






视频链接:
预测本频道观看人数(上) - 机器学习基本概念简介_哔哩哔哩_bilibili
基于datawhale活动这里推荐简单学一下神经网络
基本概念
- 机器学习(machine learning):机器具有学习的能力,即机器具有寻找函数的能力(looking for function)
- 举例:语音识别,机器听到这个声音产生对应文字
- 图像识别:输入图片输出图片内容
回归(regression)
- 定义:假设机器要寻找的函数输出是数值,一个标量(scalar)
- 举例:要预测PM2.5,

- 这个输入的可能是有关预测PM2.5的相关数字
-
分类(classification)
分类是另外一个常见的任务,目的是要让机器做选择题
人类给出准备好的选项,这些选项称为_类别(class),_现在要找的函数输出就是从设定好的选项里选择一个当作输出,这个过程称之为分类
举例:检测邮箱中是否存在垃圾邮件.
注意分类不一定只有两个选项.
AlphaGo即属于回归任务又属于分类任务,这个机器人中存在一个函数来进行下棋,输入现在棋盘上黑子白字的位置,输出自己要下的位置信息;同样,其中存在一个函数,将棋盘中点位置输入作为类别,选择一个进行落子.
结构化学习(structured learning)
- 现如今机器不是简单输出一个数字一个选择,而是学习创造,输出一个文章,画一个画等
- 叫机器产生有结构的东西的问题就是结构化学习
机器学习案例学习
举例视频后台数据.
输入的是这个视频所有的点击量,观看人数等,预测明天的点击量观看人数
机器学习寻找函数的过程:
- 第一步:写出带有一个未知数的函数

- 其中,y是需要预测的函数在这里就是明日的点击量等,x是输入的数,点击量等,bw两个是未知参数
- **领域知识(domain knowledge)**用于以上这种带有未知参数的函数
- 并不一定就是按照这个函数进行,这只是一个简单的猜测,猜测往往基于对问题本质的了解,
- 在这里再次引出一个概念:带有未知参数的函数称为模型(model)
- x_1是特征(feature)w是权重(wight),b是偏置(bias)
- 第二步:定义损失(loss),损失也是函数.
- 这个损失函数的输入是函数里的参数,损失函数是L(b,w)
- 损失函数输出的值代表这一组位置的参数设定成一个数值的时候,这个数值是好还是不好
- 举例说明:b= 0.5K,w = 1
y
=
b
+
w
x
1
→
y
=
0.5
K
+
1
X
1
y = b+wx_1\rightarrow y = 0.5K+1X_1
y=b+wx1→y=0.5K+1X1
- 要从训练数据看这个函数好不好,即往日的点击量


- 根据预测函数计算出下一天的点击量在与真实值做对比,差值即为 e 1 e_1 e1(即第一天1月1日的计算值) e 1 = ∣ y ^ − y ∣ = 0.4 K e_1 = |\hat{y}-y|=0.4K e1=∣y^−y∣=0.4K;在仿照上面的操作计算出所有的差值.
- 将所有的差值求平均得到损失 L L = 1 N ∑ n e n L= \frac{1}{N} \sum_{n}e_n L=N1∑nen
- 在上面的公式中,N表示训练数据个数,这里表示3年的数据
- 扩展补充:计算差值有很多种方式,平均绝对误差;均方差如下

- 有一些 y 和 y ^ y和\hat{y} y和y^都是概率分布,这个时候会选择交叉熵(cross entropy)
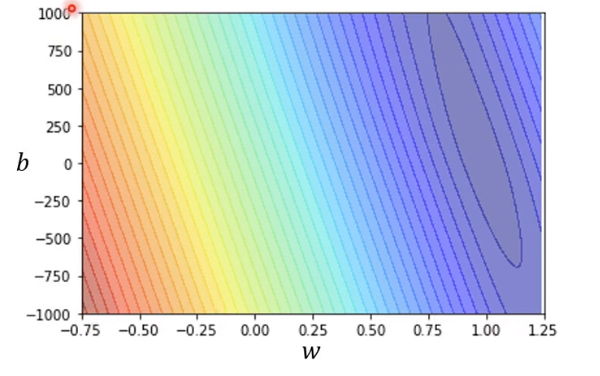
- 以上为根据真实数据所画出来的等高线图,其中红色代表wb损失大,蓝色与其相反,这个等高线图也被称作误差表面(error surface)
- 第三步:接触一个最优解,w和b,代入进去损失最小。记为
w
∗
和
b
∗
w^{*}和b^{*}
w∗和b∗
- 梯度下降是常用的优化方法
- 假设只有一个未知数w(为了简化方便理解),b已知。
- w带入不同的值就会得到不同的损失,

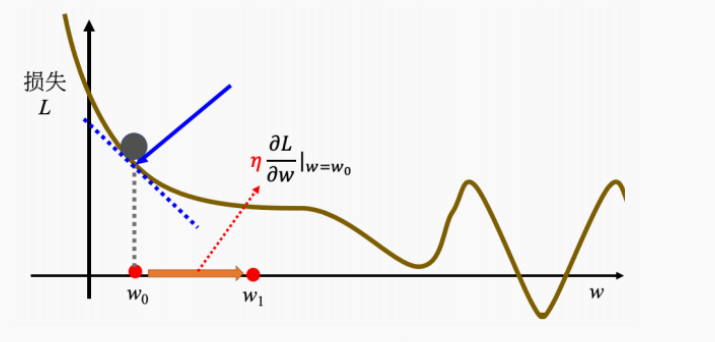
- 为了找到w让损失值最小,随机定一个 w 0 w_0 w0然后计算微分 ∂ L ∂ w ∣ w = w 0 \frac{∂L}{∂w}|_{w=w_0} ∂w∂L∣w=w0
- 微分为负数时:即左高右低,即w值变大,损失就变小;微分为正数时:即右高左低,即w值变小,损失就变大;
- w变化取决于两件事情:
- 第一就是这个点的斜率即微分,斜率大就大变,小就小变。
- 学习率(learning rate)_η _也会影响变化大小。这个学习率时自己设置的,如果设置大一点,每次更新就会量大,学习就会较快;设置小一点参数更新就会很慢。
- 引申出的定义:在机器学习中需要自己设置的的参数称为超参数(hyperparameter)
- 举例:在误差表面(1维)中的w_0处向右走一步,新位置记作w_1,这一步变化是_η ,_公式是:
- w 1 ← w 0 − η ∂ L ∂ w ∣ w = w 0 w^{1}\leftarrow w_0- η \frac{∂L}{∂w}|_{w=w_0} w1←w0−η∂w∂L∣w=w0
- 重复进行以上操作,计算
w
1
,
w
2
.
.
.
.
.
.
.
.
.
w_1,w_2.........
w1,w2.........停下来的两种结果:
- 在调整参数时,设置了上限,参数更新超过上限就不再更新
- 理想状态下,计算出来的值为0,即微分为0
- 梯度下降的常见问题:
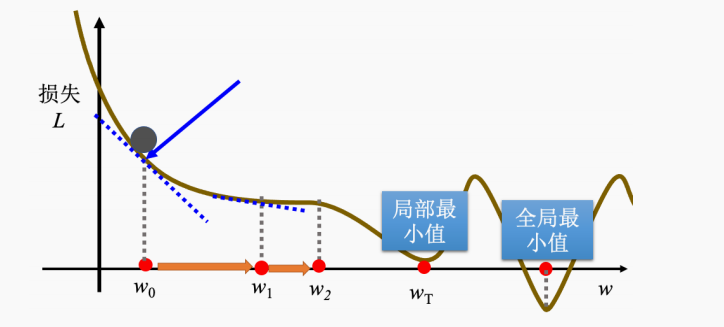
- 最大的问题就是没有找到最优解,没有找到损失最小的w。在这个图中从
w
0
w_0
w0向右侧走,一直到**全局最小值(global minima)的时候就会停止,但实际上,最小的损失值在局部最小值(local minima)**的位置。(初始值是随机的)
- 最大的问题就是没有找到最优解,没有找到损失最小的w。在这个图中从
w
0
w_0
w0向右侧走,一直到**全局最小值(global minima)的时候就会停止,但实际上,最小的损失值在局部最小值(local minima)**的位置。(初始值是随机的)
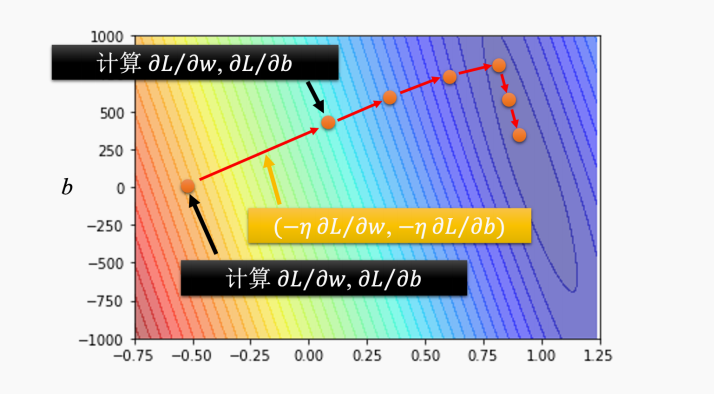
- 两个参数w和b与一个参数w没有什么不同。之前计算一个微分,现在计算两个微分,公式和上面的两个公式一样
- 实际上在在深度学习框架(pytorch等)中,微分是程序自动算。
- 举例:
- 梯度下降是常用的优化方法
最后结果呈现(真实数据):据图所示,二者差距不是很大,但是这个图像有一个神奇的周期性,每隔七天一个循环,所以可以更新模型,参考的是前七天的数据而不是前一天的数据。这个模型的修改也是基于对问题的理解,即领域知识。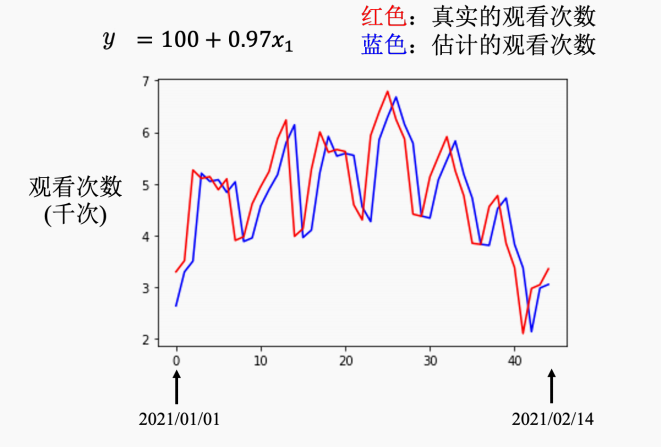
如果是参考前七天的数据的话:
y
=
b
+
∑
j
=
1
7
w
i
x
j
y = b+\sum_{j=1}^{7}w_ix_j
y=b+∑j=17wixj
下图中第一个函数就是只看前一天的数据从而得出的结果;第二个就是看前七天得出的结果,第三个是看前一个月得出的结果,第四个是看56天得出的结果,从以上数据得出,损失值并不是随着天数的增加而逐渐减小。
这些都是一个特征x乘以一个权重在加上一个偏置得到的,这些模型都是线性模型(linear model)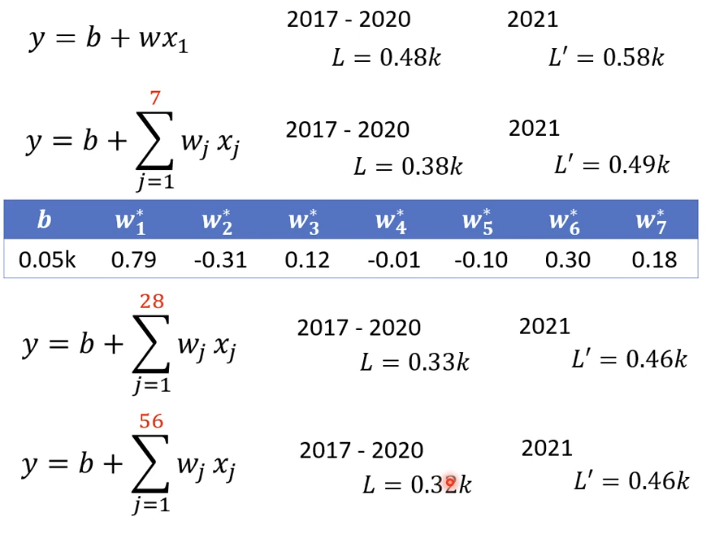
:::info
学生提问放在最后
提问:为什么损失可以是负的?
答 :损失函数是自己定义的,在定义中,损失就是估测的值跟正确的值的绝对值,按照这个来讲,决不可能是负数。但是实际上损失函数是自己定义的,比如:我设置损失函数是绝对值减去100,这个损失函数就可能为负数,上面图片误差表面(1维)并不是一个真实的损失,损失曲线可以是任意形状的,不一定是图中所示
:::
分段线性曲线(piecewise Linear Curves)
上述的线性模型过于简单,x和y之间很可能有更复杂的关系,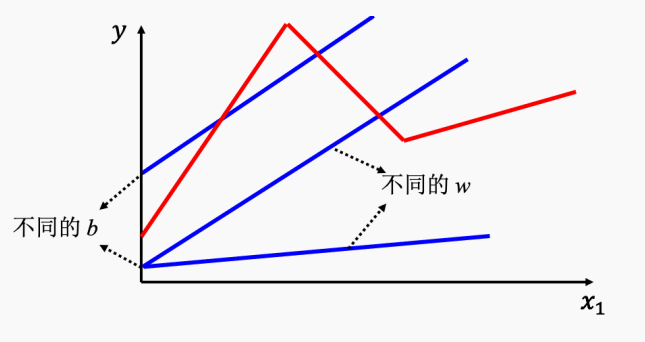
如上图所示,无论怎么更改权重或偏置,x和y的关系都是直线,总是单调的;w影响斜率,b影响和y轴交点。
基于上面视频播放的例子来看,观看量和天数之间可能并不会是简单的正比或者反比的关系。会有一个更为复杂的,类似于红线的关系存在。这种限制称为模型偏差(Model Bias)
为了写出红色函数,需要构造一个更为复杂的函数,引入Hard Sigmoid 函数(即下图中的蓝色折线)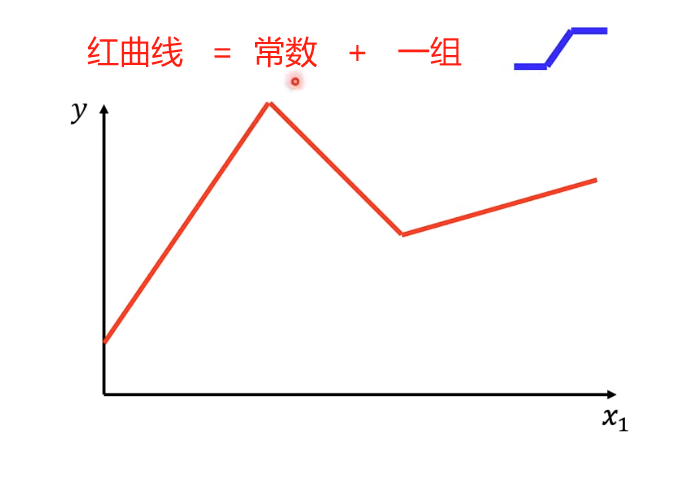
其中,常数一般设为起点的x值
Hard Sigmoid 函数函数“斜坡”起点就是红色函数的斜坡”起点;蓝色函数的“斜坡终点”是在第一个红色函数第一个拐角处。因此红蓝双方“斜坡”的斜率就一致,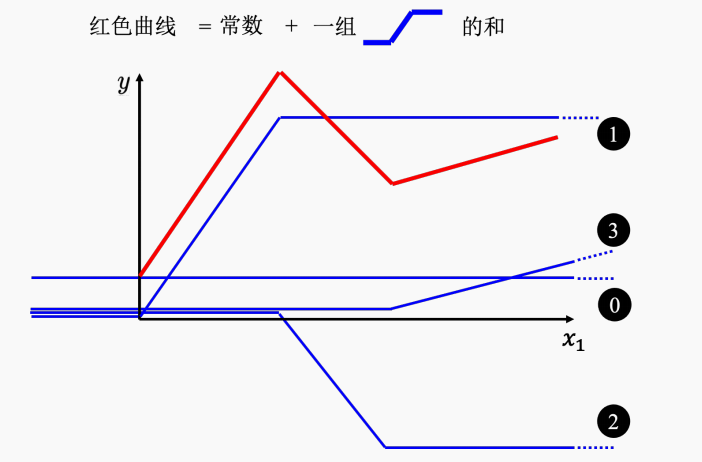
如图所示,就是函数“加法”,起始点是红色曲线和y轴交点,加上函数0组合出红色曲线左边的曲线;“斜坡部分”就是函数1,单增的红色曲线部分就是函数3.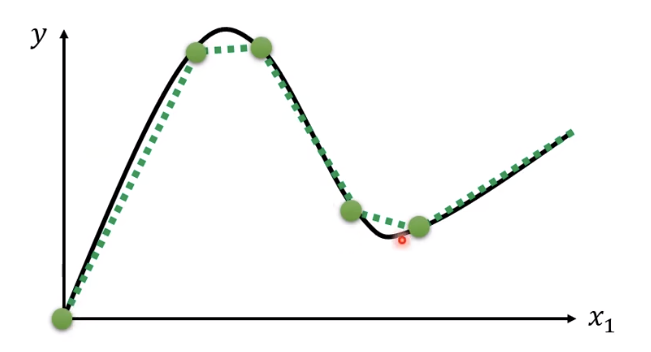
如上图所示,根据微元思想,只要点点得够多够密集,就可以用分段线性曲线无线逼近任意曲线。根据上面的函数“加法”,也就是说,任意曲线都可以用一堆蓝色函数组合起来。
直接写Hard Sigmoid函数不太容易,写Sigmoid函数逼近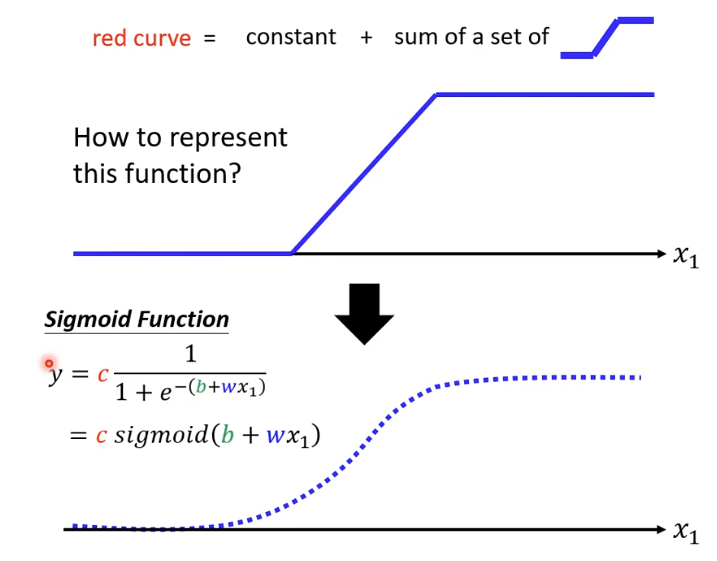
当
x
1
x_1
x1趋近于无穷大时,
e
(
−
b
+
w
x
1
)
e^{(-b+wx_1)}
e(−b+wx1)就会消失;当
x
1
x_1
x1非常大时,y就收敛于c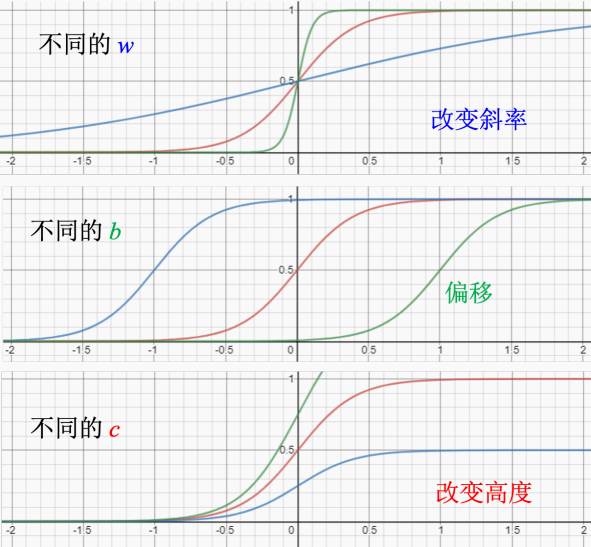
这里是更改不同的参数得到的函数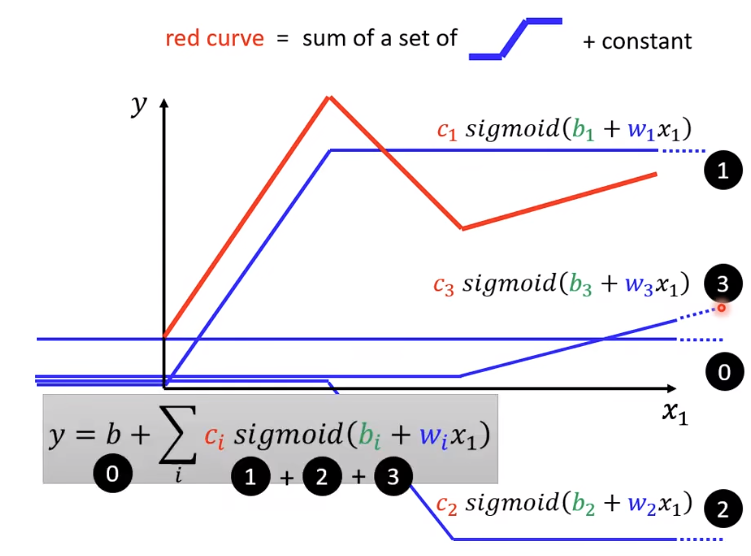
这个图是红色曲线的公式以及图像表示。这里bwc都是为止的,就可以根据“红色函数”制造出不同的蓝色函数。制造出不同的分段函数。制造出不同的分段线性曲线逼近各式各样的连续函数。
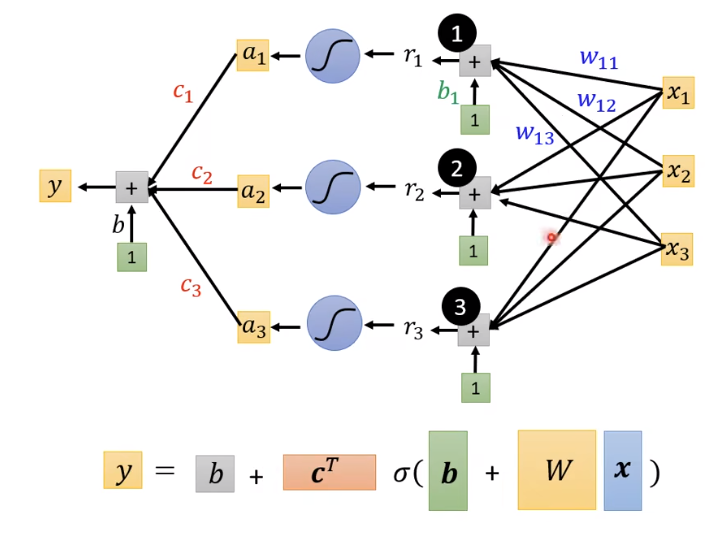
这里涉及神经网络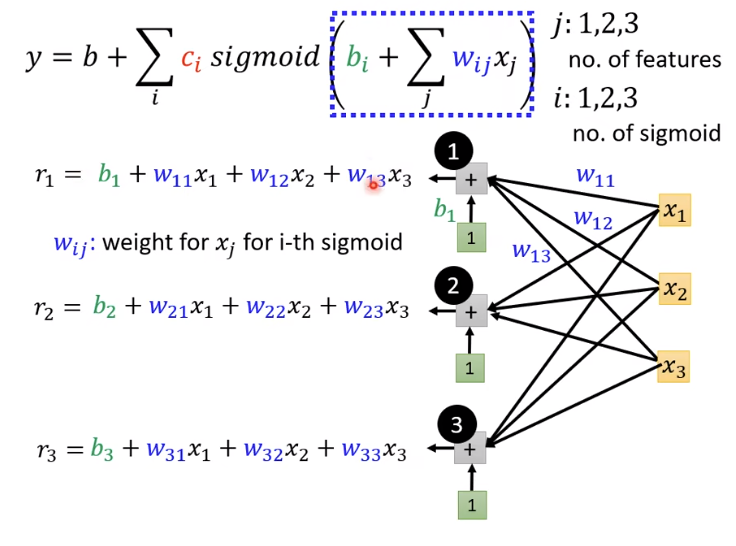
这里
w
11
w_{11}
w11指的是
x
1
×
w
1
x_1\times w_1
x1×w1i代表一个蓝色的函数,第几个蓝色的函数,j就是权重,最后就简化成图片左边的式子形式
r
1
r
2
r
3
r_1r_2r_3
r1r2r3。你也可以简化成下图的形式
最后换成矩阵相乘的形式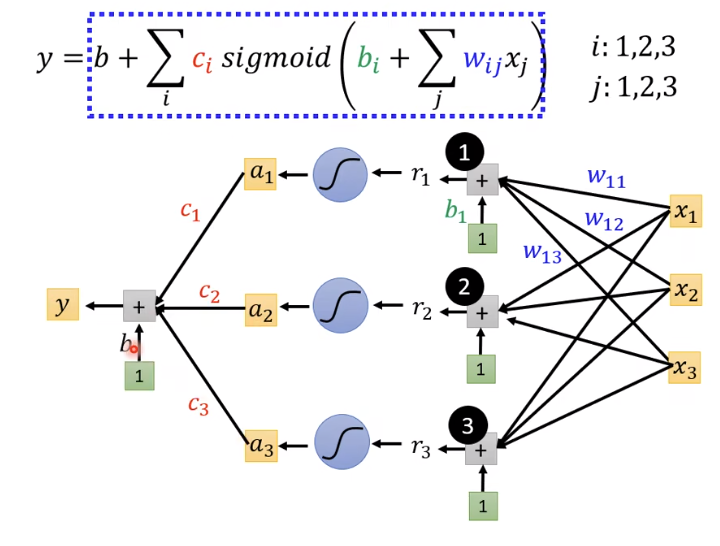
通过
r
1
r
2
r
3
r_1r_2r_3
r1r2r3得到Sigmoid函数
a
1
a
2
a
3
a_1a_2a_3
a1a2a3即
a
=
σ
(
r
)
a = σ(r)
a=σ(r)
因此,得到函数
y
=
b
+
c
t
a
y = b + c^{t}a
y=b+cta
在文档中提到的 ( a = σ ( r ) a = \sigma(r) a=σ(r) ) 表示使用Sigmoid函数对输入 ( r ) 进行非线性变换,生成新的输出 ( a )。这里的映射是一个数学上的函数操作,具体来说:
- 输入 ( r ): 这是一个实数,可以是从模型的前一层传递过来的加权和(可能还包括了偏置项),公式可以表示为 ( r = b + Wx ),其中 ( W ) 是权重矩阵,( x ) 是输入特征,( b ) 是偏置。
- Sigmoid函数 ( σ \sigma σ ): 这是一个将任意实数输入转换成(0, 1)区间内的输出的数学函数,其公式为 ( σ ( r ) = 1 1 + e − r \sigma(r) = \frac{1}{1 + e^{-r}} σ(r)=1+e−r1 )。这个函数的特点是它能够将输入值 ( r ) 压缩到0和1之间,当 ( r ) 很大的时候,( σ ( r ) \sigma(r) σ(r) ) 接近1;当 ( r ) 很小或者为负数时,( σ ( r ) \sigma(r) σ(r) ) 接近0。
- 输出 ( a ): 这是Sigmoid函数的输出,它将输入 ( r ) 映射到一个新的值。这个值 ( a ) 可以被解释为某个事件发生的概率,或者在某些情况下,可以作为二分类问题中的类标签预测(通常当 ( a ) 大于某个阈值,如0.5时,预测为正类)。
映射的过程就是将输入 ( r ) 通过Sigmoid函数转换成一个新值 ( a ) 的过程。这种转换是非线性的,它允许模型学习更加复杂的函数映射,这是线性模型所不具备的。在神经网络中,这种非线性变换是实现深层网络能够学习和模拟复杂函数的关键因素之一。
y = b + c T a y = b + c^T a y=b+cTa中的 c T c^T cT 是一个向量 c 的转置,它与 a 做矩阵乘法(在这里是向量点乘),计算得到的结果是模型的最终预测输出 y。在这个表达式中,b 是一个偏置项,而 c T c^T cT 和 a 的乘积代表了模型中某些权重参数与通过Sigmoid函数转换后的激活值的乘积,这通常在神经网络的输出层中出现,用于生成最终的预测结果。
总结来说,a 是Sigmoid激活函数的输出,而 c T c^T cT 是模型参数的一个向量转置,它们共同参与计算得到预测输出 y 。
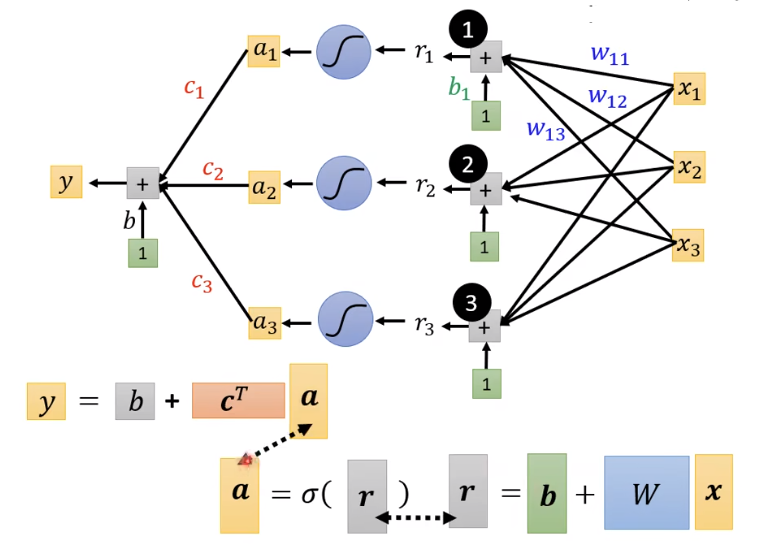
蓝色虚框推理: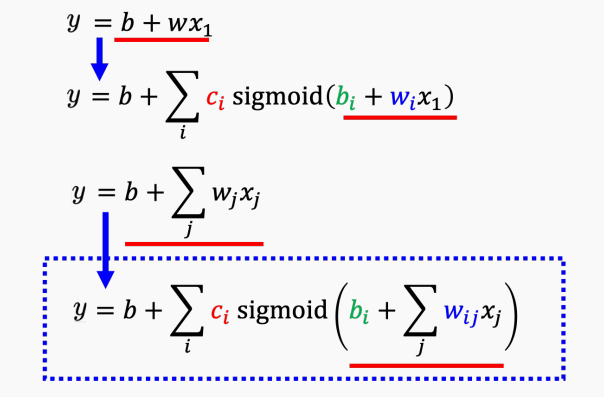
其中x是特征,绿色的b是向量,灰色的b是数值。
W
,
b
,
c
t
,
b
W,b,c^{t},b
W,b,ct,b是未知参数,
这里插入提问
:::info
问题一:优化是找一个可以让损失最小的参数,是否可以穷举所有可能的未知参数的值?
答 案:在只有w和b这两个参数的前提下可以进行穷举,因为参数很少。这里甚至不需要梯度下降,不需要优化。但是参数非常多的情况下,就不可,需要梯度下降来进行
:::
问题二:刚才的例子里面有 3 个 Sigmoid,为什么是 3 个,能不能 4 个或更多?
答 案:Sigmoid 的数量是由自己决定的,而且 Sigmoid 的数量越多,可以产生出来的分段
线性函数就越复杂。Sigmoid 越多可以产生有越多段线的分段线性函数,可以逼近越复
杂的函数。Sigmoid 的数量也是一个超参数。
因为未知参数太多,为了方便,这里使用**_θ _**来统设所有的参数,所以损失函数
L
(
w
,
b
)
→
L
(
θ
)
L(w,b)\rightarrow L(\theta)
L(w,b)→L(θ)
这
θ
\theta
θ指代的是
W
,
b
,
c
t
,
b
W,\mathbf{b},c^t,b
W,b,ct,b
- 先对y进行估测,计算误差e
- 将误差全部相加得到损失
- 优化,即
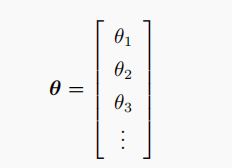
为了得到最小的一组
θ
\theta
θ,将损失最小的一组
θ
\theta
θ称为
θ
∗
\theta ^*
θ∗,接下来对
θ
\theta
θ进行随机初始化,按照下图计算微分,得到向量g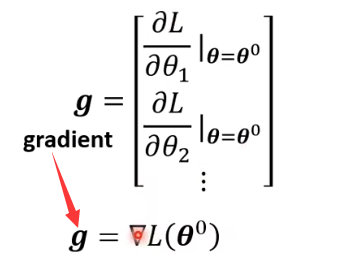
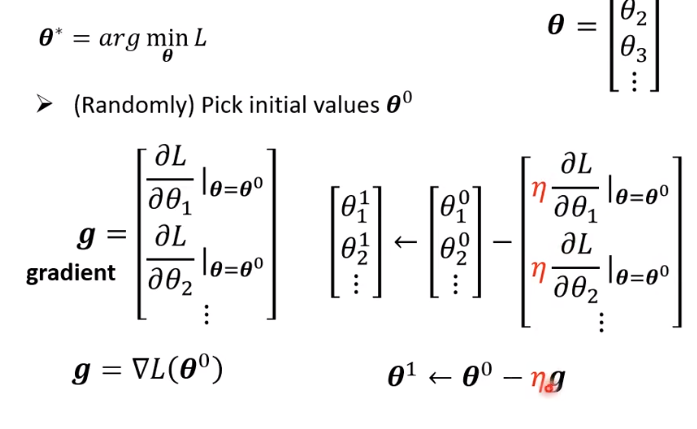
假设有 1000 个参数,这个向量的长度就是 1000,这个向量也称为梯度,_∇L _代表梯度。
L( θ 0 \theta_0 θ0) 是指计算梯度的位置,是在 **_θ _**等于 θ 0 \theta_0 θ0的地方。计算出 **_g _**后,接下来跟新参数, θ 0 \theta_0 θ0 代
表它是一个起始的值,它是一个随机选的起始的值,代表 _θ_1 更新过一次的结果, θ 2 0 \theta_2^{0} θ20减掉微分
乘以,减掉 _η _乘上微分的值,得到 θ 2 1 \theta_2^{1} θ21 ,以此类推,就可以把 1000 个参数都更新了。

模型详解
在机器学习中,模型的参数是那些在训练过程中通过学习数据调整的变量。这些参数决定了模型的行为和性能。对于一个具体的模型,比如一个神经网络,参数通常包括网络中的权重(weights)和偏置(biases)。
- 参数的集合:假设一个模型有1000个这样的参数,我们可以将它们想象为一个集合,其中每个参数都有一个特定的角色和值。这些参数共同决定了模型如何从输入数据映射到输出结果。
- 参数向量:为了方便处理,我们通常会将所有这些参数整合到一个单一的结构中,即一个向量。这个向量中的每一个元素对应模型中的一个参数。例如,如果我们有一个深度学习模型,其中包含多个层和多个神经元,每个神经元可能有自己的权重和偏置,所有这些权重和偏置都可以串联成一个长向量。
- 维度解释:在这个向量中,每个维度(或元素)代表一个可学习的参数。维度的数量,即向量的长度,直接等于模型中参数的总数。因此,如果模型有1000个参数,那么参数向量就有1000个维度。
- 参数向量的作用:
- 表示:参数向量提供了一种紧凑的方式来表示模型的全部知识。
- 更新:在训练过程中,我们通过计算梯度来更新这个向量中的每个元素,以此来优化模型的性能。
- 优化:参数向量的使用使得我们能够应用高效的数学和计算技术来优化模型,比如通过梯度下降算法。
- 梯度向量:在梯度下降算法中,我们计算损失函数相对于每个参数的梯度。这些梯度值也组成了一个向量,即梯度向量。梯度向量的每个元素是损失函数对参数向量中对应参数的偏导数。梯度向量的维度与参数向量的维度相同,都是1000。
- 更新规则:在梯度下降中,参数向量的每个元素(即每个参数)都根据对应的梯度值进行更新。更新规则通常是:新的参数值 = 旧的参数值 - 学习率 × 对应的梯度值。
通过这种方式,参数向量和梯度向量的使用使得模型训练过程变得系统化和高效。这种向量化的处理方法不仅简化了数学表达,还提高了计算的效率,尤其是在使用现代计算框架(如TensorFlow或PyTorch)时。
在机器学习模型中,参数通常被组织成一个向量,因为这样做可以方便地进行数学运算,尤其是当我们需要同时更新所有参数时。每个参数可以被视为向量中的一个分量。
假设模型有1000个参数,这意味着我们需要1000个独立的值来完全描述这个模型在某一特定状态下的所有可学习的部分。因此,如果我们将这1000个参数视为一个向量,那么这个向量的维度就是1000。这个向量中的每一个元素都对应模型中的一个参数。
梯度向量 (
∇
L
\nabla L
∇L ) 是由损失函数 ( L ) 对每个参数的偏导数组成的向量。对于1000个参数的模型,梯度向量也会有1000个元素,每个元素是损失函数相对于对应参数的偏导数。梯度向量的维度与参数向量的维度相同,因为每个参数都需要一个梯度值来指示如何更新。
在梯度下降算法中,梯度向量用于指导参数更新的方向和幅度。更新规则一般形式为:
θ new = θ old − η ⋅ ∇ L ( θ old ) \theta_{\text{new}} = \theta_{\text{old}} - \eta \cdot \nabla L(\theta_{\text{old}}) θnew=θold−η⋅∇L(θold)
其中:
- ( θ old \theta_{\text{old}} θold) 是当前的参数向量。
- ( η \eta η ) 是学习率,一个标量值。
- ( ∇ L ( θ old ) \nabla L(\theta_{\text{old}}) ∇L(θold) ) 是损失函数在当前参数下的梯度向量。
因此,当我们说梯度是一个向量,并且它的长度是1000,意味着我们有一个包含1000个偏导数值的向量,每个偏导数都对应一个参数,用于指导该参数如何更新。这样的向量操作不仅数学上优雅,而且在实现上也高效,因为可以利用现代计算库进行批量矩阵运算。
计算过程详解当我们在机器学习模型中谈论参数的计算过程时,我们通常指的是如何使用这些参数来更新模型,以便更好地拟合训练数据。以下是详细的计算过程,解释了如何使用参数向量和梯度向量进行模型训练:
1. 参数向量的初始化
首先,模型的1000个参数需要被初始化。这些参数可以随机初始化,或者使用某种启发式方法。初始化的参数集合可以表示为一个向量:
θ = [ θ 1 , θ 2 , … , θ 1000 ] \theta = [\theta_1, \theta_2, \dots, \theta_{1000}] θ=[θ1,θ2,…,θ1000]
其中每个 ( θ i \theta_i θi) 是模型中的一个参数。
2. 模型的前向传播
- 输入数据:模型接收输入数据 ( x )。
- 参数应用:输入数据通过模型的计算图,其中每个参数 ( θ i \theta_i θi) 被用来计算模型的预测输出。例如,在神经网络中,这可能涉及到矩阵乘法和非线性激活函数。
3. 计算损失
- 真实标签:模型的输出与真实标签 ( y ) 相比较。
- 损失函数:使用一个损失函数 ( L ) 来量化模型预测 ( y ^ \hat{y} y^ ) 和真实标签 ( y ) 之间的差异。常见的损失函数包括均方误差和交叉熵损失。
4. 计算梯度
- 梯度计算:计算损失函数 ( L ) 相对于每个参数 ( \theta_i ) 的梯度。这涉及到反向传播算法,它通过链式法则来计算每个参数的偏导数。
- 梯度向量:所有这些偏导数组成了梯度向量:
[ ∇ L ( θ ) = [ ∂ L ∂ θ 1 , ∂ L ∂ θ 2 , … , ∂ L ∂ θ 1000 ] \nabla L(\theta) = \left[ \frac{\partial L}{\partial \theta_1}, \frac{\partial L}{\partial \theta_2}, \dots, \frac{\partial L}{\partial \theta_{1000}} \right] ∇L(θ)=[∂θ1∂L,∂θ2∂L,…,∂θ1000∂L] ]
5. 参数更新
- 学习率:选择一个学习率 ( η \eta η),这是一个超参数,用于控制更新步长的大小。
- 更新规则:使用梯度下降法更新每个参数:
[ θ i ← θ i − η ⋅ ∂ L ∂ θ i \theta_i \leftarrow \theta_i - \eta \cdot \frac{\partial L}{\partial \theta_i} θi←θi−η⋅∂θi∂L ]
其中 ( θ i \theta_i θi ) 是更新前的参数值,( ∂ L ∂ θ i \frac{\partial L}{\partial \theta_i} ∂θi∂L ) 是对应的梯度值。
6. 迭代过程
- 重复迭代:重复步骤2到5,直到满足某个停止条件,如达到最大迭代次数,或者损失函数的值不再显著下降。
7. 模型评估
- 性能评估:在训练完成后,使用测试数据集评估模型的性能。
这个过程是机器学习中典型的梯度下降训练过程,通过不断地调整参数来最小化损失函数,从而提高模型的预测准确性。每一步都涉及到对参数向量的处理,包括计算梯度和更新参数,这些都是通过向量和矩阵运算高效实现的。
是把N笔数据随机分成一个一个的批量(batch),每一批批量里都有B笔数据.
原本是所有数据算一个损失L,现在是一个批量一个损失
L
i
L_i
Li如果B足够大,而这就会很接近.
最后用每一个批量的
L
i
L_i
Li来计算梯度,在更新参数.把所有的批量都看一遍叫做一个回合(epoch)
每一次更新参数叫做更新,这两个是不同的东西.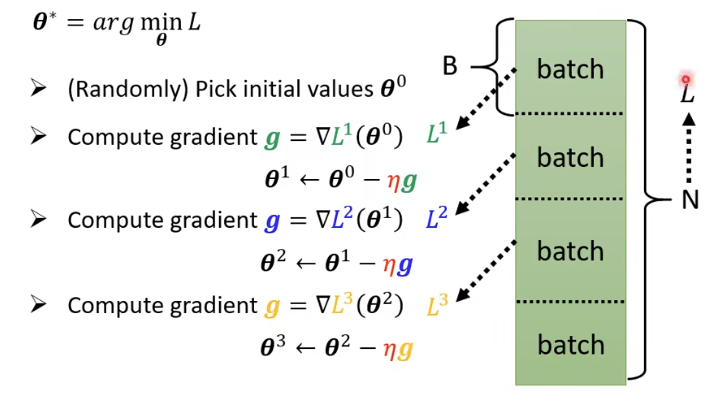
更新和回合的区别
举个例子,假设有 10000 笔数据,即 _N _等于 10000,批量的大小是设 10,也就 _B _等于 10。10000 个**样本(example)**形成了 1000 个批量,所以在一个回合里面更新了参数 1000 次,所以一个回合并不是更新参数一次,在这个例子里面一个回合,已经更新了参数 1000 次了。
第 2 个例子,假设有 1000 个数据,**批量大小(batch size)**设 100,批量大小和 Sigmoid
的个数都是超参数。1000 个样本,批量大小设 100,1 个回合总共更新 10 次参数。所以做了
一个回合的训练其实不知道它更新了几次参数,有可能 1000 次,也有可能 10 次,取决于它
的批量大小有多大。
模型变形
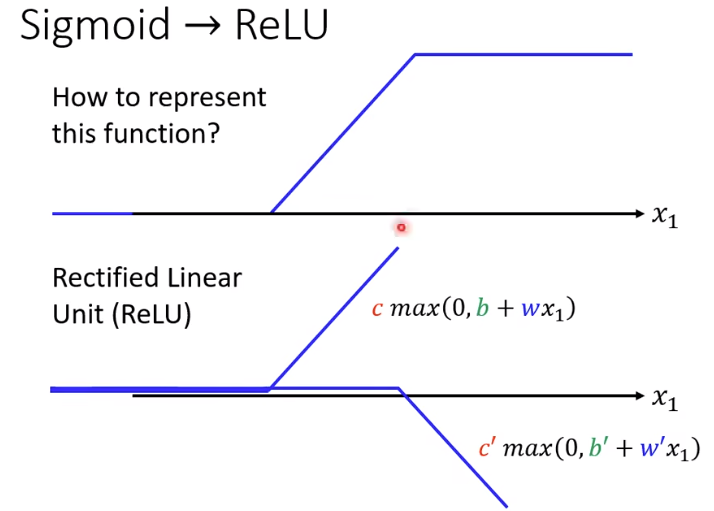
不一定要把Hard Sigmoid 换成 Soft Sigmoid。可以看作是两个修正线性单元(Rectified Linear Unit,ReLU)的总和.
公式:
c
×
m
a
x
(
0
,
b
+
w
x
1
)
c\times max(0,b+wx_1)
c×max(0,b+wx1)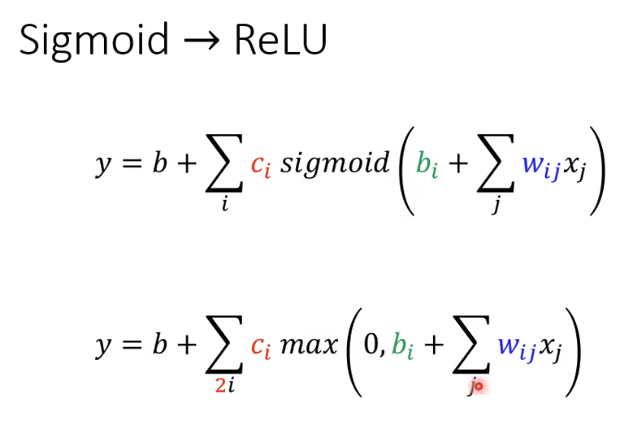
想要用ReLU,就直接换成max,不用Sigmoid.这里ReLU的数量是Sigmoid的2倍.二者都是激活函数(activation function)。
激活函数有很多,并不是只有这两个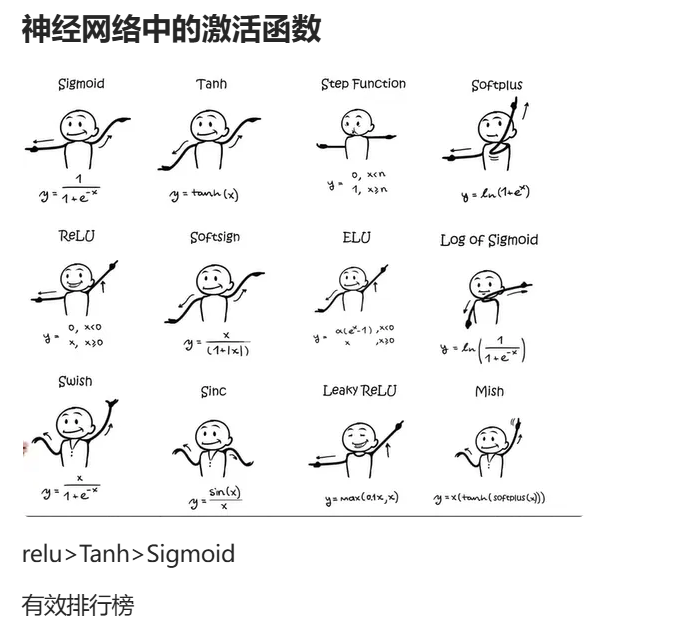
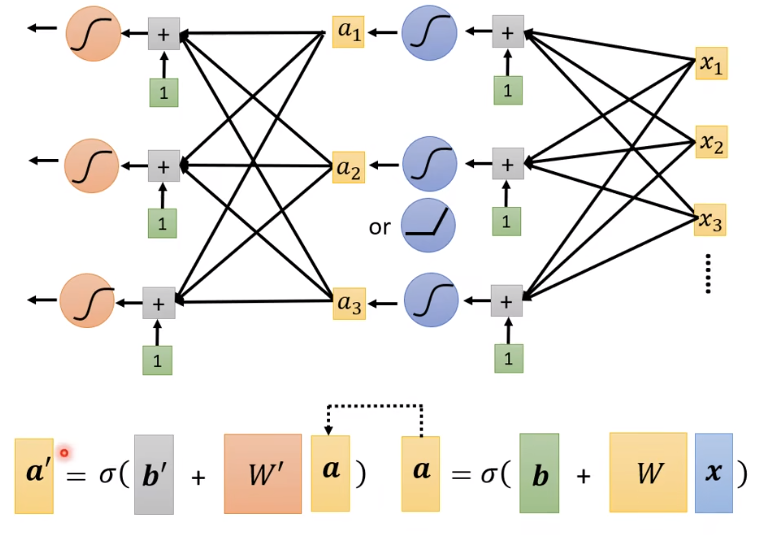
描述的是对模型进行改进的过程,特别是在深度学习中如何通过增加网络的深度(更多的层)来提高模型的性能。这个过程涉及到使用多个修正线性单元(ReLU)来构建更复杂的函数映射能力。### 模型改进的步骤:
- 从x到a的转换:
- 输入特征 ( x ) 通过一系列的变换最终转换为输出 ( a )。
- 这个过程首先包括将输入 ( x ) 与权重 ( W ) 相乘并加上偏置 ( b ),得到中间结果 ( z )。
- 然后,将 ( z ) 通过激活函数(如ReLU)转换得到 ( a )。
- 重复的层结构:
- 这个过程不是只进行一次,而是多次重复。每次重复都包括权重和偏置的更新,以及通过非线性激活函数。
- 每次转换可以视为一个“层”的操作,其中 ( a ) 可以作为下一层的输入 ( x )。
- 增加深度:
- 通过增加更多的层(即重复上述过程多次),模型可以学习更复杂的数据表示。
- 每一层都可以看作是对数据的一种更深层次的抽象或特征提取。
- 参数的增加:
- 每增加一层,意味着模型的参数数量(权重和偏置)也会增加。
- 这些额外的参数提供了更多的自由度,使模型能够拟合更复杂的数据模式。
- 超参数的角色:
- 增加层数是一个超参数决策,需要根据具体问题来调整。
- 层数太多可能导致过拟合,而层数太少可能导致模型学习能力不足。
- 实验结果:
- 文档中提到,通过增加层数,可以在训练数据上减少损失,同时在未见过的数据上也表现出更好的泛化能力。
- 例如,使用3次ReLU后,损失从280降到140,显示了模型性能的提升。
展示了通过增加网络深度来增强模型性能的直观例子。它强调了深度学习中“深度”一词的实际意义——即通过增加处理层来增强模型的学习能力。这种方法使得模型能够捕捉数据中的复杂特征和模式,从而在各种任务中,如图像识别、语音处理等领域,取得了显著的成功。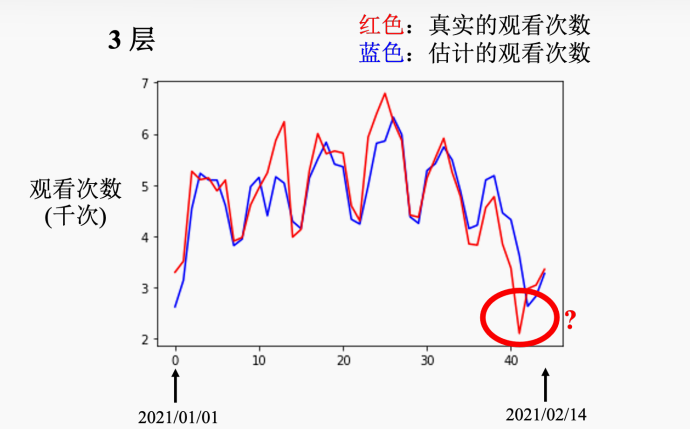
如上图所示,没有预测出红圈这一天的低谷,这一天是除夕夜,这个是可以改进的一点.除了这一点外,其余部分预估还是大概准确的.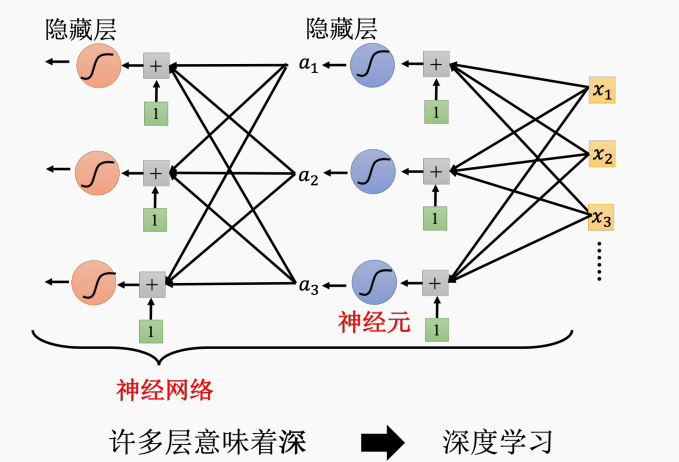
如上图所示,Sigmoid 或 ReLU 称为神经元(neuron),神经元构成神经网络(neural network)
这个是模拟人脑,但是和人脑又不太一样.每一排是一层,称为隐藏层(hidden layer),这个技术也是深度学习
神经网络的变种很多,大部分应用在图像识别等方面,在计算机视觉方面应用广泛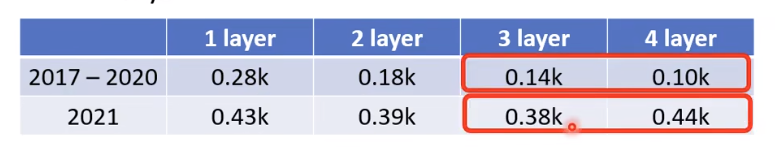
3层比4层差,但是在没看过的数据上,4 层比较差,3 层比较好,如上图所示。在训练数
据和测试数据上的结果是不一致的,这种情况称为过拟合(overfitting)。
这里应该选三层,通过三四层对比可以发现,三层对未知预估的更好,四层预估未来的差一点,我们需要的是对未来的预估更准确的模型,选三层.
深度学习的训练会用到反向传播(BackPropagation,BP),其实它就是比较有效率、算梯度的方法
反向传播反向传播算法是深度学习中用于训练神经网络的核心算法,它通过计算损失函数相对于网络参数的梯度来更新网络权重,从而最小化损失函数。以下是反向传播算法的更详细步骤:
前向传播(Forward Pass)
- 输入层:输入数据 ( x ) 被送入网络。
- 隐藏层计算:每一层的神经元接收输入,进行加权求和,加上偏置,并通过激活函数进行非线性变换。数学表达为:
[
a ( l ) = σ ( W ( l ) a ( l − 1 ) + b ( l ) ) a{(l)} = \sigma(W{(l)} a{(l-1)} + b{(l)}) a(l)=σ(W(l)a(l−1)+b(l))
]
其中 ( a ( l ) ) 是第 ( l ) 层的激活输出, ( W ( l ) a{(l)} ) 是第 ( l ) 层的激活输出,( W{(l)} a(l))是第(l)层的激活输出,(W(l)) 和 ( b ( l ) b^{(l)} b(l) ) 分别是该层的权重矩阵和偏置向量,( σ \sigma σ) 是激活函数。 - 输出层:最后一层(输出层)的激活输出 ( y ^ \hat{y} y^) 被用来计算损失函数。
- 损失函数:根据任务(如分类或回归),选择合适的损失函数 ( L ) 来衡量预测输出 ( y ^ \hat{y} y^ ) 和真实标签 ( y ) 之间的差异。
反向传播(Backward Pass)
- 损失梯度:计算损失函数 ( L ) 对输出 (
y
^
\hat{y}
y^ ) 的梯度,即:
∂ L ∂ y ^ \frac{\partial L}{\partial \hat{y}} ∂y^∂L - 链式法则:使用链式法则递归地计算每个参数的梯度。对于第 ( l ) 层的权重 (
W
(
l
)
)
和偏置
(
b
(
l
)
W{(l)} ) 和偏置 ( b{(l)}
W(l))和偏置(b(l) ),梯度计算为:
[
∂ L ∂ W ( l ) = ∂ L ∂ a ( l ) ⋅ ∂ a ( l ) ∂ z ( l ) ⋅ ∂ z ( l ) ∂ W ( l ) \frac{\partial L}{\partial W{(l)}} = \frac{\partial L}{\partial a{(l)}} \cdot \frac{\partial a{(l)}}{\partial z{(l)}} \cdot \frac{\partial z{(l)}}{\partial W{(l)}} ∂W(l)∂L=∂a(l)∂L⋅∂z(l)∂a(l)⋅∂W(l)∂z(l)
]
[
∂ L ∂ b ( l ) = ∂ L ∂ a ( l ) ⋅ ∂ a ( l ) ∂ z ( l ) ⋅ ∂ z ( l ) ∂ b ( l ) \frac{\partial L}{\partial b{(l)}} = \frac{\partial L}{\partial a{(l)}} \cdot \frac{\partial a{(l)}}{\partial z{(l)}} \cdot \frac{\partial z{(l)}}{\partial b{(l)}} ∂b(l)∂L=∂a(l)∂L⋅∂z(l)∂a(l)⋅∂b(l)∂z(l)
]
其中 ( z ( l ) ) 是第 ( l ) 层的加权输入加上偏置,即 z{(l)} )是第 ( l ) 层的加权输入加上偏置,即 z(l))是第(l)层的加权输入加上偏置,即 ( z ( l ) = W ( l ) a ( l − 1 ) + b ( l ) ( z{(l)} = W{(l)} a{(l-1)} + b^{(l)} (z(l)=W(l)a(l−1)+b(l) )。 - 激活函数的导数:计算激活函数的导数 ( ∂ a ( l ) ∂ z ( l ) \frac{\partial a{(l)}}{\partial z{(l)}} ∂z(l)∂a(l)),这取决于所使用的激活函数(如 Sigmoid、ReLU 等)。
参数更新
- 梯度下降:利用计算得到的梯度和学习率 ( \eta ) 更新每个参数:
W
(
l
)
new
=
W
(
l
)
old
−
η
∂
L
∂
W
(
l
)
W{(l)}_{\text{new}} = W{(l)}{\text{old}} - \eta \frac{\partial L}{\partial W^{(l)}}
W(l)new=W(l)old−η∂W(l)∂L_
b
(
l
)
new
=
b
(
l
)
old
−
η
∂
L
∂
b
(
l
)
b^{(l)}{\text{new}} = b{(l)}_{\text{old}} - \eta \frac{\partial L}{\partial b{(l)}}
b(l)new=b(l)old−η∂b(l)∂L
迭代优化
- 多次迭代:重复执行前向传播和反向传播,直到模型性能不再提升或达到预定的迭代次数。
优化策略
- 动量(Momentum):结合过去梯度的指数衰减平均,以加速梯度下降并减少震荡。
- 自适应学习率:如 Adam、RMSprop 等算法,根据参数的历史梯度自动调整学习率。
- 权重初始化:合适的初始化(如 Xavier 初始化)有助于避免梯度消失或爆炸问题。
- 正则化技术:如 L1、L2 正则化,以及 Dropout,防止过拟合,提高模型泛化能力。
反向传播算法的关键在于有效地计算梯度,并通过梯度下降或其他优化算法来更新网络参数。这个过程需要在每次训练迭代中重复执行,直到模型收敛。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









