







文章目录
第1章 计算机网络和因特网
1.1 什么是因特网
在本书中,我们使用一种特定的计算机网络,即公共因特网,作为讨论计算机网络及其协议的主要载体。但什么是因特网?
回答这个问题有两种方式:
其一,我们能够描述因特网的具体构成,即构成因特网的基本硬件和软件组件;
其二,我们能够根据为分布式应用提供服务的联网基础设施来描述因特网。
我们先从描述因特网的具体构成开始。
1.1.1 具体构成描述
因特网是一个世界范围的计算机网络,即它是一个互联了遍及全世界数十亿计算设备的网络。在不久前,这些计算设备多数是传统的桌面PC、Linux工作站以及所谓的服务器。然而,越来越多的非传统的因特网“物品”(如便携机、智能手机、平板电脑、电视)正在与因特网相连。
用因特网术语来说,所有这些设备都称为主机(host)或端系统)(endsystem)。
全球因特网——图解
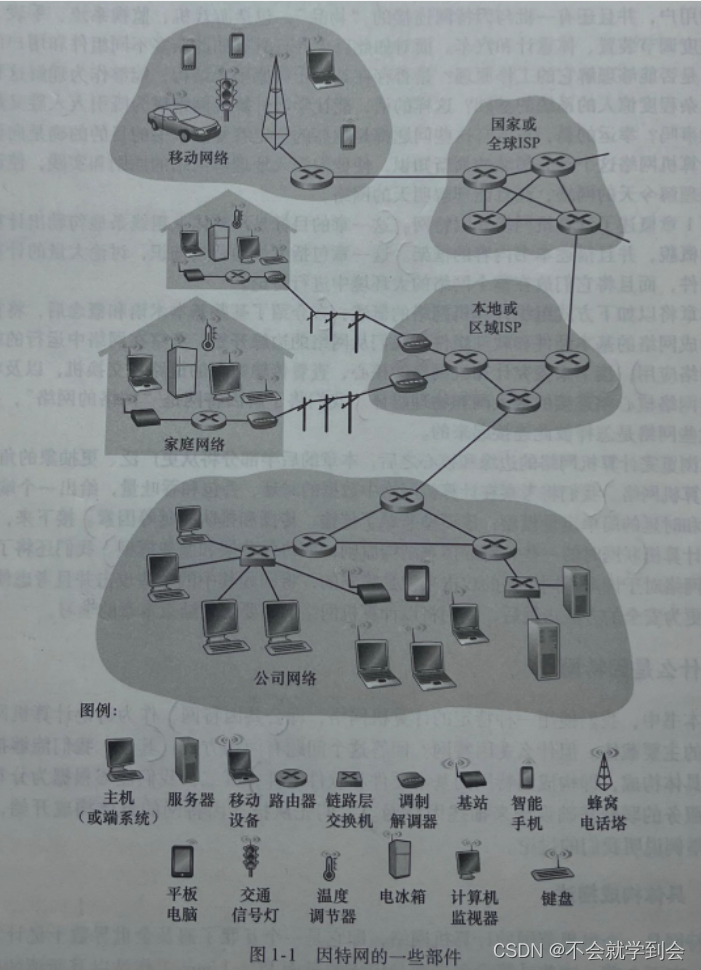
端系统通过通信链路(communication link)和分组交换机(packet switch)连接到一起。
在1.2节中,我们将介绍许多类型的通信链路,它们由不同类型的物理媒体组成。这些物理媒体包括同轴电缆、铜线、光纤和无线电频谱。不同的链路能够以不同的速率传输数据,链路的传输速率(transmission rate)以比特/秒(bit/s,或bps)度量。
当一台端系统要向另一台端系统发送数据时,发送端系统将数据分段,并为每段加上首部字节。由此形成的信息包用计算机网络的术语来说称为分组(packet)这些分组通过网络发送到目的端系统,在那里被装配成初始数据。
分组交换机从它的一条入通信链路接收到达的分组,并从它的一条出通信链路转发该分组。
市面上流行着各种类型、各具特色的分组交换机,但在当今的因特网中,两种最著名的类型是路由器(router)和链路层交换机(link-layer switch),这两种类型的交换机朝着最终目的地转发分组。链路层交换机通常用于接入网中,而路由器通常用于网络核心中。
从发送端系统到接收端系统,一个分组所经历的一系列通信链路和分组交换机称为通过该网络的路径(route或path)。
比喻1:分组交换网络
用于传送分组的分组交换网络在许多方面类似于承载运输车辆的运输网络,该网络包括了高速公路、公路和交叉口。
例如,考虑下列情况,一个工厂需要将大量货物搬运到数千公里以外的某个目的地仓库。在工厂中,货物要分开并装上卡车车队。然后,每辆卡车独立地通过高速公路、公路和立交桥组成的网络向仓库运送货物。在目的地仓库,卸下这些货物,并且与一起装载的同一批货物的其余部分堆放在一起。因此,在许多方面,分组类似于卡车,通信链路类似于高速公路和公路,分组交换机类似于交叉口,而端系统类似于建筑物。就像卡车选取运输网络的一条路径前行一样,分组则选取计算机网络的一条路径前行。
端系统通过因特网服务提供商(IntermetServiceProvider,,ISP)接人因特网,包括如本地电缆或电话公司那样的住宅区ISP、公司ISP、大学ISP,在机场、旅馆、咖啡店和其他公共场所提供WiFi接人的ISP,以及为智能手机和其他设备提供移动接人的蜂窝数据ISP。
**每个ISP自身就是一个由多台分组交换机和多段通信链路组成的网络。**各ISP为端系统提供了各种不同类型的网络接入,包括如线缆调制解调器或DSL那样的住宅宽带接入、高速局域网接入和移动无线接入。ISP也为内容提供者提供因特网接入服务,将Web站点和视频服务器直接连人因特网。
因特网就是将端系统彼此互联,因此为端系统提供接入的ISP 也必须互联。 **较低层的ISP 通过国家的、国际的较高层ISP(如Level3 Communications、AT&T、Sprint和NTT)互联起来。**较高层ISP是由通过高速光纤链路互联的高速路由器组成的。无论是较高层还是较低层ISP网络,它们每个都是独立管理的,运行着IP协议(详情见后),遵从一定的命名和地址规则。
端系统、分组交换机和其他因特网部件都要运行一系列协议(protocol),这些协议控制因特网中信息的接收和发送。**TCP(TransmissionControl Protocol,传输控制协议)和IP(Intermet Protocol,网际协议)是因特网中两个最为重要的协议。
** IP协议定义了在路由器和端系统之间发送和接收的分组格式。 因特网的主要协议统称为TCP/IP。
因特网标准(Intemet standard)由因特网工程任务组(Interet Engineering Task Force, IETF) 研发。(IETF的标准文档称为请求评论(RequestForComment,RFC)。**RFC 文档往往是技术性很强并相当详细的。**它们定义了 TCP、IP、HTTP(用于Web)和SMTP(用于电子邮件)等协议。
1.1.2 服务描述
前面的讨论已经辨识了构成因特网的许多部件。但是我们也能从一个完全不同的角度,即从为应用程序提供服务的基础设施的角度来描述因特网。
除了诸如电子邮件和Web冲浪等传统应用外,因特网应用还包括移动智能手机和平板电脑应用程序,其中包括即时讯息、与实时道路流量信息的映射、来自云的音乐流、电影和电视流、在线社交网络、视频会议、多人游戏以及基于位置的推荐系统。
因为这些应用程序涉及多个相交换数据的端系统,故它们被称为分布式应用程序)(distributedapplication)。
重要的是因特网应用程序运行在端系统上,即它们并不运行在网络核心中的分组交换机中。尽管分组交换机能够加速端系统之间的数据交换,但它们并不在意作为数据的源或宿的应用程序。
因特网描述为应用程序的平台。运行在一个端系统上的应用程序怎样才能指令因特网向运行在另一个端系统上的软件发送数据呢?
与因特网相连的端系统提供了一个套接字接口(socket interface),**该接口规定了运行在一个端系统上的程序请求因特网基础设施向运行在另一个端系统上的特定目的地程序交付数据的方式。**因特网套接字接口是一套发送程序必须遵循的规则集会,因此因特网能够将数据交付到目的地
1.1.3 什么是协议
课程引出——
既然我们已经对因特网是什么有了一点印象,那么下面考虑计算机网络中另一个重要的时髦术语:协议(protocol)。什么是协议?协议是用来干什么的?
协议(protocol)定义了在两个或多个通信实体之间交换的报文的格式和顺序,以及报文发送和/或接收一条报文或其他事件所采取的动作。
比喻2:协议与人类生活
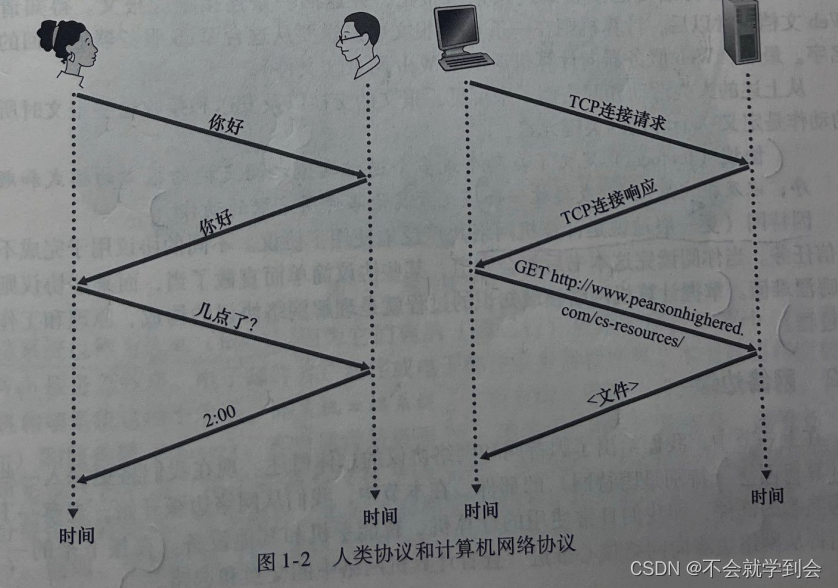
比喻3:上课与网络协议
我们再考虑第二个人类类比的例子。假定你正在大学课堂里上课(例如上的是计算机网络课程)。教师正在唠唠叨叨地讲述协议,而你困惑不解。这名教师停下来问“同学们有什么问题吗?”(教师发送出一个报文,该报文被所有没有睡觉的学生接收到了。)你举起了手(向教师发送了一个隐含的报文)。这位教师面带微笑地示意你说“请讲……”(教师发出的这个报文鼓励你提出问题,教师喜欢被问问题。)接着你就问了问题(向该教师传输了你的报文)。教师听取了你的问题(接收了你的问题报文)并加以回答(向你传输了回答报文)。我们再一次看到了报文的发送和接收,以及这些报文发送和接收时所采取的一系列约定俗成的动作,这些是这个“提问与回答”协议的关键所在。
在因特网中,涉及两个或多个远程通信实体的所有活动都受协议的制约。例如——
在两台物理上连接的计算机中,硬件实现的协议控制了在两块网络接口卡间的“线上”的比特流;
在端系统中,拥塞控制协议控制了在发送方和接收方之间传输的分组发送的速率;
路由器中的协议决定了分组从源到目的地的路径。
在因特网中协议运行无处不在,因此本书的大量篇幅都与计算机网络协议有关——掌握计算机网络领域知识的过程就是理解网络协议的构成、原理和工作方式的过程。
1.2 网络边缘
课程引出——
在接下来的一节中,我们将从网络边缘向网络核心推进,查看计算机网络中的交换和选路。
端系统交互——图解
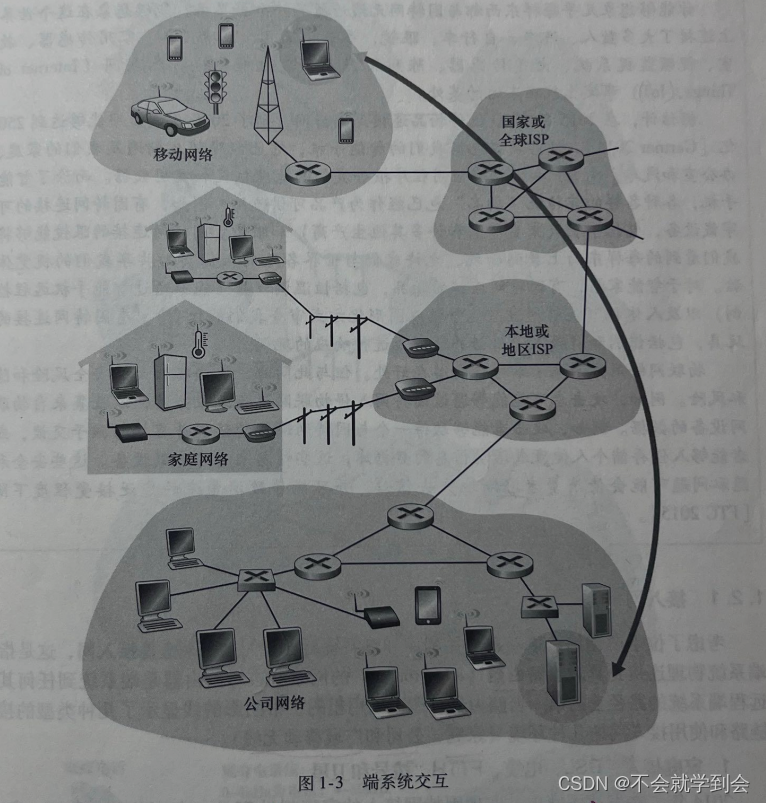
端系统也称为主机(host)(因为它们容纳(即运行)应用程序),本书通篇将交替使用主机和端系统这两个术语,即主机=端系统。
主机有时又被进一步划分为两类——
客户(client)和服务器(server)。
客户通常是桌面PC、移动PC 和智能手机等,而服务器通常是更为强大的机器,用于存储和发布Web页面、流视频、中继电子邮件等。
今天,大部分提供搜索结果、电子邮件、Web页面和视频的服务器都属于大型数据中心(datacenter)。例如,谷歌公司(Google)拥有50~100个数据中心,其中15个大型数据中心每个都有10万台以上的服务器。
1.2.1接入网
课程引出——
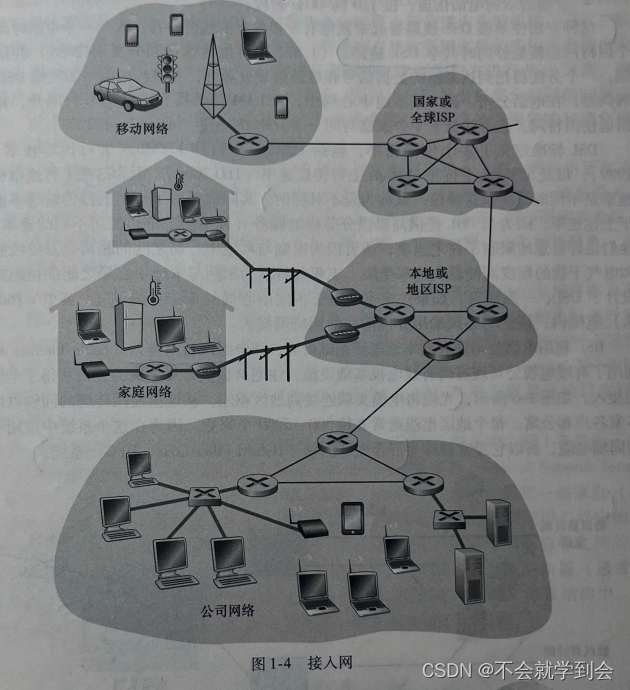
考虑了位于“网络边缘”的应用程序和端系统后,(我们接下来考虑接入网,这是指将端系统物理连接到其边缘路由器(edgerouter)的网络。
边缘路由器是端系统到任何其他远程端系统的路径上的第一台路由器。图1-4用粗的、带阴影的线显示了几种类型的接入链路和使用接入网的几种环境(家庭、公司和广域移动无线)。
(1)家庭接人:DSL、电缆、FTTH、拨号和卫星
今天,宽带住宅接入有两种最流行的类型**:数字用户线**(DigitalSubscriber Line,DSL)和电缆。
住户通常从提供本地电话接人的本地电话公司处获得DSL因特网接人。
因此,当使用 DSL时,用户的本地电话公司也是它的ISP。如图1-5 所示,每个用户的 DSL调制解调器使用现有的电话线(即双绞铜线)与位于电话公司的本地中心局(CO)中的数字用户线接复用器(DSLAM)换数据。
(家庭的 DSL 调制解调器得到数字数据后将其转换为高频音,以通过电话线传输给本地中心局;来自许多家庭的模拟信号在DSLAM 处被转换回数字形式。)
图解——接入网
图解——DSL因特网接入
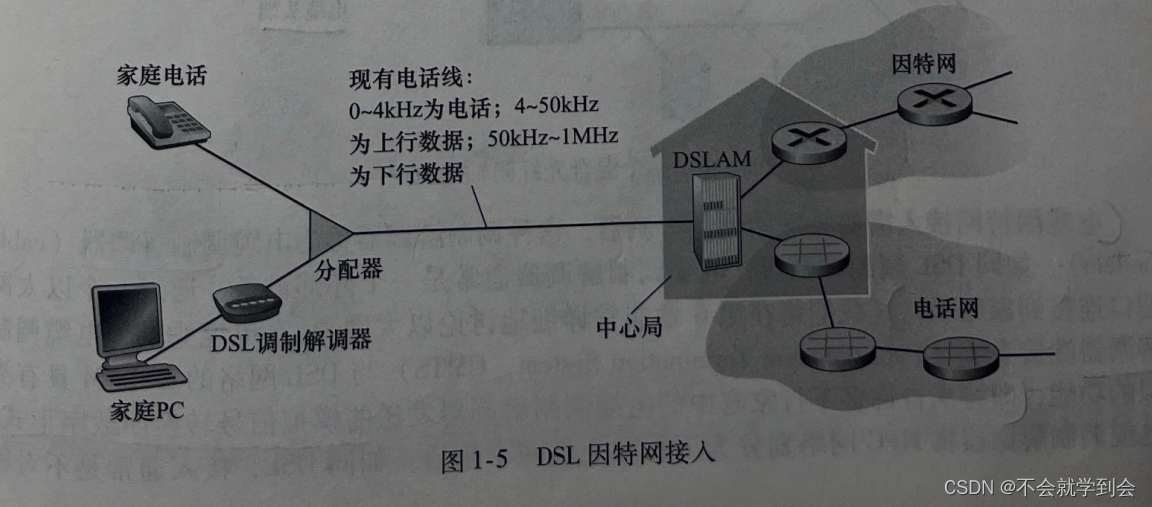
DSL利用电话公司现有的本地电话基础设施,而电缆因特网接入(cable Intermet access)利用了有线电视公司现有的有线电视基础设施。住宅从提供有线电视的公司获得了电缆因特网接人。
如图1-6所示,光缆将电缆头端连接到地区枢纽,从这里使用传统的同轴电缆到达各家各户和公寓。每个地区枢纽通常支持500~5000个家庭。因为在这个系统中应用了光纤和同轴电缆,所以它经常被称为混合光纤同轴(HybridFiberCoax,HFC)系统。
图解——混合光纤同轴接入网
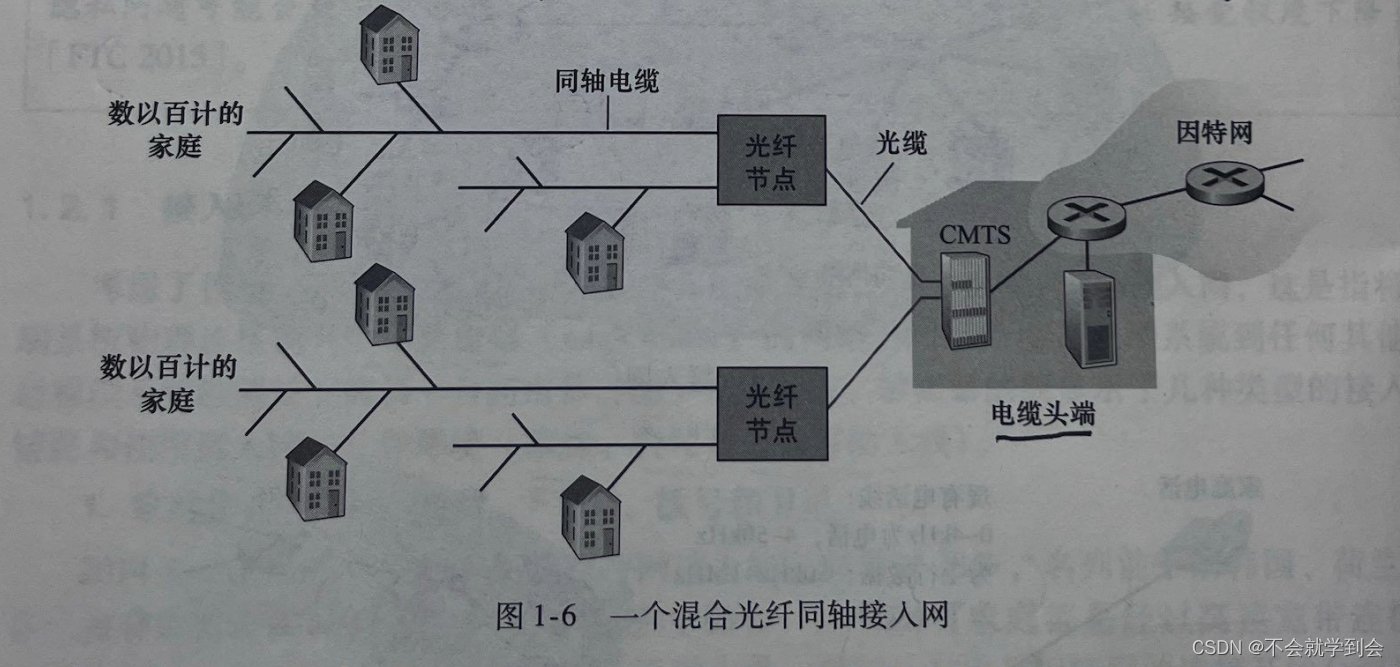
电缆因特网接人需要特殊的调制解调器,这种调制解调器称为电缆调制解调器(cablemodem)。
如同 DSL调制解调器,电缆调制解调器通常是一个外部设备,通过一个以太网端口连接到家庭PC。
在电缆头端,电缆调制解调器端接系统(Cable Modem Termination System,CMTS)与 DSL 网络的 DSLAM 具有类似的功能,即将来自许多下行家庭中的电缆调制解调器发送的模拟信号转换回数字形式。电缆调制解调器将 HFC网络划分为下行和上行两个信道。如同 DSL,接入通常是不对称的。电缆因特网接人的一个重要特征是共享广播媒体。
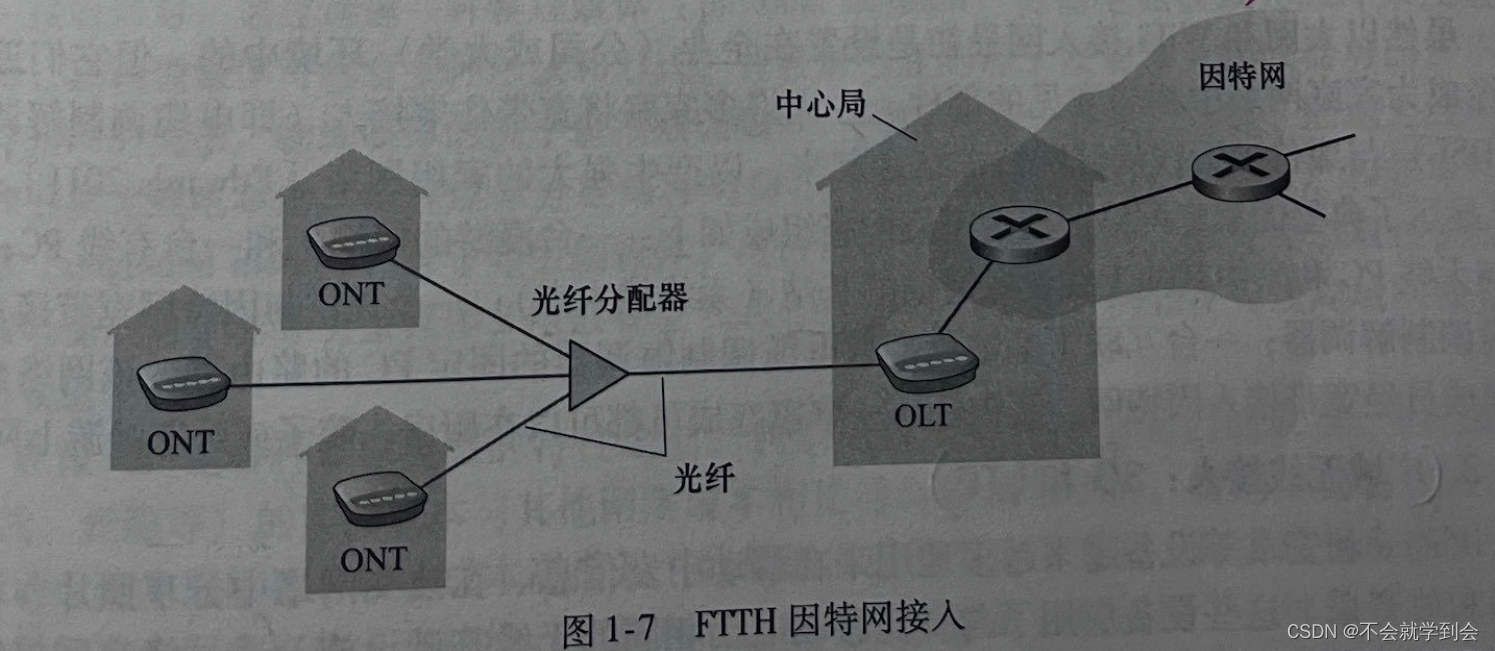
图解——FTTH 因特网接入
尽管DSL和电缆网络当前代表了超过85%的美国住宅宽带接入,但一种提供更高速率的新兴技术是光纤到户(FiberToThe Home,FTTH) ,FTTH 有潜力提供每秒千兆比特范围的因特网接人速率。
(2)企业(和家庭)接人:以太网和WiFi
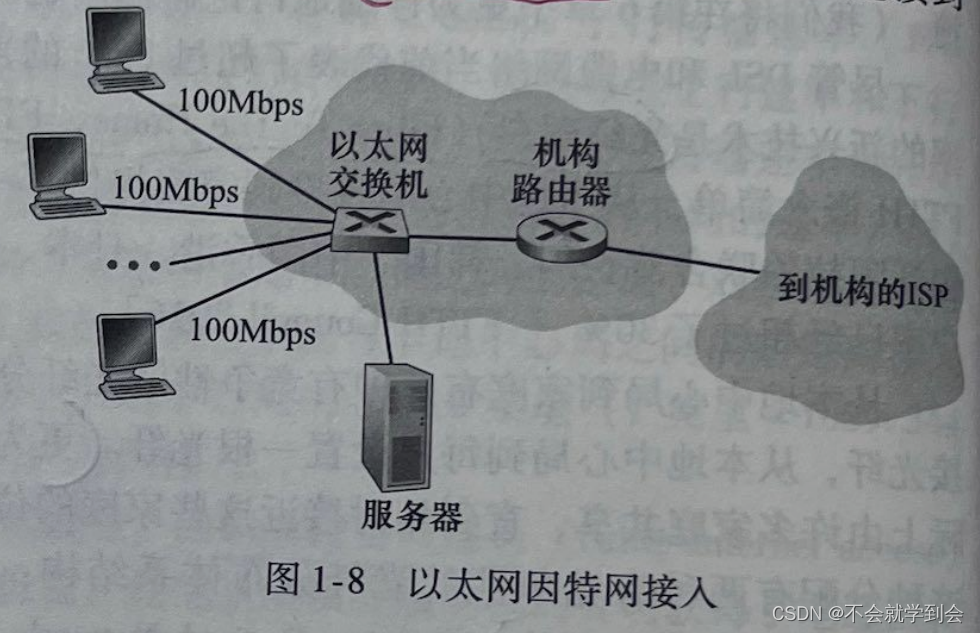
图解——以太网因特网接入
在公司和大学校园以及越来越多的家庭环境中,使用局域网(LAN)将端系统连接到边缘路由器。
尽管有许多不同类型的局域网技术,但是以太网到目前为止是公司、大学和家庭网络中最为流行的接人技术
如图1-8 中所示,以太网用户使用双绞铜线与一台以太网交换机相连。
一个无线LAN 用户通常必须位于接人点的几十米范围内。基于EEE802.11技术的无线LAN 接入,更通俗地称为(WiFi),目前几乎无所不在
虽然以太网和 WiFi接入网最初是设置在企业(公司或大学)环境中的,但它们近来已经成为家庭网络中相当常见的部件。今天许多家庭 将宽带住宅接入(即电缆调制解调器或 DSL)与廉价的无线局域网技术结合起来,以产生强大的家用网络 。

(3)广域无线接入:3G和LTE
iPhone 和安卓等设备越来越多地用来在移动中发信息、在社交网络中分享照片、观看视频和放音乐。这些设备应用了与蜂窝移动电话相同的无线基础设施,通过蜂窝网提供商运营的基站来发送和接收分组。)与WiFi不同的是,一个用户仅需要位于基站的数万米(而不是几十米)范围。
LTE(长期演进“ Long- Term Evolution”)的缩写 )来源于3G技术,它能够取得超过10Mbps的速率。
1.2.2 物理媒体
课程引出——
在前面的内容中,我们概述了因特网中某些最为重要的网络接入技术。当我们描述这些技术时,我们也指出了所使用的物理媒体。
例如——
我们说过HFC使用了光缆和同轴电缆相结合的技术。
我们说过DSL和以太网使用了双绞铜线。
我们也说过移动接入网在使用了无线电频谱输媒体。
本节的内容将详细解答物理媒介——
比特的历程——
比特当从源到目的地传输时,通过一系列**“发射器-接收器”对。对于每个发射器-接收器对,通过跨越一种物理媒体(physical medium)传播电磁波或光脉冲来发送该比特。该物理媒体可具有多种形状和形式,并且对沿途的每个发射器-接收器对而言不必具有相同的类型。物理媒体的例子包括双绞铜线、同轴电缆、多模光纤缆、陆地无线电频谱和卫星无线电频谱**。
物理媒体分成两种类型:(导引型媒体(guidedmedia)和非导引型媒体(unguided media)。
对于导引型媒体,电波沿着固体媒体前行,如光缆、双绞铜线或同轴电缆。
对于非导引型媒体,电波在空气或外层空间中传播,例如在无线局域网或数字卫星频道中。
(1)双绞铜线
最便宜并且最常用的导引型传输媒体是双绞铜线。一百多年来,它一直用于电话网。事实上,从电话机到本地电话交换机的连线超过99%便用的是双绞铜线。)我们多数人在自已家中和工作环境中已经看到过双绞线。双绞线由两根绝缘的铜线组成,每根大约1mm粗,以规则的螺旋状排列着。这两根线被绞合起来,以减少邻近类似的双绞线的电气干扰。通常许多双绞线捆扎在一起形成一根电缆,并在这些双绞线外面覆盖上保护性防护层。一对电线构成了一个通信链路。(无屏蔽双绞线(Unshielded Twisted Pair,UTP)常用在建筑物内的计算机网络中,即用于局域网(LAN)中。目前局域网中的双绞线的数据速率从10Mbps到10Gbps。所能达到的数据传输速率取决于线的粗细以及传输方和接收方之间的距离。
(2)同轴电缆
与双绞线类似,同轴电缆由两个铜导体组成,但是这两个导体是同心的而不是并行的。借助于这种结构及特殊的绝缘体和保护层,同轴电缆能够达到较高的数据传输速率。同轴电缆在电缆电视系统中相当普遍。
(3)光纤
光纤是一种细而柔软的、能够导引光脉冲的媒体,每个脉冲表示一个比特。
一根光纤能够支持极高的比特速率,高达数十甚至数百Gbps。((它们不受电磁干扰,长达100km的光缆信号衰减极低,并且很难窃听。这些特征使得光纤成为长途导引型传输媒体,特别是跨海链路。在美国和别的地方,许多长途电话网络现在全面使用光纤。光纤也广泛用于因特网的主干。然而,高成本的光设备,如发射器、接收器和交换机,阻碍光纤在短途传输中的应用,如在LAN或家庭接人网中就不使用它们。
(4)陆地无线电信道
无线电信道承载电磁频谱中的信号。它不需要安装物理线路,并具有穿透墙壁、提供与移动用户的连接以及长距离承载信号的能力,因而成为一种有吸引力的媒体。
陆地无线电信道能够大致划分为三类——
一类运行在很短距离(如1米或2米);
另一类运行在局域,通常跨越数十到几百米(LAN);
第三类运行在广域,跨越数万米。个人设备如无线头戴式耳机、蜂窝接入、键盘和医疗设备跨短距离运行;
(5)卫星无线电信道
一颗通信卫星连接地球上的两个或多个微波发射器/接收器,它们被称为地面站。
该卫星在一个频段上接收传输,使用一个转发器(下面讨论)再生信号,并在另一个频率上发射信号。
通信中常使用两类卫星:同步卫星和近地轨道卫星
1.3 网络核心
课程引出——
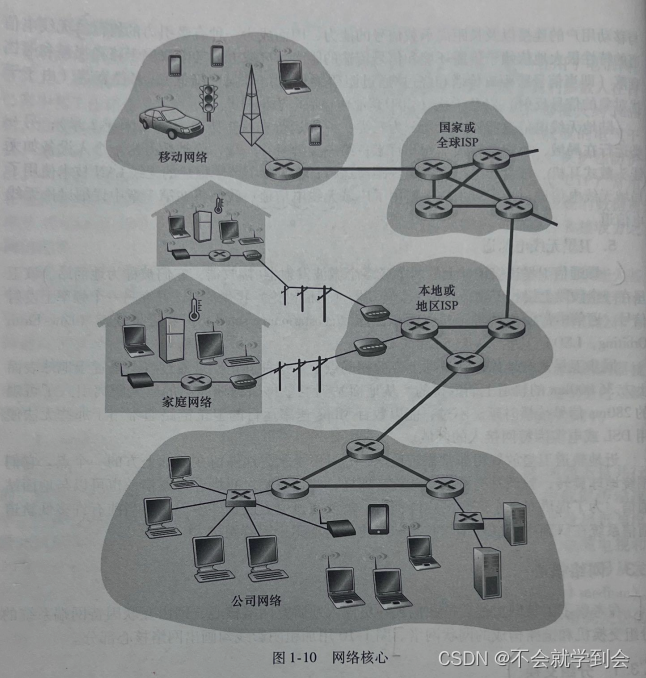
在考察了因特网边缘后,我们现在更深人地研究网络核心,即由互联因特网端系统的分组交换机和链路构成的网状网络。图1-10用加粗阴影线勾画出网络核心部分。
图解——网络核心
1.3.1 分组交换
在各种网络应用中,端系统彼此交换报文(message)。
报文能够包含协议设计者需要的任何东西。报文可以执行一种控制功能(例如,图1-2所示例子中的“你好”报文),也可以包含数据,例如电子邮件数据、JPEG图像或MP3音频文件。
为了从源端系统向目的端系统发送一个报文,源将长报文划分为较小的数据块,称之为分组(packet)。在源和目的地之间,每个分组都通过通信链路和分组交换机(packetswitch)。交换机主要有两类:路由器(router)和链路层交换机(Iink-layerswitch)。
分组以等于该链路最大传输速率的速度传输通过通信链路。因此,如果某源端系统或分组交换机经过一条链路发送一个L比特的分组,链路的传输速率为R比特/秒,则传输该分组的时间为 L/R 秒。
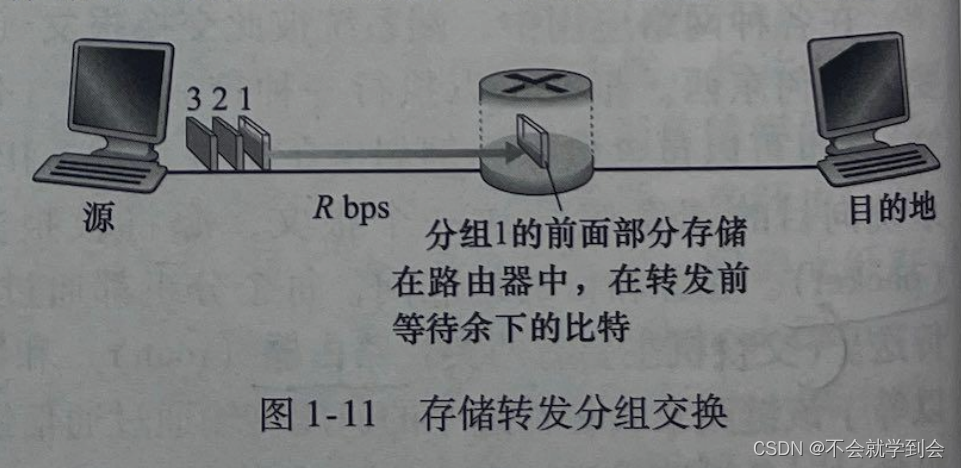
(1)存储转发传输
多数分组交换机在链路的输人端使用存储转发传输机制。存储转发传输是指在交换机能够开始向输出链路传输该分组的第一个比特之前,必须接收到整个分组。
图解——存储转发分组交换
**
(2)排队时延和分组丢失
每台分组交换机有多条链路与之相连。对于每条相连的链路,该分组交换机具有一个输出缓存(output bufer,也称为输出队列(output queue)),它用于存储路由器准备发往那条链路的分组。该输出缓存在分组交换中起着重要的作用。如果到达的分组需要传输到某条链路,但发现该链路正忙于传输其他分组,该到达分组必须在输出缓存中等待。因此,除了存储转发时延以外,分组还要承受输出缓存的排队时延(queuing delay)。这些时延是变化的,变化的程度取决于网络的拥塞程度。因为缓存空间的大小是有限的,一个到达的分组可能发现该缓存已被其他等待传输的分组完全充满了。在此情况下,将出现分组丢失(丢包)(packet loss),到达的分组或已经排队的分组之一将被丢弃。
(3)转发表和路由选择协议
路由器怎样决定它应当向哪条链路进行转发呢?
——路由器使用分组的目的地址来索引转发表并决定适当的出链路
在因特网中,每个端系统具有一个称为IP地址的地址。当源主机要向目的端系统发送一个分组时,源在该分组的首部包含了目的地的IP地址。)如同邮政地址那样,该地址具有一种等级结构。当一个分组到达网络中的路由器时,路由器检查该分组的目的地址的一部分,并向一台相邻路由器转发该分组。更特别的是,每台路由器具有一个转发表(forwarding table),**用于将目的地址(或目的地址的一部分)映射成为输出链路。)**当某分组到达一台路由器时,路由器检查该地址,并用这个目的地址搜索其转发表,以发现适当的出链路。路由器则将分组导向该出链路。
图解——分组交换
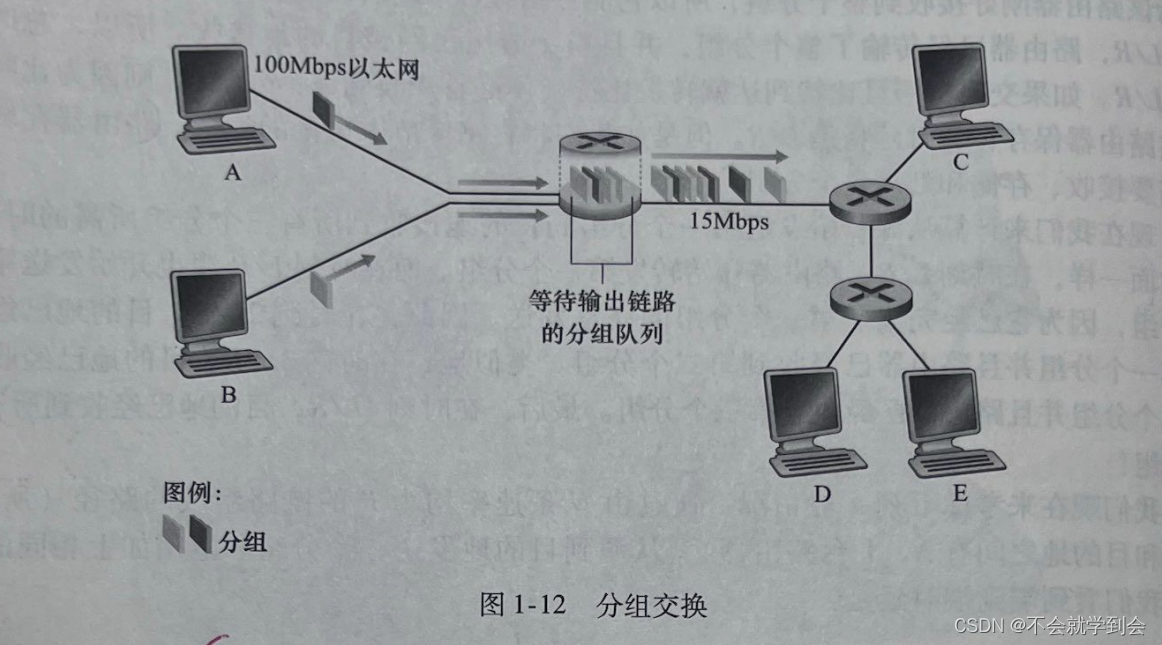
比喻4:端到端选路过程(分组交换)
端到端选路过程可以用一个不使用地图而喜欢问路的汽车驾驶员来类比。例如,假定Joe驾车从费城到佛罗里达州奥兰多市的LakesideDrive街156号。Joe 先驾车到附近的加油站,询问怎样才能到达佛罗里达州奥兰多市的LakesideDrive街156号。加油站的服务员从该地址中抽取了佛罗里达州部分,告诉Joe他需要上I-95南州际公路,该公路恰有一个邻近该加油站的人口。他又告诉Joe,一旦到了佛罗里达后应当再问当地人。于是,Je上了 1-95南州际公路,一直到达佛罗里达的Jacksonvile,在那里他向另一个加油站服务员问路。该服务员从地址中抽取了奥兰多市部分,告诉Joe他应当继续沿I-95公路到Daytona 海滩,然后再问其他人。在Daytona 海滩,另一个加油站服务员也抽取该地址的奥兰多部分,告诉Joe 应当走 I-4 公路直接前往奥兰多。Joe 走了 I-4公路,并从奥兰多出口下来。Joe 又向另一个加油站的服务员询问,这时该服务员抽取了该地址的Lakeside Drive 部分告诉了 Joe 到 Lakeside Drive 必须要走的路。一旦 Joe 到达了 Lakeside Drive,他向一个骑自行车的小孩询问了到达目的地的方法。这个孩子抽取了该地址的156号部分,并指示了房屋的方向。Joe最后到达了最终目的地。在上述类比中,那些加油站服务员和骑车的孩于可类比为路由器。
转发表是如何进行设置的?
因特网具有一些特殊的路由选择协议,用于自动地设置这些转发表。(例如,一个路由选择协议可以决定从每台路由器到每个目的地的最短路径,并使用这些最短路径结果来配置路由器中的转发表。
第5章将深入探讨这个问题
1.3.2 电路交换
课程引出——
通过网络链路和交换机移动数据有两种基本方法:电路交换(circuitswitching)和分组交换(packet switching)。)上一小节已经讨论过分组交换网络,现在我们将注意力转向电路交换网络。
在电路交换网络中,在端系统间通信会话期间,预留了端系统间沿路径通信所需要的资源(缓存,链路传输速率)。)
在分组交换网络中,这些资源则不是预留的;会话的报文按需使用这些资源,其后果可能是**不得不等待(即排队)**接人通信线路。
比喻5:电路交换与分组类比
一个简单的类比是,考虑两家餐馆,一家需要顾客预订(电路交换),而另一家不需要预订(分组),但不保证能安排顾客。对于需要预订的那家餐馆,我们在离开家之前必须承受先打电话预订的麻烦,但当我们到达该餐馆时,原则上我们能够立即入座并点菜。对于不需要预订的那家餐馆,我们不必麻烦地预订餐桌,但当我们到达该餐馆时,也许不得不先等待一张餐桌空闲后才能入座。
图解——一个简单电路交换网络
图1-13 显示了一个电路交换网络。在这个网络中,用4条链路互联了4台电路交换机。这些链路中的每条都有4条电路,因此每条链路能够支持4条并行的连接。每台主机(例如PC和工作站)都与一台交换机直接相连。当两台主机要通信时,该网络在两台王机之间创建一条专用的端到端连接(end-to-endconnection)。因此,主机A为了向主机B发送报文,网络必须在两条链路的每条上先预留一条电路。
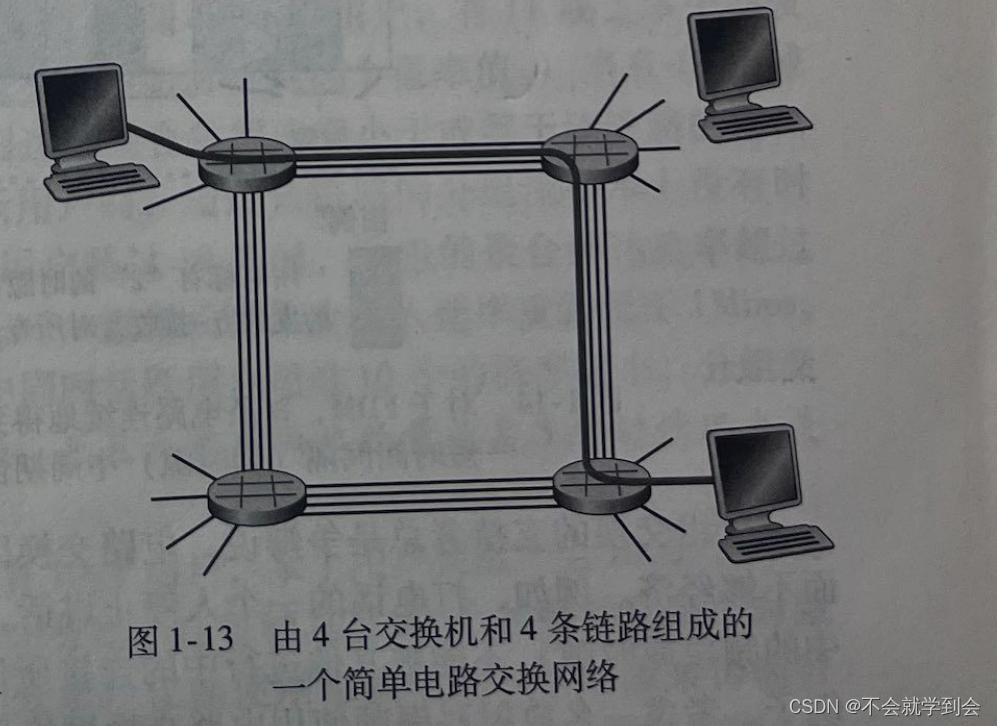
(1)电路交换网络中的复用

图解——FDM 和TDM

(2)分组交换与电路交换的对比
在描述了电路交换和分组交换之后,我们来对比一下这两者。
支持电路交换——
分组交换不适合实时服务(例如,电话和视频会议),因为它的端到端时延是可变的和不可预测的(主要是因为排队时延的变动和不可预测所致)。
支持分组交换——
①电路交换因为在静默期(silentperiod)专用电路空闲而不够经济。例如,打电话的一个人停止讲话,空闲的网络资源(在沿该连接路由的链路中的频段或时隙)不能被其他进行中的连接所使用。
②它提供了比电路交换更好的带宽共享;
③它比电路交换更简单、更有效,实现成本更低。
(3)分组交换更有效
虽然分组交换和电路交换在今天的电信网络中都是普遍采用的方式,但趋势无疑是朝着分组交换方向发展。甚至许多今天的电路交换电话网正在缓慢地向分组交换迁移。)特别是,电话网经常在昂贵的海外电话部分使用分组交换。
1.3.3 网络的网络
问题引出——
让端用户和内容提供商连接到接人ISP仅解决了连接难题中的很小一部分,因为因特网是由数以亿计的用户构成的。
要解决这个难题,接入ISP自身必须互联。通过创建网络的网络可以做到这一点,理解这个短语是理解因特网的关键。
因为接人ISP向全球传输ISP付费,故接人ISP被认为是客户(customer),而全球传输ISP 被认为是提供商(provider)。
我们通过5个网络结构模型引出今天最终使用的网络结构——
网络模型1:
用单一的全球传输ISP互联所有接入ISP。我们假想的全球传输ISP是一个由路由器和通信链路构成的网络,该网络不仅跨越全球,而且至少具有一台路由器靠近数十万接人ISP中的每一个。当然,对于全球传输ISP,建造这样一个大规模的网络将耗资巨大。为了有利可图,自然要向每个连接的接入ISP收费。
网络模型2:
如果某个公司建立并运营一个可赢利的全球传输ISP,其他公司建立自己的全球传输ISP并与最初的全球传输ISP竞争则是一件自然的事。这导致了(网络结构2)它由数十万接人ISP和多个全球传输ISP组成。接入ISP无疑喜欢网络结构2胜过喜欢网络结构1,因为它们现在能够根据价格和服务因素在多个竞争的全球传输提供商之间进行选择。然而,值得注意的是,这些全球传输ISP之间必须是互联的:不然的话,与某个全球传输ISP连接的接人ISP将不能与连接到其他全球传输ISP的接人ISP进行通信。)
网络模型3:
在某些区域,可能有较大的区域ISP(可能跨越整个国家),该区域中较小的区域ISP与之相连,较大的区域ISP 则与第一层ISP连接。
例如,在中国,每个城市有接入ISP,它们与省级ISP连接,省级ISP又与国家级ISP连接,国家级ISP最终与第一层ISP连接 。这个多层等级结构仍然仅仅是今天因特网的粗略近似,我们称它为网络结构3。
网络模型4:
为了建造一个与今天的因特网更为相似的网络,我们必须在等级化网络结构3上增加存在点(Point of Presence ,(PoP)、多宿、对等和因特网交换点。
PoP存在于等级结构的所有层次,但底层(接入ISP)等级除外。一个PoP 只是提供商网络中的一台或多台路由器(在相同位置)群组,其中客户ISP能够与提供商ISP连接。对于要与提供商PoP连接的客户网络,它能从第三方电信提供商租用高速链路将它的路由器之一直接连接到位于该PoP的一台路由器。任何ISP(除了第一层ISP)可以选择 多宿(multi-home),即可以与两个或更多提供商ISP连接。例如,一个接入ISP可能与两个区域ISP多宿,既可以与两个区域ISP 多宿,也可以与一个第一层 ISP 多宿。当一个 ISP 多宿时,即使它的提供商之一出现故障,它仍然能够继续发送和接收分组。
正如我们刚才学习的,客户ISP向它们的提供商ISP付费以获得全球因特网互联能力。客户ISP支付给提供商ISP的费用数额反映了它通过提供商交换的通信流量。为了减少这些费用,位于相同等级结构层次的邻近一对ISP能够对等(peer),(也就是说,能够直接将它们的网络连到一起,使它们之间的所有流量经直接连接而不是通过上游的中间ISP传输。)当两个 ISP 对等时,通常不进行结算,即任一个ISP不向其对等付费。如前面提到的那样,(第一层 ISP 也与另一个第一层 ISP 对等,它们之间无结算。)对于对等和客户-提供商关系的讨论, 沿着这些相同路线,第三方公司能够创建一个因特网交换点(Intermet Exchange Point,(IXP)(IXP是一个汇合点,多个 ISP能够在这里一起对等)(IXP通常位于一个有自己的交换机的独立建筑物中)
在今天的因特网中有400多个IXP 。我们称这个生态系统为网络结构4——由接人ISP、区城ISP、第一层ISP、PoP、多宿、对等和IXP组成
网络模型5:
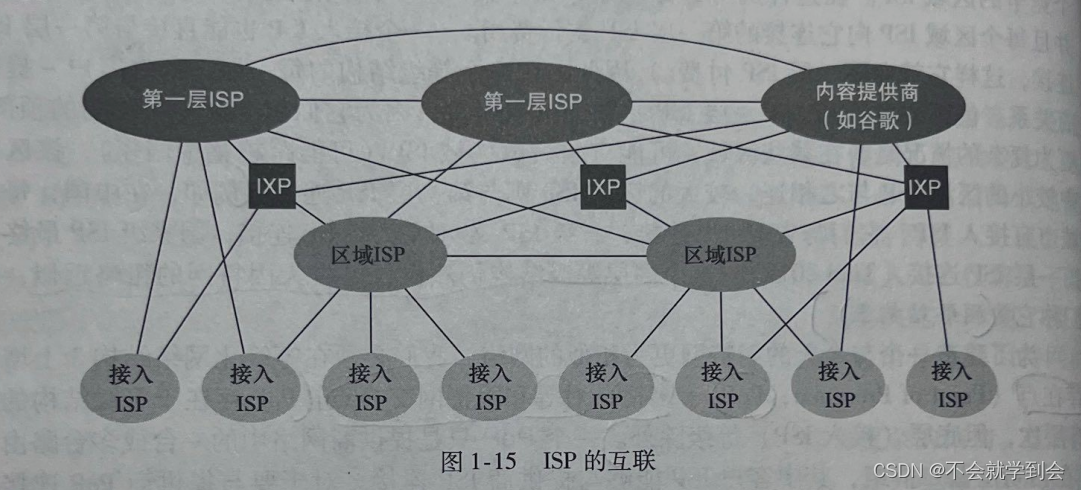
我们现在最终到达了网络结构5,它描述了现今的因特网。在图1-15 中显示了网络结构5,它通过在网络结构4顶部增加内容提供商网络 (content provider network)构建而成。如谷歌。谷歌是当前这样的内容提供商网络的一个突出例子。
谷歌估计有50~100个数据中心分布于北美、欧洲、亚洲、南美和澳大利亚。其中的某些数据中心容纳了超过十万台的服务器,而另一些数据中心则较小,仅容纳数百台服务器。谷歌数据中心都经过专用的TCP/IP网络互联,该网络跨越全球,不过独立于公共因特网。重要的是,谷歌专用网络仅承载出入谷歌服务器的流量。如图1-15所示,谷歌专用网络通过与较低ISP对等(无结算),尝试“绕过”因特网的较高层,采用的方式可以是直接与它们连接或者在IXP处与它们连接。
图解——ISP 的互联(当今网络结构)
总结网络核心
今天的因特网是一个网络的网络,其结构复杂,由十多个第一层ISP和数十万个较低层ISP组成。 ISP覆盖的区域多种多样,有些跨越多个大洲和大洋,有些限于狭窄的地理区域。较低层的ISP与较高层的ISP相连,较高层ISP彼此互联。 用户和内容提供商是较低层ISP的客户,较低层ISP是较高层ISP的客户。 近年来,主要的内容提供商也已经创建自己的网络,直接在可能的地方与较低层ISP互联。
1.4 分组交换网中的时延、丢包和吞吐量
课程引出——
在理想情况下,我们希望因特网服务能够在任意两个端系统之间随心所欲地瞬间移动数据而没有任何数据丢失。然而,这是一个极高的目标,实践中难以达到。与之相反,计算机网络必定要限制在端系统之间的吞吐量(每秒能够传送的数据量),在端系统之间引入时延,而且实际上也会丢失分组。
本节我们将开始研究和量化计算机网络中的时延、丢包和吞吐量等问题。
1.4.1 分组交换网中的时延概述
当分组从一个节点(主机或路由器)沿着这条路径到后继节点(主机或路由器),该分组在沿途的每个节点经受了几种不同类型的时延。
这些时延最为重要的是节点处理时延(nodal prcessing delay)、排队时延(queuing delay)、传输时延ransmission delay)和 ** 传播时延 (propagation delay),这些时延总体累加起来是节点总时延(total nodal delay)。
许多因特网应用,如搜索、Web 浏览、电子邮件、地图、即时讯息和PP语音,它们的性能受网络时延的影响很大。为了深人理解分组交换和计算机网络我们必须理解这些时延的性质和重要性。
时延的类型
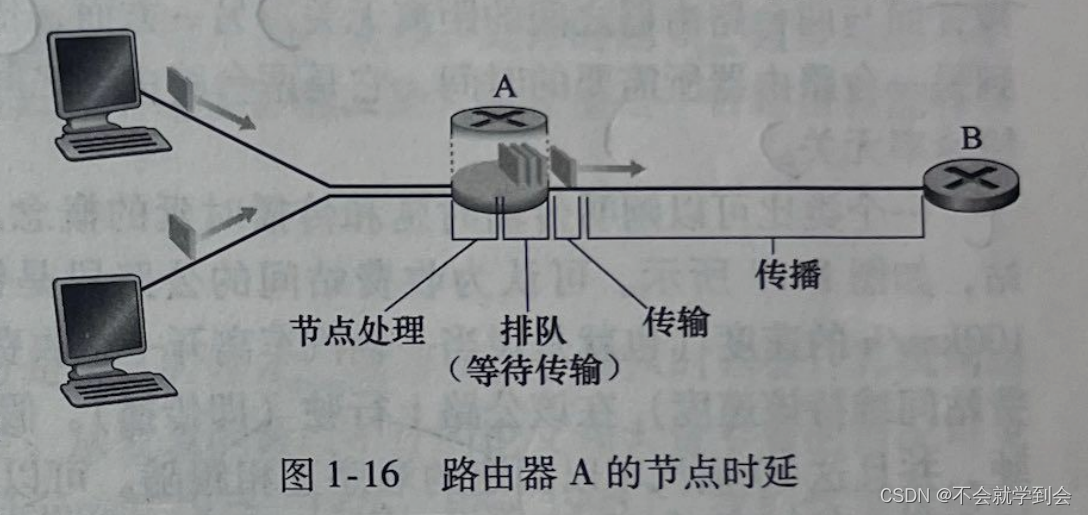
(2)处理时延
检查分组首部和决定将该分组导向何处 所需要的时间是处理时延的一部分。
处理时也能够包括其他因素,如检查比特级别的差错所需要的时间,该差错出现在从上游节点向路由器A传输这些分组比特的过程中。高速路由器的处理时延通常是微秒或更低的数量级。在这种节点处理之后,路由器将该分组引向通往路由器B链路之前的队列。
(2)排队时延
在队列中,当分组在链路上等待传输时,它经受排队时延。一**个特定分组的排队时延长度将取决于先期到达的正在排队等待向链路传输的分组数量。**如果该队列是空的,并且当前没有其他分组正在传输,则该分组的排队时延为0。另一方面,如果流量很大,并且许多其他分组也在等待传输,该排队时延将很长。我们将很快看到,到达分组期待发现的分组数量是到达该队列的流量的强度和性质的函数。实际的排队时延可以是毫秒到微秒量级。
(3)传输时延
假定分组以先到先服务方式传输——这在分组交换网中是常见的方式,仅当所有已经到达的分组被传输后,才能传输刚到达的分组。用L比特表示该分组的长度,用Rbps(即 b/s)表示从路由器A到路由器B的链路传输速率。例如,对于一条10Mbps的以太网链路,速率R=10Mbps;对于100Mbps的以太网链路,速率R=100Mbps。传输时延是L/R。
**这是将所有分组的比特推向链路(即传输,或者说发射)所需要的时间。**实际的传输 时延通常在毫秒到微秒量级。
(4)传播时延
一旦一个比特被推向链路,该比特需要向路由器B传播。 **从该链路的起点到路由器B传播所需要的时间是传播时延。**该比特以该链路的传播速率传播。该传播速率取决于该链路的物理媒体(即光纤、双绞铜线等),其速率范围是2x10°~3x10°m/s,这等于或略小于光速。该传播时延等于两台路由器之间的距离除以传播速率。即传播时延是d/s,其中d是路由器A和路由器B之间的距离,s是该链路的传播速率。一旦该分组的最后一个比特传播到节点B,该比特及前面的所有比特被存储于路由器B。整个过程将随着路由器B执行转发而持续下去。在广域网中,传播时延为毫秒量级。
(5)传输时延和传播时延的比较
传输时延是路由器推出分组所需要的时间,它是分组长度和链路传输速率的函数,而与两台路由器之间的距离无关。
传播时延是一个比特从一台路由器传播到另一台路由器所需要的时间,它是两台路由器之间距离的函数,而与分组长度或链路传输速率无关。
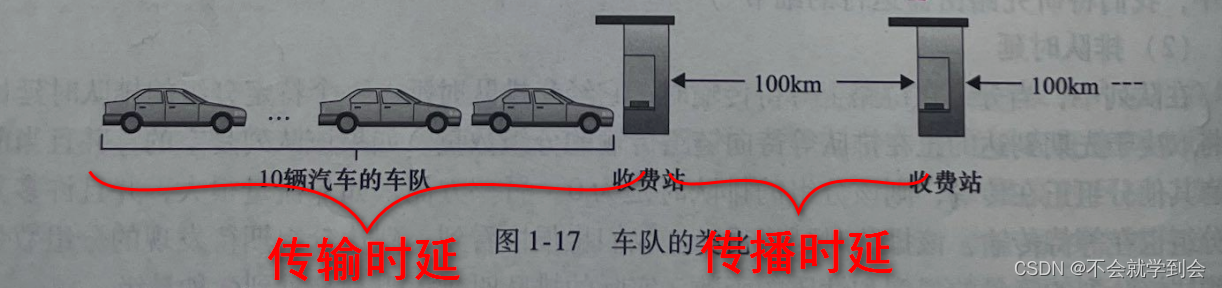
比喻6:传输时延和传播时延VS高速路亭与路程
一个类比可以阐明传输时延和传播时延的概念。考虑一条公路每100km有一个收费站 。可认为收费站间的公路段是链路,收费站是路由器。假定汽车以100km/h的速度(也就是说当一辆汽车离开一个收费站时,它立即加速到100km/h并在收费站间维持该速度)在该公路上行驶(即传播)。假定这时有10辆汽车作为一个车队在行驶,并且这10辆汽车以固定的顺序互相跟随。可以认为每辆汽车是一个比特,该车队是一个分组。同时假定每个收费站以每辆车12s的速度服务(即传输)一辆汽车,并且由于时间是深夜,因此该车队是公路上唯一一批汽车。最后,假定无论该车队的第一辆汽车何时到达收费站,它在入口处等待,直到其他9辆汽车到达并整队依次前行。
(因此,整个车队在它能够“转发”之前,必须存储在收费站。)收费站将整个车队推向公路所需要的时间是(10辆车)/(5辆车/min)=2min。该时间类比于一台路由器中的传输时延。
一辆汽车从一个收费站出口行驶到下一个收费站所需要的时间是100km/(100km/h)=1h。这个时间类比于传播时延。
因此,从该车队存储在收费站前到该车队存储在下一个收费站前的时间是“传输时延”与“传播时间”总和,在本例中为62min。
节点总时延

1.4.2 排队时延和丢包
(1)排队时延
节点时延的最为复杂和有趣的成分是排队时延dqueue。与其他3项时延不同的是,排队时延对不同的分组可能是不同的。
例如,如果10个分组同时到达空队列,传输的第一个分组没有排队时延,而传输的最后一个分组将经受相对大的排队时延(这时它要等待其他9个分组被传输)。因此,当表征排队时延时,人们通常使用统计量来度量,如平均排队时延排队时延的方差和排队时延超过某些特定值的概率。
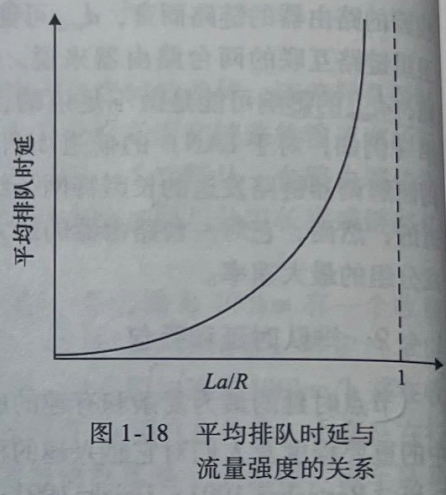
什么时候排队时延大,什么时候又不大呢?该问题的答案很大程度取决于流量到达该队列的速率、链路的传输速率和到达流量的性质,即流量是周期性到达还是以突发形式到达。为了更深人地领会某些要点,令a表示分组到达队列的平均速率(a的单位是分组/秒,即pkt/s)。前面讲过R是传输速率,即从队列中推出比特的速率(以bps即b/s为单位)。为了简单起见,也假定所有分组都是由工比特组成的。则比特到达队列的平均速率是Labps。最后,假定该队列非常大,因此它基本能容纳无限数量的比特。比率La/R被称为流量强度)(traffc intensity),它在估计排队时延的范围方面经常起着重要的作用。如果La/R>1,则比特到达队列的平均速率超过从该队列传输出去的速率。在这种不幸的情况下,该队列趋向于无限增加,并且排队时延将趋向无穷大!因此,流量工程中的一条金科玉律是:设计系统时流量强度不能大于1。
(2)丢包
丢包
在上述讨论中,我们已经假设队列能够容纳无穷多的分组。在现实中,一条链路前的队列只有有限的容量,尽管排队容量极大地依赖于路由器设计和成本。因为该排队容量是有限的,随着流量强度接近1,排队时延并不真正趋向无穷大。相反,到达的分组将发现一个满的队列。由于没有地方存储这个分组,路由器将丢弃(drop)该分组,即该分组将会丢失(lost)。
从端系统的角度看,上述丢包现象看起来是一个分组已经传输到网络核心,但它绝不会从网络发送到目的地。分组丢失的比例随着流量强度增加而增加。因此,一个节点的性能常常不仅根据时延来度量,而且根据丢包的概率来度量。正如我们将在后面各章中讨论的那样,丢失的分组可能基于端到端的原则重传,以确保所有的数据最终从源传送到了目的地。
1.4.3 端到端时延
当用户指定一个目的主机名字时,源主机中的该程序朝着目的地发送多个特殊的分组。当这些分组向着目的地传送时,它们通过一系列路由器。当路由器接收到这些特殊分组之一时,它向源回送一个短报文。该短报文包括路由器的名字和地址。
(1)实验:
假定在源和目的地之间有N-1台路由器。源将向网络发送N个特殊的分组,其中每个分组地址指向最终目的地。这N个特殊分组标识为从1到N,第一个分组标识为1,最后的分组标识为N。当第n台路由器接收到标识为n的第n个分组时,该路由器不是向它的目的地转发该分组,而是向源回送一个报文。当目的主机接收第N个分组时,它也会向源返回一个报文。该源记录了从它发送一个分组到它接收到对应返回报文所经历的时间;它也记录了返回该报文的路由器(或目的主机)的名字和地址。以这种方式,源能够重建分组从源到目的地所采用的路由,并且该源能够确定到所有中间路由器的往返时延。
源主机 gaia.cs.umass. edu(位于马萨诸塞大学)到cis.poly.edu(位于布鲁克林的理工大学)。
输出有6列:第一列是前面描述的n值,即路径上的路由器编号😭第二列是路由器的名字;第三列是路由器地址)(格式为 xxx.xxx.xxx.xxx);最后3列是3次实验的往返时延。如果源从任何给定路由器接收到的报文少于3条(由于网络中的丢包),Traceroute在该路由器号码后面放一个星号,并向那台路由器报告少于3次往返时间。
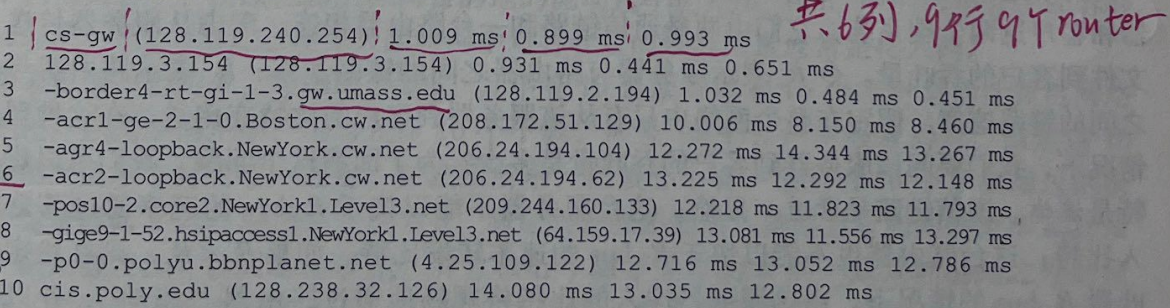
在上还跟踪中,在源和目的之间有9台路由器。这些路由器中的多数有一个名字,所有都有地址。例如,路由器3的名字是border4-rt-gi-1-3.gw.umass.edu,它的地址是128.119.2.194。看看为这台路由器提供的数据,可以看到在源和路由器之间的往返时延3 次实验中的第一次是1.03ms,后继两次实验的往返时延是0.48ms和0.45ms。这些往返时延包括刚才讨论的所有时延,即包括传输时延、传播时延、路由器处理时延和排队时延。因为该排队时延随时间变化,所以分组n发送到路由器n的往返时延实际上可能比分组n+1发送到路由器n+1的往返时延更长。
(2)端系统、应用程序和其他时延
除了处理时延、传输时延和传播时延,端系统中还有其他一些重要时延。(例如,希望向共享媒体(例如在WiFi或电缆调制解调器情况下)传输分组的端系统可能有意地延迟它的传输,把这作为它与其他端系统共享媒体的协议的一部分;我们将在第6章中详细地考虑这样的协议。另一个重要的时延是媒体分组化时延,这种时延出现在语音(oIP应用中。在VoIP中,发送方在向因特网传递分组之前必须首先用编码的数字化语音填充一个分组。这种填充一个分组的时间称为分组化时延,它可能较大,并能够影响用户感受到的 VoIP 呼叫的质量。这个问题将在本章结束的课后作业中进一步探讨。
1.4.4 计算机网络中的吞吐量
除了时延和丢包,计算机网络中另一个至关重要的性能测度是端到端吞吐量。为了定义吞吐量,考虑从主机A到主机B跨越计算机网络传送一个大文件。例如,也许是从一个P2P文件共享系统中的一个对等方向另一个对等方传送一个大视频片段。在任何时间瞬间的瞬时吞吐量(instantaneous throughput)是主机B接收到该文件的速率(以bps计)。(许多应用程序包括许多P2P文件共享系统,其用户界面显示了下载期间的瞬时吞吐量,也许你以前已经观察过它!)如果该文件由F比特组成,主机B接收到所有F比特用去T秒则文件传送的平均吞吐量(averagethroughput)是F/Tbps。对于某些应用程序如因特网电话,希望具有低时延和在某个阈值之上(例如,对某些因特网电话是超过24kbps,对某些实时视频应用程序是超过256kbps)的一致的瞬时吞吐量。对于其他应用程序,包括涉及文件传送的那些应用程序,时延不是决定性的,但是希望具有尽可能高的吞吐量。
令Rs表示服务器与路由器之间的链路速率;Rc表示路由器与客户之间的链路速率。其吞吐量是min{Rc,Rs},这就是说,它是瓶颈链路对于这种简单的两链路网络,(bottleneck link)的传输速率。

我们观察一个特定的例子。假定Rs=2Mbps,Rc=1Mbps,R=5Mbps,并且公共链路为10个下载平等划分它的传输速率。这时每个下载的瓶颈不再位于接入网中,而是位于核心中的共享链路了,该瓶颈仅能为每个下载提供500kbps 的吞吐量。因此每个下载的端到端吞吐量现在减少到500kbps。
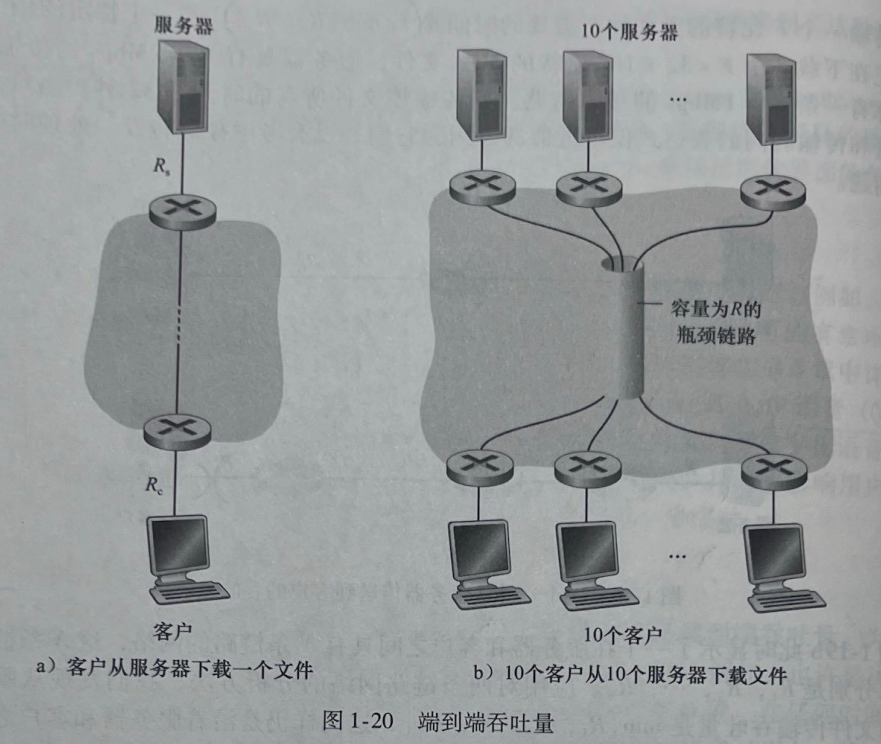
图1-19和图1-20中的例子说明吞吐量取决于数据流过的链路的传输速率。我们看当没有其他干扰流量时,其吞吐量能够近似为沿着源和目的地之间路径的最小传输速率图。1-20b中的例子更一般地说明了吞吐量不仅取决于沿着路径的传输速率,而且取决于扰流量。特别是,如果许多其他的数据流也通过这条链路流动,一条具有高传输速率的路仍然可能成为文件传输的瓶颈链路。
1.5 协议层次及其服务模型
课程引出——
我们已经看到,因网有许多部分:(大量的应用程序和协议、各种类型的端系统、分组交换机以及各种类型的链路级媒体。面对这种巨大的复杂性,存在着组织网络体系结构的希望吗?或者至少存着我们对网络体系结构进行讨论的希望吗?
幸运的是,对这两个问题的回答都是肯定的
1.5.1 分层的体系结构
比喻7——分层与航班类比
你怎样用一个结构来描述这样一个复杂的系统?该系统具有票务代理行李检查、登机口人员、飞行员、飞机、空中航行控制和世界范围的导航系统。描述这系统的一种方式是,描述当你乘某个航班时,你(或其他人替你)要采取的一系列动作你要购买机票,托运行李,去登机口,并最终登上这次航班。该飞机起飞,飞行到目的地。当飞机着陆后,你从登机口离机并认领行李。如果这次行程不理想,你向票务机构投诉这次航班(你的努力一无所获)。

我们已经能从这里看出与计算机网络的某些类似:
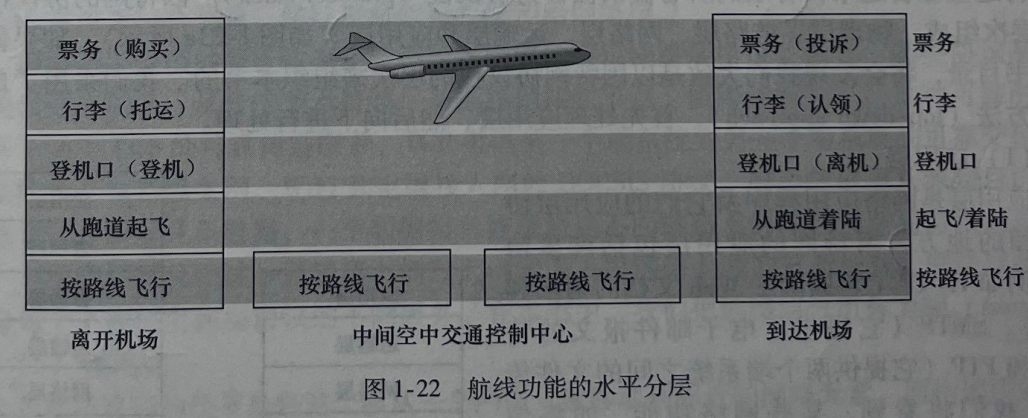
航空公司把你从源送到目的地;而分组被从因特网中的源主机送到目的主机。但这不是我们寻求的完全的类似。我们在图1-21中寻找某些结构。观察图1-21,我们注意到在每一端都有票务功能;还对已经检票的乘客有托运行李功能,对已经检票并已经检查过行李的乘客有登机功能。对于那些已经通过登机口的乘客(即已经经过检票、行李检查和通过登机口的乘客),有起飞和着陆的功能,并且在飞行中,有飞机按预定路线飞行的功能。这提示我们能够以水平的方式看待这些功能,如图1-22所示
图1-22将航线功能划分为一些层次,提供了我们能够讨论航线旅行的框架。注意到每个层次与其下面的层次结合在一起,实现了某些功能、服务。在票务层及以下,完成了一个人从航线柜台到航线柜台的转移。在行李层及以下,完成了人和行李从行李托运到行李认领的转移。注意到行李层仅对已经完成票务的人提供服务。在机口层,完成了人和行李从离港登机口到到港登机口的转移。在起飞/着陆层,完成了一个人和手提行李从跑道到跑道的转移。
每个层次通过以下方式提供服务:①在这层中执行了某些动作(例如在登机口层,某飞机的乘客登机和离机);②使用直接下层的服务(例如,在登机口层使用起飞/着陆层的跑道到跑道的旅客转移服务)。
利用分层的体系结构,我们可以讨论一个大而复杂系统的定义良好的特定部分。这种简化本身由于提供模块化而具有很高价值,这使某层所提供的服务实现易于改变。只要该层对其上面的层提供相同的服务,并且使用来自下面层次的相同服务,当某层的实现变化时,该系统的其余部分保持不变。
1.协议分层
一个协议层能够用软件、硬件或两者的结合来实现。诸如HTTP和SMTP这样的应用层协议几乎总是在端系统中用软件实现,运输层协议也是如此)(因为物理层和数据链路层负责处理跨越特定链路的通信,它们通常在与给定链路相关联的网络接口卡(例如以太网或WiFi接口卡)中实现。)(网络层经常是硬件和软件实现的混合体。)还要注意的是,如同分层的航线体系结构中的功能分布在构成该系统的各机场和飞行控制中心中一样,一个第n层协议也分布在构成该网络的端系统、分组交换机和其他组件中。这就是说,第n层协议的不同部分常常位于这些网络组件的各部分中。
将这些综合起来,各层的所有协议被称为协议栈(protocolstack)。因特网的协议栈由5 个层次组成:物理层、链路层、网络层、运输层和应用层 。如果你查看本书目录,将会发现我们大致是以因特网协议栈的层次来组织本书的。我们采用了自顶向下方法(top-down approach),首先处理应用层,然后向下进行处理。

(1)应用层
应用层是网络应用程序及它们的应用层协议存留的地方。因特网的应用层包括许多协议,例如 HTTP(它提供了 Web 文档的请求和传送)、SMTP(它提供了电子邮件报文的传输)和FTP(它提供两个端系统之间的文件传送)。我们将看到,某些网络功能,如将像www.iet.org这样对人友好的端系统名字转换为32比特的网络地址,也是借助于特定的应用层协议即域名系统(DNS)完成的。我们将在第2章中看到,创建并部署我们自己的新应用层协议是非常容易的。
应用层协议分布在多个端系统上,而一个端系统中的应用程序使用协议与另一个端系统中的应用程序交换信息分组。我们把这种位于应用层的信息分组称为报文(message)。
(2)运输层
因特网的运输层在应用程序端点之间传送应用层报文。(在因特网中,有两种运输协议,即(TCP和UDP)利用其中的任一个都能运输应用层报文。
TCP 向它的应用程序提供了面向连接的服务。这种服务包括了应用层报文向目的地的确保传递和流量控制(即发送方/接收方速率匹配)。TCP也将长报文划分为短报文,并提供拥塞控制机制,因此当网络拥塞时,源抑制其传输速率。
UDP协议向它的应用程序提供无连接服务。这是一种不提供不必要服务的服务,没有可靠性,没有流量控制,也没有拥塞控制
在本书中,我们把运输层的分组称为报文段(segment)。
(3)网络层
因特网的网络层负责将称为数据报(datagram)的网络层分组从一台主机移动到另一台主机。在一台源主机中的因特网运输层协议(TCP或UDP)向网络层递交运输层报文段和目的地址,就像你通过邮政服务寄信件时提供一个目的地址一样。
因特网的网络层包括著名的网际协议IP,该协议定义了在数据报中的各个字段以及端系统和路由器如何作用于这些字段。IP仅有一个,所有具有网络层的因特网组件必须运行IP。因特网的网络层也包括决定路由的路由选择协议,它根据该路由将数据报从源传输到目的地。因特网具有许多路由选择协议。如我们在1.3节所见,因特网是一个网络的网络,并且在一个网络中,其网络管理者能够运行所希望的任何路由选择协议。尽管网络层包括了网际协议和一些路由选择协议,但通常把它简单地称为IP层,这反映了是将因特网连接在一起的黏合剂这样的事实。
(4)链路层
因特网的网络层通过源和目的地之间的一系列路由器路由数据报。为了将分组从一个节点(主机或路由器)移动到路径上的下一个节点,网络层必须依靠该链路层的服务。特别是在每个节点,网络层将数据报下传给链路层,链路层沿着路径将数据报传递给下一个节点,在该下一个节点,链路层将数据报上传给网络层。由链路层提供的服务取决于应用于该链路的特定链路层协议。例如,某些协议基于链路提供可靠传递,从传输节点跨越一条链路到接收节点。值得注意的是,这种可靠的传递服务不同于 TCP的可靠传递服务,TCP提供从一个端系统到另一个端系统的可靠交付。链路层的例子包括以太网、WiFi和电缆接入网的 DOCSIS 协议。因为数据报从源到目的地传送通常需要经过几条链路,一个数据报可能被沿途不同链路上的不同链路层协议处理。例如,一个数据报可能被一段链路上的以太网和下一段链路上的PPP所处理。网络层将受到来自每个不同的链路层协议的不同服务。在本书中,我们把链路层分组称为帧(frame)。
(5)物理层
虽然链路层的任务是将整个帧从一个网络元素移动到邻近的网络元素,而物理层的任务是将该帧中的一个个比特从一个节点移动到下一个节点。在这层中的协议仍然是链路相关的,并且进一步与该链路(例如,双绞铜线、单模光纤)的实际传输媒体相关。例如,以太网具有许多物理层协议:一个是关于双绞铜线的,另一个是关于同轴电缆的,还有一个是关于光纤的,等等。在每种场合中,跨越这些链路移动一个比特是以不同的方式进行的。
2.OSl 模型
详细地讨论过因特网协议栈后,我们应当提及它不是唯一的协议栈。特别是在20世纪70年代后期,**国际标准化组织(IS0)**提出计算机网络围绕7层来组织,称为开放系统互联模型。
OSI参考模型的7层是:应用层、表示层、会话层、运输层、网络层、数据链路层和物理层。这些层次中,5层的功能大致与它们名字类似的因特网对层的功能相同。所以,我们来考虑 OSI参考模型中附加的两个层,即表示层和会话层。
表示层的作用是使通信的应用程序能够解释交换数据的含义。这些服务包括数据压缩和数据加密(它们是自解释的)以及数据描述(这使得应用程序不必担心在各台计算机中表示存储的内部格式不同的问题)。
会话层提供了数据交换的定界和同步功能,包括了建立查点和恢复方案的方法。
因特网缺少了在OSI参考模型中建立的两个层次,该事实引起了一些有趣的问题。这些层次提供的服务不重要吗?如果一个应用程序需要这些服务之一,将会怎样呢?因特网对这两个问题的回答是相同的:表示层、会话层,这留给应用程序开发者处理。应用程序开发者决定一个服务是否是重要的,如果该服务重要,应用程序开发者就应该在应用程序中构建该功能。
1.5.2 封装
图1-24显示了这样一条物理路径:数据从发送端系统的协议栈向下,沿着中间的链路层交换机和路由器的协议栈上上下下,然后向上到达接收端系统的协议栈。如我们将在本书后面讨论的那样,路由器和链路层交换机都是分组交换机。与端系统类似,路由器和链路层交换机以多层次的方式组织它们的网络硬件和软件。而路由器和链路层交换机并不实现协议栈中的所有层次。如图1-24所示,链路层交换机实现了第一层和第二层;路由器实现了第一层到第三层。例如,这意味着因特网路由器能够实现IP协议(一种第三层协议),而链路层交换机则不能。我们将在后面看到,尽管链路层交换机不能识别IP地址,但它们能够识别第二层地址,如以太网地址。值得注意的是,主机实现了所有5个层次,这与因特网体系结构将它的复杂性放在网络边缘的观点是一致的。
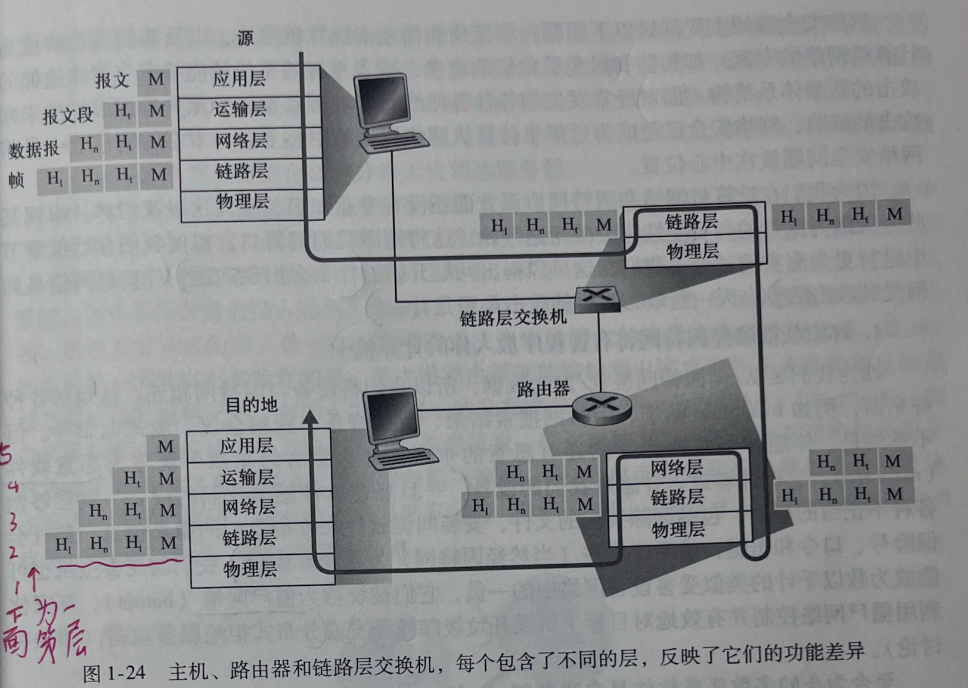
图1-24也说明了一个重要概念:封装(encapsulation)。在发送主机端,一个应用层报文(application-layer message)(图1-24 中的)被传送给运输层。在最简单的情况下运输层收取到报文并附上附加信息(所谓运输层首部信息,图1-24中的H),(该首部将被接收端的运输层使用。应用层报文和运输层首部信息一道构成了运输层报文段(transporlayer segment)。运输层报文段因此封装了应用层报文。附加的信息也许包括了下列信息允许接收端运输层向上向适当的应用程序交付报文的信息;差错检测位信息,该信息让接收方能够判断报文中的比特是否在途中已被改变。运输层则向网络层传递该报文段,网络层增加了如源和目的端系统地址等网络层首部信息(图1-24中的H),生成了网络层数据报(network-layer datagram)。该数据报接下来被传递给链路层,链路层(自然而然地增加它自己的链路层首部信息并生成链路层帧(link-layer frame)。
所以我们看到,在每层,一个分组具有两种类型的字段:首部字段和有效载荷字段(payload feld)。有效载荷通常是来自上一层的分组。
1.6 面对攻击的网络
1.坏家伙能够经因特网将有害程序放人你的计算机中
因为我们要从/向因特网接收/发送数据,所以我们将设备与因特网相连。这包括各好东西,例如Instagram 帖子、因特网搜索结果、流式音乐、视频会议、流式电影等。但不幸的是,伴随好的东西而来的还有恶意的东西,这些恶意的东西可统称为恶意软(malware),它们能够进入并感染我们的设备。一旦恶意软件感染我们的设备,就能够各种不正当的事情,包括删除我们的文件,安装间谍软件来收集我们的隐私信息,如社会保险号、口令和击键,然后将这些(当然经因特网)发送给坏家伙。我们的受害主机也可能成为数以千计的类似受害设备网络中的一员,它们被统称为僵尸网络(botmet),坏家伙利用僵尸网络控制并有效地对目标主机展开垃圾邮件分发或分布式拒绝服务攻击(很快讨论)。
至今为止的多数恶意软件是自我复制(self-replicating)的:一旦它感染了一台主机就会从那台主机寻求进入因特网上的其他主机,从而形成新的感染主机,再寻求进人更的主机。以这种方式,自我复制的恶意软件能够指数式地快速扩散。恶意软件能够以病毒或蠕虫的形式扩散。病毒(virus)是一种需要某种形式的用户交互来感染用户设备的恶意软件。典型的例子是包含恶意可执行代码的电子邮件附件。如果用户接收并打开这样的件,不经意间就在其设备上运行了该恶意软件。通常,这种电子邮件病毒是自我复制的例如,一旦执行,该病毒可能向用户地址簿上的每个接收方发送一个具有相同恶意附件的相同报文。蠕虫(worm)是一种无须任何明显用户交互就能进入设备的恶意软件。例如,用户也许运行了一个攻击者能够发送恶意软件的脆弱网络应用程序。在某些情况下,没有用户的任何干预,该应用程序可能从因特网接收恶意软件并运行它,生成了蠕虫。新近感染设备中的蠕虫则能扫描因特网,搜索其他运行相同网络应用程序的易受感染的主机。它发现其他易受感染的主机时,便向这些主机发送一个它自身的副本。今天,恶意软件无所不在且防范成本高。当你用这本书学习时,我们鼓励你思考下列问题:计算机网络设计者能够采取什么防御措施,以使与因特网连接的设备免受恶意软件的攻击?
2.坏家伙能够攻击服务器和网络基础设施
另一种宽泛类型的安全性威胁称为(拒绝服务攻击)(Denial-of-Service(DoS))attack)顾名思义,DoS 攻击使得网络、主机或其他基础设施部分不能由合法用户使用。Web服务器、电子邮件服务器、DNS服务器(在第2章中讨论)和机构网络都能够成为DoS攻击的目标。因特网 DoS攻击极为常见,每年会出现数以千计的DoS攻击[Moore 2001]。访问数字攻击图(Digital Attack Map)站点可以观看世界范围内每天最厉害的DoS攻击[DAM 2016]。大多数因特网 DoS 攻击属于下列三种类型之一:
- 弱点攻击,这涉及向一台目标主机上运行的易受攻击的应用程序或操作系统发送制作精细的报文。如果适当顺序的多个分组发送给一个易受攻击的应用程序或操作系统,该服务器可能停止运行,或者更糟糕的是主机可能崩溃。
- 带宽洪泛,攻击者向目标主机发送大量的分组,分组数量之多使得目标的接人链路变得拥塞,使得合法的分组无法到达服务器。
- 连接洪泛攻击者在目标主机中创建大量的半开或全开TCP连接(将在第3章中讨论TCP连接)。该主机因这些伪造的连接而陷人困境,并停止接受合法的连接。
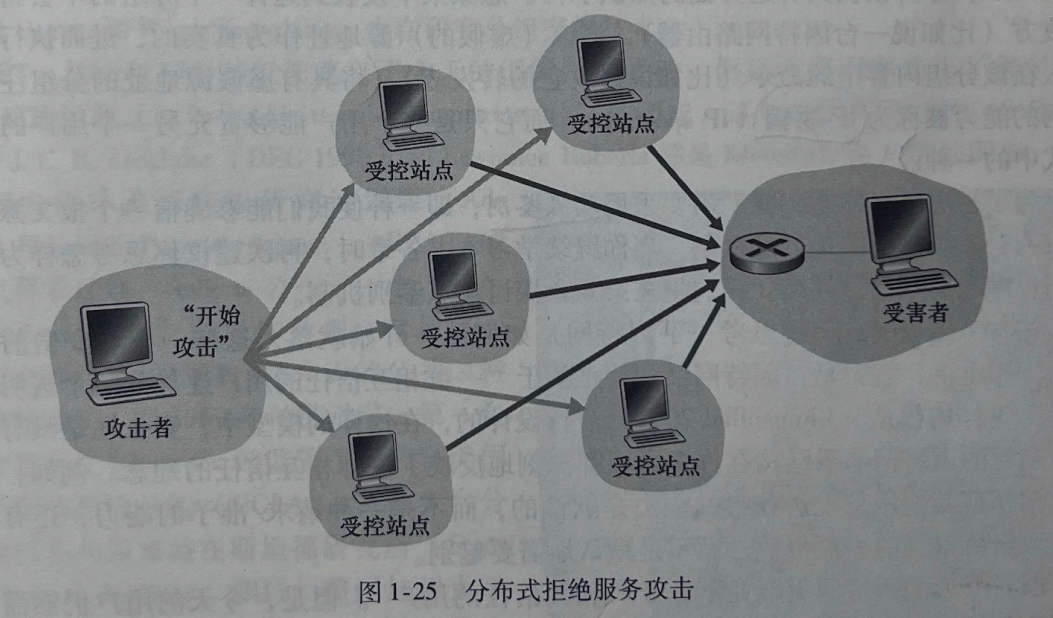
我们现在更详细地研究这种带宽洪泛攻击。回顾1.4.2节中讨论的时延和丢包问题显然,如果某服务器的接入速率为Rbps,则攻击者将需要以大约Rbps的速率来产生危害。如果R非常大的话,单一攻击源可能无法产生足够大的流量来伤害该服务器。此外如果从单一源发出所有流量的话,某上游路由器就能够检测出该攻击并在该流量靠近服务器之前就将其阻挡下来。在图1-25 中显示的分布式DoS(Distributed DoS,DDoS)中,攻击者控制多个源并让每个源向目标猛烈发送流量。使用这种方法,遍及所有受控源的聚合流量速率需要大约R的能力来使该服务陷入瘫痪。DDoS攻击充分利用由数以千计的受害主机组成的僵尸网络,这在今天是屡见不鲜的[DAM 2016]。相比于来自单一主机的 DoS攻击,DDoS 攻击更加难以检测和防范。
3.坏家伙能够嗅探分组
今天的许多用户经无线设备接人因特网,如WiFi连接的膝上计算机或使用蜂窝因特网连接的手持设备(在第7章中讨论)。无所不在的因特网接入极为便利并让移动用户方便地使用令人惊奇的新应用程序的同时,也产生了严重的安全脆弱性–在无线传输设备的附近放置一台被动的接收机,该接收机就能得到传输的每个分组的副本!这些分组包含了各种敏感信息,包括口令、社会保险号、商业秘密和隐秘的个人信息。记录每个流经的分组副本的被动接收机被称为分组嗅探器(packetsniffer)。
嗅探器也能够部署在有线环境中。在有线的广播环境中,如在许多以太网LAN中分组嗅探器能够获得经该LAN发送的所有分组。如在1.2节中描述的那样,电缆接入技术也广播分组,因此易于受到嗅探攻击。此外,获得某机构与因特网连接的接人路由器或接入链路访问权的坏家伙能够放置一台嗅探器以产生从该机构出入的每个分组的副本,再对嗅探到的分组进行离线分析,就能得出敏感信息。
4.坏家伙能够伪装成你信任的人
生成具有任意源地址、分组内容和目的地址的分组,然后将这个人工制作的分组传输到因特网中,因特网将忠实地将该分组转发到目的地,这一切都极为容易(当你学完这本教科书后,你将很快具有这方面的知识了!)。想象某个接收到这样一个分组的不会猜疑的接收方(比如说一台因特网路由器),将该(虚假的)源地址作为真实的,进而执行某些嵌人在该分组内容中的命令(比如说修改它的转发表)。将具有虚假源地址的分组注人因特网的能力被称为(IP 哄骗)(IPspoofng),而它只是一个用户能够冒充另一个用户的许多方式中的一种。
为了解决这个问题,我们需要采用端点鉴别,即一种使我们能够确信一个报文源自我们认为它应当来自的地方的机制。当你继续学习本书各章时,再次建议你思考怎样为网络应用程序和协议做这件事。我们将在第8章探讨端点鉴别机制。















 1519
1519











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









