






首先以一张思维导图从全局上给大家分享以下几种SQL优化策略,再详细讲解
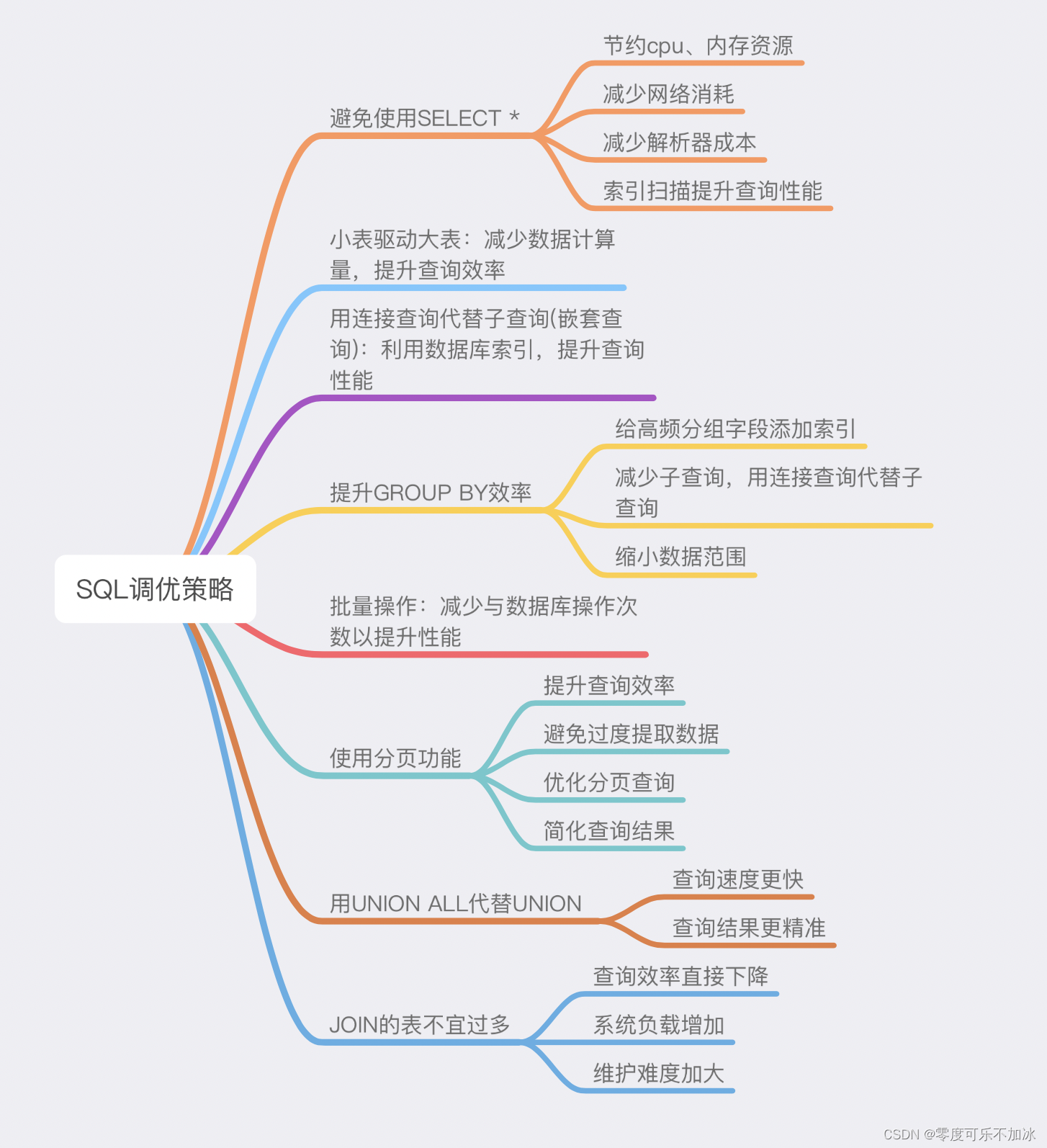
1、避免使用SELECT *
在阿里的编码规范中也强制了数据库查询不能使用SELECT *,因为SELECT *方式走的都是全表扫描,导致的结果就是查询效率非常低下,其原因为当我们使用SELECT *方式时,SQL会有一个格式化的阶段,这个阶段会将所有表字段都取出(将*号解析成表的各个字段),增加了查询解析器的成本
2、小表驱动大表
小表驱动大表指的是使用数据量较小,索引比较完备的表,然后使用它的索引和条件对大表的数据进行关联和筛选,从而减少数据的计算量,提升查询效率
例如当下我又两张表,分别为学生表(有45条数据),分数表(有1000条数据),它们需要进行关联查询,我们可能会用到LEFT JOIN或者RIGHT JOIN ,在FROM我们跟的表一般为主表,此时如果我们的SQL语句为
“……FROM student LEFT JOIN score……”
就叫做小表驱动大表;反之就是大表驱动小表,因为它需要将分数表中的1000条数据都查出来之后在去一一关联学生表
3、用连接查询代替子查询
在MySQL进行两张或两张以上的表进行联查时,可以使用连接查询和嵌套查询,尽可能减少嵌套查询的次数,其原因为:
①嵌套查询需要执行两次数据库查询,一次是外部查询,一次是嵌套子查询,而是用连接查询可以减少数据库查询次数从而提升查询效率
②连接查询可以更好地用上数据库的索引,而嵌套查询通常需要扫描整个表,因此连接查询可以跟快的执行查询操作
当然以上说法也并不绝对,在嵌套查询中我们依旧可以通过合理的使用IN或EXIST关键字来提升查询效率(遵循小表驱动大表原则)。
IN关键字通常应用在嵌套查询的嵌套条件前,例如“……FROM xxx WHERE xxx IN(嵌套SQL)”
如果sql语句中包含了IN关键字,则它会优先执行IN里面的子查询语句,然后再执行IN外面的语句。如果IN里面的数据量很少,作为条件查询速度更快。
EXISTS关键字也使用在嵌套查询条件前,例如
“……FROM xxx WHERE EXISTS (嵌套SQL语句)”
如果sql语句中包含了exists关键字,它优先执行exists左边的语句(即主查询语句)。然后把它作为条件,去跟右边的语句匹配。如果左侧SQL语句查询数据量较少,依旧能够提升查询效率。
4、提升GROUP BY的查询效率
如果没有为GROUP BY的字段设置索引,则查询可能会变得非常慢(这里面涉及到了一个B+树的概念,它会为我们有序的排序索引的数据),当为需要分组的字段建立索引后,数据就是有序的,这些有序的数据会排列在一起
5、使用批量插入
MySQL本身就支持批量插入数据,例如:
![]()
而在代码中通过持久层访问数据库插入数据时,我们也不建议一条一条或者通过循环的形式插入,因为每次调用循环里的插入方法 相当于都要和数据库进行一次;宜采取的方式是将数据封装在一个集合中,通过集合一次性插入数据,例如:

6、当一次查询数据量过多时,一定要使用LIMIT进行分页
一个查询返回成干上万的数据行,不仅占用了大量的系统资源,也会占用更多的网络带宽,影响查询效率也有可能造成内存溢出。使用LIMIT可以限制返回的数据行数,减轻了系统负担,提高了查询效率。使用LIMIT可以达到以下结果:
- 避免过度提取数据:对于大型数据库系统,从数据库中提取大量的数据可能会导致系统崩溃。使用LIMIT可以限制提取的数据量,避免过度提取数据,保护系统不受影响。
- 优化分页查询:分页查询需要查询所有的数据才能进行分页处理,这会浪费大量的系统资源和时间。使用LIMIT优化分页查询可以只章询需要的数据行,缩短查询时间,减少资源的浪费。
- 简化查询结果:有时我们只需要一小部分数据来得出决策,而不是整个数据集。使用LIMIT可以使结果集更加精简和易于阅读和理解。
- 限制行数非常有用,因为它可以提高查询性能、减少处理需要的时间,并且只返回我们关心的列
7、需要合并数据时尽可能使用UNION ALL而非UNION
UNION ALL和UNION通常在数据合并中使用,例如:
“(SELECT * FROM user WHERE id=1) UNION (SELECT * FROM user WHERE id=2)”
SQL语句使用UNION关键字后,可以获取去重后的数据,而如果使用UNION ALL关键字,可以获取所有数据,包含重复的数据。在业务允许出现重复数据的情况下,我们更推荐使用UNION ALL,因为UNION去重需要经过数据的遍历、排序和比较,计算无疑是更耗费性能和CPU资源的。
除非是有些特殊的场景,比如UNION ALL之后,结果集中出现了重复数据,而业务场景中是不允许产生重复数据的,这时可以使用UNION;或者在UNION前利用索引提升查询效率
8、尽可能减少表关联的次数(减少JOIN的使用)
对于这个优化策略,我的理解是,减少JOIN的次数并非减少必要使用次数,JOIN终究在查询效率上还是远高于IN的,这个减少的含义应该是减少表的冗余关联字段来减少表的链接(即需要找到多表能够进行关联的最少字段,用最少的字段进行关联)。
减少JOIN的使用次数更多的原因还是在SQL语句的编写上,很容易造成关联错误。
以上就是关于SQL调优的策略介绍,总结来说,SQL调优的原则就是减少数据扫描、减少与数据库反复的交互次数、减少内存开销,而大部分的优化策略都是在索引的基础上是实现的。
———————————————————————————————————————————
路漫漫其修远兮,吾将上下而求索~
到此关于SQL调优策略的讲解算告一段落了,写作不易,如果你认为博主写的不错!
请点赞、关注、评论给博主一个鼓励吧,您的鼓励就是博主前进的动力。
















 243
243











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











