






咱们现在要爬取的是当当网中出版社为清华大学,书名中包含数据采集的书本信息,包含书名、作者、价格、日期
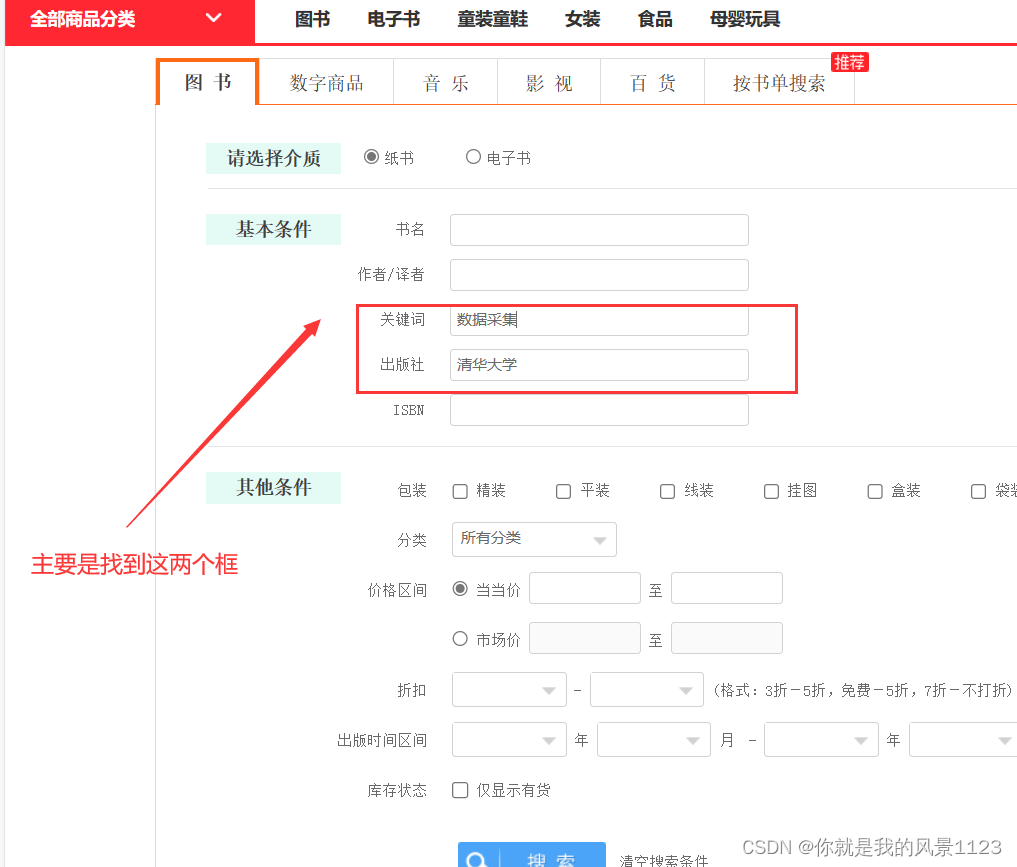
1.你首先得观察搜索页面,在检查中找到下面两个文本框的html源代码,通过给文本框输入‘2数据采集’,‘清华大学’找到我们需要搜索结果的url,代码在下面
def build_form(press_name, keyword):
header = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Trident/7.0; rv:11.0) like Gecko'}
res = requests.get('http://search.dangdang.com/advsearch', headers=header)
res.encoding = 'GB2312'
soup = BeautifulSoup(res.text, 'html.parser')
# 定位input标签
input_tag_name_press = ''
input_tag_name_keyword = ''
conditions = soup.select('.box2 > .detail_condition > label')
print('共找到%d项基本条件,正在寻找input标签' % len(conditions))
for item in conditions:
text = item.select('span')[0].string
if text == '出版社':
input_tag_name_press = item.select('input')[0].get('name')
print('已经找到出版社input标签,name:', input_tag_name_press)
elif text == '关键词':
input_tag_name_keyword = item.select('input')[0].get('name')
print('已经找到关键词input标签,name:', input_tag_name_keyword)
# 拼接url
keywords = {
'medium': '01',
input_tag_name_press: press_name.encode('gb2312'),
input_tag_name_keyword: keyword.encode('gb2312'),
'category_path': '01.00.00.00.00.00',
'sort_type': 'sort_pubdate_desc'
}
url = 'http://search.dangdang.com/?'
url += urllib.parse.urlencode(keywords)
print('入口地址:%s' % url)
return url
这是获得url的函数 ,结果如下

2.获得完整url后我们开始进行数据的爬取,将爬取的数据都保存在一个字典中,代码如下
def get_info(entry_url):
header = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Trident/7.0; rv:11.0) like Gecko'}
res = requests.get(entry_url, headers=header)
res.encoding = 'GB2312'
# 这里用lxml解析会出现内容缺失
soup = BeautifulSoup(res.text, 'html.parser')
# 获取页数
page_num = int(soup.select('.data > span')[1].text.strip('/'))
print('共 %d 页待抓取, 这里只测试采集1页' % page_num)
page_num = 1 # 这里只测试抓1页
page_now = '&page_index='
# 书名 作者 价格 出版时间
books_title = []
books_author=[]
books_price = []
books_date = []
for i in range(1, page_num + 1):
now_url = entry_url + page_now + str(i)
print('正在获取第%d页,URL:%s' % (i, now_url))
res = requests.get(now_url, headers=header)
soup = BeautifulSoup(res.text, 'html.parser')
# 获取书名
tmp_books_title = soup.select('ul.bigimg > li[ddt-pit] > a')
for book in tmp_books_title:
books_title.append(book.get('title'))
# 获取作者
tmp_books_author = soup.select('ul.bigimg > li[ddt-pit] > p.search_book_author > span > a')
for author_tag in tmp_books_author:
#获取文本
author_name = author_tag.get_text(strip=True)
# 不让等于 "清华大学出版社"
if author_name != "清华大学出版社":
books_author.append(author_name)
# 获取价格
tmp_books_price = soup.select('ul.bigimg > li[ddt-pit] > p.price > span.search_now_price')
for book in tmp_books_price:
books_price.append(book.text)
# 获取出版日期
tmp_books_date = soup.select('ul.bigimg > li[ddt-pit] > p.search_book_author > span')
for book in tmp_books_date[1::3]:
books_date.append(book.text[2:])
books_dict = {'title': books_title,'author':books_author, 'price': books_price, 'date': books_date}
return books_dict3.将爬取好的数据保存在本地txt文件中,我的是清华大学出版社.txt,代码如下
def save_info(file_dir, press_name, books_dict):
res = ''
try:
for i in range(len(books_dict['title'])):
res += (str(i + 1) + '.' + '书名:' + books_dict['title'][i] + '\r\n' +
'作者:'+ books_dict['author'][i] + '\r\n'
'价格:' + books_dict['price'][i] + '\r\n' +
'出版日期:' + books_dict['date'][i] + '\r\n'
)
except Exception as e:
print('保存出错')
print(e)
traceback.print_exc()
finally:
file_path = file_dir + os.sep + press_name + '.txt'
f = open(file_path, "wb")
f.write(res.encode("utf-8"))
f.close()
return4.开始爬取数据主函数如下,其中press_name和keyword就是你想爬取的信息关键词,例如我的就是‘清华大学出版社’,‘数据采集’
def start_spider(press_name, keyword,saved_file_dir):
print('------ 开始抓取 %s包含%s的书本 ------' % (press_name, keyword))
press_page_url = build_form(press_name,keyword)
books_dict = get_info(press_page_url)
save_info(saved_file_dir, press_name, books_dict)
print('------- 出版社: %s %s的书本信息抓取完毕 -------' % (press_name,keyword))
return
if __name__ == '__main__':
# 出版社名列表所在文件路径
# 抓取信息保存路径
saved_file_dir = r'D:\python\pythonProject'
# 启动
press_name = '清华大学出版社'
keyword = '数据采集'
start_spider(press_name, keyword, saved_file_dir)
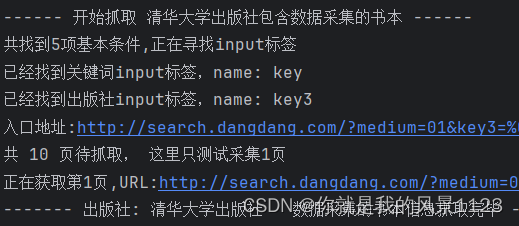
5.结果演示

若是运行不出来,把所有代码复制即可!!!

















 959
959

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









