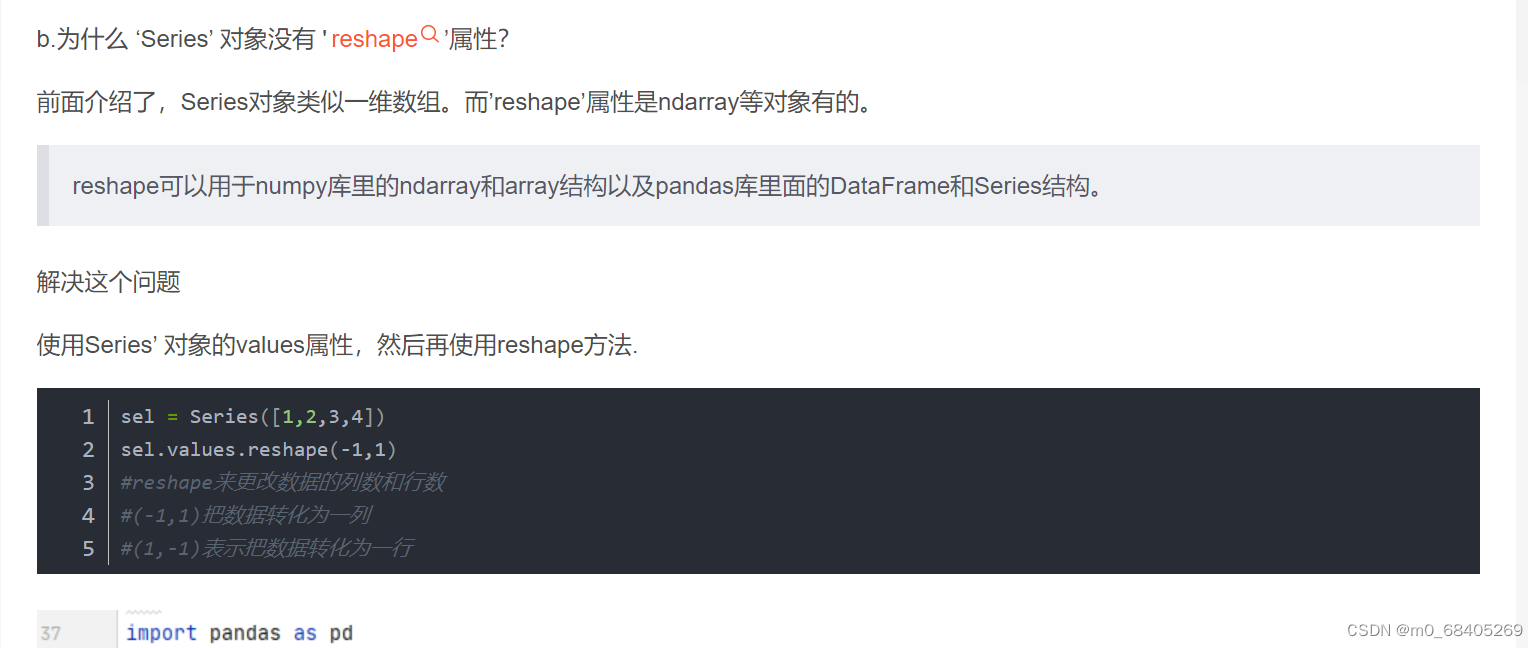
.reshape()


.values.reshape()
.flatten() :把多维将为一维
import numpy as np x = np.array([[1, 3, 4], [2, 3, 5]]) print("x.ravel的输出:", x.ravel()) print("x.flatten的输出:", x.flatten()) x.flatten()[1] =10 print("发生改变时x.ravel的输出:", x) 不会改变原来的数组 x.ravel()[1] = 10 print("发生改变时x.flatten的输出:", x) 会改变原来的数组
数据标准化
连续数据离散化

使用k-means聚类实现数据离散化
import numpy as np import pandas as pd from sklearn.cluster import KMeans from sklearn import preprocessing df=pd.read_excel("D:\统计建模比赛\处理后杭州二手房数据(1).xlsx") df.head(5) data=df.loc[:,'总价'] data_reshape=data.values.reshape(-1,1) print(data_reshape) model_kmeans=KMeans(n_clusters=4,random_state=0) kmeans_result=model_kmeans.fit_predict(data_reshape) print(kmeans_result) df['amount2']=kmeans_result print(df['amount2']) df.to_csv('D:\统计建模比赛\处理后杭州二手房数据(2).csv',encoding='utf_8_sig')
画图
填充cos_y < sin_y的部分
mp.fill_between(x, cos_y, sin_y, cos_y < sin_y, color='dodgerblue', alpha=0.5)
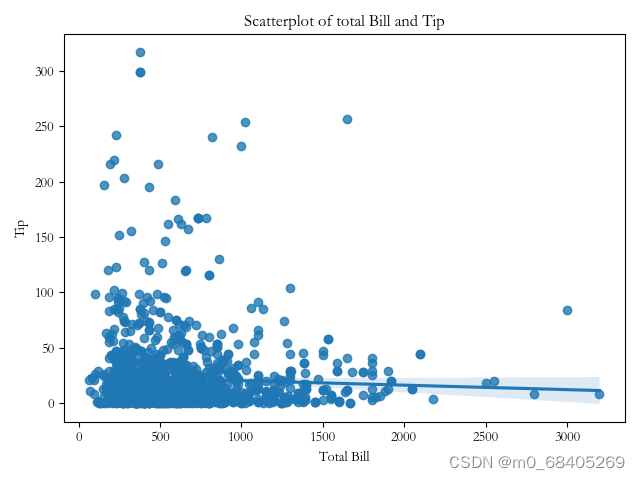
绘制散点图
scatter,ax = plt.subplots() ax = sns.regplot(x = '总价',y='关注度',data=df) ax.set_title('Scatterplot of total Bill and Tip') ax.set_xlabel('Total Bill') ax.set_ylabel('Tip') plt.show()
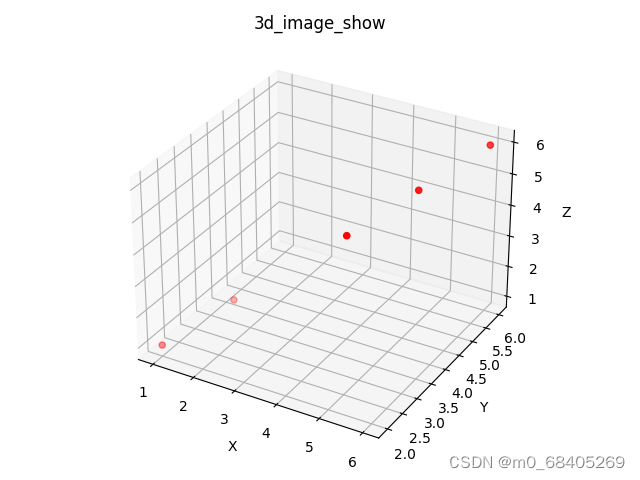
绘制三维散点图
import numpy as np # 用来处理数据 import matplotlib.pyplot as plt x = np.array([1, 2, 4, 5, 6]) y = np.array([2, 3, 4, 5, 6]) z = np.array([1, 2, 4, 5, 6]) ax = plt.subplot(projection='3d') # 创建一个三维的绘图工程 ax.set_title('3d_image_show') # 设置本图名称 ax.scatter(x, y, z, c='r') # 绘制数据点 c: 'r'红色,'y'黄色,等颜色 ax.set_xlabel('X') # 设置x坐标轴 ax.set_ylabel('Y') # 设置y坐标轴 ax.set_zlabel('Z') # 设置z坐标轴 plt.show()
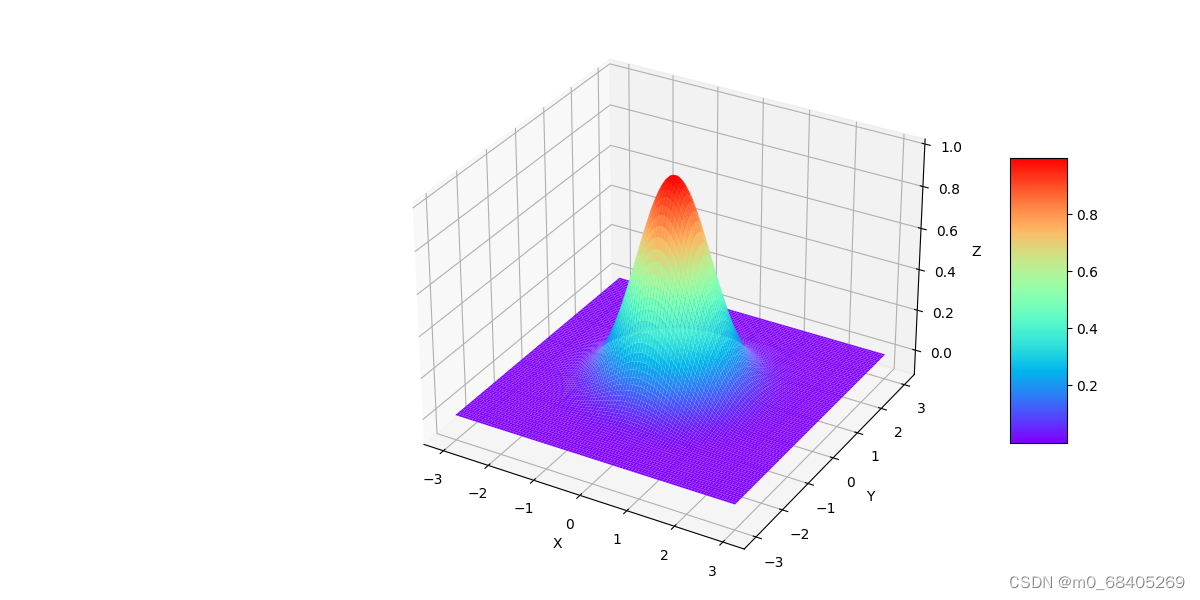
绘制三维图形
import matplotlib .pyplot as plt import numpy as np fig = plt.figure (figsize= (12,6)) # 使用.axes方法告诉告诉代码需要返回3d图形 ax = plt.axes(projection="3d") # 生成为x y 生成等差数组(在-3,3内取100个点) 计算之后为对z使用.exp方法计算e的-X**2-Y**2次方 X,Y = np.mgrid[-3:3:100j,-3:3:100j] Z = np.exp(-X**2-Y**2) surf = ax.plot_surface(X,Y,Z, rstride = 1, cstride= 1, cmap = plt.get_cmap('rainbow') ) # 对z进行限制 ax.set_zlim(-0.1,1) ax.set_xlabel("X");ax.set_ylabel("Y");ax.set_zlabel("Z") fig.colorbar(surf,shrink=0.5,aspect=5) plt.show()
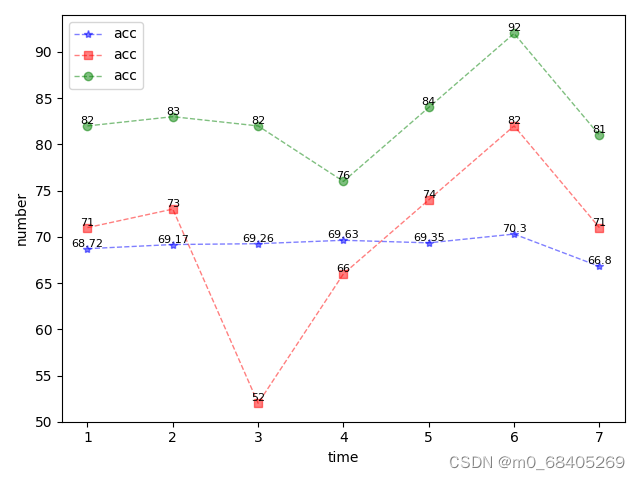
绘制折线图
import matplotlib.pyplot as plt import numpy as np # 数据 x_axis_data = [1, 2, 3, 4, 5, 6, 7] y_axis_data1 = [68.72, 69.17, 69.26, 69.63, 69.35, 70.3, 66.8] y_axis_data2 = [71, 73, 52, 66, 74, 82, 71] y_axis_data3 = [82, 83, 82, 76, 84, 92, 81] # 画图 plt.plot(x_axis_data, y_axis_data1, 'b*--', alpha=0.5, linewidth=1, label='acc') # ' plt.plot(x_axis_data, y_axis_data2, 'rs--', alpha=0.5, linewidth=1, label='acc') plt.plot(x_axis_data, y_axis_data3, 'go--', alpha=0.5, linewidth=1, label='acc') ## 设置数据标签位置及大小(plt.text(a,b)设置标签a,b加标签的位置) for a, b in zip(x_axis_data, y_axis_data1): plt.text(a, b, str(b), ha='center', va='bottom', fontsize=8) # ha='center', va='top' for a, b1 in zip(x_axis_data, y_axis_data2): plt.text(a, b1, str(b1), ha='center', va='bottom', fontsize=8) for a, b2 in zip(x_axis_data, y_axis_data3): plt.text(a, b2, str(b2), ha='center', va='bottom', fontsize=8) plt.legend() # 显示上面的label plt.xlabel('time') plt.ylabel('number') # accuracy # plt.ylim(-1,1)#仅设置y轴坐标范围 plt.show()
绘制等高线图
import matplotlib.pyplot as mp import numpy as np # 等高线图 n = 1000 x,y = np.meshgrid(np.linspace(-3,3,n),np.linspace(-3,3,n)) print(x,'--x') print(y,'--y') z = (1 - x / 2 + x**5 + y**3) * np.exp(-x**2 - y**2) # 上述代码得到二维数组x、y直接组成坐标点矩阵 # z为通过每个坐标的x与y计算而得的高度值(模拟采集的海拔高度) # 画图 mp.figure('Contour',facecolor='lightgray') mp.title('Contour',fontsize=16) mp.grid(linestyle=':') # 线型,虚线是负的,实线是正的 cntr = mp.contour(x,y,z,8,colors='black',linewidth=0.5) # 设置等高线上的高度标签文本 mp.clabel(cntr,fmt='%.2f',inline_spacing=2,fontsize=8) mp.contourf(x,y,z,8,camp='jet') mp.show()
matplotlib.pyplot常用方法
https://www.cnblogs.com/AloneDKN/p/11466119.html
plt.subplot:多个图形在一个页面显示时使用
plt.subplot(1, 3, 1)
隐藏坐标轴
plt.axis('off')
jupyter使用
如何找到jupyter的路径,在里面下载库
Jupyter的工作目录(根目录)位置_查看jupyter文件位置_浅挚灬半离兮的博客-CSDN博客
如何在jupyter里面安装库
! pip install 库名
图像数据处理
读取图像数据
from PIL import Image import numpy as np image= Image.open(r'C:\Users\OneDrive\桌面\不对劲不对劲9276.jpg') image.show()
将矩阵保存为图像
# 将处理后的图像转换为PIL对象 output_image = Image.fromarray(image_data.astype(np.uint8)) # 保存图像文件 output_image.save("output.jpg")
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









