










🌈hello,你好鸭,我是Ethan,一名不断学习的码农,很高兴你能来阅读。
✔️目前博客主要更新Java系列、项目案例、计算机必学四件套等。
🏃人生之义,在于追求,不在成败,勤通大道。加油呀!
🔥个人主页:Ethan Yankang
🔥专栏:mybatis||必知必会工具集
🔥本篇概览:mybatis基本使用、Mapper.xml映射文件、核心架构、一二级缓存、EhCache专业缓存使用
文章目录
Mybatis
一、概述
1.mybatis是什么?有什么特点?
它是一款半自动的ORM持久层框架,具有较高的SQL灵活性,支持高级映射(一对一,一对多),动态SQL,延迟加载和缓存等特性,但它的数据库无关性较低
2.什么是ORM?
Object Relation Mapping,对象关系映射。对象指的是Java对象,关系指的是数据库中的关系模型,对象关系映射,指的就是在Java对象和数据库的关系模型之间建立一种对应关系,比如用一个Java的Student类,去对应数据库中的一张student表,类中的属性和表中的列一一对应。Student类就对应student表,一个Student对象就对应student表中的一行数据
3.为什么mybatis是半自动的ORM框架?
用mybatis进行开发,需要手动编写SQL语句。而全自动的ORM框架,如hibernate,则不需要编写SQL语句。用hibernate开发,只需要定义好ORM映射关系,就可以直接进行CRUD操作了。由于mybatis需要手写SQL语句,所以它有较高的灵活性,可以根据需要,自由地对SQL进行定制,也因为要手写SQL,当要切换数据库时,SQL语句可能就要重写,因为不同的数据库有不同的方言(Dialect),所以mybatis的数据库无关性低。虽然mybatis需要手写SQL,但相比JDBC,它提供了输入映射和输出映射,可以很方便地进行SQL参数设置,以及结果集封装。并且还提供了关联查询和动态SQL等功能,极大地提升了开发的效率。并且它的学习成本也比hibernate低很多
4.为什么需要 MyBatis?
传统的弊病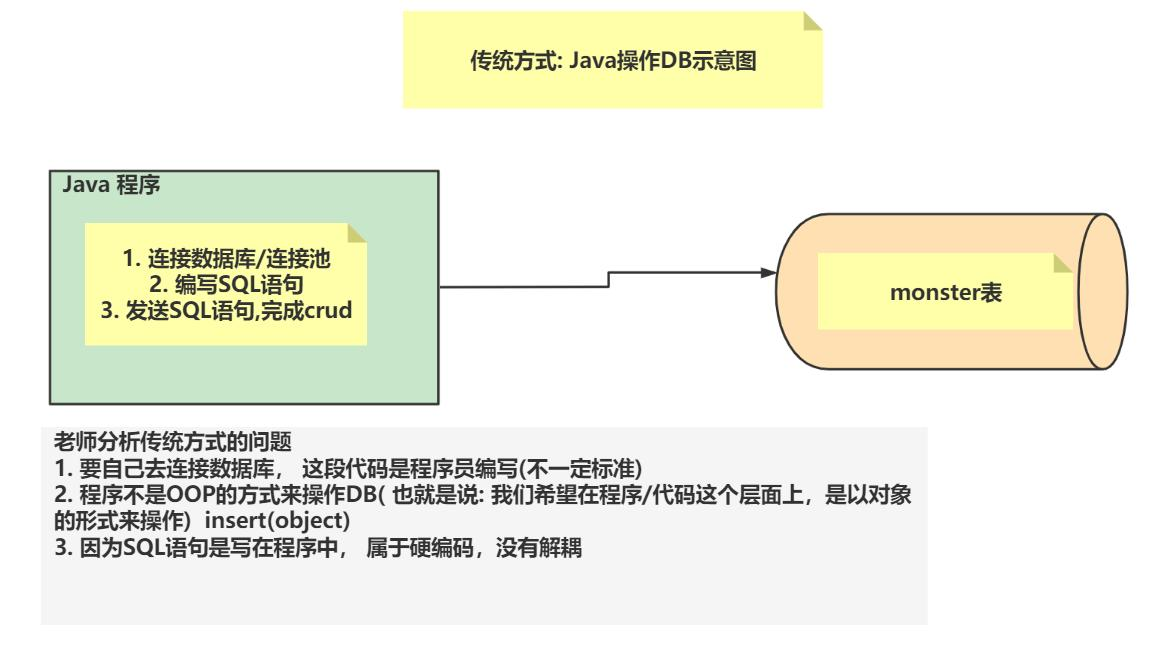
引出 MyBatis
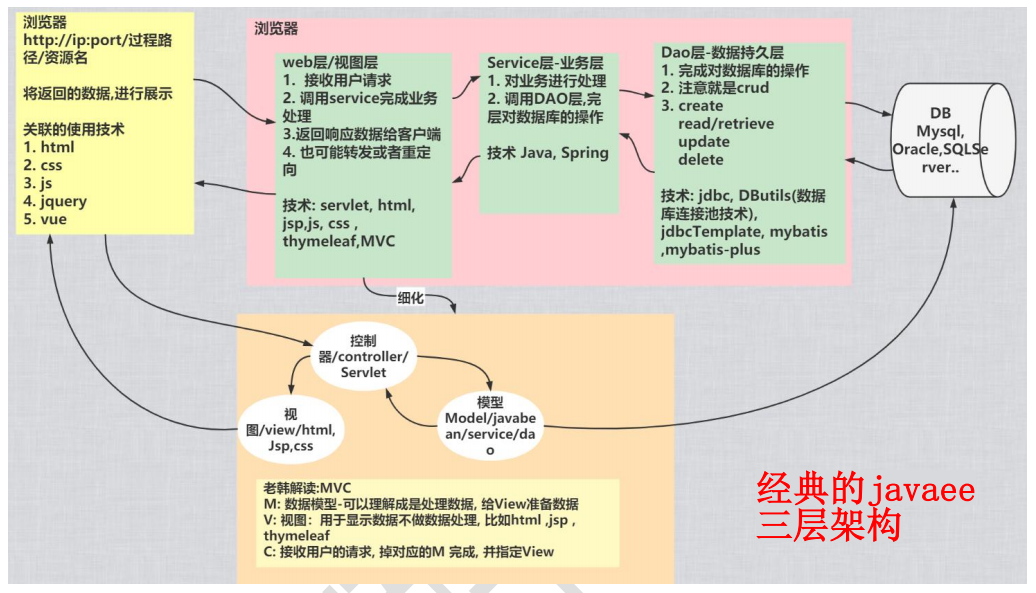

5.MyBatis 工作示意图

二、快速入门
- 创建 mybatis 数据库 - monster 表
CREATE DATABASE `mybatis` CREATE TABLE `monster` (
`id` INT NOT NULL AUTO_INCREMENT, `age` INT NOT NULL, `birthday` DATE DEFAULT NULL, `email` VARCHAR(255) NOT NULL , `gender` TINYINT NOT NULL, `name` VARCHAR(255) NOT NULL, `salary` DOUBLE NOT NULL,
PRIMARY KEY (`id`)
) CHARSET=utf8
- 创建 maven 项目, 方便项目需要 jar 包管理

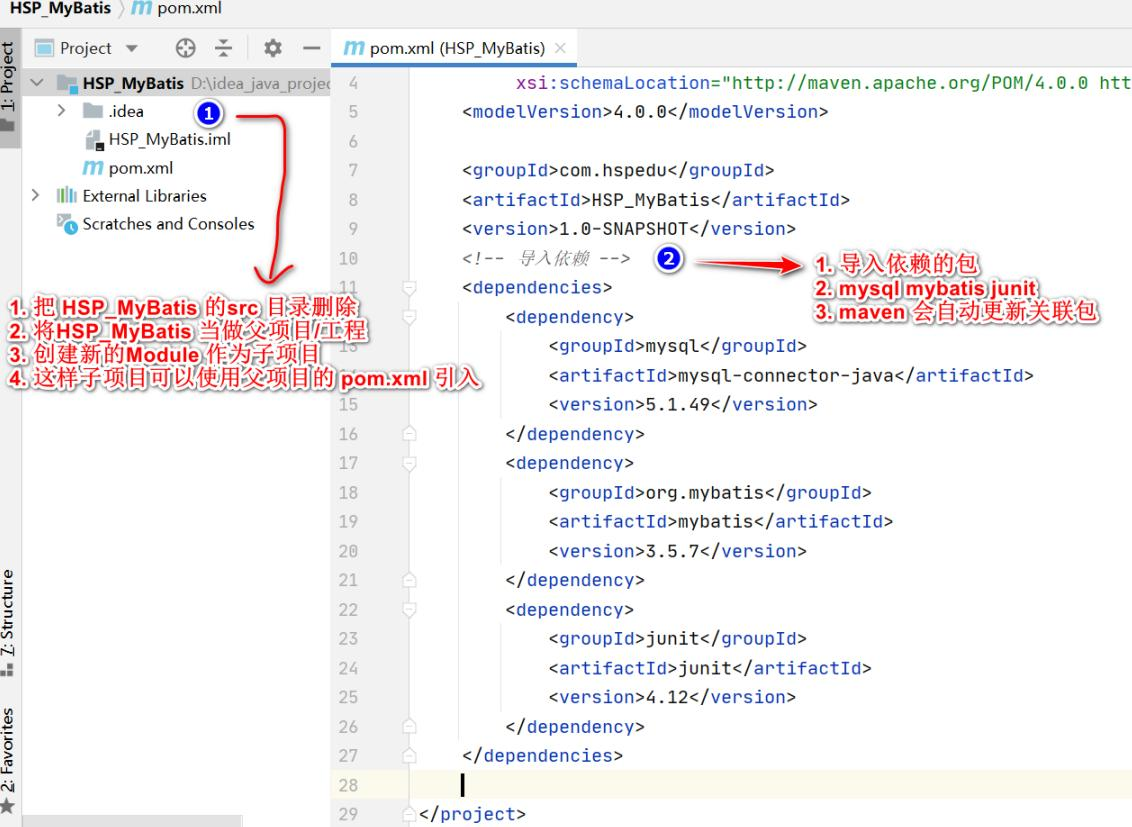
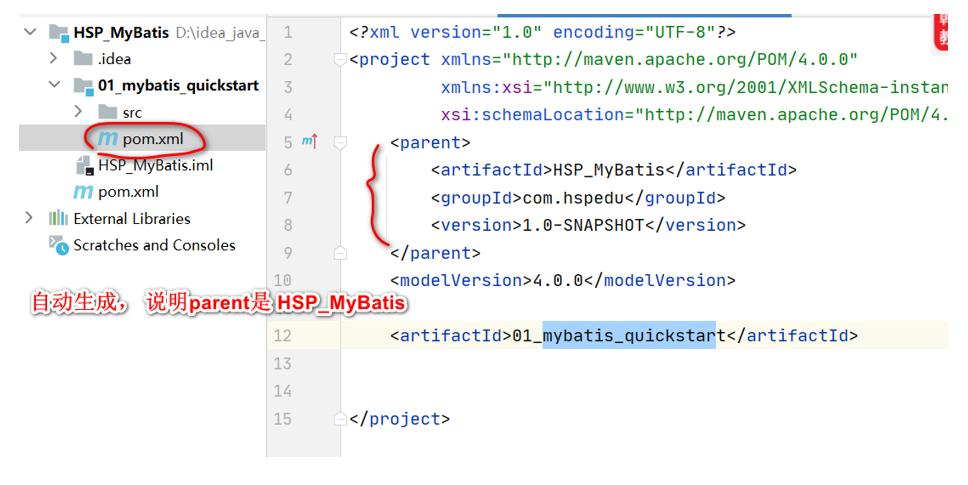
说明: 将 D:\idea_java_projects\HSP_MyBatis\pom.xml 作为父项目 pom.xml 引入相关依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0
http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.hspedu</groupId>
<artifactId>HSP_MyBatis</artifactId>
<packaging>pom</packaging>
<version>1.0-SNAPSHOT</version>
<!-- 导入依赖 -->
<dependencies>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.49</version>
</dependency>
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis</artifactId>
<version>3.5.7</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>


3. 创建 resources/mybatis-config.xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<environments default="development">
<environment id="development">
<transactionManager type="JDBC"/>
<dataSource type="POOLED">
<property name="driver" value="com.mysql.jdbc.Driver"/>
<property name="url"
value="jdbc:mysql://127.0.0.1:3306/mybatis?useSSL=true&
useUnicode=true&characterEncoding=UTF-8"/>
<property name="username" value="root"/>
<property name="password" value="hsp"/>
</dataSource>
</environment>
</environments>
</configuration>
- 创 建java\com\hspedu\entity\Monster.java
package com.hspedu.entity;
import java.util.Date;
/**
* @author 韩顺平|
* @version 1.0
*/
//老韩解读
//1. 一个普通的 Pojo 类
//2. 使用原生态的 sql 语句查询结果还是要封装成对象
//3. 要求大家这里的实体类属性名和表名字段保持一致。
public class Monster {
private Integer id;
private Integer age;
private String name;
private String email;
private Date birthday;
private double salary;
private Integer gender;
public Monster() {
}
public Monster(Integer id, Integer age, String name, String email, Date birthday, double
salary, Integer gender) {
this.id = id;
this.age = age;
this.name = name;
this.email = email;
this.birthday = birthday;
this.salary = salary;
this.gender = gender;
}
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getEmail() {
return email;
}
public void setEmail(String email) {
this.email = email;
}
public Date getBirthday() {
return birthday;
}
public void setBirthday(Date birthday) {
this.birthday = birthday;
}
public double getSalary() {
return salary;
}
public void setSalary(double salary) {
this.salary = salary;
}
public Integer getGender() {
return gender;
}
public void setGender(Integer gender) {
this.gender = gender;
}
@Override
public String toString() {
return "Monster{" +
"id=" + id +
", age=" + age +
", name='" + name + '\'' +
", email='" + email + '\'' +
", birthday=" + birthday +
", salary=" + salary +
", gender=" + gender +
'}';
}
}
- 创 建java\com\hspedu\mapper\MonsterMapper.java
package com.hspedu.mapper;
import com.hspedu.entity.Monster;
import org.apache.ibatis.annotations.Param;
import java.util.List;
import java.util.Map;
/**
* @author 韩顺平
* @version 1.0
*/
public interface MonsterMapper {
//添加方法
public void addMonster(Monster monster);
}
- 创 建java\com\hspedu\mapper\MonsterMapper.xml
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<!-- mapper: 表 示 一 个 映 射 器 , 文
档:https://mybatis.org/mybatis-3/zh/sqlmap-xml.html#insert_update_and_delete
1. namespace="com.hspedu.mapper.MonsterMapper" 说明本 mapper.xml 文件是用来 映射管理 MonsterMapper 接口
,主要是去实现 MonsterMapper 接口声明方法
2. select: 实现一个查询操作 insert:表示一个添加操作
3. id="addMonster" 表示 MonsterMapper 接口 的方法名
4. resultType="xx" 返回的结果类型,如果没有就不需要写
5. parameterType="com.hspedu.entity.Monster" 表示该方法输入的参数类型
6. (age,birthday,email,gender,name,salary) 表的字段名
7. #{age},#{birthday},#{email},#{gender},#{name},#{salary} 是实体类 Monster 的属性名
-->
<mapper namespace="com.hspedu.mapper.MonsterMapper">
<!--没有在 mybatis-config.xml 指定 typealiases 时,需要给 Monster 指定全类名
<insert id="addMonster" parameterType="com.hspedu.entity.Monster"-->
<!-- useGeneratedKeys="true" keyProperty="id"-->
<!-- >-->
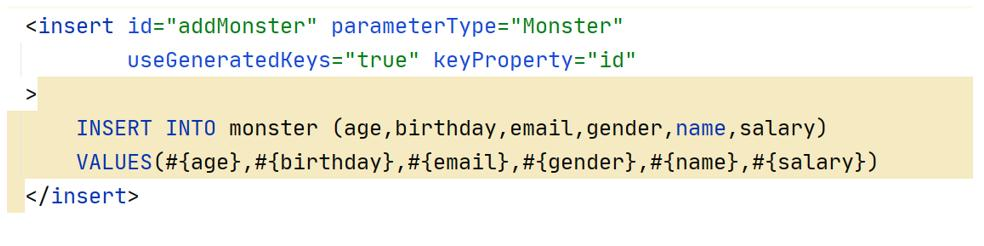
<insert id="addMonster" parameterType="com.hspedu.entity.Monster" useGeneratedKeys="true" keyProperty="id" >
INSERT INTO monster (age,birthday,email,gender,name,salary)
VALUES(#{age},#{birthday},#{email},#{gender},#{name},#{salary})
</insert>
</mapper>
- 修 改main\resources\mybatis-config.xml
</environments>
<mappers>
<!-- 这里会引入(注册)我们的 Mapper.xml 文件 -->
<mapper resource="com/hspedu/mapper/MonsterMapper.xml"/>
</mappers>
- 创 建 工 具 类java\com\hspedu\util\MyBatisUtils.java
package com.hspedu.util;
import org.apache.ibatis.io.Resources;
import org.apache.ibatis.session.SqlSession;
import org.apache.ibatis.session.SqlSessionFactory;
import org.apache.ibatis.session.SqlSessionFactoryBuilder;
import java.io.IOException;
import java.io.InputStream;
/**
* @author 韩顺平
* @version 1.0
韩顺平 Java 工程师
*/
public class MyBatisUtils {
private static SqlSessionFactory sqlSessionFactory;
static {
try {
//使用 mybatis 第一步:获取 sqlSessionFactory 对象
String resource = "mybatis-config.xml";
InputStream inputStream = Resources.getResourceAsStream(resource);
sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
} catch (IOException e) {
e.printStackTrace();
}
}
/**
* 老韩解读
* 1. 获得 SqlSession 的实例
* 2. SqlSession 提供了对数据库执行 SQL 命令所需的所有方法。
* 3. 通过 SqlSession 实例来直接执行已映射的 SQL 语句
* @return
*/
public static SqlSession getSqlSession() {
return sqlSessionFactory.openSession();
}
}
- 创建并测试src\test\java\com\hspedu\mapper\MonsterMapperTest.java
package com.hspedu.mapper;
import com.hspedu.entity.Monster;
import com.hspedu.util.MyBatisUtils;
import org.apache.ibatis.io.Resources;
import org.apache.ibatis.session.SqlSession;
import org.apache.ibatis.session.SqlSessionFactoryBuilder;
import org.junit.Before;
import org.junit.Test;
import java.io.InputStream;
import java.util.*;
/**
* @author 韩顺平
韩顺平 Java 工程师
* @version 1.0
*/
public class MonsterMapperTest {
//这个是 Sql 会话,通过它可以发出 sql 语句
private SqlSession sqlSession;
private MonsterMapper monsterMapper;
@Before
public void init() throws Exception {
//通过 SqlSessionFactory 对象获取一个 SqlSession 会话
sqlSession = MyBatisUtils.getSqlSession();
//获取 MonsterMapper 接口对象, 该对象实现了 MonsterMapper
monsterMapper = sqlSession.getMapper(MonsterMapper.class);
System.out.println(monsterMapper.getClass());
}
@Test
public void addMonster() {
for (int i = 0; i < 1; i++) {
Monster monster = new Monster();
monster.setAge(100 + i); monster.setBirthday(new Date());
monster.setEmail("tn@sohu.com");
monster.setGender(1); monster.setName("松鼠精" + i);
monster.setSalary(9234.89 + i * 10);
monsterMapper.addMonster(monster);
System.out.println("刚刚添加的对象的 id=" + monster.getId());
}
//增删改,需要提交事务
if (sqlSession != null) {
sqlSession.commit();
sqlSession.close();
}
System.out.println("保存成功!");
}
}
-
测试,看看是否可以添加成功, 这时会出现找不到 Xxxxmapper.xml 错误, 分析了原因

-
解决找不到 Mapper.xml 配置文件问题, 老韩提示:如果顺利,你会很快解决,不顺利,
你 会 干 到 怀 疑 人 生

//在父工程的 pom.xml 加入 build 配置
</dependencies>
<!--在 build 中配置 resources,来防止我们资源导出失败的问题
老韩解读:
1. 不同的 idea/maven 可能提示的错误不一样
2. 不变应万变,少什么文件,就增加相应配置即可
-->
<build>
<resources>
<resource>
<directory>src/main/java</directory>
<includes>
韩顺平 Java 工程师
<include>**/*.xml</include>
</includes>
</resource>
<resource>
<directory>src/main/resources</directory>
<includes>
<include>**/*.xml</include>
<include>**/*.properties</include>
</includes>
</resource>
</resources>
</build>


12. 修改 MonsterMapper.java, 增加方法接口
//根据 id 删除一个 Monster
public void delMonster(Integer id);
- 修改 MonsterMapper.xml, 实现方法接口
<delete id="delMonster" parameterType="Integer">
DELETE FROM monster
WHERE id=#{id}
</delete>
- 完 成 测 试 , 修 改
D:\idea_java_projects\HSP_MyBatis\01_mybatis_quickstart\src\test\java\com\hspedu\mapper\MonsterMapperTest.java, 增加测试方法
//测试 mybatis 删除功能
@Test
public void delMonster() {
monsterMapper.delMonster(2);
if (sqlSession != null) {
sqlSession.commit();
sqlSession.close();
}
System.out.println("删除 ok");
}
- 修改 MonsterMapper.java, 增加方法接口
//修改 Monster
public void updateMonster(Monster monster);
//查询-根据 id
public Monster getMonsterById(Integer id);
//查询所有的 Monster
public List<Monster> findAllMonster();
- 修改 MonsterMapper.xml, 实现方法接口
- 为了配置方便,在 mybatis-config.xml 配置 Monster 的别名
<configuration>
<typeAliases>
<!-- 为某个 mapper 指定一个别名, 下面可以在 XxxxxMapper.xml 做相应简化处理
-->
<typeAlias type="com.hspedu.entity.Monster" alias="Monster"/>
</typeAliases>
- 修改 MonsterMapper.xml, 实现方法接口, 可以使用 Monster 别名了.
<update id="updateMonster" parameterType="Monster">
UPDATE monster SET age=#{age}, birthday=#{birthday}, email = #{email}, gender= #{gender}, name=#{name}, salary=#{salary} WHERE id=#{id}
</update>
<select id="getMonsterById" parameterType="Integer"
resultType="Monster">
SELECT * FROM monster WHERE id = #{id}
</select>
<!-- 实现 findAllMonster -->
<select id="findAllMonster"
resultType="Monster">
SELECT * FROM monster
</select>
- 完成测试, 修改 MonsterMapperTest.java , 增加测试方法
//测试 mybatis 的修改
@Test
public void updateMonster() {
Monster monster = new Monster();
monster.setAge(200);
monster.setBirthday(new Date());
monster.setEmail("hspedu@sohu.com");
monster.setGender(2);
monster.setName("狐狸精");
monster.setSalary(9234.89);
monster.setId(2);
monsterMapper.updateMonster(monster);
if (sqlSession != null) {
sqlSession.commit();
sqlSession.close();
}
System.out.println("修改 ok");
}
//测查询单个对象
@Test
public void getMonsterById() {
Monster monster = monsterMapper.getMonsterById(2);
System.out.println(monster);
if (sqlSession != null) {
sqlSession.close();
}
}
@Test
public void findAllMonster() {
List<Monster> monsterList = monsterMapper.findAllMonster();
for (Monster monster : monsterList) {
System.out.println(monster);
}
if (sqlSession != null) {
sqlSession.close();
}
}
2.3 日志输出-查看 SQL
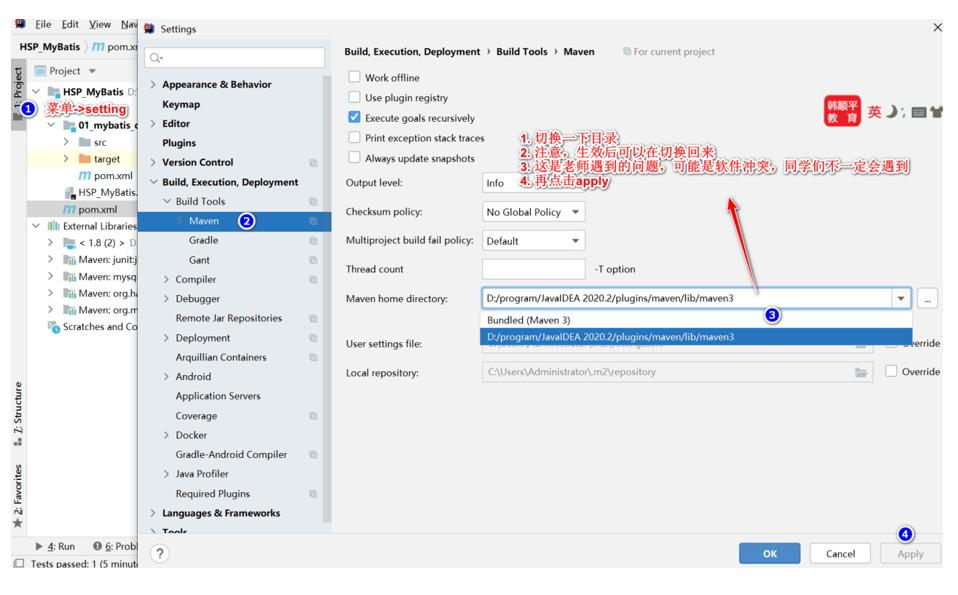
- 在开发 MyBatis 程序时,比如执行测试方法,程序员往往需要查看 程序底层发给 MySQL的 SQL 语句, 到底长什么样, 怎么办?
修 改
D:\java_projects\HSP_MyBatis\01_mybatis_quickstart\src\main\resources\mybatis-config.x
ml, 加入日志输出配置, 方便分析 SQL 语句
<configuration>
<!-- 配置 MyBatis 自带的日志输出, 还可以是其它日志比如 SLF4J | LOG4J | LOG4J2 |
JDK_LOGGING 等 -->
<settings>
<setting name="logImpl" value="STDOUT_LOGGING"/>
</settings>
三、注解开发
1.MyBatis-原生的 API 调用
原生的 API 快速入门需求
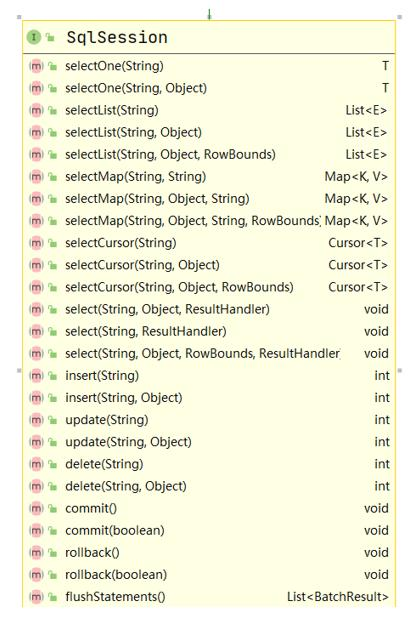
● 在前面项目的基础上,将增删改查,使用 MyBatis 原生的 API 完成,就是直接通过
SqlSession 接口的方法来完成
如下——
具体案例请见上面
2.MyBatis-注解的方式操作
注解的 方式快速入门需求
● 在前面项目的基础上,将增删改查,使用 MyBatis 的注解的方式完成
1.增加
2.删除
3.修改
4.查询
(1). 创 建MonsterAnnotation.java
D:\idea_java_projects\HSP_MyBatis\01_mybatis_quickstart\src\main\java\com\hspedu\mapper\MonsterAnnotation.java
package com.hspedu.mapper;
import com.hspedu.entity.Monster;
import org.apache.ibatis.annotations.Delete;
import org.apache.ibatis.annotations.Insert;
import org.apache.ibatis.annotations.Select;
import org.apache.ibatis.annotations.Update;
import java.util.List;
/**
* @author 韩顺平
* @version 1.0
*/
public interface MonsterAnnotation {
//添加方法,将我们的 sql 语句直接写在@Insert 注解即可
@Insert("INSERT INTO monster (age,birthday,email,gender,name,salary) " + "VALUES(#{age},#{birthday},#{email},#{gender},#{name},#{salary})")
public void addMonster(Monster monster);
//根据 id 删除一个 Monster
@Delete("DELETE FROM monster " + "WHERE id=#{id}")
public void delMonster(Integer id);
//修改 Monster
@Update("UPDATE monster SET age=#{age}, birthday=#{birthday}, " + "email = #{email},gender= #{gender}, " + "name=#{name}, salary=#{salary} " + "WHERE id=#{id}")
public void updateMonster(Monster monster);
//查询-根据 id
@Select("SELECT * FROM monster WHERE " + "id = #{id}")
public Monster getMonsterById(Integer id);
//查询所有的 Monster
@Select("SELECT * FROM monster ")
public List<Monster> findAllMonster();
}
(2). 修改 mybatis-config.xml , 对 MonsterAnnotaion 进行注册
<mappers>
<!-- 这里会引入(注册)我们的 Mapper.xml 文件 -->
<mapper resource="com/hspedu/mapper/MonsterMapper.xml"/>
<!--老韩解读
1. 如果是通过注解的方式,可不再使用 MonsterMapper.xml
2. 但是需要在 mybatis-config.xml 注册含注解的类
-->
<mapper class="com.hspedu.mapper.MonsterAnnotation"/>
(3). 创 建src\test\java\com\hspedu\mapper\MonsterAnnotationTest.java , 完成测试
package com.hspedu.mapper;
import com.hspedu.entity.Monster;
import com.hspedu.util.MyBatisUtils;
import org.apache.ibatis.session.SqlSession;
import org.junit.Before;
import org.junit.Test;
import java.util.Date;
/**
* @author 韩顺平
* @version 1.0
*/
public class MonsterAnnotationTest {
//这个是 Sql 会话,通过它可以发出 sql 语句
private SqlSession sqlSession;
@Before
public void init() throws Exception {
//通过 SqlSessionFactory 对象获取一个 SqlSession 会话
sqlSession = MyBatisUtils.getSqlSession();
}
//测试通过注解的方式来完成接口中方法的实现
//其它的删除,修改,查询是一样一样,同学们自己测试即可
@Test
public void addMonster() {
Monster monster = new Monster();
monster.setAge(500);
monster.setBirthday(new Date());
monster.setEmail("hspedu@sohu.com");
monster.setGender(2);
monster.setName("白虎精");
monster.setSalary(9234.89);
MonsterAnnotation monsterAnnotation =
sqlSession.getMapper(MonsterAnnotation.class);
monsterAnnotation.addMonster(monster);
//增删改,需要提交事务
if (sqlSession != null) {
sqlSession.commit();
sqlSession.close();
}
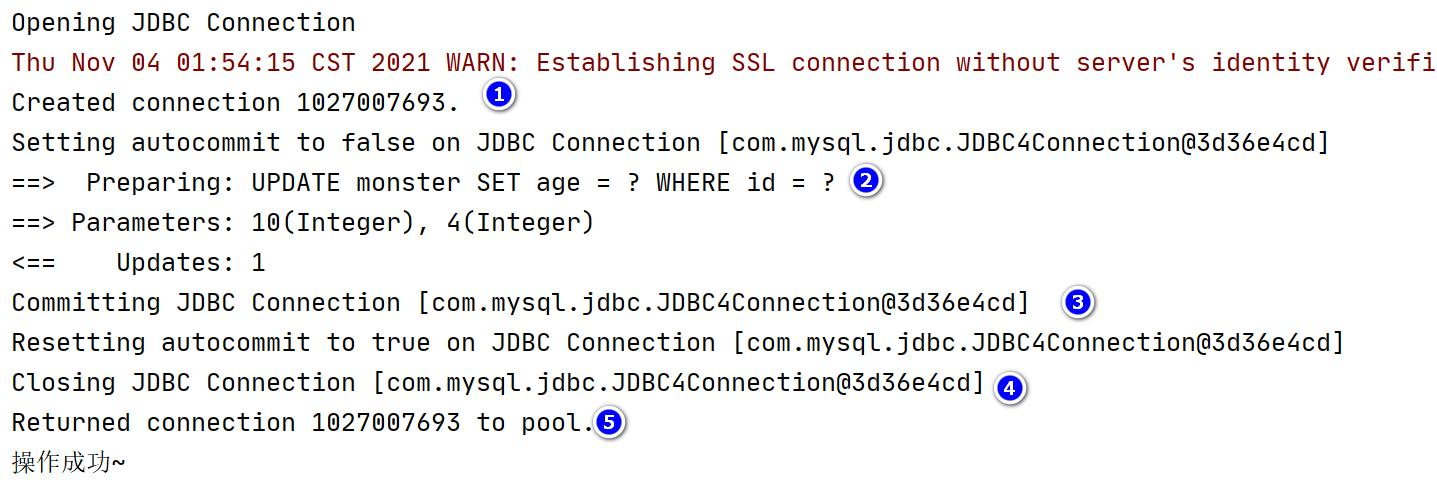
System.out.println("操作成功");
}
}
3.注意事项和说明
- 如 果 是 通 过 注 解 的 方 式 , 就 不 再 使 用 MonsterMapper.xml 文 件 , 但 是 需 要 在
mybatis-config.xml 文件中注册含注解的类/接口 - 使用注解方式,添加时, 如果要返回自增长 id 值, 可以使用**@Option** 注解 , 组合使用
@Insert(value = "INSERT INTO `monster` (`age`, `birthday`, `email`, `gender`, `name`, `salary`) " +
"VALUES (#{age}, #{birthday}, #{email}, #{gender}, #{name}, #{salary})")
@Options(useGeneratedKeys = true, keyProperty = "id", keyColumn = "id")
public void addMonster(Monster monster);
四、mybatis-config.xml-配置文件详解
mybatis 的核心配置文件(mybatis-config.xml),比如配置 jdbc 连接信息,注册 mapper
等等,我们需要对这个配置文件有详细的了解

1.properties 属性
通过该属性,可以指定一个外部的 jdbc.properties 文件,引入我们的 jdbc 连接信息
- 创 建D:\idea_java_projects\HSP_MyBatis\01_mybatis_quickstart\src\main\resources\jdbc.properties
jdbc.user=root
jdbc.password=hsp
jdbc.url=jdbc:mysql://127.0.0.1:3306/mybatis?userSSL=true&userUnicode=true&char
acterEncoding=UTF-8
jdbc.driver=com.mysql.jdbc.Driver
- 修改 mybatis-confing.xml
<configuration>
<!-- 这里就是引入 jdbc.properties 文件 -->
<properties resource="jdbc.properties"/>
<environments default="development">
<environment id="development">
<transactionManager type="JDBC"/>
<dataSource type="POOLED">
<!-- <property name="driver" value="com.mysql.jdbc.Driver"/>-->
<!-- <property name="url"
韩顺平 Java 工程师
value="jdbc:mysql://127.0.0.1:3306/mybatis?userSSL=true&-->
<!-- userUnicode=true&characterEncoding=UTF-8"/>-->
<!-- <property name="username" value="root"/>-->
<!-- <property name="password" value="hsp"/>-->
<property name="driver" value="${jdbc.driver}" />
<property name="url" value="${jdbc.url}" />
<property name="username" value="${jdbc.user}" />
<property name="password" value="${jdbc.password}" />
</dataSource>
</environment>
</environments>
- 修改父项目的 pom.xml(如果已经配置了*.properties 就不用再配置) 并完成测试

2.settings 全局参数定义
settings 列表,通常使用默认
3.typeAliases 别名处理器
1.别名是为 Java 类型命名一个短名字。它只和 XML 配置有关,用来减少类名重复的部分
2.如果指定了别名,我们的 MappperXxxx.xml 文件就可以做相应的简化处理
3.注意指定别名后,还是可以使用全名的
举例说明
修 改01_mybatis_quickstart\src\main\resources\mybatis-config.xml
<typeAliases>
<!-- 如果一个包下有很多的类,我们可以直接引入包,这样
该包下面的所有类名,可以直接使用
-->
<package name="com.hspedu.entity"/>
<!-- 为某个 mapper 指定一个别名, 下面可以在 XxxxxMapper.xml 做相应简化处理 -->
<!-- <typeAlias type="com.hspedu.entity.Monster" alias="Monster"/> -->
</typeAliases>
2) 修改 MonsterMapper.xml 并完成测试
<!--没有在 mybatis-config.xml 指定 typealiases 时,需要给 Monster 指定全类名
<insert id="addMonster" parameterType="com.hspedu.entity.Monster"-->
<!-- useGeneratedKeys="true" keyProperty="id"-->
<!-- >-->
<insert id="addMonster" parameterType="Monster" useGeneratedKeys="true" keyProperty="id" >
INSERT INTO monster (age,birthday,email,gender,name,salary)
VALUES(#{age},#{birthday},#{email},#{gender},#{name},#{salary})
</insert>
4.typeHandlers 类型处理器

5.environments 环境
- resource 注册 Mapper 文件: XXXMapper.xml 文件(常用,使用过)

2 class:接口注解实现(使用过)

3.package 方式注册 :
<package name="com.hspedu.mapper"/> 并测试
<!-- 老韩解读
1. 当一个包下有很多的 Mapper.xml 文件和基于注解实现的接口时,
为了方便,我们可以以包方式进行注册
2. 将下面的所有 xml 文件和注解接口 都进行注册
-->
<package name="com.hspedu.mapper"/>
</mappers>
五、XxxxMapper.xml-SQL 映射文件
1、MyBatis 的真正强大在于它的语句映射(在 XxxMapper.xml 配置), 由于它的异常强大, 如
果拿它跟具有相同功能的 JDBC 代码进行对比,你会立即发现省掉了将近 95% 的代码。
MyBatis 致力于减少使用成本,让用户能更专注于 SQL 代码。
2、SQL 映射文件常用的几个顶级元素(按照应被定义的顺序列出):
cache – 该命名空间的缓存配置。
cache-ref – 引用其它命名空间的缓存配置。
resultMap – 描述如何从数据库结果集中加载对象,是最复杂也是最强大的元素。
parameterType - 将会传入这条语句的参数的类全限定名或别名。
sql – 可被其它语句引用的可重用语句块。
insert – 映射插入语句。
update – 映射更新语句。
delete – 映射删除语句。
select – 映射查询语句。
3.XxxMapper.xml-详细说明
新建 Module xml-mapper
1、在原来的项目中,新建 xml-mapper 项目演示 xml 映射器的使用
2、新建 Module 后,先创建需要的包,再将需要的文件/资源拷贝过来(这里我们拷贝
Monster.java、resources/jdbc.properties 和 mybatis-config.xml)
3、创建 MonsterMapper.java MonsterMapper.xml 和 MonsterMapperTest.java , 做一个比
较干净的讲解环境, 可以再写一遍, 让学员加深印象.
基本使用
- insert、delete、update、select 这个我们在前面讲解过,分别对应增删改查的方法和 SQL
语句的映射. - 如何获取到刚刚添加的 Monster 对象的 id 主键 [前面使用过了]
3.parameterType(输入参数类型)
● parameterType(输入参数类型)
- 传入简单类型,比如按照 id 查 Monster(前讲过)
- 传入 POJO 类型,查询时需要有多个筛选条件
- 当有多个条件时,传入的参数就是 Pojo 类型的 Java 对象,比如这里的 Monster 对象
- 当传入的参数类是 String 时,也可以使用 ${} 来接收参数
parameterType-应用案例
-
案例 1:请查询 id = 1 或者 name = ‘白骨精’ 的妖怪
-
案例 2:请查询 name 中 包含 “牛魔王” 的妖怪
1 修改 MonsterMapper.java, 增加方法接口
//通过 id 或者名字查询
public List<Monster> findMonsterByNameORId(Monster monster);
//查询名字中含义'精'妖怪
public List<Monster> findMonsterByName(String name);
- 修改 MonsterMapper.xml
<!-- 实现 findMonsterByNameORId -->
<select id="findMonsterByNameORId" parameterType="Monster"
resultType="Monster">
SELECT * FROM monster
WHERE id=#{id} OR name=#{name}
</select>
<!-- 看看模糊查询的使用 取值 需要 ${value} 取值-->
<select id="findMonsterByName" parameterType="String" resultType="Monster">
SELECT * FROM monster
WHERE name LIKE '%${value}%' </select>
- 修改 MonsterMapperTest.java ,完成测试
//演示多条件的查询
@Test
public void findMonsterByNameORId() {
Monster monster = new Monster();
monster.setId(5);
monster.setName("白虎精");
List<Monster> list = monsterMapper.findMonsterByNameORId(monster);
for (Monster monster2 : list) {
System.out.println(monster2);
}
if (sqlSession != null) {
sqlSession.close();
}
}
//测试一个模糊查询
@Test
public void findMonsterByName() {
List<Monster> list = monsterMapper.findMonsterByName("精");
for (Monster monster : list) {
System.out.println(monster);
}
if (sqlSession != null) {
sqlSession.close();
}
}
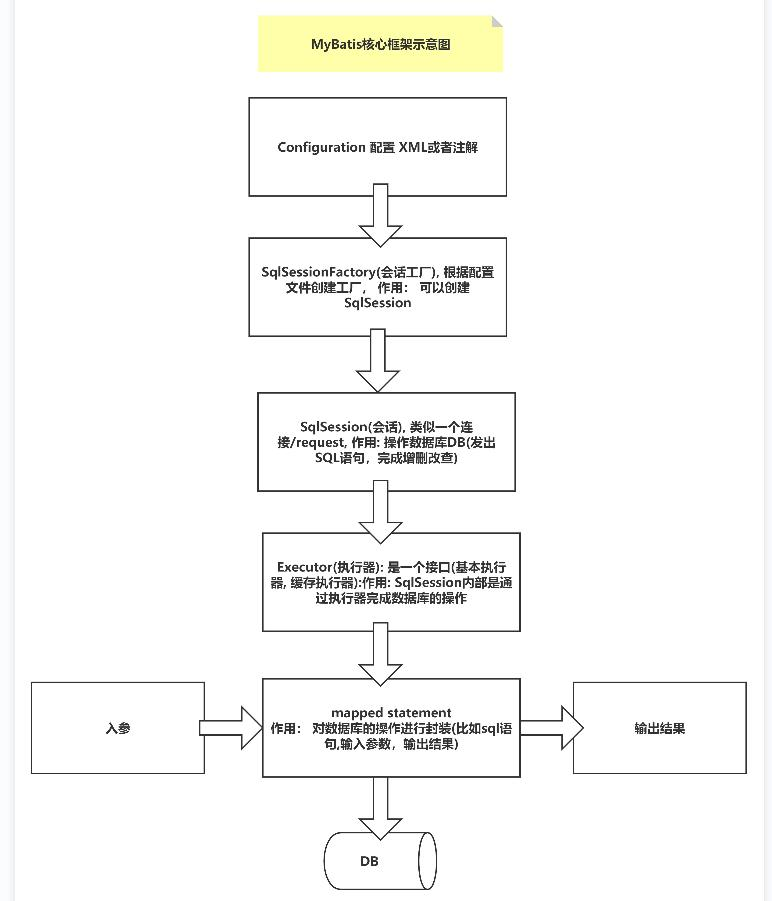
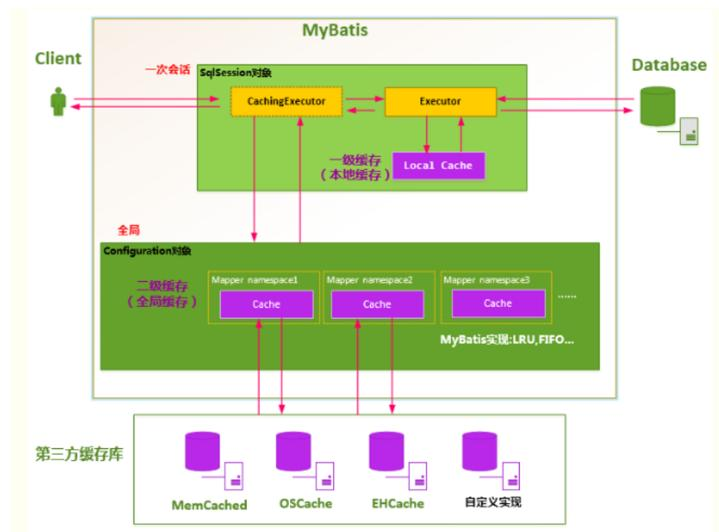
六、核心架构
七、缓存
1.一级缓存
- 默认情况下,mybatis 启用的是一级缓存/本地缓存/local Cache,它是 SqlSession 级别的。
- 同一个 SqlSession 接口对象调用了相同的 select 语句,会直接从缓存里面获取,而不是再去查询数据库
一级缓存原理图
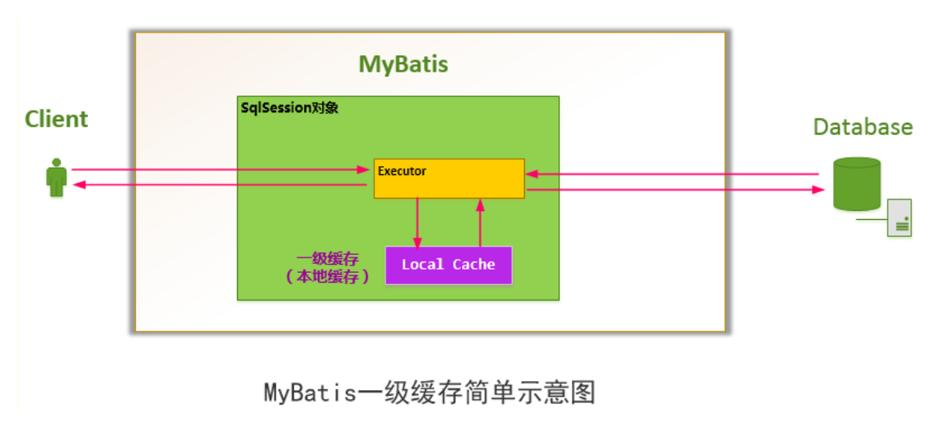
需求: 当我们第 1 次查询 id=1 的 Monster 后,再次查询 id=1 的 monster 对象,就会直接从一级缓存获取,不会再次发出 sql
2.一级缓存失效分析
-
关闭 sqlSession 会话后, 再次查询,会到数据库查询, 修改 MonsterMapperTest.java, 测
试一级缓存失效情况 -
当执行 sqlSession.clearCache() 会使一级缓存失效,修改 MonsterMapperTest.java, 测
试一级缓存失效情况 -
当对同一个 monster 修改,该对象在一级缓存会失效, 修改 MonsterMapperTest.java, 测
试一把
3.二级缓存
- 二级缓存和一级缓存都是为了提高检索效率的技术
- 最大的区别就是作用域的范围不一样,一级缓存的作用域是 sqlSession 会话级别,在一次
会话有效,而二级缓存作用域是全局范围,针对不同的会话都有效.
● 二级缓存原理图

4.二级缓存快速入门
快速入门
(1). mybatis-config.xml 配置中开启二级缓存
<configuration>
<!-- 这里就是引入 jdbc.properties 文件 -->
<properties resource="jdbc.properties"/>
<settings>
<!-- 开启二级缓存 -->
<setting name="cacheEnabled" value="true"/>
</settings>
(2) 使用二级缓存时 entity 类实现序列化接口 (serializable),因为二级缓存可能使用到序列化技术

(3)在对应的 XxxMapper.xml 中设置二级缓存的策略
<mapper namespace="com.hspedu.mapper.MonsterMapper">
<!-- 老韩解读
1. 针对这个 monster 对象的二级缓存策略和相关设置
eviction="FIFO" : 缓存策略 先进先出, 细节会再说
flushInterval="30000": 每 30000 毫秒 刷新一次,和数据库保持一致. size: 二级缓存设置最大保持的 360 个对象, 超过了,就启用 fifo 策略处理 ,默认
1024
readOnly: 只读,为了提高效率
-->
<cache eviction="FIFO" flushInterval="30000" size="360" readOnly="true"/>
(4)修改 MonsterMapperTest.java , 完成测试
@Test
public void level2CacheTest() {
Monster monster = monsterMapper.getMonsterById(2);
System.out.println("--" + monster + "--");
//----------------------------测试 2 级缓存-----------------------
//1. 当我们关闭 sqlSession 会话后,再次查询 id =2 的 monster 时,如果有二级缓存
// 就会从二级缓存读取. 不会发出 sql
System.out.println("=======关闭 sqlSession 会话后, 再次查询同一数据,如果有二级
缓存,不会到数据库查询========");
sqlSession.close();
sqlSession = MyBatisUtils.getSqlSession();
monsterMapper = sqlSession.getMapper(MonsterMapper.class);
monster = monsterMapper.getMonsterById(2);
System.out.println("--" + monster + "--");
if (sqlSession != null) {
sqlSession.commit();
sqlSession.close();
}
System.out.println("操作成功");
}
5.二级缓存注意事项和使用陷阱
(1)理解二级缓存策略的参数
<cache eviction="FIFO" flushInterval="30000" size="360" readOnly="true"/>
上面的配置意思如下:
创建了 FIFO 的策略,每隔 30 秒刷新一次,最多存放 360 个对象而且返回的对象被认为是 只读的。
eviction:缓存的回收策略
flushInterval:时间间隔,单位是毫秒
size:引用数目,内存大就多配置点,要记住你缓存的对象数目和你运行环境的可用内存资源数目。 默认值是 1024。
readOnly:true,只读
(2)四大策略
√ LRU – 最近最少使用的:移除最长时间不被使用的对象,它是默认 。
√ FIFO –先进先出:按对象进入缓存的顺序来移除它们。
√ SOFT – 软引用:移除基于垃圾回收器状态和软引用规则的对象。
√ WEAK –弱引用:更积极地移除基于垃圾收集器状态和弱引用规则的对象。
6.如何禁用二级缓存
1.修改mybatis-config.xml
<settings>
<setting name="logImpl" value="STDOUT_LOGGING"/>
<!--全局性地开启或关闭所有映射器配置文件中已配置的任何缓存, 默认就是 true-->
<setting name="cacheEnabled" value="false"/>
</settings>
2.修改mapper\MonsterMapper.xml
<!--<cache eviction="FIFO" flushInterval="30000" size="360" readOnly="true"/>-->
3.或者更加细粒度的, 在配置方法上指定

设置 useCache=false 可以禁用当前 select 语句的二级缓存,即每次查询都会发出 sql 去查询,默认情况是 true,即该 sql 使用二级缓存。
注意:一般我们不需要去修改,使用默认的即可
- mybatis 刷新二级缓存的设置
<update id="updateMonster" parameterType="Monster" flushCache="true">
UPDATE mybatis_monster SET NAME=#{name},age=#{age} WHERE id=#{id}
</update>
insert、update、delete 操作数据后需要刷新缓存,如果不执行刷新缓存会出现脏读,默认为 true,默认情况下为 true 即刷新缓存,一般不用修改。
Mybatis 的一级缓存和二级缓存执行顺序
一句话:缓存执行顺序是:二级缓存–>一级缓存–>数据库
7.一二级缓存关系
- 不会出现一级缓存和二级缓存中有同一个数据。因为二级缓存(数据)是在一级缓存关闭之后才有的
2.在一级缓存存在的情况下,依然是先查询二级缓存,但是因为二级缓存,没有数据, 所以命中率都是 0.0
8.EhCache 缓存
- EhCache 是一个纯 Java 的缓存框架,具有快速、精干等特点
- MyBatis 有自己默认的二级缓存(前面我们已经使用过了),但是在实际项目中,往往使用的是更加专业的第三方缓存产品 作为 MyBatis 的二级缓存,EhCache 就是非常优秀的缓存产品
(1)配置和使用 EhCache
- 加入相关依赖, 修改 D:\idea_java_projects\HSP_MyBatis\03_mybatis_cache\pom.xml
<dependencies>
<dependency>
<groupId>net.sf.ehcache</groupId>
<artifactId>ehcache-core</artifactId>
<version>2.6.11</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.7.25</version>
</dependency>
<dependency>
<groupId>org.mybatis.caches</groupId>
<artifactId>mybatis-ehcache</artifactId>
<version>1.2.1</version>
</dependency>
</dependencies>
(2)mybatis-config.xml 仍然打开二级缓存
<settings><!-- 开启二级缓存,默认就是打开 --><setting name="cacheEnabled" value="true"/></settings>
(3) 加 入src\main\resources\ehcache.xml 配置文件
<?xml version="1.0" encoding="UTF-8"?>
<ehcache>
<!--diskStore:为缓存路径,ehcache 分为内存和磁盘两级,此属性定义磁盘的缓存位置。
参数解释如下:
user.home – 用户主目录
user.dir – 用户当前工作目录
java.io.tmpdir – 默认临时文件路径
-->
<diskStore path="java.io.tmpdir/Tmp_EhCache"/>
<!--defaultCache:默认缓存策略,当 ehcache 找不到定义的缓存时,则使用这个缓存策略。
只能定义一个。
-->
<!--name:缓存名称。
maxElementsInMemory:缓存最大数目
maxElementsOnDisk:硬盘最大缓存个数。
eternal:对象是否永久有效,一但设置了,timeout 将不起作用。
overflowToDisk:是否保存到磁盘,当系统当机时
timeToIdleSeconds:设置对象在失效前的允许闲置时间(单位:秒)。仅当 eternal=false
对象不是永久有效时使用,可选属性,默认值是 0,也就是可闲置时间无穷大。
timeToLiveSeconds:设置对象在失效前允许存活时间(单位:秒)。最大时间介于创建时
间和失效时间之间。仅当 eternal=false 对象不是永久有效时使用,默认是 0.,也就是对象存活
时间无穷大。
diskPersistent:是否缓存虚拟机重启期数据 Whether the disk store persists between
restarts of the Virtual Machine. The default value is false. diskSpoolBufferSizeMB:这个参数设置 DiskStore(磁盘缓存)的缓存区大小。默认是
30MB。每个 Cache 都应该有自己的一个缓冲区。
diskExpiryThreadIntervalSeconds:磁盘失效线程运行时间间隔,默认是 120 秒。
memoryStoreEvictionPolicy:当达到 maxElementsInMemory 限制时,Ehcache 将会根
据指定的策略去清理内存。默认策略是 LRU(最近最少使用)。你可以设置为 FIFO(先进先出)
或是 LFU(较少使用)。
clearOnFlush:内存数量最大时是否清除。
memoryStoreEvictionPolicy:可选策略有:LRU(最近最少使用,默认策略)、FIFO(先
进先出)、LFU(最少访问次数)。
FIFO,first in first out,这个是大家最熟的,先进先出。
LFU, Less Frequently Used,就是上面例子中使用的策略,直白一点就是讲一直以来
最少被使用的。如上面所讲,缓存的元素有一个 hit 属性,hit 值最小的将会被清出缓存。
LRU,Least Recently Used,最近最少使用的,缓存的元素有一个时间戳,当缓存容量
满了,而又需要腾出地方来缓存新的元素的时候,那么现有缓存元素中时间戳离当前时间最远的
元素将被清出缓存。
-->
<defaultCache eternal="false" maxElementsInMemory="10000" overflowToDisk="false" diskPersistent="false"
timeToIdleSeconds="1800"
timeToLiveSeconds="259200" memoryStoreEvictionPolicy="LRU"/>
</ehcache>
(4) 在 XxxMapper.xml 中启用 EhCache , 当然原来 MyBatis 自带的缓存配置就注销了
<mapper namespace="com.hspedu.mapper.MonsterMapper">
<!-- 老韩解读
1. 针对这个 monster 对象的二级缓存策略和相关设置
eviction="FIFO" : 缓存策略 先进先出, 细节会再说
flushInterval="30000": 每 30000 毫秒 刷新一次,和数据库保持一致. size: 二级缓存设置最大保持的 360 个对象, 超过了,就启用 fifo 策略处理 ,默认
1024
readOnly: 只读,为了提高效率
-->
<!-- <cache eviction="FIFO" flushInterval="30000" size="360" readOnly="true"/>-->
<!-- 启动 ehcache 缓存 -->
<cache type="org.mybatis.caches.ehcache.EhcacheCache"/>
(5)在 XxxMapper.xml 中启用 EhCache , 当然原来 MyBatis 自带的缓存配置就注销了
<mapper namespace="com.hspedu.mapper.MonsterMapper">
<!-- 老韩解读
1. 针对这个 monster 对象的二级缓存策略和相关设置
eviction="FIFO" : 缓存策略 先进先出, 细节会再说
flushInterval="30000": 每 30000 毫秒 刷新一次,和数据库保持一致. size: 二级缓存设置最大保持的 360 个对象, 超过了,就启用 fifo 策略处理 ,默认
1024
readOnly: 只读,为了提高效率
-->
<!-- <cache eviction="FIFO" flushInterval="30000" size="360" readOnly="true"/>-->
<!-- 启动 ehcache 缓存 -->
<cache type="org.mybatis.caches.ehcache.EhcacheCache"/>
(6)修改 MonsterMapperTest.java
//测试 ehCache 级缓存,及其失效情况
@Test
public void ehCacheTest() {
Monster monster = monsterMapper.getMonsterById(2);
System.out.println("--" + monster + "--");
//----------------------------测试 ehCache 缓存-----------------------
//. 当我们关闭 sqlSession 会话后,再次查询 id =2 的 monster 时,如果有 ehCache 缓
存
// 就会从 ehCache 缓存读取. 不会发出 sql
System.out.println("=======关闭 sqlSession 会话后, 再次查询同一数据,如果有
ehCache 缓存,不会到数据库查询========");
sqlSession.close();
sqlSession = MyBatisUtils.getSqlSession();
monsterMapper = sqlSession.getMapper(MonsterMapper.class);
monster = monsterMapper.getMonsterById(2);
System.out.println("--" + monster + "--");
if (sqlSession != null) {
sqlSession.close();
}
System.out.println("操作成功");
}
9.EhCache 缓存-细节说明
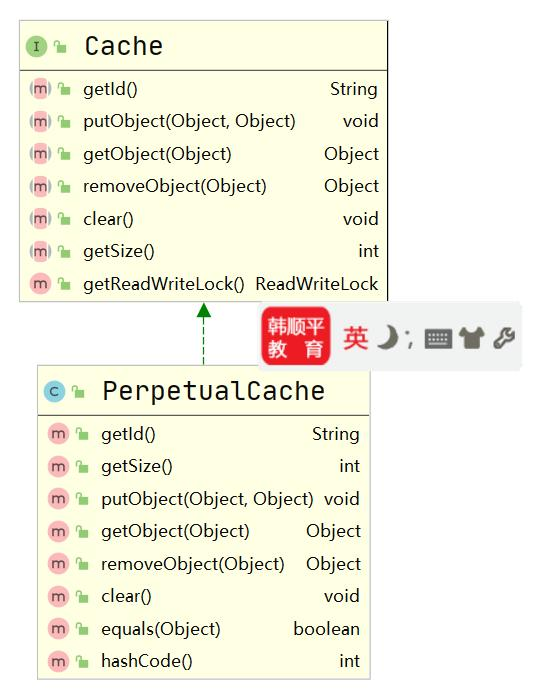
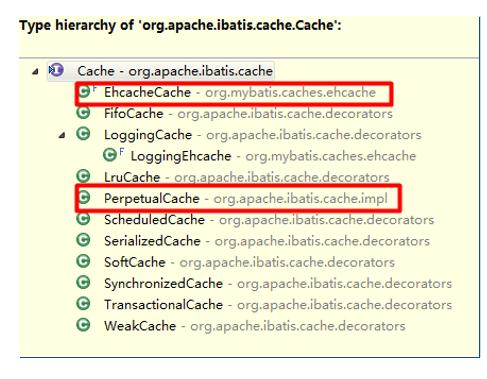
如何理解 EhCache 和 MyBatis 缓存的关系
-
MyBatis 提供了一个接口 Cache【如右图,找到 org.apache.ibatis.cache.Cache ,关联源码包就可以看到 Cache 接口】
-
只要实现了该 Cache 接口,就可以作为二级缓存产品和 MyBatis 整合使用,Ehcache 就是实现了该接口
-
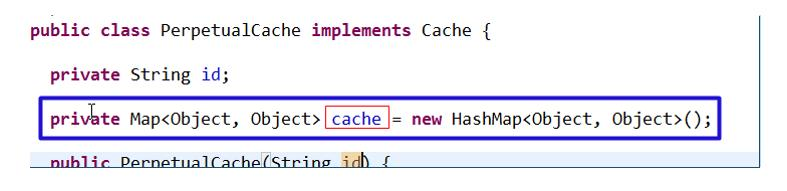
MyBatis 默认情况(即一级缓存)是使用的 PerpetualCache 类实现 Cache 接口的,是核心类
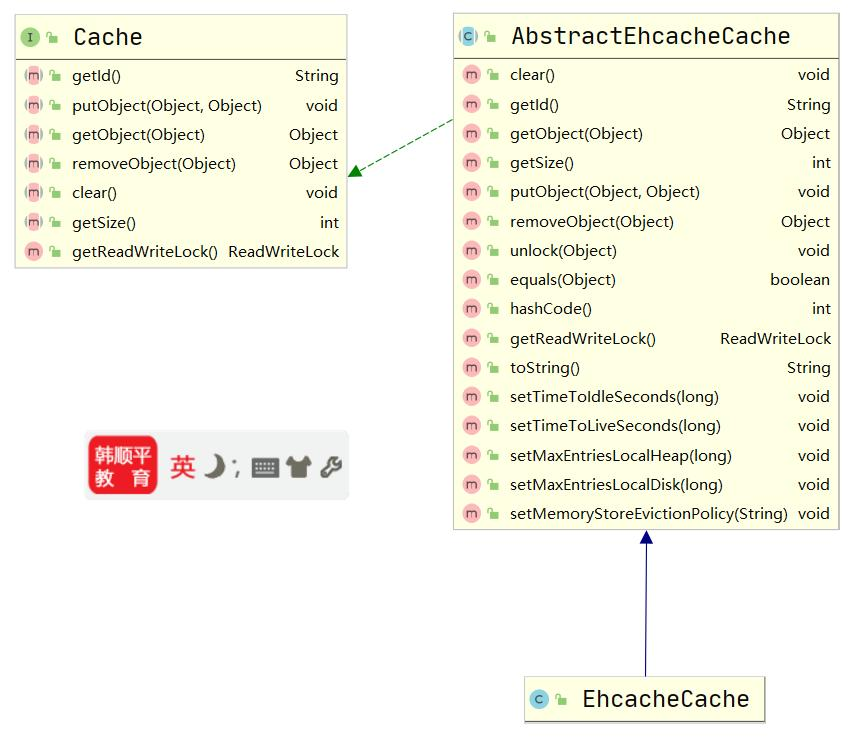
-
当我们使用了 Ehcahce 后,就是 EhcacheCache 类实现 Cache 接口的,是核心类
-
我们看一下源码,发现缓存的本质就是 Map<Object,Object>
💖💖💖💖💖💖💖💖💖💖💖💖💖💖💖💖💖💖
热门专栏推荐
🌈🌈计算机科学入门系列 关注走一波💕💕
🌈🌈CSAPP深入理解计算机原理 关注走一波💕💕
🌈🌈微服务项目之黑马头条 关注走一波💕💕
🌈🌈redis深度项目之黑马点评 关注走一波💕💕
🌈🌈Java面试八股文系列专栏 关注走一波💕💕
🌈🌈算法leetcode+剑指offer 关注走一波💕💕
📣非常感谢你阅读到这里,如果这篇文章对你有帮助,希望能留下你的点赞👍 关注❤ 分享👥 留言💬thanks!!!
📚愿大家都能学有所得,功不唐捐!















 15万+
15万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









