






浅看了一下BERT的代码,相当于没看。
BERT
论文地址:https://arxiv.org/pdf/1810.04805
BERT只使用到了encoder架构(同时查看句子中的所有单词),base_bert使用了12个encoder堆叠。创新在输入和loss阶段。
整体而言,BERT使用了两种训练策略:
- 掩码预测模型(MLM)
- 预测下一句(NSP)
input = token emb + segment emb +position emb
对于这个token emb,使用的是WordPiece分词方法。
对于这个segment emb,主要是为了区分两个句子,句子A的向量值标为0,句子B的向量值标为1.
对于这个position emb,与Transformer不同的是这是一个可学习训练的参数,最大长度固定之后不能外推,只能处理那么长的句子。比如最大长度定为了512,编码维度为768,那么初始化为一个512*768的向量,最多能处理长度为512的句子。如果还想更长就只能将超出的向量随机初始化再进行微调。
MLM
主要可以理解句子内的上下文。
这部分主要是在预训练的过程中对每一个输入序列中的一部分单词mask一下,然后训练模型根据周围单词提供的上下文推测这个被mask的词是什么。
这就导致当BERT用于下游位置微调的时候是没有[mask]标志的,预训练和微调之间不匹配,所以当训练的时候只将80%*15%进行替换为[mask],10%*15%的概率替换为其他单词,剩下10%的句子不做任何调整。但也只能缓解这个问题,而且只有15%被预测,导致模型收敛速度很慢。
NSP
主要可以理解句子对之间的联系或关系。
预测第二句是否与第一句相连。训练的数据是50%为顺序相连的正样本,50%的数据为随机选择的句子。
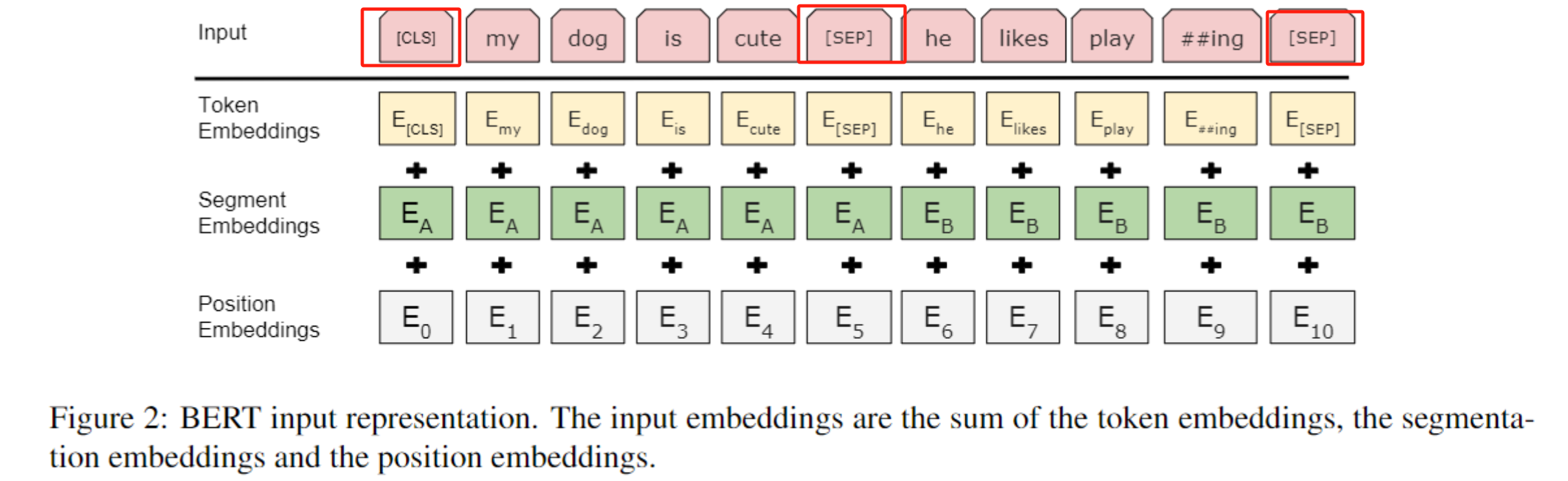
传入两个句子如上图。如上图,[cls]是每一个输入的标志,[sep]是两个句子之间的分隔。
分词
(因为BERT使用了WordPiece所以补充一章分词的内容。)
分词主要是为了将输入的文本拆分成一个个词元方便输入学习的任务。分词主要是基于三种维度进行的:词粒度(之前的第一版transformer,将词按照空格来区分,中文的话使用jieba分词工具来区分)、字符粒度(英文按照26个字母,中文按照5000多个常用字,另外再补充一些常用的字符)、子词粒度(subword介于上述两者之间)
subward
BPE
BPE主要是基于26个字母和其他符号进行合并到达设定的合并次数。
首先将句子中的每一个字母和字母出现的频率拆出来:
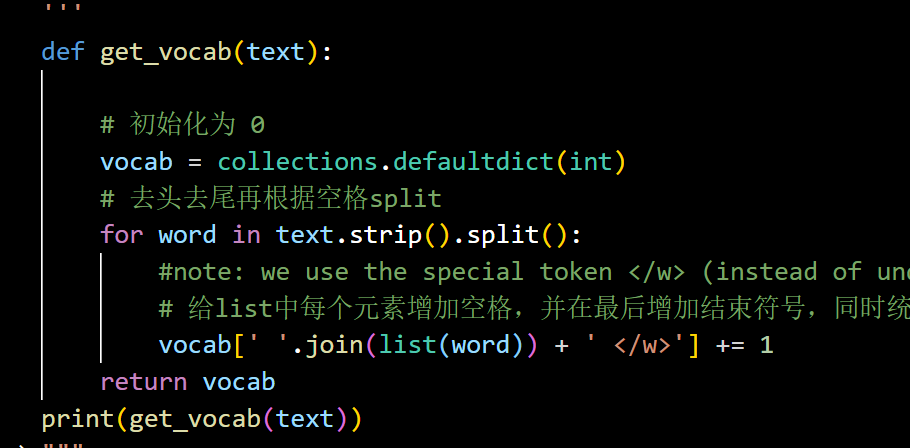
然后基于拆出来的字母-次数表进行合并,把两个一起出现最多的合并为一个。
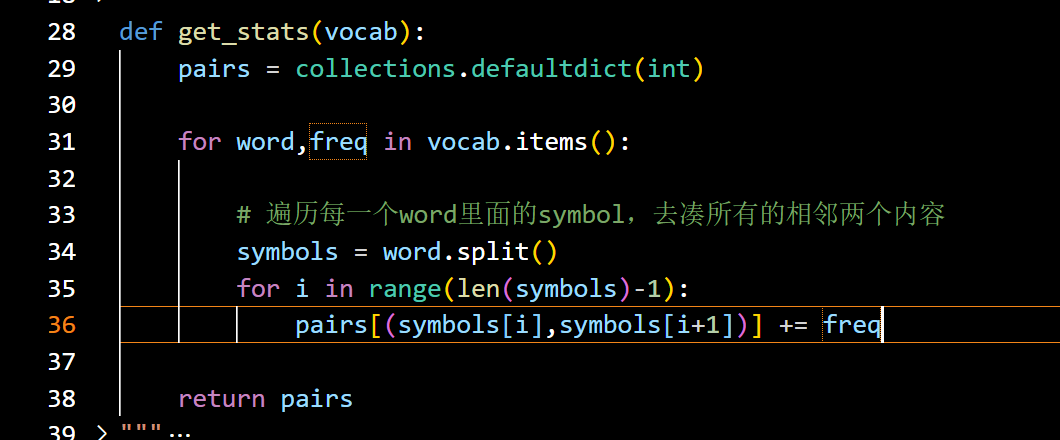
其中对于每一个词都会在结束的地方增加</w>。主要是为了区分出哪些是后缀。

缺点:
- 分词结果有很多,可能会导致有歧义。
- 很依赖训练语料。
- 无法得到不同形态的单词之间的关联性。
BBPE
和BPE的合并逻辑是一样的,但是BBPE不是看两个字母合并,而是合并两个字节。这样的话可以更好的扩展到多语言、动态处理未登录词,迁移能力更强。而且会让词表大为减少。
WordPiece
相较于BPE,wordpiece是根据互信息来合并的。选择互信息最大的两个子词合并。


缺点是计算复杂度高,而且也很受语料库的影响。
ULM
首先初始化一个大的词表(使用BPE或者别的什么)然后通过删除对损失影响小的subword来缩小词表。总体而言,是希望找到整个句子概率最大的子词序列。不同于BPE或WordPiece的确定性分词,ULM会保留多个可能的分词结果,并为每种分词方式计算概率,最终输出概率最高的候选分词。
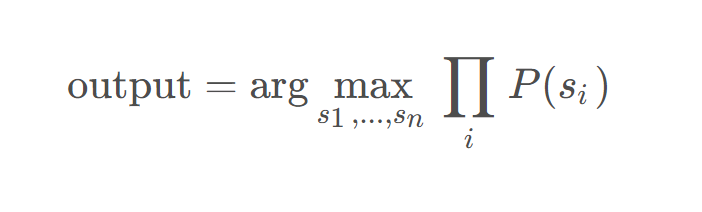
相较于之前的方法这种方法对语料库的要求降低了,但是计算量上升了。
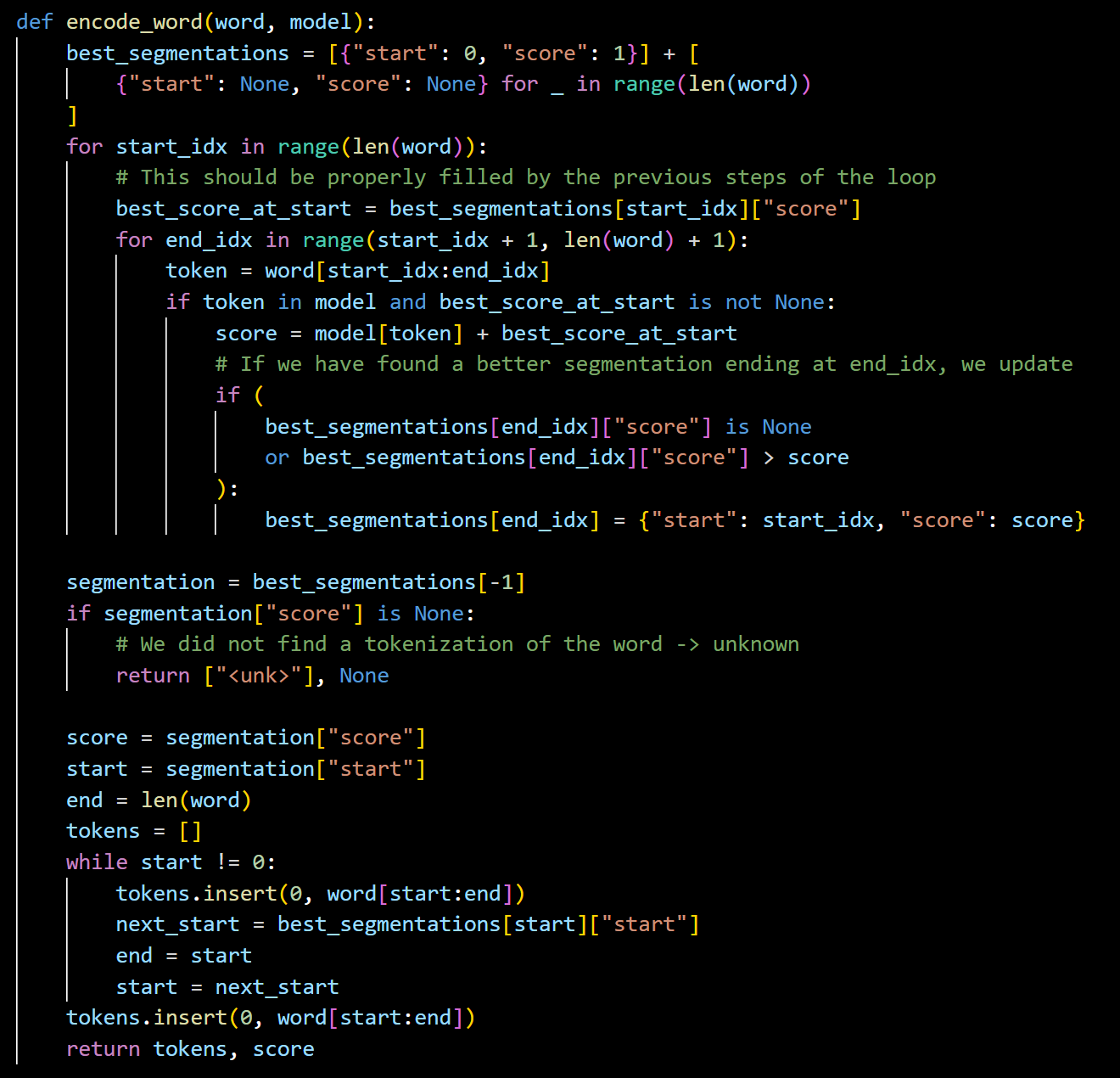
上图是基于维特比算法计算的ULM代码。总体而言就是先对每一个词进行分词,计算每一种存在的分词形式的损失值,找到最优解。使用的时候会控制字符和子词的频率,防止过拟合。(大模型使用的一般30000-50000.)

使用动态规划算法,一步步调整end_idx找最优解(减少暴力搜索中的重复计算,将时间复杂度降低)。总之ULM的算法的优点就是考虑了不同分词的可能。
今天最大的收获是知道了原来有调试控制台,不需要一直自己写print...



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









