






离线业务编排详解
在线业务和离线业务
在线业务
Deployment、StatefulSet以及 DaemonSet 这三个编排概念的共同之处是:它们主要编排的对象,都是"在线业务",即:Long Running Task(长作业)。比如常用的 Nginx、Tomcat,以及 MySQL 等等。这些应用一旦运行起来,除非出错或者停止,它的容器进程会一直保持在 Running 状态。
离线业务
也可以叫做Batch Job(计算业务)。这种业务在计算完成后就直接退出了,如果用 Deployment 来管理这种业务,会发现 Pod 会在计算结束后退出,然后被 Deployment Controller 不断地重启
Job解析
什么是Job?
一个用来描述离线业务的 API 对象
Job API 对象的定义
# vim job.yaml
apiVersion: batch/v1
kind: Job
metadata:
name: pi
spec:
template:
spec:
containers:
- name: pi
image: resouer/ubuntu-bc
command: ["sh", "-c", "echo 'scale=10000; 4*a(1)' | bc -l "]
restartPolicy: Never
backoffLimit: 4Job 对象不要求定义一个 spec.selector 来描述要控制哪些 Pod
spec.template 字段为Pod 模板
运行程序
echo "scale=10000; 4*a(1)" | bc -l
bc 命令:
是 Linux 里的"计算器"
-l 表示:是要使用标准数学库
a(1): 是调用数学库中的 arctangent 函数,计算 atan(1)。这是什么意思呢?
数学知识回顾:
tan(π/4) = 1。所以,4*atan(1)正好就是π,也就是 3.1415926…。
这是一个计算π值的容器。通过 scale=10000,指定了输出的小数点后的位数是 10000。在我的计算机上,这个计算大概用时 1 分 54 秒。
创建Job
kubectl create -f job.yaml查看 Job 对象
# kubectl describe jobs/pi
Name: pi
Namespace: default
Selector: controller-uid=c2db599a-2c9d-11e6-b324-0209dc45a495
Labels: controller-uid=c2db599a-2c9d-11e6-b324-0209dc45a495
job-name=pi
Annotations: <none>
Parallelism: 1
Completions: 1
..
Pods Statuses: 0 Running / 1 Succeeded / 0 Failed
Pod Template:
Labels: controller-uid=c2db599a-2c9d-11e6-b324-0209dc45a495
job-name=pi
Containers:
...
Volumes: <none>
Events:
FirstSeen LastSeen Count From SubobjectPath Type Reason Message
--------- -------- ----- ---- ------------- -------- ------ -------
1m 1m 1 {job-controller } Normal SuccessfulCreate Created pod: pi-rq5rl为了避免不同 Job 对象所管理的 Pod 发生重合,Job 对象在创建后,它的 Pod 模板,被自动加上了一个 controller-uid=< 一个随机字符串 > 这样的 Label。而这个 Job 对象本身,则被自动加上了这个 Label 对应的 Selector,保证了 Job 与它所管理的 Pod 之间的匹配关系。
这种自动生成的 Label 对用户并不友好,不太适合推广到 Deployment 等长作业编排对象上。
Pod 进入了 Running 状态说明它正在计算 Pi 的值
# kubectl get pods
NAME READY STATUS RESTARTS AGE
pi-rq5rl 1/1 Running 0 10s几分钟后计算结束,这个 Pod 就会进入 Completed 状态
# kubectl get pods
NAME READY STATUS RESTARTS AGE
pi-rq5rl 0/1 Completed 0 4m离线计算的 Pod 永远都不应该被重启
实现方式是在 Pod 模板中定义 restartPolicy=Never
事实上restartPolicy 在 Job 对象里只允许被设置为 Never 和 OnFailure;而在 Deployment 对象里,restartPolicy 则只允许被设置为 Always。
查看 Pod 日志
# kubectl logs pi-rq5rl //可以看到计算得到的 Pi 值已经被打印了出来
3.141592653589793238462643383279...离线作业失败处理方式
离线作业失败后 Job Controller 就会不断地尝试创建一个新 Pod,这个尝试肯定不能无限进行下去。所以,在 Job 对象的 spec.backoffLimit 字段里定义了重试次数为 4(即,backoffLimit=4,默认值是 6)
Job Controller 重新创建 Pod 的间隔是呈指数增加的,即下一次重新创建 Pod 的动作会分别发生在 10 s、20 s、40 s …后。
如果restartPolicy=OnFailure,离线作业失败后,Job Controller 就不会去尝试创建新的 Pod。但是,它会不断地尝试重启 Pod 里的容器。
# kubectl get pods
NAME READY STATUS RESTARTS AGE
pi-55h89 0/1 ContainerCreating 0 2s
pi-tqbcz 0/1 Error 0 5s可以看到,这时候会不断地有新 Pod 被创建出来。
spec.activeDeadlineSeconds 字段:
当一个 Job 的 Pod 运行结束后,它会进入 Completed 状态。但是,如果这个 Pod 因为某种原因一直不肯结束呢?
在 Job 的 API 对象里,有一个 spec.activeDeadlineSeconds 字段可以设置最长运行时间,比如:
spec:
backoffLimit: 5
activeDeadlineSeconds: 100
一旦运行超过了 100 s,这个 Job 的所有 Pod 都会被终止。并且,你可以在 Pod 的状态里看到终止的原因是 reason: DeadlineExceeded。
以上,就是一个 Job API 对象最主要的概念和用法
并行作业
离线业务之所以被称为 Batch Job,是因为它们可以以"Batch",也就是并行的方式去运行。
负责并行控制的参数有两个:
spec.parallelism:
定义一个 Job 在任意时间最多可以启动多少个 Pod 同时运行;
spec.completions:
定义 Job 至少要完成的 Pod 数目,即 Job 的最小完成数。
在之前计算 Pi 值的 Job 里,添加这两个参数:
注意:本例只是为了演示 Job 的并行特性,实际用途不大。不过现实中确实存在很多需要并行处理的场景。比如批处理程序,每个副本(Pod)都会从任务池中读取任务并执行,副本越多,执行时间就越短,效率就越高。这种类似的场景都可以用 Job 来实现。
apiVersion: batch/v1
kind: Job
metadata:
name: pi
spec:
parallelism: 2
completions: 4
template:
spec:
containers:
- name: pi
image: resouer/ubuntu-bc
command: ["sh", "-c", "echo 'scale=5000; 4*a(1)' | bc -l "]
restartPolicy: Never
backoffLimit: 4这样,我们就指定了这个 Job 最大的并行数是 2,而最小的完成数是 4。
创建这个 Job 对象:
# kubectl create -f job.yaml
这个 Job 其实也维护了两个状态字段,即 DESIRED 和 SUCCESSFUL,如下所示:
# kubectl get job //注意,最新版本的子段已经不一样了
NAME DESIRED SUCCESSFUL AGE
pi 4 0 3s
其中,DESIRED 的值,正是 completions 定义的最小完成数。
这个 Job 首先创建了两个并行运行的 Pod 来计算 Pi:
# kubectl get pods
NAME READY STATUS RESTARTS AGE
pi-5mt88 1/1 Running 0 6s
pi-gmcq5 1/1 Running 0 6s
而在 40 s 后,这两个 Pod 相继完成计算。
这时可以看到,每当有一个 Pod 完成计算进入 Completed 状态时,就会有一个新的 Pod 被自动创建出来,并且快速地从 Pending 状态进入到 ContainerCreating 状态:
# kubectl get pods
NAME READY STATUS RESTARTS AGE
pi-gmcq5 0/1 Completed 0 40s
pi-84ww8 0/1 Pending 0 0s
pi-5mt88 0/1 Completed 0 41s
pi-62rbt 0/1 Pending 0 0s# kubectl get pods
NAME READY STATUS RESTARTS AGE
pi-gmcq5 0/1 Completed 0 40s
pi-84ww8 0/1 ContainerCreating 0 0s
pi-5mt88 0/1 Completed 0 41s
pi-62rbt 0/1 ContainerCreating 0 0s
紧接着,Job Controller 第二次创建出来的两个并行的 Pod 也进入了 Running 状态:
# kubectl get pods
NAME READY STATUS RESTARTS AGE
pi-5mt88 0/1 Completed 0 54s
pi-62rbt 1/1 Running 0 13s
pi-84ww8 1/1 Running 0 14s
pi-gmcq5 0/1 Completed 0 54s
最终,后面创建的这两个 Pod 也完成了计算,进入了 Completed 状态。
这时,由于所有的 Pod 均已经成功退出,这个 Job 也就执行完了,所以你会看到它的 SUCCESSFUL 字段的值变成了 4:
# kubectl get pods
NAME READY STATUS RESTARTS AGE
pi-5mt88 0/1 Completed 0 5m
pi-62rbt 0/1 Completed 0 4m
pi-84ww8 0/1 Completed 0 4m
pi-gmcq5 0/1 Completed 0 5m# kubectl get job
NAME DESIRED SUCCESSFUL AGE
pi 4 4 5m
Job Controller工作原理总结
Job Controller 控制的对象,直接就是 Pod。
Job Controller 在控制循环中进行的调谐(Reconcile)操作,是根据实际在 Running 状态 Pod 的数目、已经成功退出的 Pod 的数目,以及 parallelism、completions 参数的值共同计算出在这个周期里,应该创建或者删除的 Pod 数目,然后调用 Kubernetes API 来执行这个操作。
在上面计算 Pi 值的这个例子中,当 Job 一开始创建出来时,实际处于 Running 状态的 Pod 数目 =0,已经成功退出的 Pod 数目 =0,而用户定义的 completions,也就是最终用户需要的 Pod 数目 =4。
所以,在这个时刻,需要创建的 Pod 数目 = 最终需要的 Pod 数目 - 实际在 Running 状态 Pod 数目 - 已经成功退出的 Pod 数目 = 4 - 0 - 0= 4。也就是说,Job Controller 需要创建 4 个 Pod 来纠正这个不一致状态。
可是,又定义了这个 Job 的 parallelism=2 规定了每次并发创建的 Pod 个数不能超过 2 个。所以,Job Controller 会对前面的计算结果做一个修正,修正后的期望创建的 Pod 数目应该是:2 个。
这时候,Job Controller 就会并发地向 kube-apiserver 发起两个创建 Pod 的请求。
类似地,如果在这次调谐周期里,Job Controller 发现实际在 Running 状态的 Pod 数目,比 parallelism 还大,那么它就会删除一些 Pod,使两者相等。
综上所述,Job Controller 实际上控制了,作业执行的并行度,以及总共需要完成的任务数这两个重要参数。而在实际使用时,你需要根据作业的特性,来决定并行度(parallelism)和任务数(completions)的合理取值。
Job控制器CronJob
Job 对象:CronJob
CronJob 描述的是定时任务,CronJob 是一个 Job 对象的控制器(Controller)
CronJob的 API 对象,如下所示:
# vim ./cronjob.yaml
apiVersion: batch/v1beta1
kind: CronJob
metadata:
name: hello
spec:
schedule: "*/1 * * * *"
jobTemplate:
spec:
template:
spec:
containers:
- name: hello
image: daocloud.io/library/busybox
args:
- /bin/sh
- -c
- date; echo Hello from the Kubernetes cluster
restartPolicy: OnFailureCronJob 与 Job 的关系,同 Deployment 与 Pod 的关系一样。
CronJob 是一个专门用来管理 Job 对象的控制器。它创建和删除 Job 的依据,是 schedule 字段定义的、一个标准的Unix Cron格式的表达式。
比如:
*/1 * * * *
分钟、小时、日、月、星期
这个 Cron 表达式里 _/1 中的 _ 表示从 0 开始,/ 表示"每",1 表示偏移量。所以,它的意思就是:从 0 开始,每 1 个时间单位执行一次。
本例表示从当前开始,每分钟执行一次
这里要执行的内容,就是 jobTemplate 定义的 Job 。
这个 CronJob 对象在创建 1 分钟后,就会有一个 Job 产生了,如下所示:
# kubectl create -f ./cronjob.yaml
cronjob "hello" created一分钟后
# kubectl get jobs
NAME DESIRED SUCCESSFUL AGE
hello-4111706356 1 1 2s
此时,CronJob 对象会记录下这次 Job 执行的时间:新版本中在describe里显示执行时间
# kubectl get cronjob hello
NAME SCHEDULE SUSPEND ACTIVE LAST-SCHEDULE
hello */1 * * * * False 0 Thu, 6 Sep 2018 14:34:00 -070
spec.concurrencyPolicy 字段:
由于定时任务的特殊性,很可能某个 Job 还没有执行完,另外一个新 Job 就产生了。这时候,可以通过 spec.concurrencyPolicy 字段来定义具体的处理策略。
concurrencyPolicy=Allow
默认情况,表示这些 Job 可以同时存在;
concurrencyPolicy=Forbid
表示不会创建新的 Pod,该创建周期被跳过;
concurrencyPolicy=Replace
表示新产生的 Job 会替换旧的、没有执行完的 Job。
spec.startingDeadlineSeconds 字段:
如果某一次 Job 创建失败,这次创建就会被标记为"miss"。当在指定的时间窗口内,miss 的数目达到 100 时,那么 CronJob 会停止再创建这个 Job。
这个时间窗口,可以由 spec.startingDeadlineSeconds 字段指定。比如 startingDeadlineSeconds=200,意味着在过去 200 s 里,如果 miss 的数目达到了 100 次,那么这个 Job 就不会被创建执行了。
k8s之共享存储pv&pvc
存储资源管理
在基于k8s容器云平台上,对存储资源的使用需求通常包括以下几方面:
1.应用配置文件、密钥的管理;
2.应用的数据持久化存储;
3.在不同的应用间共享数据存储;k8s的Volume抽象概念就是针对这些问题提供的解决方案,k8s的volume类型非常丰富,从临时目录、宿主机目录、ConfigMap、Secret、共享存储(PV和PVC)。
k8s支持Volume类型包括以下几类:
1.临时空目录(随着Pod的销毁而销毁) emptyDir: 2.配置类(将配置文件以Volume的形式挂载到容器内) ConfigMap:将保存在ConfigMap资源对象中的配置文件信息挂载到容器内的某个目录下 Secret:将保存在Secret资源对象中的密码密钥等信息挂载到容器内的某个文件中。 downwardAPI:将downwardAPI的数据以环境变量或文件的形式注入容器中。 gitErpo:将某Git代码库挂载到容器内的某个目录下 3.本地存储类 hostpath:将宿主机的目录或文件挂载到容器内进行使用。 local:Kubernetes从v1.9版本引入,将本地存储以PV的形式提供给容器使用,并能够实现存储空间的管理。 4.共享存储 PV(Persistent Volume):将共享存储定义为一种“持久存储卷”,可以被多个容器应用共享使用。 PVC(Persistent Volume Claim):用户对存储资源的一次“申请”,PVC申请的对象是PV,一旦申请成功,应用就能够像使用本地目录一样使用共享存储了。共享存储主要用于多个应用都能够使用存储资源,例如NFS存储、光纤存储Glusterfs共享文件系统等,在k8s系统中通过PV/StorageClass和PVC来完成定义,并通过volumeMount挂载到容器的目录或文件进行使用。
ConfigMap、Secret、emptyDir、hostPath等属于临时性存储,当pod被调度到某个节点上时,它们随pod的创建而创建,临时占用节点存储资源,当pod离开节点时,存储资源被交还给节点,pod一旦离开这个节点,存储就失效,不具备持久化存储数据的能力。与此相反,持久化存储拥有独立的生命周期,具备持久化存储能力,其后端一般是独立的存储系统如NFS、iSCSI、cephfs、glusterfs等。
pv与pvc
Kubernetes中的node代表计算资源,而PersistentVolume(PV)则代表存储资源,它是对各种诸如NFS、iSCSI、云存储等各种存储后端所提供存储块的统一抽象从而提供网络存储,通过它屏蔽低层实现细节。与普通volume不同,PV拥有完全独立的生命周期。 因为PV表示的是集群能力,它是一种集群资源,所以用户(通常是开发人员)不能直接使用PV,就像不能直接使用内存一样,需要先向系统申请,而 PVC 就是请求存储资源的。 Kubernetes通过PersistentVolumeClaim(PVC)代理用户行为,用户通过对PVC的操作实现对PV申请、使用、释放等操作,PVC是用户层面的资源。 PV 和 PVC 可以将 pod 和数据卷解耦,pod 不需要知道确切的文件系统或者支持它的持久化引擎。Kubernetes的共享存储供应模式包括静态和动态两种模式
静态模式 静态PV由系统管理员负责创建、提供、维护,系统管理员为用户屏蔽真正提供存储的后端及其实现细节,普通用户作为消费者,只需通过PVC申请、使用此类资源。 动态模式: 集群管理员无须手工创建PV,而是通过对Storage Class的设置对后端存储进行描述,“storage class”可以理解成某种具体的后端存储,标记为某种“类型(Class)”,此时要求PVC对存储的类型进行声明,系统将自动完成PV的创建与PVC的绑定。如果用户的PVC中“storage class”的值为"",则表示不能为此PVC动态创建PV。PV与PVC的绑定
用户创建包含容量、访问模式等信息的PVC,向系统请求存储资源。系统查找已存在PV或者监控新创建PV,如果与PVC匹配则将两者绑定。如果PVC创建动态PV,则系统将一直将两者绑定。PV与PVC的绑定是一一对应关系,不能重复绑定。如果系统一直没有为PVC找到匹配PV,则PVC无限期维持在"unbound"状态,直到系统找到匹配PV。实际绑定的PV容量可能大于PVC中申请的容量。
持久卷pv的类型
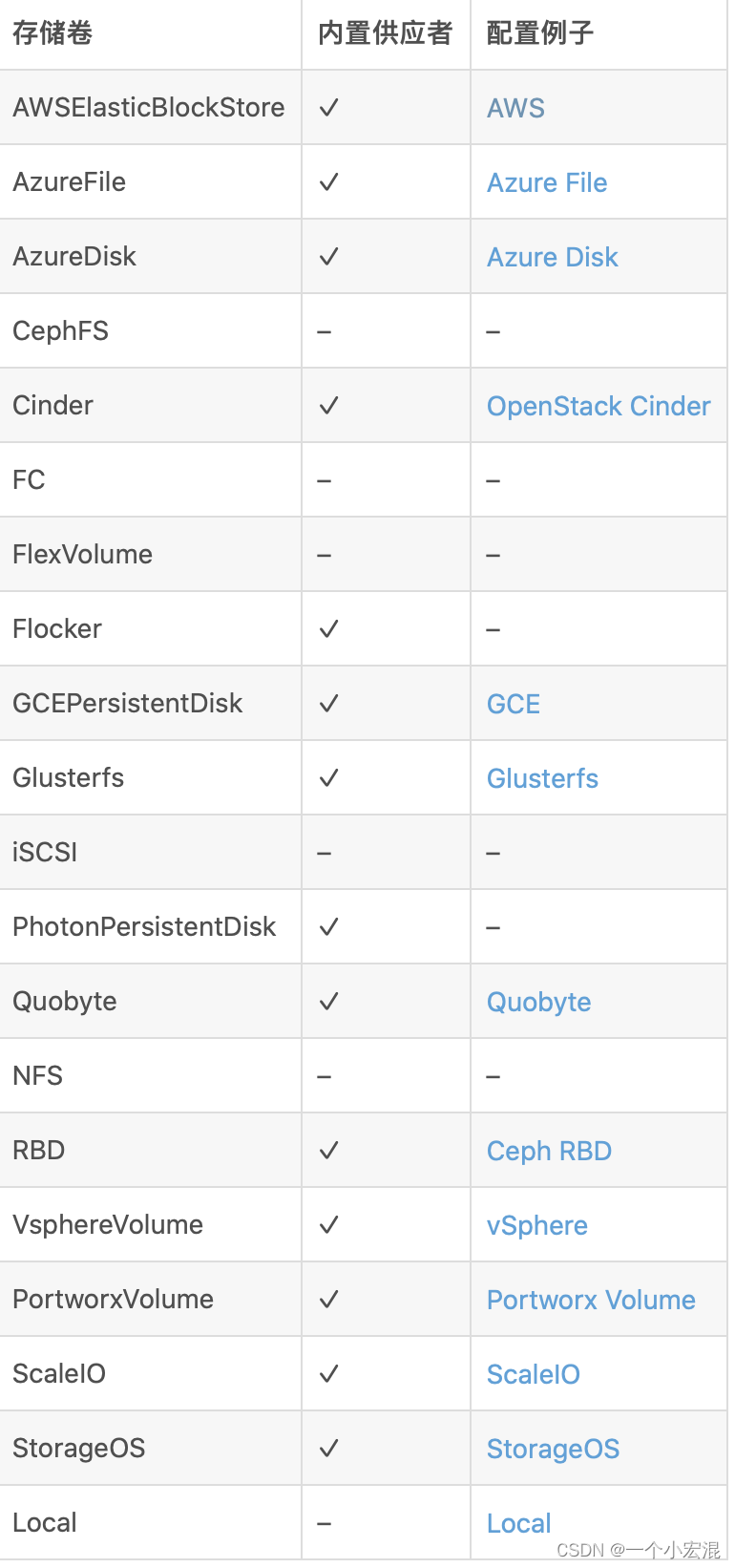
#PV 持久卷是用插件的形式来实现的。Kubernetes 目前支持以下插件
- GCEPersistentDisk
- AWSElasticBlockStore
- AzureFile
- AzureDisk
- FC (Fibre Channel)
- Flexvolume
- Flocker
- NFS
- iSCSI
- RBD (Ceph Block Device)
- CephFS
- Cinder (OpenStack block storage)
- Glusterfs
- VsphereVolume
- Quobyte Volumes
- HostPath (Single node testing only – local storage is not supported in any way and WILL NOT WORK in a multi-node cluster)
- Portworx Volumes
- ScaleIO Volumes
- StorageOS
实验mysql基于NFS共享存储实现持久化存储
安装NFS
#机器准备
k8s-master 制作nfs服务端作为共享文件系统
[root@k8s-master ~]# yum install -y nfs-utils rpcbind
[root@k8s-master ~]# mkdir /mnt/data #制作共享目录
[root@k8s-master ~]# vim /etc/exports
/mnt/data 192.168.122.0/24(rw,no_root_squash)
[root@k8s-master ~]# systemctl start rpcbind #启动服务
[root@k8s-master ~]# systemctl start nfs
# 使配置生效
[root@k8s-master ~]# exportfs -r
# 检查配置是否生效
[root@k8s-master ~]# exportfs
集群中的工作节点都需要安装客户端工具,主要作用是节点能够驱动 nfs 文件系统
只安装,不启动服务
# yum install -y nfs-utils
# showmount -e master_ip
# mount -t nfs master_ip:/mnt/data /mnt/data
master节点
制作pv.yaml(一般这个动作由 kubernetes 管理员完成,也就是我们运维人员)
[root@k8s-master ~]# mkdir /k8s/mysql -p
[root@k8s-master ~]# cd /k8s/mysql/
[root@k8s-master mysql]# vim pv.yaml
apiVersion: v1
kind: PersistentVolume #类型定义为pv
metadata:
name: my-pv #pv的名字
labels: #定义标签
type: nfs #类型为nfs
spec:
nfs: # 存储类型,需要与底层实际的存储一致,这里采用 nfs
server: 192.168.122.24 # NFS 服务器的 IP
path: "/mnt/data" # NFS 上共享的目录
capacity: #定义存储能力
storage: 3Gi #指定存储空间
accessModes: #定义访问模式
- ReadWriteMany #读写权限,允许被多个Node挂载
persistentVolumeReclaimPolicy: Retain #定义数据回收策略,这里是保留PV参数详解
1.存储能力(Capacity)
描述存储设备的能力,目前仅支持对存储空间的设置(storage=xx)。
2.访问模式(Access Modes)
对PV进行访问模式的设置,用于描述用户应用对存储资源的访问权限。访问模式如下:
ReadWriteOnce:读写权限,并且只能被单个pod挂载。
ReadOnlyMany:只读权限,允许被多个pod挂载。
ReadWriteMany:读写权限,允许被多个pod挂载。
某些PV可能支持多种访问模式,但PV在挂载时只能使用一种访问模式,多种访问模式不能同时生效。3.persistentVolumeReclaimPolicy定义数据回收策略
目前支持如下三种回收策略:
保留(Retain):保留数据,需要手工处理。
回收空间(Recycle):警告: 回收策略 Recycle 已被废弃。取而代之的建议方案是使用动态供应。如果下层的卷插件支持,回收策略 Recycle 会在卷上执行一些基本的 擦除(rm -rf /thevolume/*)操作,之后允许该卷用于新的 PVC 申领
删除(Delete):会将 PersistentVolume 对象从 Kubernetes 中移除,同时也会从外部基础设施(如 AWS EBS、GCE PD、Azure Disk 或 Cinder 卷)中移除所关联的存储资产。 就是把云存储一起删了。目前,只有 NFS 和 HostPath 两种类型的存储设备支持 “Recycle” 策略; AWS EBS、 GCE PD、Azure Disk 和 Cinder volumes 支持 “Delete” 策略。
4.storageClassName存储类别(Class)
PV可以设定其存储的类型(Class),通过 storageClassName参数指定一个 StorageClass 资源对象的名称。
具有特定“类别”的 PV 只能与请求了该“类别”的 PVC 进行绑定。未设定 “类别” 的 PV 则只能与不请求任何 “类别” 的 PVC 进行绑定。
相当于一个标签。
创建pv
[root@k8s-master mysql]# kubectl apply -f pv.yaml
persistentvolume/my-pv created
[root@k8s-master mysql]# kubectl get pvPV 生命周期的各个阶段(Phase)
某个 PV 在生命周期中,可以处于以下4个阶段之一:
- Available:可用状态,还未与某个 PVC 绑定。
- Bound:已与某个 PVC 绑定。
- Released:释放,绑定的 PVC 已经删除,但没有被集群回收存储空间 。
- Failed:自动资源回收失败。
pv创建成功目前属于可用状态,还没有与pvc绑定,那么现在创建pvc
创建pvc
[root@k8s-master mysql]# vim mysql-pvc.yaml
apiVersion: v1
kind: PersistentVolumeClaim #定义类型为PVC
metadata:
name: mypvc #声明pvc的名称,当做pod的卷使用时会用到
spec:
accessModes: #定义访问pvc的模式,与pv拥有一样的模式
- ReadWriteMany #读写权限,允许被多个pod挂载
resources: #声明可以请求特定数量的资源,目前仅支持 request.storage 的设置,即存储空间大小。
requests:
storage: 3Gi #定义空间大小
selector: #PV选择条件,标签选择器,通过标签选择
matchLabels:
type: "nfs" #选择pv类型的nfs
注意:当我们申请pvc的容量大于pv的容量是无法进行绑定的。
创建pvc
[root@k8s-master mysql]# kubectl apply -f mysql-pvc.yaml
persistentvolumeclaim/mypvc created
[root@k8s-master mysql]# kubectl get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
mypvc Bound my-pv 3Gi RWX pv-nfs 37s
status状态
- Available (可用): 表示可用状态,还未被任何PVC绑定
- Bound (已绑定):已经绑定到某个PVC
- Released (已释放):对应的PVC已经删除,但资源还没有被集群收回
- Failed:PV自动回收失败
Kubernetes中会自动帮我们查看pv状态为Available并且根据声明pvc容量storage的大小进行筛选匹配,同时还会根据AccessMode进行匹配。如果pvc匹配不到pv会一直处于pending状态。
mysql使用pvc持久卷
创建secret
[root@k8s-master mysql]# echo -n 'QianFeng@123!' | base64
UWlhbkZlbmdAMTIzIQ==
[root@k8s-master mysql]# vim mysql-secret.yaml
apiVersion: v1
data:
password: UWlhbkZlbmdAMTIzIQ==
kind: Secret
metadata:
annotations:
name: my-pass
type: Opaque
[root@k8s-master mysql]# kubectl apply -f mysql-secret.yaml
secret/my-pass created
[root@k8s-master mysql]# kubectl get secret
NAME TYPE DATA AGE
default-token-24c52 kubernetes.io/service-account-token 3 6d22h
my-pass Opaque 1 69s
创建myslq-pod文件
[root@k8s-master mysql]# cat mysql-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-mysql
spec:
replicas: 1
selector:
matchLabels:
app: mysql
template:
metadata:
labels:
app: mysql
spec:
containers:
- name: my-mysql
image: daocloud.io/library/mysql:5.7
ports:
- containerPort: 3306
env:
- name: MYSQL_ROOT_PASSWORD
valueFrom:
secretKeyRef:
name: my-pass
key: password
volumeMounts:
- name: mysql-data
mountPath: /var/lib/mysql
volumes:
- name: mysql-data
persistentVolumeClaim: #绑定pvc
claimName: mypvc #指定对应的pvc名字
[root@k8s-master mysql]# kubectl apply -f mysql-deployment.yaml
[root@k8s-master mysql]# kubectl get pod
NAME READY STATUS RESTARTS AGE
my-mysql-5474b6885f-c5dmp 1/1 Running 0 8s
[root@k8s-master mysql]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
my-mysql-5474b6885f-c5dmp 1/1 Running 0 40s 10.244.2.5 k8s-node2 <none> <none>
测试
[root@k8s-master ~]# cd /mnt/data/
[root@k8s-master data]# ll
总用量 188484
-rw-r----- 1 polkitd ssh_keys 56 11月 8 21:49 auto.cnf
-rw------- 1 polkitd ssh_keys 1680 11月 8 21:49 ca-key.pem
-rw-r--r-- 1 polkitd ssh_keys 1112 11月 8 21:49 ca.pem
-rw-r--r-- 1 polkitd ssh_keys 1112 11月 8 21:49 client-cert.pem
-rw------- 1 polkitd ssh_keys 1680 11月 8 21:49 client-key.pem
-rw-r----- 1 polkitd ssh_keys 688 11月 8 21:57 ib_buffer_pool
-rw-r----- 1 polkitd ssh_keys 79691776 11月 8 21:59 ibdata1
-rw-r----- 1 polkitd ssh_keys 50331648 11月 8 21:59 ib_logfile0
-rw-r----- 1 polkitd ssh_keys 50331648 11月 8 21:49 ib_logfile1
-rw-r----- 1 polkitd ssh_keys 12582912 11月 8 22:00 ibtmp1
drwxr-x--- 2 polkitd ssh_keys 4096 11月 8 21:49 mysql
drwxr-x--- 2 polkitd ssh_keys 8192 11月 8 21:49 performance_schema
-rw------- 1 polkitd ssh_keys 1680 11月 8 21:49 private_key.pem
-rw-r--r-- 1 polkitd ssh_keys 452 11月 8 21:49 public_key.pem
-rw-r--r-- 1 polkitd ssh_keys 1112 11月 8 21:49 server-cert.pem
-rw------- 1 polkitd ssh_keys 1676 11月 8 21:49 server-key.pem
drwxr-x--- 2 polkitd ssh_keys 8192 11月 8 21:49 sys动态绑定pv
StorageClass 相当于一个创建 PV 的模板,用户通过 PVC 申请存储卷,StorageClass 通过模板自动创建 PV,然后和 PVC 进行绑定。
StorageClass创建动态存储卷流程
集群管理员预先创建存储类(StorageClass);
用户创建使用存储类的持久化存储声明(PVC:PersistentVolumeClaim);
存储持久化声明通知系统,它需要一个持久化存储(PV: PersistentVolume);
系统读取存储类的信息;
系统基于存储类的信息,在后台自动创建PVC需要的PV;
用户创建一个使用PVC的Pod;
Pod中的应用通过PVC进行数据的持久化;
而PVC使用PV进行数据的最终持久化处理。

StorageClass支持的动态存储插件:
NFS Provisioner 是一个自动配置卷程序,它使用现有的和已配置的 NFS 服务器来支持通过持久卷声明动态配置 Kubernetes 持久卷。
注意:k8s 1.21版本中创建pvc时nfs-provisioner会报错
E0903 08:00:24.858523 1 controller.go:1004] provision “default/test-claim” class “managed-nfs-storage”: unexpected error getting claim reference: selfLink was empty, can’t make reference
解决方法: 修改 /etc/kubernetes/manifests/kube-apiserver.yaml文件 增加 - --feature-gates=RemoveSelfLink=false
spec:
containers:
- command:
- kube-apiserver
- --feature-gates=RemoveSelfLink=false # 增加这行
- --advertise-address=172.24.0.5
- --allow-privileged=true
- --authorization-mode=Node,RBAC
- --client-ca-file=/etc/kubernetes/pki/ca.crt配置nfs-provisioner授权
创建ServiceAccount、ClusterRole、ClusterRoleBinding等,为nfs-client-provisioner授权
# rbac.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: nfs-client-provisioner
# replace with namespace where provisioner is deployed
namespace: default
---
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: nfs-client-provisioner-runner
rules:
- apiGroups: [""]
resources: ["persistentvolumes"]
verbs: ["get", "list", "watch", "create", "delete"]
- apiGroups: [""]
resources: ["persistentvolumeclaims"]
verbs: ["get", "list", "watch", "update"]
- apiGroups: ["storage.k8s.io"]
resources: ["storageclasses"]
verbs: ["get", "list", "watch"]
- apiGroups: [""]
resources: ["events"]
verbs: ["create", "update", "patch"]
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: run-nfs-client-provisioner
subjects:
- kind: ServiceAccount
name: nfs-client-provisioner
# replace with namespace where provisioner is deployed
namespace: default
roleRef:
kind: ClusterRole
name: nfs-client-provisioner-runner
apiGroup: rbac.authorization.k8s.io
---
kind: Role
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: leader-locking-nfs-client-provisioner
# replace with namespace where provisioner is deployed
namespace: default
rules:
- apiGroups: [""]
resources: ["endpoints"]
verbs: ["get", "list", "watch", "create", "update", "patch"]
---
kind: RoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: leader-locking-nfs-client-provisioner
subjects:
- kind: ServiceAccount
name: nfs-client-provisioner
# replace with namespace where provisioner is deployed
namespace: default
roleRef:
kind: Role
name: leader-locking-nfs-client-provisioner
apiGroup: rbac.authorization.k8s.io部署nfs-client-provisioner
# nfs-provisioner.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nfs-client-provisioner
labels:
app: nfs-client-provisioner
# replace with namespace where provisioner is deployed
namespace: default #与RBAC文件中的namespace保持一致
spec:
replicas: 1
selector:
matchLabels:
app: nfs-client-provisioner
strategy:
type: Recreate
selector:
matchLabels:
app: nfs-client-provisioner
template:
metadata:
labels:
app: nfs-client-provisioner
spec:
serviceAccountName: nfs-client-provisioner
containers:
- name: nfs-client-provisioner
image: quay.io/external_storage/nfs-client-provisioner:latest
volumeMounts:
- name: nfs-client-root
mountPath: /persistentvolumes
env:
- name: PROVISIONER_NAME
value: gxf-nfs-storage #provisioner名称,请确保该名称与 nfs-StorageClass.yaml文件中的provisioner名称保持一致
- name: NFS_SERVER
value: 10.24.X.X #NFS Server IP地址
- name: NFS_PATH
value: /home/nfs/1 #NFS挂载卷
volumes:
- name: nfs-client-root
nfs:
server: 10.24.X.X #NFS Server IP地址
path: /home/nfs/1 #NFS 挂载卷# 部署
[root@kube-master ~]# kubectl apply -f rbac.yaml
[root@kube-master ~]# kubectl apply -f nfs-provisioner.yaml
[root@kube-master ~]# kubectl get pod
NAME READY STATUS RESTARTS AGE
nfs-client-provisioner-75bfdbdcd8-5mqbv 1/1 Running 0 4m24s创建StorageClass
# nfs-StorageClass.yaml
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: managed-nfs-storage
provisioner: gxf-nfs-storage #这里的名称要和provisioner配置文件中的环境变量PROVISIONER_NAME保持一致
reclaimPolicy: Retain # 默认为delete
parameters:
archiveOnDelete: "true" # false表示pv被删除时,在nfs下面对应的文件夹也会被删除,true正相反deployment 动态挂载
部署一个有2个副本的deployment,挂载共享目录
创建pvc,“storageClassName"为上面创建的"managed-nfs-storage”,即指定动态创建PV的模板文件的名字。
# test-pvclaim.yaml
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: test-claim
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 100Mi
storageClassName: managed-nfs-storage
[root@kube-master ~]# kubectl apply -f test-pvclaim.yaml
#deployment部署
# test-deploy.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: test-deploy
labels:
app: test-deploy
namespace: default #与RBAC文件中的namespace保持一致
spec:
replicas: 2
selector:
matchLabels:
app: test-deploy
strategy:
type: Recreate
selector:
matchLabels:
app: test-deploy
template:
metadata:
labels:
app: test-deploy
spec:
containers:
- name: test-pod
image: busybox:1.24
command:
- "/bin/sh"
args:
- "-c"
# - "touch /mnt/SUCCESS3 && exit 0 || exit 1" #创建一个SUCCESS文件后退出
- touch /mnt/SUCCESS5; sleep 50000
volumeMounts:
- name: nfs-pvc
mountPath: "/mnt"
# subPath: test-pod-3 # 子路径 (这路基代表存储卷下面的test-pod子目录)
volumes:
- name: nfs-pvc
persistentVolumeClaim:
claimName: test-claim #与PVC名称保持一致statefulset 动态挂载
# test-sts-1.yaml
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: test-sts
labels:
k8s-app: test-sts
spec:
serviceName: test-sts-svc
replicas: 3
selector:
matchLabels:
k8s-app: test-sts
template:
metadata:
labels:
k8s-app: test-sts
spec:
containers:
- image: busybox:1.24
name: test-pod
command:
- "/bin/sh"
args:
- "-c"
# - "touch /mnt/SUCCESS3 && exit 0 || exit 1" #创建一个SUCCESS文件后退出
- touch /mnt/SUCCESS5; sleep 50000
imagePullPolicy: IfNotPresent
volumeMounts:
- name: nfs-pvc
mountPath: "/mnt"
volumeClaimTemplates:
- metadata:
name: nfs-pvc
spec:
accessModes: ["ReadWriteMany"]
storageClassName: managed-nfs-storage
resources:
requests:
storage: 20Mi
[root@kube-master ~]# kubectl apply -f test-sts-1.yaml
[root@kube-master ~]# kubectl get sts
NAME READY AGE
test-sts 3/3 4m46sStatefulSet有状态的应用
在Kubernetes系统中,Pod的管理对象RC、Deployment、DaemonSet都是面向无状态的服务,它们所管理的Pod的IP、名字,启停顺序等都是随机的。但现实中有很多服务是有状态的,特别是一些复杂的中间件集群。例如Mysql集群、MongoDB集群、Kafka集群、Zookeeper集群等,这些都有一个共同的特点:
1.每个节点都有固定的ID,通过这个ID,集群中的成员可以相互发现并且通信。
2.集群的规模是比较固定的,集群规模不能随意改动。
3.集群里的每个节点都是有状态的,通常会持久化数据到永久存储中。
4.如果磁盘损坏,集群里的某个节点就无法正常运行,集群功能受损。
StatefulSet本质上是Deployment的一种变体,在v1.9版本中已成为GA版本,它为了解决有状态服务的问题,它所管理的Pod拥有固定的Pod名称,启停顺序的,如果使用RC/Deployment控制副本的方式实现有状态的集群那么pod的名字是没有办法控制的因为是随机产生,同时也无法为每一个pod确定唯一不变的ID号,为了解决这个问题,在k8s中引用了新的资源对象即StatefulSet。在StatefulSet中,Pod名字称为网络标识(hostname),还必须要用到共享存储。
1.StatefulSet里的每个Pod都有稳定、唯一的网络标识,可以用来发现集群中的其他成员,比如说StatefulSet的名字是N,那么第一个pod的名字就是N-0,第二个就是N-1,以此类推
2.StatefulSet控制的pod副本的启停顺序是受控制的,操作第n个pod,前面的n-1的pod已经是运行且准备好的状态。
3.StatefulSet里的pod采用稳定的持久化存储卷,通过PV/PVC来实现,删除Pod时默认不会删除与StatefulSet相关的存储卷(目的是为了保证数据的安全性)所以,StatefulSet的核心功能,就是通过某种方式,记录这些状态,然后在Pod被重新创建时,能够为新Pod恢复这些状态.
在Deployment中,与之对应的服务是service,而在StatefulSet中与之对应的headless service,headless service,即无头服务,与service的区别就是它没有Cluster IP,解析它的名称时将返回该Headless Service对应的全部Pod的Endpoint列表。
除此之外,StatefulSet在Headless Service的基础上又为StatefulSet控制的每个Pod副本创建了一个DNS域名,这个域名的格式为:
$(podname).(headless server name)
StatefulSet实现Pod的存储状态
通过PVC机制来实现存储状态管理
在StatefulSet对象中除了定义PodTemplate还会定义一个volumeClaimTemplates凡是被这个StatefulSet管理的Pod都会声明一个对应的PVC,这个PVC的定义就来自于 volumeClaimTemplates这个模板字段,这个PVC的名字,会被分配一个与这个Pod完全一致的编号。
把一个Pod比如N-0删除之后,这个Pod对应的PVC和PV并不会被删除,而这个Volume 里已经写入的数据,也依然会保存在远程存储服务里
StatefulSet在重新创建N-0这个pod的时候.它声明使用的PVC的名字还是叫作:N-0 这个PVC的定义,还是来自于PVC模板(volumeClaimTemplates)这是StatefulSet创建 Pod的标准流程
Kubernetes为它查找名叫N-0的PVC时,就会直接找到旧Pod遗留下来的同名的 PVC进而找到跟这个PVC绑定在一起的PV.这样新的Pod就可以挂载到旧Pod对应的那个Volume并且获取到保存在Volume里的数据.通过这种方式Kubernetes的StatefulSet就实现了对应用存储状态的管理
StatefulSet 的应用特点
-
StatefulSet的核心功能就是,通过某种方式记录应用状态,在Pod被重建的时候,通过这种方式还可以恢复原来的状态。
-
StatefulSet由以下几个部分组成:
-
Headless Service 用于定义网络标识(DNS)
-
volumeClaimTemplates 用于创建PV
-
StatefulSet 用于定义具体应用
-
-
稳定且有唯一的网络标识符 当节点挂掉,既pod重新调度后其PodName和HostName不变,基于Headless Service来实现
-
稳定且持久的存储 当节点挂掉,既pod重新调度能访问到相同的持久化存储,基于PVC实现
-
有序、平滑的扩展、部署 即Pod是有顺序的,在部署或者扩展的时候要依据定义的顺序依次进行(即从0到N-1,在下一个Pod运行之前所有之前的Pod必须都是Running和Ready状态),基于init containers来实现。
-
有序、平滑的收缩、删除 既Pod是有顺序的,在收缩或者删除的时候要依据定义的顺序依次进行(既从N-1到0,既倒序)。
-
拓扑状态。是应用多个实例之间的不完全对等的关系,这些应用实例是必须按照定义的顺序启动的。例如主应用A先于从应用B启动,如果把A和B删掉,应用还要按照先启动主应用A再启动从应用B,且创建的应用必须和原来的应用的网络标识一样(既PodName和HostName)。这样他们就可以按照原来的顺序创建了。
-
存储状态。应用实例分别绑定了不同的数据存储,Pod A第一次读到的数据要和10分钟后读到的数据,是同一份。哪怕这期间Pod A被重建。这种典型的例子就是数据库应用的多个存储实例。
实战1-通过StatefulSet创建nginx
由于statefulSet在创建的时候使用的是动态绑定pvc,而动态绑定pvc是需要插件支持的,一下实验通过手动创建pv在通过StatefulSet自动实现pvc申请持久卷。
1.创建基于NFS的pv持久卷
[root@k8s-master ~]# mkdir /mnt/data-1 #创建共享目录
[root@k8s-master ~]# mkdir /mnt/data-2
[root@k8s-master ~]# vim /etc/exports
/mnt/data-1 172.16.229.*/24 (rw,sync,insecure,no_subtree_check,no_root_squash)
/mnt/data-2 172.16.229.*/24 (rw,sync,insecure,no_subtree_check,no_root_squash)
[root@k8s-master ~]# systemctl restart nfs[root@k8s-master ~]# mkdir /k8s/nginx #创建工作目录
[root@k8s-master ~]# cd /k8s/nginx/
[root@k8s-master nginx]# vim nginx-pv.yaml
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv-0
labels:
type: pv-0
spec:
capacity:
storage: 5Gi
accessModes:
- ReadWriteMany
persistentVolumeReclaimPolicy: Recycle
nfs:
server: 172.16.229.143
path: "/mnt/data-1"
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv-1
labels:
type: pv-1
spec:
capacity:
storage: 5Gi
accessModes:
- ReadWriteMany
persistentVolumeReclaimPolicy: Recycle
nfs:
server: 172.16.229.143
path: "/mnt/data-2"
2.创建pv
[root@k8s-master nginx]# kubectl apply -f nginx-pv.yaml
persistentvolume/nginx-pv created
[root@k8s-master nginx]# kubectl get pv
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
my-pv 3Gi RWX Recycle Bound default/mypvc pv-nfs 6d16h
pv-0 5Gi RWX Recycle Available 43s
pv-1 5Gi RWX Recycle Available 43s3.创建 service的Headless Service无头服务
[root@k8s-master nginx]# vim nginx-service.yaml
apiVersion: v1
kind: Service
metadata:
name: nginx #service的名字
labels:
app: nginx
spec:
ports:
- port: 80
name: web
clusterIP: None #采用什么类型的service,这里采用的是Headless Service
selector:
app: nginx
[root@k8s-master nginx]# kubectl apply -f nginx-service.yaml
service/nginx created
[root@k8s-master nginx]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 12d
nginx ClusterIP None <none> 80/TCP 5s4.创建StatefulSet,通过StatefulSet创建pvc实现自动绑定已经创建好的pv
[root@k8s-master nginx]# cat nginx-web.yaml
apiVersion: apps/v1 #选择apiserver的版本
kind: StatefulSet #定义pod类型
metadata:
name: nginx-web
spec:
serviceName: "nginx" #定义属于哪个Headless Service
replicas: 2 #定义pod的副本
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: daocloud.io/library/nginx
ports:
- containerPort: 80
name: web
volumeMounts: #定义卷的挂载到pod的路径
- name: nginx-data
mountPath: /usr/share/nginx/html
volumeClaimTemplates: #pvc的申请模版,会自动创建pvc并与pv绑定。从而实现各pod有专用存储(我们使用的是静态创建pv)
- metadata:
name: nginx-data #pvc的名字
spec:
accessModes: ["ReadWriteMany"]
resources:
requests:
storage: 5Gi #指定每一个持久卷的大小
[root@k8s-master nginx]# kubectl apply -f nginx-web.yaml查看statefulset
[root@k8s-master nginx]# kubectl get statefulset nginx-web
NAME READY AGE
nginx-web 2/2 19m查看service
[root@k8s-master nginx]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
nginx ClusterIP None <none> 80/TCP 18m
为什么需要volumeClaimTemplate?
对于有状态的副本集都会用到持久存储,对于分布式系统来讲,它的最大特点是数据是不一样的,所以各个节点不能使用同一存储卷,每个节点有自已的专用存储,但是如果在Deployment中的Pod template里定义的存储卷,是所有副本集共用一个存储卷,数据是相同的,因为是基于模板来的 ,而statefulset中每个Pod都要自已的专有存储卷,所以statefulset的存储卷就不能再用Pod模板来创建了,于是statefulSet使用volumeClaimTemplate,称为卷申请模板,它会为每个Pod生成不同的pvc,并绑定pv, 从而实现各pod有专用存储。这就是为什么要用volumeClaimTemplate的原因。
顺序创建 Pod
对于一个拥有 N 个副本的 StatefulSet,Pod 被部署时是按照 {0 …… N-1} 的序号顺序创建的。在终端中使用 kubectl get 检查输出。这个输出最终将看起来像下面的样子
[root@k8s-master nginx]# kubectl get -l app='nginx' pods
NAME READY STATUS RESTARTS AGE
nginx-web-0 1/1 Running 0 18m
nginx-web-1 1/1 Running 0 6m34s
请注意在 nginx-web-0 Pod 处于 Running和Ready 状态后 nginx-web-1 Pod 才会被启动
如同 StatefulSets 概念中所提到的,StatefulSet 中的 Pod 拥有一个具有黏性的、独一无二的身份标志。这个标志基于 StatefulSet 控制器分配给每个 Pod 的唯一顺序索引。Pod 的名称的形式为<statefulset name>-<ordinal index>。webStatefulSet 拥有两个副本,所以它创建了两个 Pod:nginx-web-0和nginx-web-1。
使用稳定的网络身份标识
每个 Pod 都拥有一个基于其顺序索引的稳定的主机名。使用[kubectl exec](https://kubernetes.io/zh/docs/reference/generated/kubectl/kubectl-commands/#exec)在每个 Pod 中执行hostname
[root@k8s-master nginx]# for i in 0 1; do kubectl exec nginx-web-$i -- /bin/bash -c 'hostname'; done
nginx-web-0
nginx-web-1
查看statefulset创建的pod的存储
获取 nginx-web-0 和 nginx-web-1 的 PersistentVolumeClaims。
[root@k8s-master nginx]# kubectl get pvc -l app='nginx'
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
nginx-data-nginx-web-0 Bound pv-0 5Gi RWX 53m
nginx-data-nginx-web-1 Bound pv-1 5Gi RWX 53m
StatefulSet 控制器创建了两个 PersistentVolumeClaims,绑定到两个 PersistentVolumes。由于这里我们使用的是手动创建pv,所有的 PersistentVolume 都是手动创建自动的绑定。
NGINX web 服务器默认会加载位于 /usr/share/nginx/html/index.html 的 index 文件。StatefulSets spec 中的 volumeMounts 字段保证了 /usr/share/nginx/html 文件夹由一个 PersistentVolume 支持。
将 Pod 的主机名写入它们的index.html文件并验证 NGINX web 服务器使用该主机名提供服务。
[root@k8s-master nginx]# kubectl exec -it nginx-web-0 /bin/bash
root@nginx-web-0:/# echo nginx-web-0 >> /usr/share/nginx/html/index.html
root@nginx-web-0:/# exit
exit
[root@k8s-master nginx]# kubectl exec -it nginx-web-1 /bin/bash
root@nginx-web-1:/# echo nginx-web-1 >> /usr/share/nginx/html/index.html
root@nginx-web-1:/# exit
exit
[root@k8s-master nginx]# kubectl get pods -l app='nginx' -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-web-0 1/1 Running 0 84m 10.244.2.24 k8s-node2 <none> <none>
nginx-web-1 1/1 Running 0 84m 10.244.1.26 k8s-node1 <none> <none>
[root@k8s-master nginx]# curl -s http://10.244.2.24
nginx-web-0
[root@k8s-master nginx]# curl -s http://10.244.1.26
nginx-web-1说明
请注意,如果你看见上面的 curl 命令返回了 403 Forbidden 的响应,你需要像这样修复使用 `volumeMounts`挂载的目录的权限:
# for i in 0 1; do kubectl exec web-$i -- chmod 755 /usr/share/nginx/html; done
#将StatefulSet创建的 所有 Pod删除
[root@k8s-master nginx]# kubectl delete -f nginx-web.yaml
statefulset.apps "nginx-web" deleted
#在使用StatefulSet重新创建的所有Pod
[root@k8s-master nginx]# kubectl apply -f nginx-web.yaml
statefulset.apps/nginx-web created
[root@k8s-master nginx]# kubectl get pods -l app='nginx' -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-web-0 1/1 Running 0 14s 10.244.2.25 k8s-node2 <none> <none>
nginx-web-1 1/1 Running 0 12s 10.244.1.27 k8s-node1 <none> <none>
#我们发现pod的IP地址发生了变化,接下来再次访问
[root@k8s-master nginx]# curl -s http://10.244.2.25
nginx-web-0
[root@k8s-master nginx]# curl -s http://10.244.1.27
nginx-web-1虽然 nginx-web-0 和 nginx-web-1 被重新调度了,但它们仍然继续监听各自的主机名,因为和它们的 PersistentVolumeClaim 相关联的 PersistentVolume 被重新挂载到了各自的 volumeMount 上。不管 nginx-web-0 和 nginx-web-1 被调度到了哪个节点上,它们的 PersistentVolumes 将会被挂载到合适的挂载点上。
扩容/缩容 StatefulSet
扩容/缩容 StatefulSet 指增加或减少它的副本数。这通过更新 replicas 字段完成.如果是手动创建的pv,那么需要提前将pv创建好了。
实战2-通过StatefulSet来管理有状态的服务msyql
[root@k8s-master ~]# mkdir /mnt/data-3
[root@k8s-master ~]# vim /etc/exports
/mnt/data-3 172.16.229.*/24 (rw,sync,insecure,no_subtree_check,no_root_squash)
[root@k8s-master ~]# systemctl restart nfs
[root@k8s-master ~]# mkdir /k8s/application/mysql
[root@k8s-master mysql]# cat mysql.pv.yaml
apiVersion: v1
kind: PersistentVolume
metadata:
name: mysql-pv
labels:
type: mysql-pv
spec:
capacity:
storage: 5Gi
accessModes:
- ReadWriteMany
persistentVolumeReclaimPolicy: Recycle
nfs:
server: 172.16.229.143
path: "/mnt/data-3"
[root@k8s-master mysql]# cat mysql-svc.yaml
apiVersion: v1
kind: Service
metadata:
name: mysql
labels:
app: mysql
spec:
ports:
- port: 3306
name: mysql
clusterIP: None
selector:
app: mysql
[root@k8s-master mysql]# cat mysql-server.yaml
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: mysql
spec:
serviceName: "mysql"
replicas: 1
selector:
matchLabels:
app: mysql
template:
metadata:
labels:
app: mysql
spec:
containers:
- name: mysql
image: daocloud.io/library/mysql:5.7
ports:
- containerPort: 3306
env:
- name: MYSQL_ROOT_PASSWORD
value: "Qfedu@123"
volumeMounts:
- name: mysql-data
mountPath: /var/lib/mysql
volumeClaimTemplates:
- metadata:
name: mysql-data
spec:
accessModes: ["ReadWriteMany"]
resources:
requests:
storage: 5Gi
[root@k8s-master mysql]# kubectl apply -f mysql.pv.yaml
persistentvolume/mysql-pv created
[root@k8s-master mysql]# kubectl apply -f mysql-svc.yaml
service/mysql created
[root@k8s-master mysql]# kubectl apply -f mysql-server.yaml
statefulset.apps/mysql created
[root@k8s-master mysql]# kubectl get pv | grep mysql
mysql-pv 5Gi RWX Recycle Bound default/mysql-data-mysql-0 7m28s
[root@k8s-master mysql]# kubectl get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
mysql-data-mysql-0 Bound mysql-pv 5Gi RWX 7m16s
[root@k8s-master mysql]# kubectl get pods -l app='mysql' -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
mysql-0 1/1 Running 0 6m22s 10.244.1.28 k8s-node1 <none> <none>
[root@k8s-master mysql]# kubectl exec -it mysql-0 /bin/bash
root@mysql-0:/# mysql -uroot -p'Qfedu@123'
mysql: [Warning] Using a password on the command line interface can be insecure.
Welcome to the MySQL monitor. Commands end with ; or \g.
...
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| sys |
+--------------------+
4 rows in set (0.01 sec)
mysql> create database test1;
Query OK, 1 row affected (0.00 sec)
mysql> exit
Bye
root@mysql-0:/# exit
exit
[root@k8s-master mysql]# cd /mnt/data-3/
[root@k8s-master data-3]# ll
总用量 188484
-rw-r----- 1 polkitd ssh_keys 56 11月 15 16:24 auto.cnf
-rw------- 1 polkitd ssh_keys 1676 11月 15 16:24 ca-key.pem
-rw-r--r-- 1 polkitd ssh_keys 1112 11月 15 16:24 ca.pem
-rw-r--r-- 1 polkitd ssh_keys 1112 11月 15 16:24 client-cert.pem
-rw------- 1 polkitd ssh_keys 1680 11月 15 16:24 client-key.pem
-rw-r----- 1 polkitd ssh_keys 1353 11月 15 16:25 ib_buffer_pool
-rw-r----- 1 polkitd ssh_keys 79691776 11月 15 16:25 ibdata1
-rw-r----- 1 polkitd ssh_keys 50331648 11月 15 16:25 ib_logfile0
-rw-r----- 1 polkitd ssh_keys 50331648 11月 15 16:24 ib_logfile1
-rw-r----- 1 polkitd ssh_keys 12582912 11月 15 16:25 ibtmp1
drwxr-x--- 2 polkitd ssh_keys 4096 11月 15 16:25 mysql
drwxr-x--- 2 polkitd ssh_keys 8192 11月 15 16:25 performance_schema
-rw------- 1 polkitd ssh_keys 1680 11月 15 16:24 private_key.pem
-rw-r--r-- 1 polkitd ssh_keys 452 11月 15 16:24 public_key.pem
-rw-r--r-- 1 polkitd ssh_keys 1112 11月 15 16:24 server-cert.pem
-rw------- 1 polkitd ssh_keys 1680 11月 15 16:24 server-key.pem
drwxr-x--- 2 polkitd ssh_keys 8192 11月 15 16:25 sys
drwxr-x--- 2 polkitd ssh_keys 20 11月 15 16:29 test1
[root@k8s-master mysql]# kubectl delete -f mysql-server.yaml
statefulset.apps "mysql" deleted
[root@k8s-master mysql]# cd /mnt/data-3/
[root@k8s-master data-3]# ll
总用量 176196
-rw-r----- 1 polkitd ssh_keys 56 11月 15 16:24 auto.cnf
-rw------- 1 polkitd ssh_keys 1676 11月 15 16:24 ca-key.pem
-rw-r--r-- 1 polkitd ssh_keys 1112 11月 15 16:24 ca.pem
-rw-r--r-- 1 polkitd ssh_keys 1112 11月 15 16:24 client-cert.pem
-rw------- 1 polkitd ssh_keys 1680 11月 15 16:24 client-key.pem
-rw-r----- 1 polkitd ssh_keys 688 11月 15 16:32 ib_buffer_pool
-rw-r----- 1 polkitd ssh_keys 79691776 11月 15 16:32 ibdata1
-rw-r----- 1 polkitd ssh_keys 50331648 11月 15 16:32 ib_logfile0
-rw-r----- 1 polkitd ssh_keys 50331648 11月 15 16:24 ib_logfile1
drwxr-x--- 2 polkitd ssh_keys 4096 11月 15 16:25 mysql
drwxr-x--- 2 polkitd ssh_keys 8192 11月 15 16:25 performance_schema
-rw------- 1 polkitd ssh_keys 1680 11月 15 16:24 private_key.pem
-rw-r--r-- 1 polkitd ssh_keys 452 11月 15 16:24 public_key.pem
-rw-r--r-- 1 polkitd ssh_keys 1112 11月 15 16:24 server-cert.pem
-rw------- 1 polkitd ssh_keys 1680 11月 15 16:24 server-key.pem
drwxr-x--- 2 polkitd ssh_keys 8192 11月 15 16:25 sys
drwxr-x--- 2 polkitd ssh_keys 20 11月 15 16:29 test1
[root@k8s-master data-3]# cd -
/k8s/application/mysql
[root@k8s-master mysql]# kubectl apply -f mysql-server.yaml
statefulset.apps/mysql created
[root@k8s-master mysql]# kubectl exec -it mysql-0 /bin/bash
root@mysql-0:/# mysql -uroot -p'Qfedu@123'
...
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| sys |
| test1 |
+--------------------+
5 rows in set (0.01 sec)
mysql>k8s中无状态服务和有状态服务部署的区别?
#**无状态**:
1. pod命名:pod名由资源名+随机的字符串组成;
2. 数据存储:多个实例pod可以共享相同的持久化数据,存储不是必要条件;
3. 扩缩容:可以随意扩缩容某个pod,不会指定某个pod进行扩缩容;
4. 启停顺序:因为pod名的序号是随机串,无启停顺序之分;
5. 无状态k8s资源:ReplicaSet、ReplicationController、Deployment、DaemonSet、Job等资源;
6. 无状态服务:tomcat、nginx等;#**有状态**
#这里假设有N个pod;
1. pod命名:pod名由statefulset资源名+有序的数字组成(0,1,2...N-1),且pod有特定的网络标识;
2. 数据存储:有状态的服务对应实例需要有自己的独立持久卷存储;
3. 扩缩容:扩缩容不可随意,缩容是从数字最大的开始递减,扩容是在原有pod序号基础上递增1。
4. 启停顺序:pod启停是有顺序的,启动时,先启动pod序号为0的,然后依次递增至N-1;停止时,先停止pod序号为最大的N-1,然后依次递减至0;
5. 有状态k8s资源:StatefulSet资源;
6. 有状态服务:Kafka、ZooKeeper、MySql、MongoDB以及一些需要保存日志的应用等服务;














 1126
1126











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









