






目录
1.整体架构
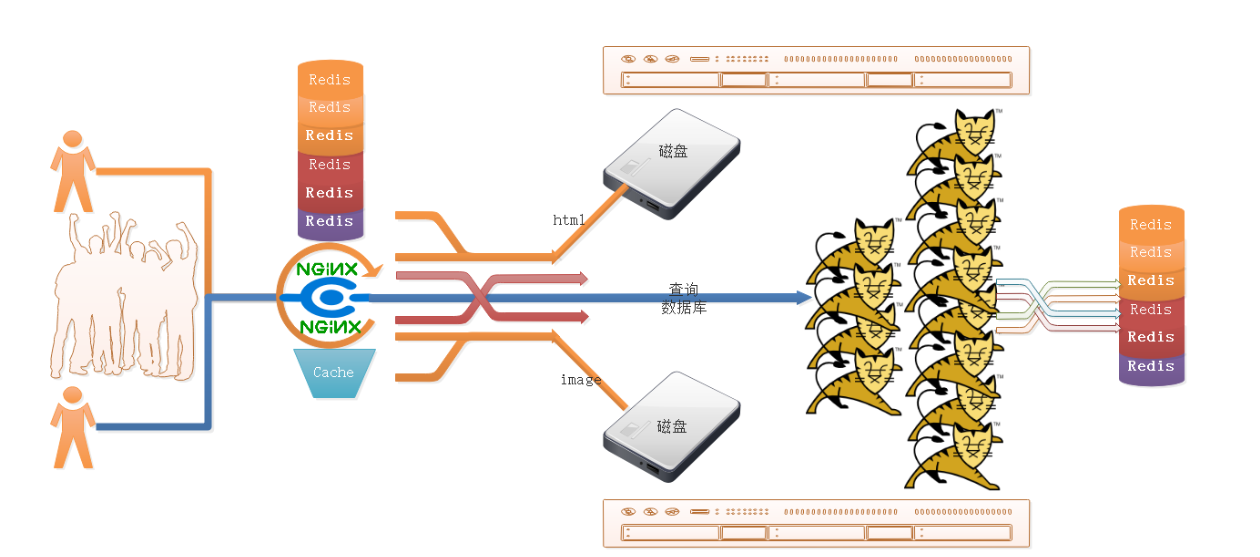
三级缓存框架图(redis,nginx,mysql)
在大并发场景下,通过引入缓存机制,减轻后端Tomcat服务的压力,避免因请求过多导致Tomcat宕机,同时提高系统的整体响应速度和性能。优化流程如下:
-
请求到达Nginx Nginx作为代理层,具有极强的抗压能力,能够承载大量的并发请求。
-
缓存策略实施
-
第一道缓存:Redis缓存
-
请求到达Nginx后,首先查询Redis缓存。
-
如果Redis中存在缓存数据,则直接返回缓存数据给用户,无需再进行后续处理。
-
-
第二道缓存:Nginx缓存
-
如果Redis中没有缓存数据,则查询Nginx自身的缓存。
-
如果Nginx缓存中有数据,也直接返回给用户。
-
-
请求路由到Tomcat
-
如果Redis和Nginx缓存中都没有数据,则将请求路由到后端的Tomcat服务。
-
-
-
Tomcat处理与缓存更新
-
Tomcat接收到请求后,从数据库中加载数据。
-
加载完成后,将数据存入Redis缓存(以便后续请求可以直接从Redis获取)。
-
同时,响应数据给用户。
-
-
后续请求处理
-
当用户再次发起相同查询请求时,会优先查询Redis缓存。
-
如果Redis缓存中存在数据,直接返回,避免再次访问Tomcat。
-
如果Redis缓存失效或不存在,再按照上述流程查询Nginx缓存或路由到Tomcat。
-
-
最终效果
-
通过Redis和Nginx的双重缓存机制,大幅减少了后端Tomcat服务被调用的次数,降低了Tomcat的负载。
-
提高了系统的整体性能和响应速度,增强了系统的稳定性和可靠性。
-
关键点
-
缓存优先级:优先使用Redis缓存,因为Redis的性能更高,适合存储热点数据。Nginx缓存作为补充,用于进一步减轻后端压力。
-
缓存更新:Tomcat加载数据后及时更新Redis缓存,确保缓存数据的时效性和准确性。
-
缓存失效策略:需要合理设置Redis和Nginx缓存的失效时间,以平衡缓存命中率和数据新鲜度。
上面这套缓存架构被多个大厂应用,除了可以有效提高加载速度、降低后端服务负载之外,还可以防止缓存雪崩,为服务稳定健康打下了坚实的基础,这也就是鼎鼎有名的多级缓存架构体系。
现在来思考以下问题:
1.如何实现多级缓存?
2.如何优化redis缓存?
3.nginx如何读取缓存的数据?
4.redis如何和数据库保持同步?
3.安装环境
1.1 使用docket安装redis
docker直接拉取rides
[root@localhost ~]# docker pull redis:7.0.5
配置容器以及说明
docker run -p 6379:6379 --name redis --restart=always \
-v /usr/local/redis/redis.conf:/etc/redis/redis.conf \
-v /usr/local/redis/data:/data \
-d redis:7.0.5 redis-server /etc/redis/redis.conf \
--appendonly yes --requirepass 123456
参数说明:
-restart=always 总是开机启动
-p 宿主机端口和容器端口映射
-v 挂载数据卷
-d 后台启动redis
- -appendonly yes 开启持久化
--requirepass 123456 设置密码查看是否启动成功
[root@localhost ~]# docker ps

1.2 配置redis缓存链接:
修改bootstrap.yml,增加配置Redis缓存链接,如下:
# Redis配置
redis:
host: 192.168.31.135 #换成自己虚拟机的ip
port: 6379
password:1234561.3 使用redisTemplate实现
引入 RedisTemplate 来进行缓存的读取和写入操作,将确保在查询数据库之前先尝试从 Redis 中获取数据,并在获取到数据库结果后将其存储到 Redis 中。
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.stereotype.Service;
import java.util.List;
import java.util.concurrent.TimeUnit;
import java.util.stream.Collectors;
@Service
public class SkuService {
@Autowired
private RedisTemplate<String, Object> redisTemplate;
@Autowired
private AdItemsMapper adItemsMapper;
@Autowired
private SkuMapper skuMapper;
private static final String CACHE_NAME = "ad-items-skus";
// 方法参数类型应与缓存键的类型一致,这里假设id是String类型的,如果不是,请调整
public List<Sku> typeSkuItems(String id) {
// 尝试从Redis中获取缓存数据
List<Sku> skus = (List<Sku>) redisTemplate.opsForValue().get(CACHE_NAME + ":" + id);
if (skus == null) {
System.out.println("查询数据库!!!");
// 如果Redis中没有缓存的数据,则查询数据库
QueryWrapper<AdItems> adItemsQueryWrapper = new QueryWrapper<AdItems>();
adItemsQueryWrapper.eq("type", Integer.parseInt(id));
List<AdItems> adItems = this.adItemsMapper.selectList(adItemsQueryWrapper);
// 获取所有SkuId
List<String> skuIds = adItems.stream().map(adItem -> adItem.getSkuId()).collect(Collectors.toList());
// 批量查询Sku
skus = skuMapper.selectBatchIds(skuIds);
// 将查询结果存入Redis,并设置过期时间(例如1小时)
//redisTemplate.opsForValue().set(CACHE_NAME + ":" + id, skus, 1, TimeUnit.HOURS);
// 设置永不过期
redisTemplate.opsForValue().set(CACHE_NAME + ":" + id, skus);
}
return skus;
}
}思考:
redisTemplate虽然可以实现,但是代码耦合性高,如何简化并实现相同效果??
1.4 缓存注解优化
1.4.1 常用缓存注解简绍
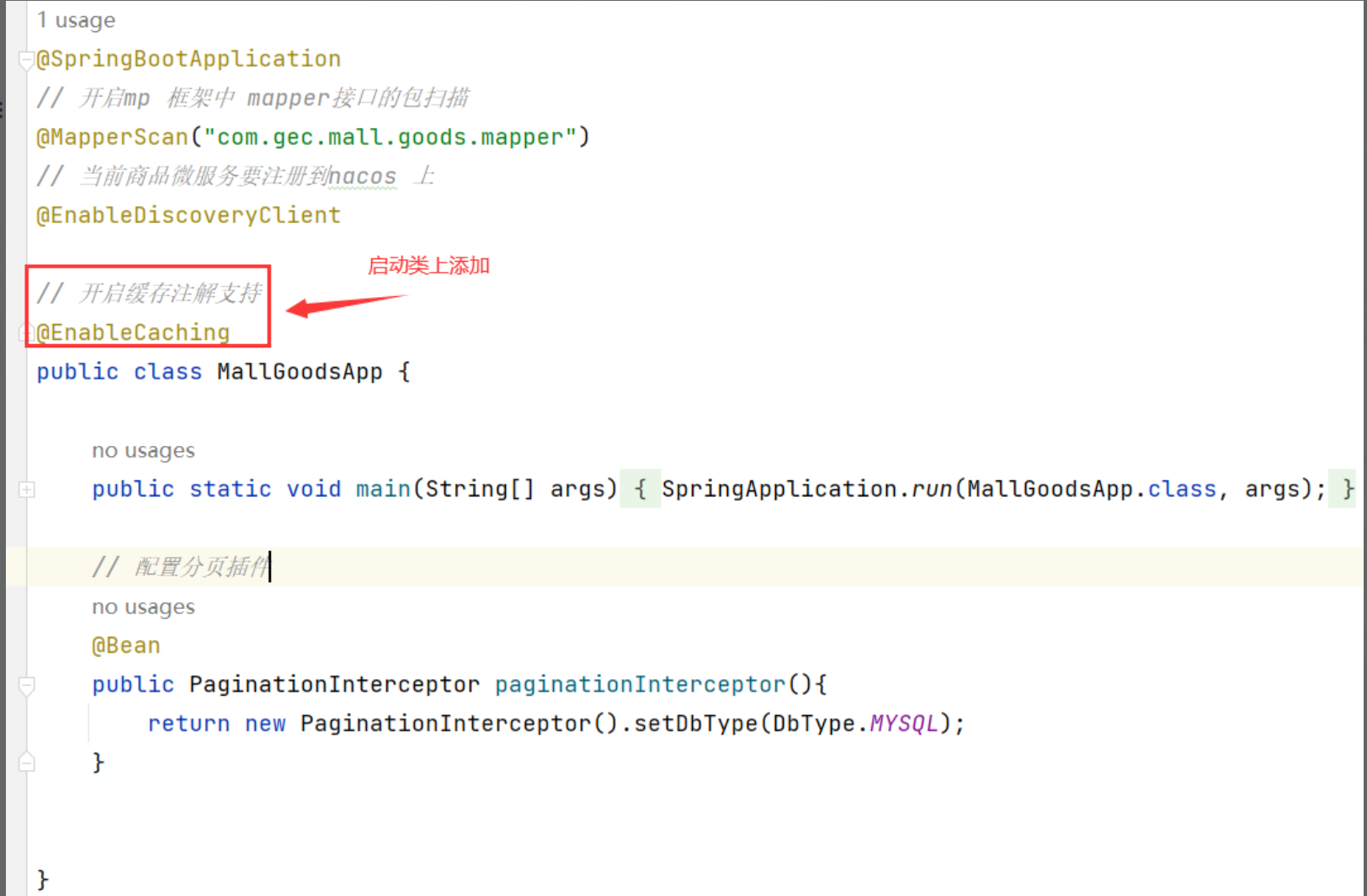
@EnableCaching: 开关性注解,在项目启动类或某个配置类上使用此注解后,则表示允许使用注解的方式进行缓存操作。
@Cacheable: 会判断缓存是否存在,可用于类或方法上;在目标方法执行前,会根据key先去缓存中查询看是否有数据,有就直接返回缓存中的key对应的value值。不再执行目标方法;无则执行目标方法,并将方法的返回值作为value,并以键值对的形式存入缓存。
@CacheEvict: 删除缓存,可用于类或方法上;在执行完目标方法后,清除缓存中对应key的数据(如果缓存中有对应key的数据缓存的话)。
@CachePut: 不会判断缓存是否存在,可用于类或方法上;在执行完目标方法后,并将方法的返回值作为value,并以键值对的形式存入缓存中。
@Caching: 三合一,此注解即可作为@Cacheable、@CacheEvict、@CachePut三种注解中的的任何一种或几种来使用。
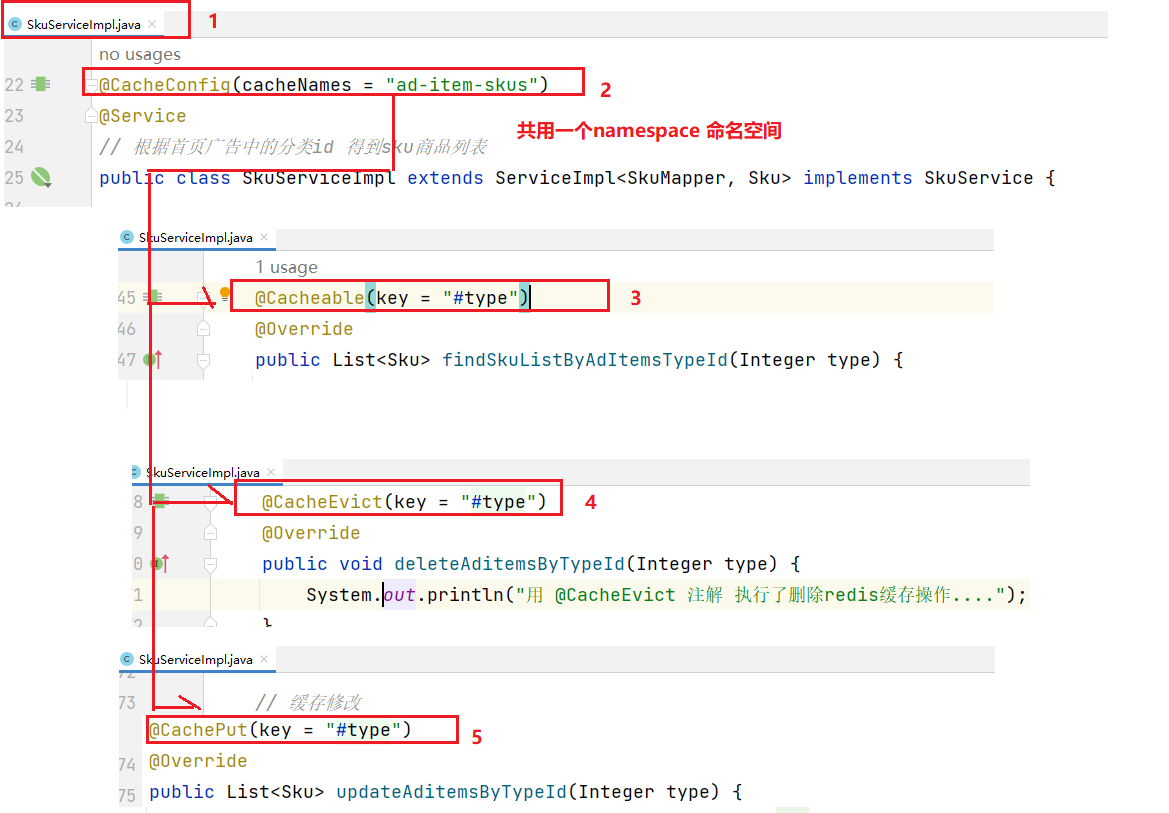
@CacheConfig: 可以用于配置@Cacheable、@CacheEvict、@CachePut这三个注解的一些公共属性,例如cacheNames、keyGenerator。
1.4.2 @EnableCaching注解的使用
1.4.3使用@Cacheable
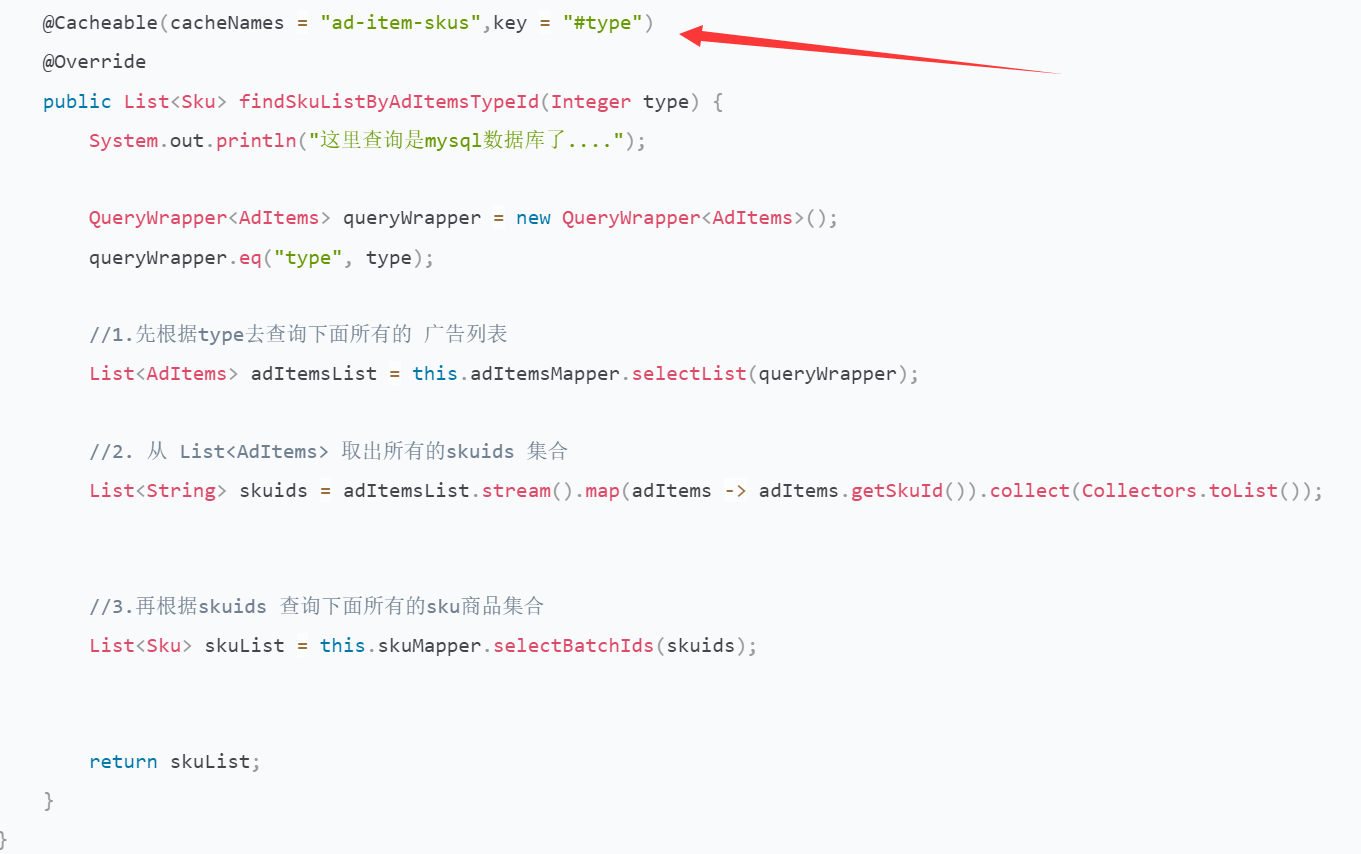
测试
第一次查询:

第二次测试:

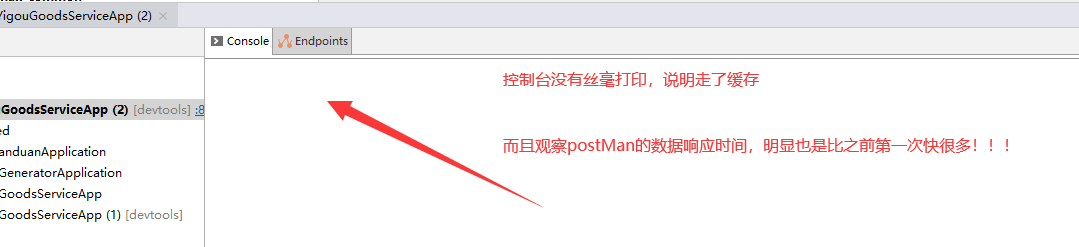
使用缓存注解存储数据到redis缓存中,key的过期时间是多久呢?
答案是:-1 永不过期!
注意:
对应的实体类要进行序列化 implements Serializeable,否则会报错!
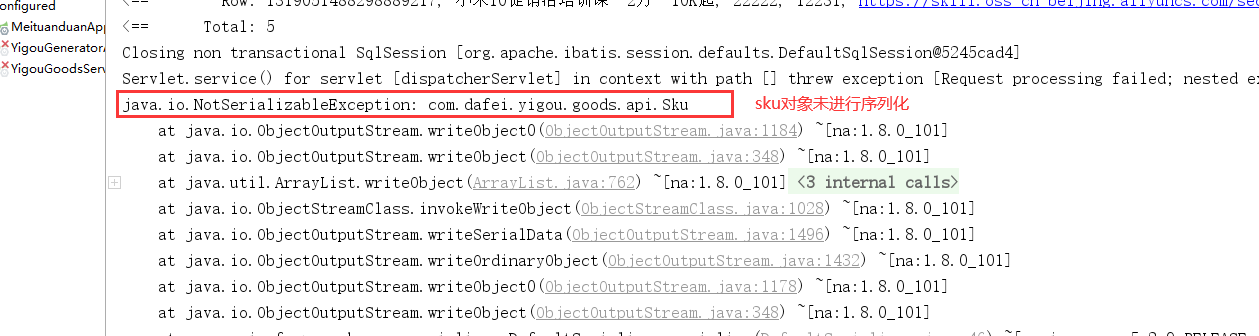
实体类序列化:
1.4.4@CachePut注解的使用

测试:
第一次
观察控制台,会发现它是查了数据库

redis中也存了缓存

第二次
观察控制台,会发现它仍然是查了数据库

redis中也存了缓存

第三次
观察控制台,会发现它还是走数据库查询

redis中也存了缓存

经过连续测试三次,会发现 CachePut 注解,就是将数据放进redis缓存中,并不存在判断缓存操作!!!
1.4.5 优化
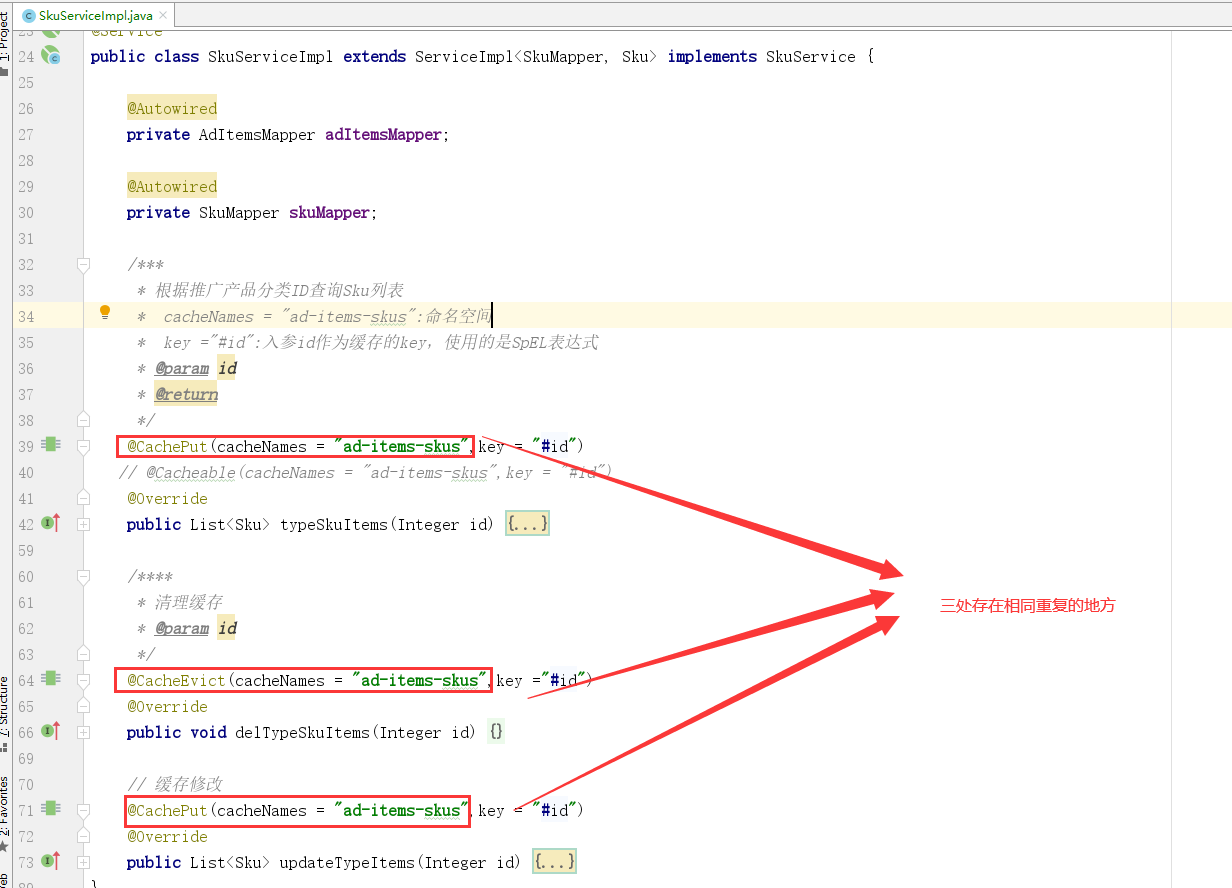
2.安装Nginx
多级缓存架构图思路:
首先用户请求先进入到Nginx ,Nginx拦截后,先找redis是否有缓存,如果redis 有数据,就直接响应给用户。如果redis缓存无数据,就会去查询nginx缓存数据。
2.1 安装OpenRest使用Nginx
OpenResty 是一个基于 Nginx 与 Lua 的高性能 Web 平台,其内部集成了大量精良的 Lua 库、第三方模块以及大多数的依赖项。用于方便地搭建能够处理超高并发、扩展性极高的动态 Web 应用、Web 服务和动态网关。OpenResty® 通过汇聚各种设计精良的 Nginx 模块(主要由 OpenResty 团队自主开发),从而将 Nginx 有效地变成一个强大的通用 Web 应用平台。这样,Web 开发人员和系统工程师可以使用 Lua 脚本语言调动 Nginx 支持的各种 C 以及 Lua 模块,快速构造出足以胜任 10K 乃至 1000K 以上单机并发连接的高性能 Web 应用系统。OpenResty® 的目标是让你的Web服务直接跑在 Nginx 服务内部,充分利用 Nginx 的非阻塞 I/O 模型,不仅仅对 HTTP 客户端请求,甚至于对远程后端诸如 MySQL、PostgreSQL、Memcached 以及 Redis 等都进行一致的高性能响应。
Nginx并发能力强 、稳定、消耗资源小
Lua:所有脚本语言中最强的
安装
进行安装包:
#进入安装包
cd openresty-1.11.2.5
#安装
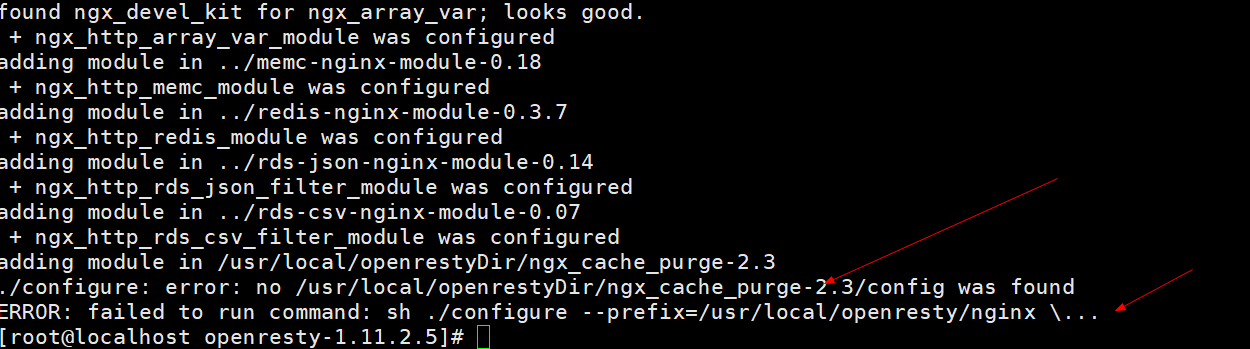
[root@localhost openresty-1.11.2.5]# ./configure --prefix=/usr/local/openresty --with-luajit --without-http_redis2_module --with-http_stub_status_module --with-http_v2_module --with-http_gzip_static_module --with-http_sub_module --add-module=/usr/local/openrestyDir/ngx_cache_purge-2.3/
参数说明:
--prefix=/usr/local/openresty:安装路径
--with-luajit:安装luajit相关库,luajit是lua的一个高效版,LuaJIT的运行速度比标准Lua快数十倍。
--without-http_redis2_module:现在使用的Redis都是3.x以上版本,这里不推荐使用Redis2,表示不安装redis2支持的lua库
--with-http_stub_status_module:Http对应状态的库
--with-http_v2_module:对Http2的支持
--with-http_gzip_static_module:gzip服务端压缩支持
--with-http_sub_module:过滤器,可以通过将一个指定的字符串替换为另一个字符串来修改响应
--add-module=/usr/local/openrestyDir/ngx_cache_purge-2.3/:Nginx代理缓存清理工具会报错:
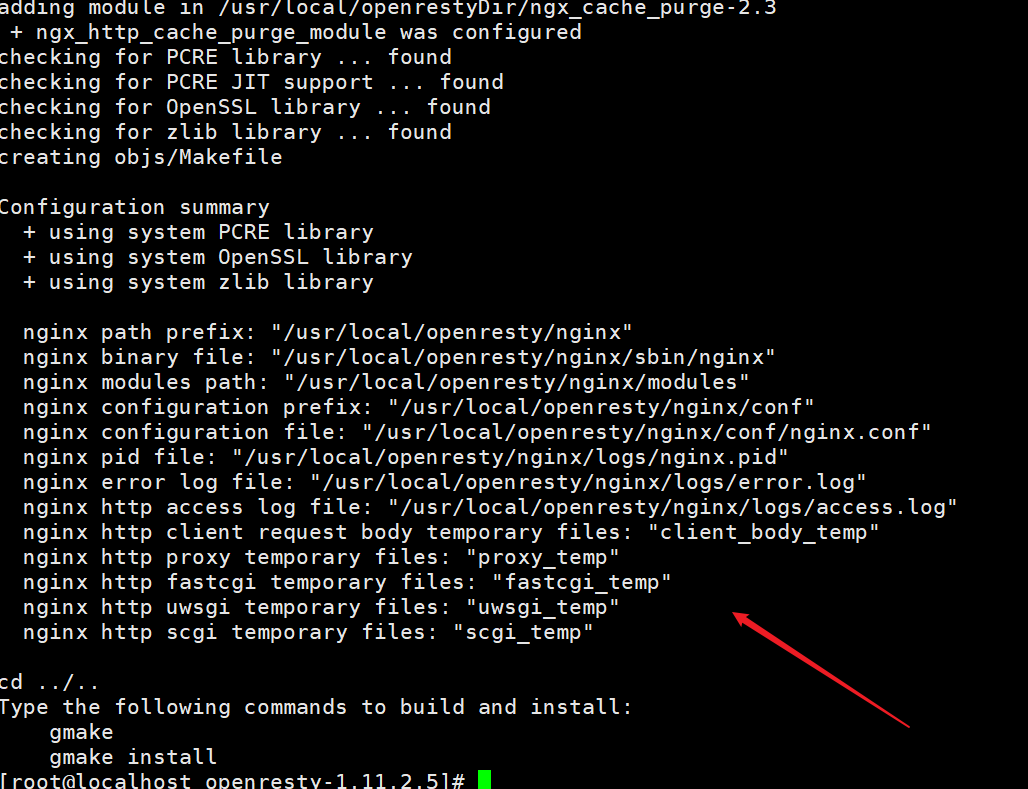
解决方案,安装Nginx代理缓存工具:
mkdir -p /usr/local/openrestyDir
cd /usr/local/openrestyDir
wget http://labs.frickle.com/files/ngx_cache_purge-2.3.tar.gz
tar -xvf ngx_cache_purge-2.3.tar.gz再次安装:
[root@localhost openresty-1.11.2.5]# ./configure --prefix=/usr/local/openresty --with-luajit --without-http_redis2_module --with-http_stub_status_module --with-http_v2_module --with-http_gzip_static_module --with-http_sub_module --add-module=/usr/local/openrestyDir/ngx_cache_purge-2.3/报错解决:
测试访问:
[root@localhost openresty-1.11.2.5]# cd /usr/local/openresty
[root@localhost openresty]# ll
总用量 240
drwxr-xr-x. 2 root root 123 8月 7 19:32 bin
-rw-r--r--. 1 root root 22924 8月 7 19:32 COPYRIGHT
drwxr-xr-x. 6 root root 56 8月 7 19:32 luajit
drwxr-xr-x. 6 root root 70 8月 7 19:32 lualib
drwxr-xr-x. 6 root root 54 8月 7 19:32 nginx
drwxr-xr-x. 43 root root 4096 8月 7 19:32 pod
-rw-r--r--. 1 root root 216208 8月 7 19:32 resty.index
drwxr-xr-x. 5 root root 47 8月 7 19:32 site
浏览器地址栏访问: http://192.168.31.134:80
注意: 检查自己linux服务器的 80 端口是否被放开?
或者 直接关闭了防火墙 也可以 !
2.2 Nginx实现动静分离站点架构
我们打开京东商城,搜索手机,查看网络可以发现响应页面后,页面又会发起很多请求,还没有查看多少信息就已经有393个请求发出了,而多数都是图片,一个人请求如此,人多了对后端造成的压力是非比寻常的,该如何降低静态资源对服务器的压力呢?
项目完成后,项目上线如果所有请求都经过Tomcat,并发量很大的时候,对项目而言将是灭顶之灾,电商项目中一个请求返回的页面往往会再次发起很多请求,而绝大多数都是图片或者是css样式、js等静态资源,如果这些静态资源都去查询Tomcat,Tomcat的压力会增加数十倍甚至更高。
这时候我们需要采用动静分离的策略:
1、所有静态资源,经过Nginx,Nginx直接从指定磁盘中获取文件,然后IO输出给用户
2、如果是需要查询数据库数据的请求,就路由到Tomcat集群中,让Tomcat处理,并将结果响应给用户例如我的门户代码放到front上,将front上传到/usr/local/shangpinmall/web/static目录下,再修改/usr/local/openresty/nginx/conf/nginx.conf,配置如下:
#门户发布
server {
listen 80;
server_name www.shangpinyungou.com;
location / {
root /usr/local/shangpinmall/web/static/frant;
}
}配置结束后一定要进行刷新:nginx -s reload
访问 www.shangpinyungou.com 效果如下:
2.2.1Nginx实现缓存
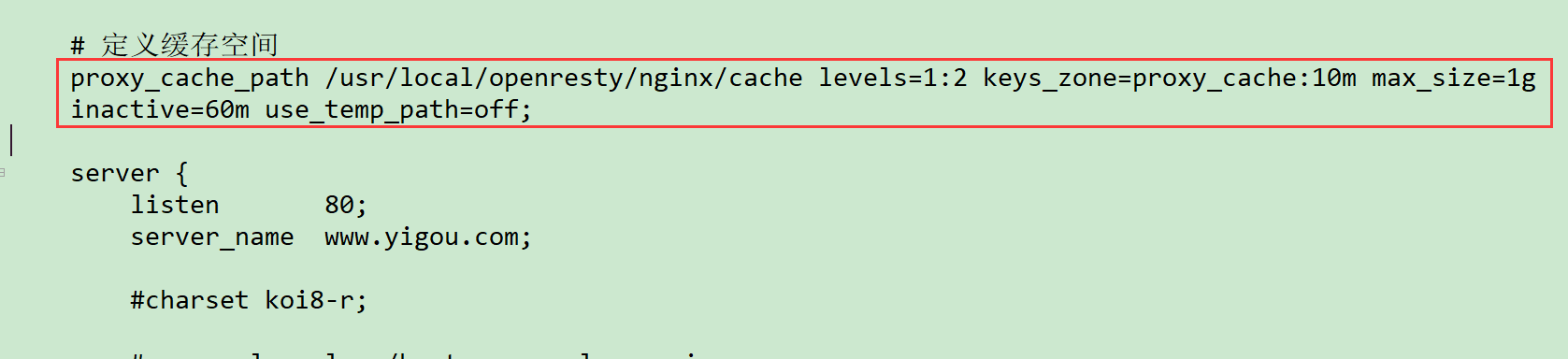
1)开启Proxy_Cache缓存:
我们需要在nginx.conf中配置才能开启缓存:
proxy_cache_path /usr/local/openresty/nginx/cache levels=1:2 keys_zone=proxy_cache:10m max_size=1g inactive=60m use_temp_path=off;
参数说明:
【proxy_cache_path】指定缓存存储的路径,缓存存储在/usr/local/openresty/nginx/cache目录 【levels=1:2】设置一个两级目录层次结构存储缓存,在单个目录中包含大量文件会降低文件访问速度,因此我们建议对大多数部署使用两级目录层次结构。 如果 levels 未包含该参数,Nginx 会将所有文件放在同一目录中。 keys_zone 缓存空间的名字 叫做: proxy_cache key是 10M 【keys_zone=proxy_cache:10m】设置共享内存区域,用于存储缓存键和元数据,例如使用计时器。拥有内存中的密钥副本,Nginx 可以快速确定请求是否是一个 HIT 或 MISS 不必转到磁盘,从而大大加快了检查速度。1 MB 区域可以存储大约 8,000 个密钥的数据,因此示例中配置的 10 MB 区域可以存储大约 80,000 个密钥的数据。 max_size 缓存数据的大小 【max_size=1g】设置缓存大小的上限。它是可选的; 不指定值允许缓存增长以使用所有可用磁盘空间。当缓存大小达到限制时,一个称为缓存管理器的进程将删除最近最少使用的缓存,将大小恢复到限制之下的文件。 // 表达一个缓存多久没去使用后,就会过期 【inactive=60m】指定项目在未被访问的情况下可以保留在缓存中的时间长度。在此示例中,缓存管理器进程会自动从缓存中删除 60 分钟未请求的文件,无论其是否已过期。默认值为 10 分钟(10m)。非活动内容与过期内容不同。Nginx 不会自动删除缓存 header 定义为已过期内容(例如 Cache-Control:max-age=120)。过期(陈旧)内容仅在指定时间内未被访问时被删除。访问过期内容时,Nginx 会从原始服务器刷新它并重置 inactive 计时器。 // 不使用临时目录 【use_temp_path=off】表示NGINX会将临时文件保存在缓存数据的同一目录中。这是为了避免在更新缓存时,磁盘之间互相复制响应数据,我们一般关闭该功能。
2)Proxy_Cache属性:
proxy_cache:设置是否开启对后端响应的缓存,如果开启的话,参数值就是zone的名称,比如:proxy_cache。
proxy_cache_valid:针对不同的response code设定不同的缓存时间,如果不设置code,默认为200,301,302,也可以用any指定所有code。
proxy_cache_min_uses:指定在多少次请求之后才缓存响应内容,这里表示将缓存内容写入到磁盘。
proxy_cache_lock:默认不开启,开启的话则每次只能有一个请求更新相同的缓存,其他请求要么等待缓存有数据要么限时等待锁释放;nginx 1.1.12才开始有。
配套着proxy_cache_lock_timeout一起使用。
proxy_cache_key:缓存文件的唯一key,可以根据它实现对缓存文件的清理操作。Nginx代理缓存热点数据应用
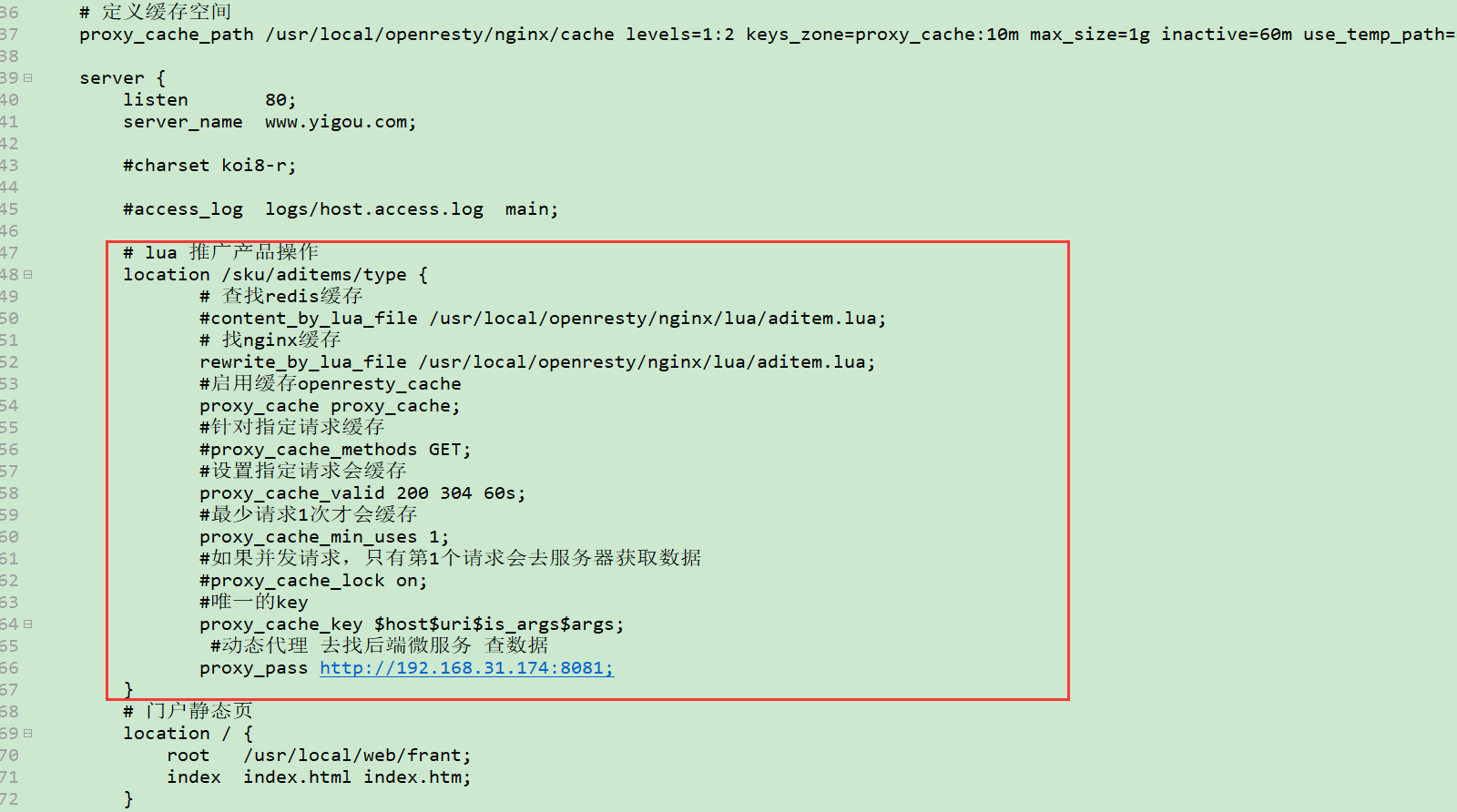
1)开启代理缓存
修改nginx.conf,添加如下配置:
proxy_cache_path /usr/local/openresty/nginx/cache levels=1:2 keys_zone=proxy_cache:10m max_size=1g inactive=60m use_temp_path=off;
修改nginx.conf,添加如下配置:
# lua 推广产品操作
location /sku/aditems/type {
# 查找redis缓存
#content_by_lua_file /usr/local/openresty/nginx/lua/aditem.lua;
# 找nginx缓存
rewrite_by_lua_file /usr/local/openresty/nginx/lua/aditem.lua;
#启用缓存openresty_cache
proxy_cache proxy_cache;
#针对指定请求缓存
#proxy_cache_methods GET;
#设置指定请求会缓存
proxy_cache_valid 200 304 60s;
#最少请求1次才会缓存
proxy_cache_min_uses 1;
#如果并发请求,只有第1个请求会去服务器获取数据
#proxy_cache_lock on;
#唯一的key
proxy_cache_key $host$uri$is_args$args;
#动态代理 去找后端微服务 查数据 这里的地址是填写你当前windows的ip地址服务器 (我们去看我们nacos中服务注册的ip就可以了)
proxy_pass http://192.168.18.1:8081;
}
# 门户静态页
location / {
root /usr/local/web/frant;
index index.html index.htm;
}重启nginx或者重新加载配置文件nginx -s reload,再次测试
进行测试,关闭运行的代码,只要不关闭虚拟机再次刷新我们发现数据仍然显示出来,说明缓存起到作用
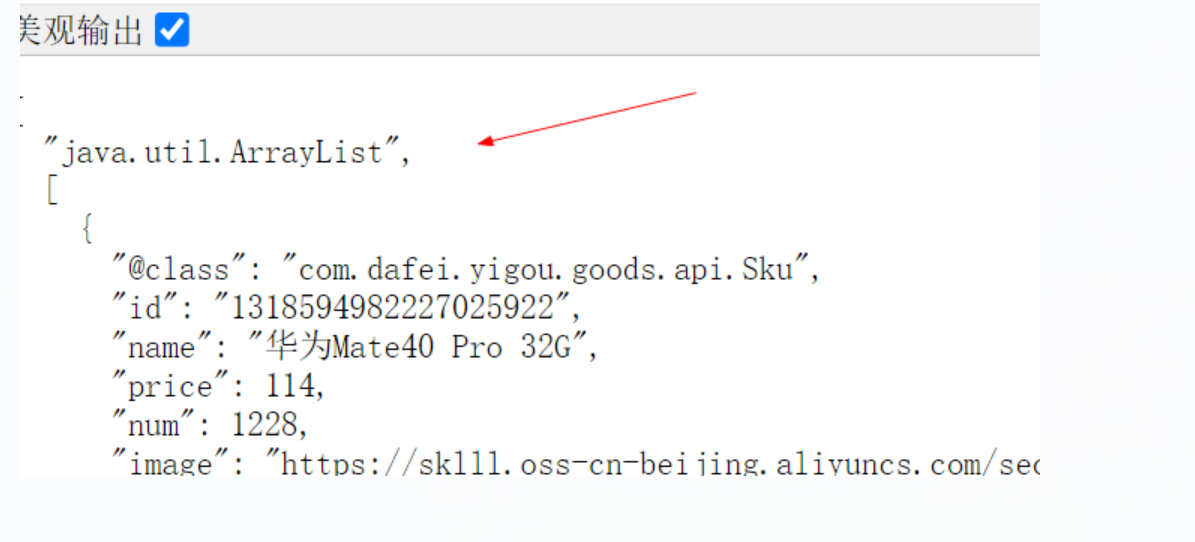
我们可以找一下nginx代理缓存的存储位置
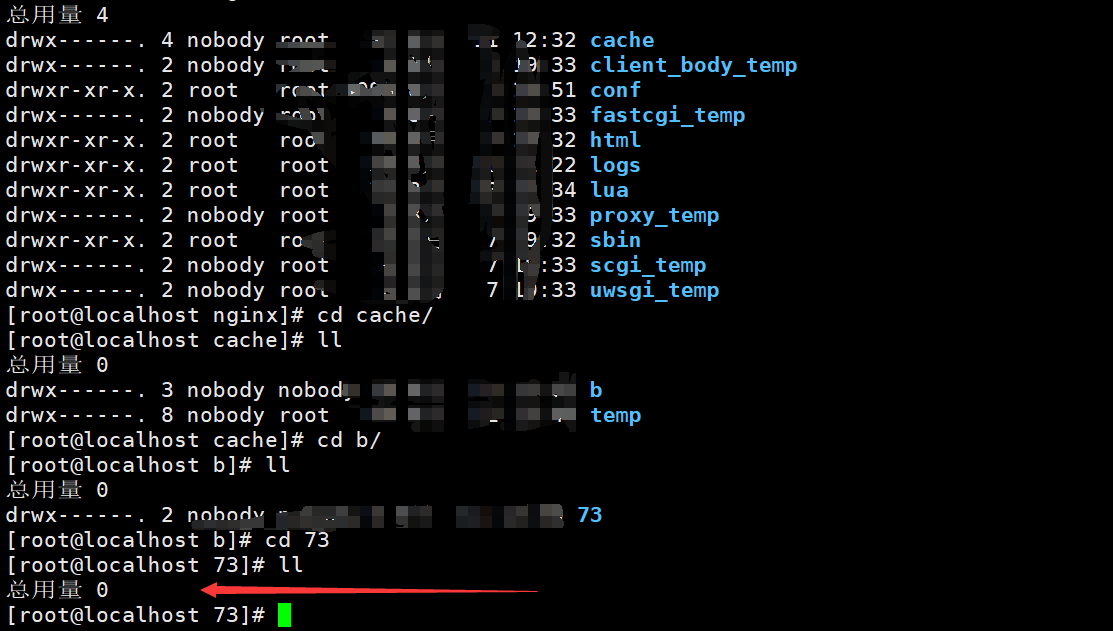
可以发现cache目录下多了目录和一个文件,这就是Nginx缓存:
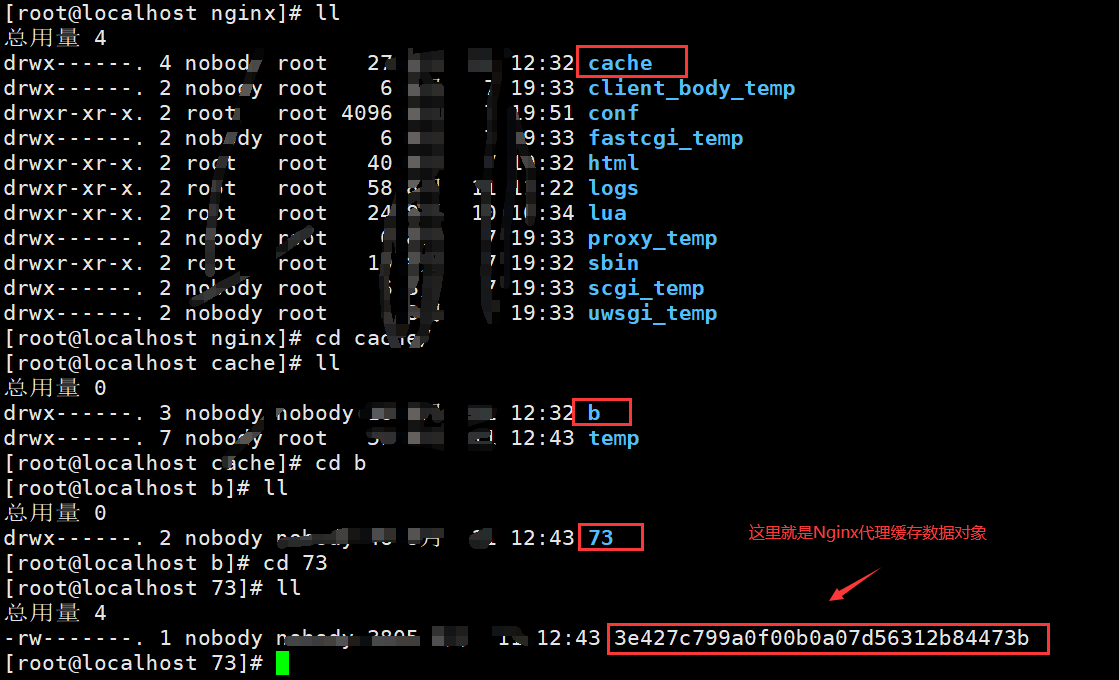
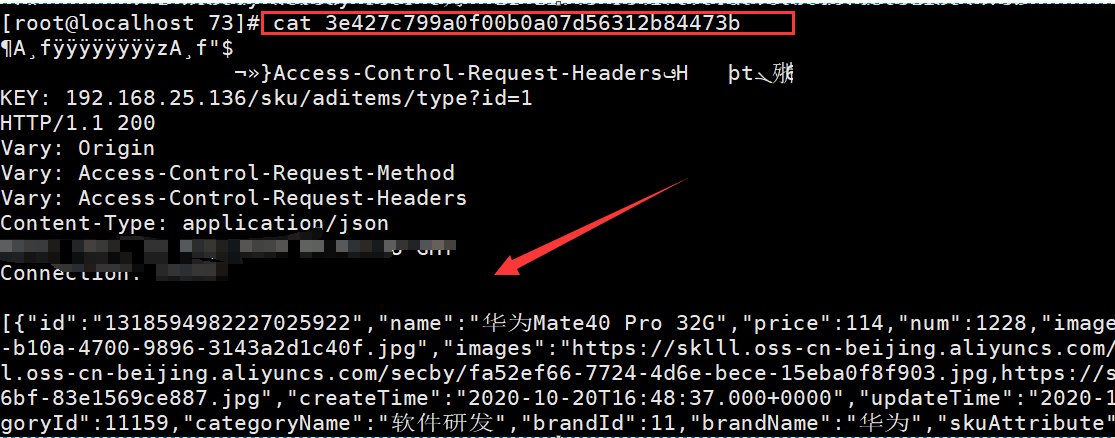
可以发现下面个规律:
1:先查找Redis缓存
2:Redis缓存没数据,直接找Nginx缓存
3:Nginx缓存没数据,则找真实服务器
2.2.2 Cache_Purge代理缓存清理
很多时候我们如果不想等待缓存的过期,想要主动清除缓存,可以采用第三方的缓存清除模块清除缓存 nginx_ngx_cache_purge。
安装nginx的时候,需要添加purge模块,purge模块我们已经下载了,在 /usr/local/openrestyDir 目录下,添加该模块 --add-module=/usr/local/openrestyDir/ngx_cache_purge-2.3/,这一个步骤我们在安装OpenRestry的时候已经实现了。
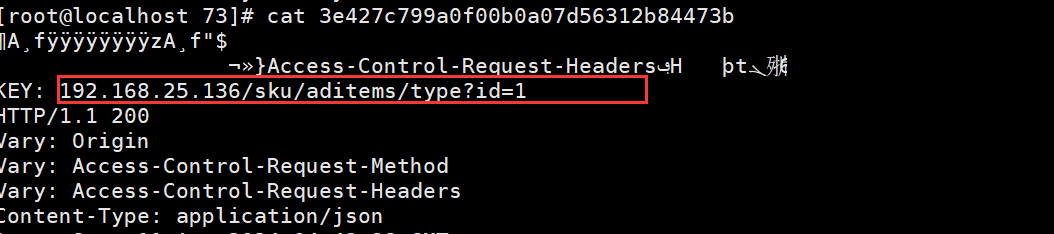
在实际部署中,你需要确保Nginx已经安装并启用了Purge模块。你可以通过运行nginx -V来检查是否已经启用了--with-http_purge_module
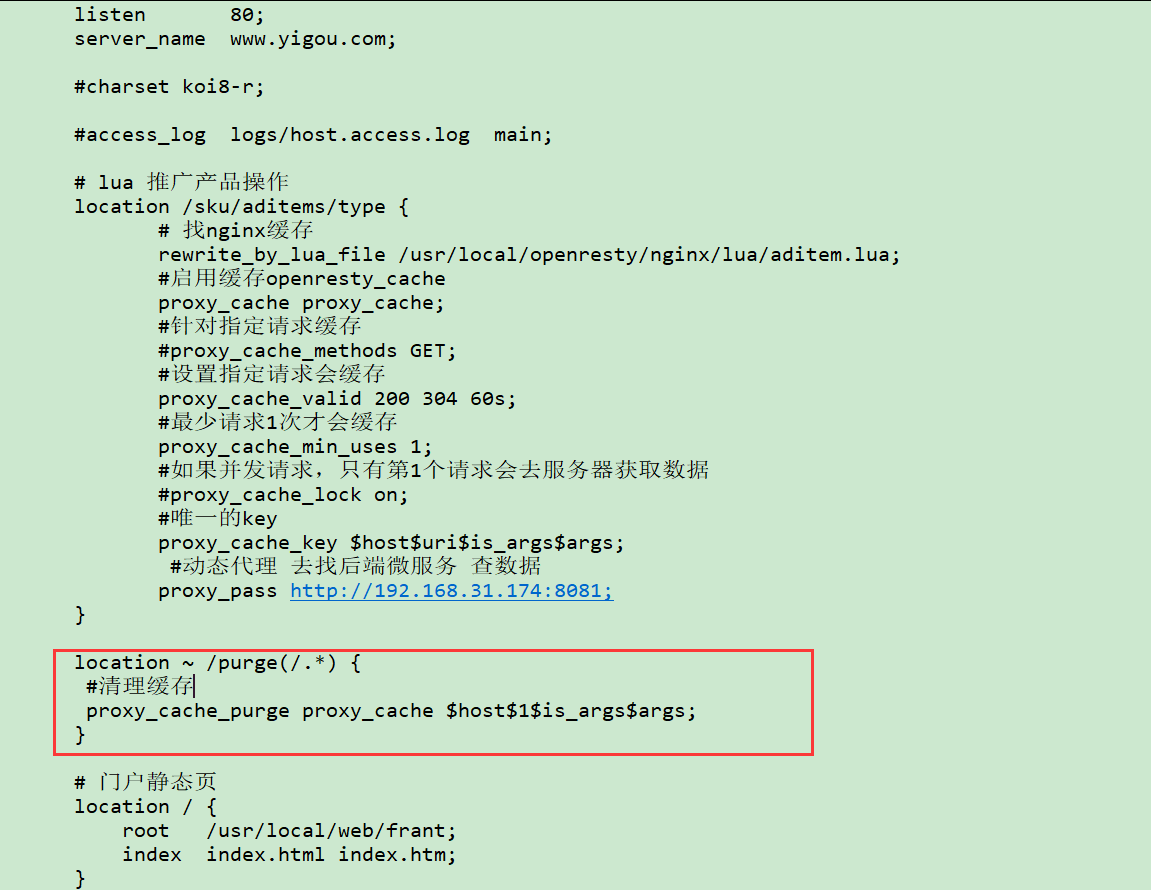
#清理缓存
location ~ /purge(/.*) {
#清理缓存 匹配 http://192.168.31.136/sku/aditems/type?id=1
proxy_cache_purge proxy_cache $host$1$is_args$args;
}
1$ 表示第一个路径 /purge 后面的路径匹配 (/sku/aditems/type,不包含/purge自己) http://192.168.25.136/sku/aditems/type?id=1此时访问 http://192.168.31.136/purge/sku/aditems/type?id=1,表示清除缓存,如果出现如下效果表示清理成功:
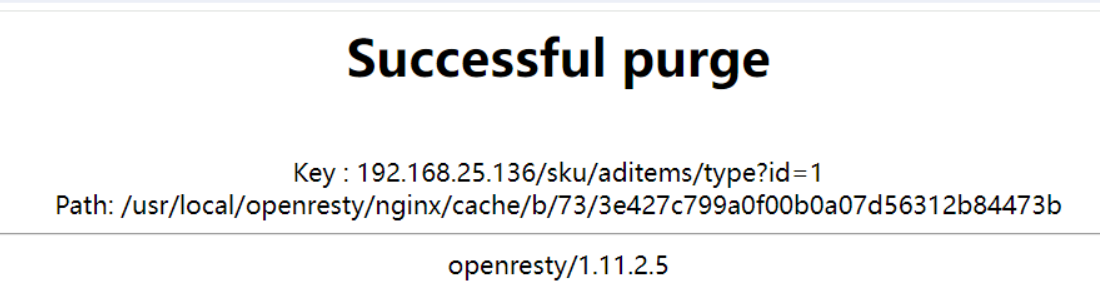
怎么确定,nginx代理缓存被清除了呢?
我们可以再次去看nginx代理数据对象数据,还是否存在
3. 缓存一致性
3.1实现原理讲解
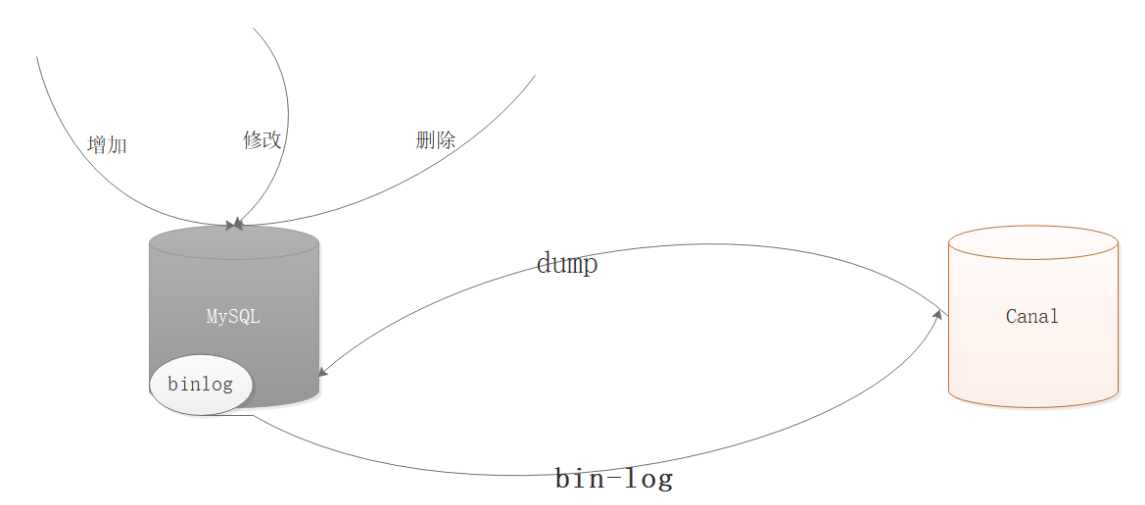
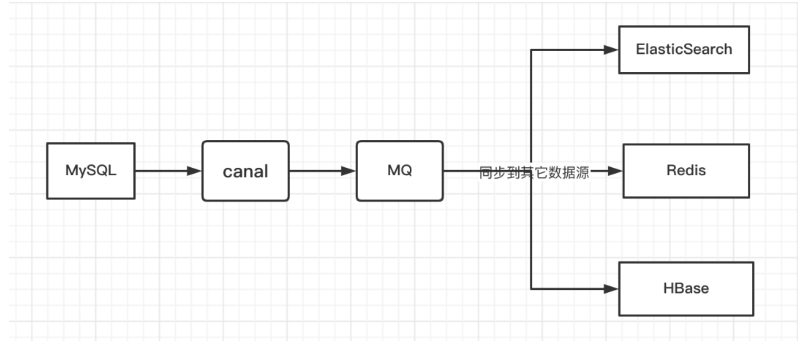
上面我们虽然实现了多级缓存架构但是问题也出现了,如果数据库中数据发生变更,如何更新Redis缓存呢?如何更新Nginx缓存呢?我们可以使用阿里巴巴的技术解决方案Canal来实现,通过Canal监听数据库变更,并实时消费变更数据,并更新缓存。
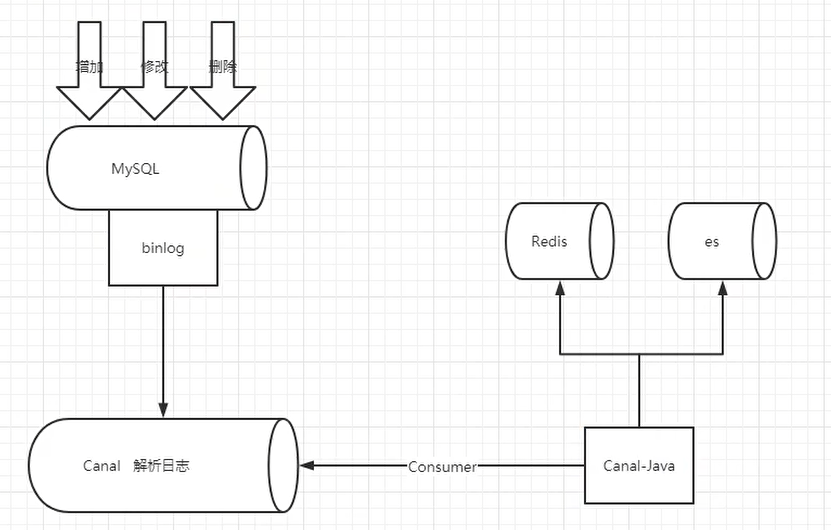
- MySQL master 将数据变更写入二进制日志( binary log, 其中记录叫做二进制日志事件binary log events,可以通过 show binlog events 进行查看)
- MySQL slave 将 master 的 binary log events 拷贝到它的中继日志(relay log)
- MySQL slave 重放 relay log 中事件,将数据变更反映它自己的数据
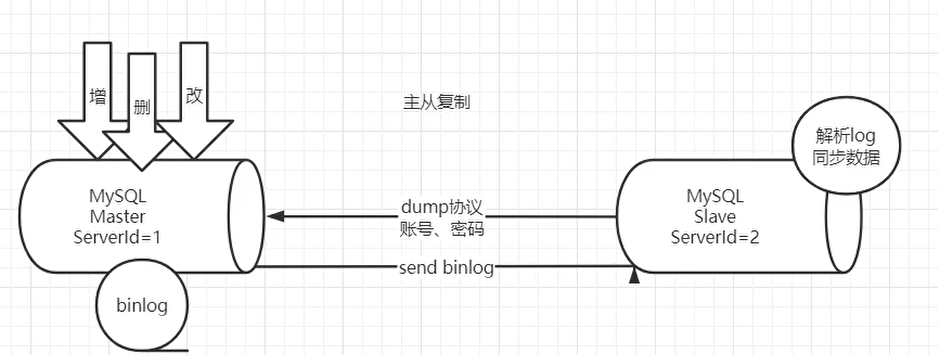
- canal 模拟 MySQL slave 的交互协议,伪装自己为 MySQL slave ,向 MySQL master 发送dump 协议
- MySQL master 收到 dump 请求,开始推送 binary log 给 slave (即 canal )
- canal 解析 binary log 对象(原始为 byte 流)
- 再发送到存储目的地,比如MySQL,Kafka,ElasticSearch等等。
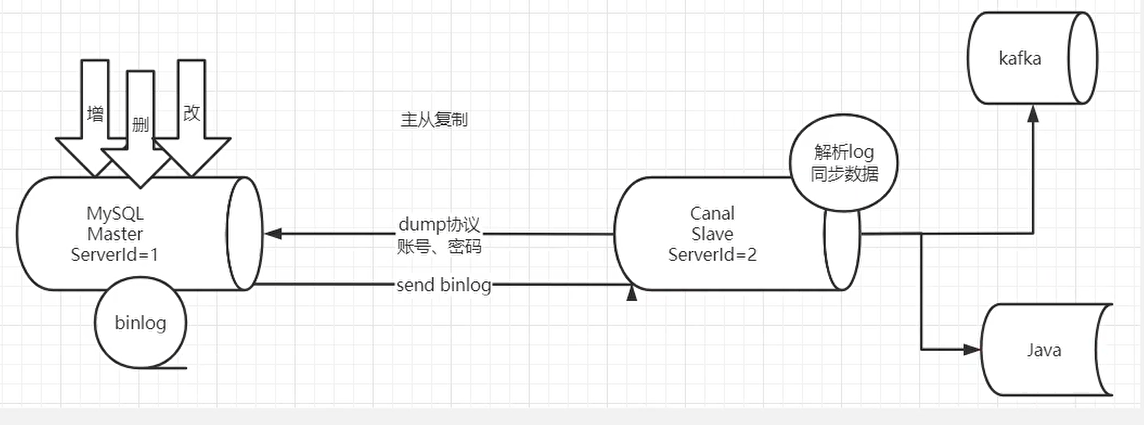
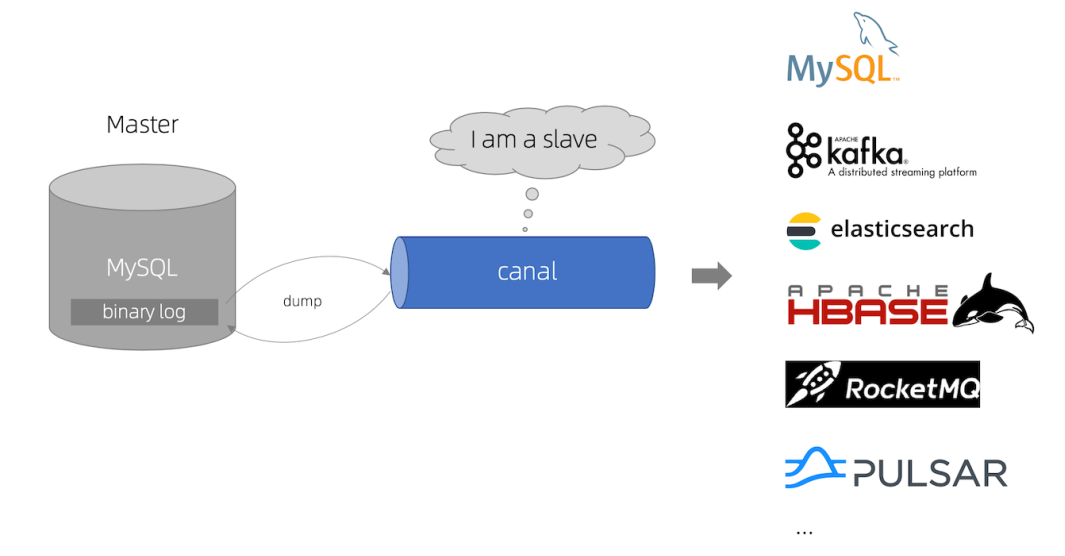
canal的好处在于对业务代码没有侵入,因为是基于监听binlog日志去进行同步数据的。而且能做到同步数据的实时性,是一种比较好的数据同步方案。
以上只是canal的原理和入门,实际项目并不是这样玩的,在实际项目中我们是配置MQ模式,配合RabbitMQ或者Kafka,canal会把数据发送到MQ中的topic,然后通过消息队列的消费者进行处理。
3.1 Canal安装
MySQL开启binlog
对于MySQL , 需要先开启 Binlog 写入功能,配置 binlog-format 为 ROW 模式,my.cnf 中配置如下:
docker exec -it mysql /bin/bash
cd /etc/mysql/
vim mysqld.cnf
[mysqld]
# 修改容器中的MySQL时间不同步的问题
default_time_zone='+8:00'
# 修改容器中的MySQL分组only_full_group_by问题
sql_mode=STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION
#修改表名不区分大小写问题
lower_case_table_names=1
# 设置服务器的排序规则为 utf8_general _ci
collation-server=utf8_general_ci
#设置服务器的默认字符集为 utf8
character-set-server=utf8
# 开启 binlog
log-bin=mysql-bin
# 选择 ROW 模式
binlog-format=ROW
# 配置 MySQL replaction 需要定义,不要和 canal 的 slaveId 重复
server_id=1
[client]
# 设置客户端的默认字符集为 utf8
default-character-set=utf8注:docker默认没有vim工具,可以在数据卷下进行操作,也可以安装工具
授权canal
权 canal 链接 MySQL 账号具有作为 MySQL slave 的权限, 如果已有账户可直接 grant:
先进入到 docker 中mysql 容器内部
docker exec -it mysql mysql -uroot -p
CREATE USER canal IDENTIFIED BY 'canal';
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%';
-- GRANT ALL PRIVILEGES ON *.* TO 'canal'@'%' ;
FLUSH PRIVILEGES;重新启动MySQL即可
Canal安装
linux硬盘空间不够的排查与清理
linux硬盘空间不够的排查与清理_linux清理磁盘空间-CSDN博客
我们采用docker安装方式:
[root@localhost ~]# docker pull canal/canal-server:v1.1.7
docker安装canal: docker环境下Canal的安装使用_docker 安装canal-CSDN博客
# 提前创建 /usr/local/docker/canal/conf 目录,接着来执行拷贝配置文件命令
docker cp canal:/home/admin/canal-server/conf/example/instance.properties /usr/local/docker/canal/conf
docker cp canal:/home/admin/canal-server/conf/canal.properties /usr/local/docker/canal/conf
# 删除原先的canal服务
docker rm -f canal
docker run --name canal \
-p 11111:11111 \
--restart=always \
-v /usr/local/docker/canal/conf/instance.properties:/home/admin/canal-server/conf/example/instance.properties \
-v /usr/local/docker/canal/conf/canal.properties:/home/admin/canal-server/conf/canal.properties \
-d canal/canal-server:v1.1.7[root@localhost ~]# docker exec -it canal /bin/bash
[root@6adf5de6d4df admin]# ls
app.sh bin canal-server health.sh node_exporter node_exporter-1.6.1.linux-amd64
[root@6adf5de6d4df admin]# cd canal-server/
[root@6adf5de6d4df canal-server]# ls
bin conf lib logs plugin
[root@6adf5de6d4df canal-server]# cd conf/
[root@6adf5de6d4df conf]# ls
canal.properties canal_local.properties example logback.xml metrics spring
进入 example
[root@6adf5de6d4df conf]# cd example/
[root@6adf5de6d4df example]# ls
h2.mv.db instance.properties入容器,修改核心配置canal.properties 和instance.properties,canal.properties 是canal自身的配置,instance.properties是需要同步数据的数据库连接配置。
[root@localhost conf]# ls
canal.properties instance.properties
[root@localhost conf]#
[root@localhost conf]# vim canal.properties

[root@6adf5de6d4df example]# vim instance.properties
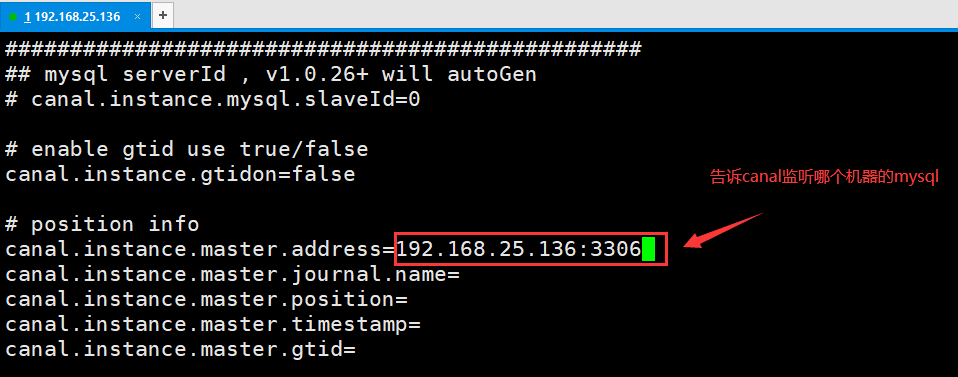
修改配置如下:
# position info canal.instance.master.address=192.168.25.136:3306
另一处配置:
找到 canal.instance.filter.regex 这里 进行修改

注:
# table regex #canal.instance.filter.regex=.*\\..* 任意数据库的任意表 #监听配置 canal.instance.filter.regex=shop_goods.ad_items
配置完毕重启即可!
bootstrap.yml:
server:
port: 8083
spring:
application:
name: mall-canal-service
cloud:
nacos:
config:
file-extension: yaml
# nacos 配置中心地址
server-addr: 192.168.254.131:8848
discovery:
#Nacos的注册地址
server-addr: 192.168.254.131:8848
#Canal配置
canal:
server: 192.168.254.131:11111 # canal的服务器ip
destination: example # canal 中配置的实例目录
#日志配置
logging:
pattern:
console: "%msg%n"
level:
root: error以上就是本期的分享啦,希望能够帮到你



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









