






Kafka
消息队列的目的是为了什么?
消息队列真正的目的是通信,屏蔽底层复杂的通信协议,定义了一套应用层的更加简单的“生产者消费者”协议,从而达到了异步、解耦;
消息队列中间件之前的区别:
RabbitMQ:功能非常强
RocketMQ :性能堪比Kafka,功能也很多
Kafka:快
zeroMQ 、activeMQ等等
broker:消息的中转站,生产者把消息给broker就完成了任务,broker把消息主动推送给消费者(或者消费者主动轮询)

为什么kafka需要zookeeper?
Todo:Kafka学习笔记(二):Zookeeper 在 Kafka 中的作用_kafka中zk的作用-CSDN博客
Kafka基本概念
| Broker | 消息中间件处理节点,一个Kafka节点就是一个broker |
| Topic | kafka根据消息的topic进行消息归类,发布到kafka的每一条消息都要有一个topic |
| Producer | 消息生产者,向Broker发送消息的客户端 |
| Consumer | 消息消费者,消费Broker消息的客户端 |
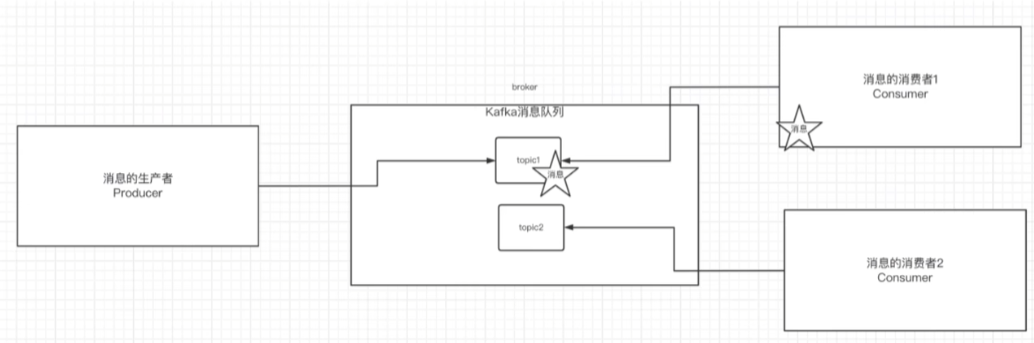
消息的偏移量以顺序消费原理
消费者消费信息的两种方式:1.当前消息的偏移量+1开始消息 2.从头开始消费(--from-beginning)
kafka中的消息存储在日志文件中,日志中存储了消费偏移量以及主题中的消息
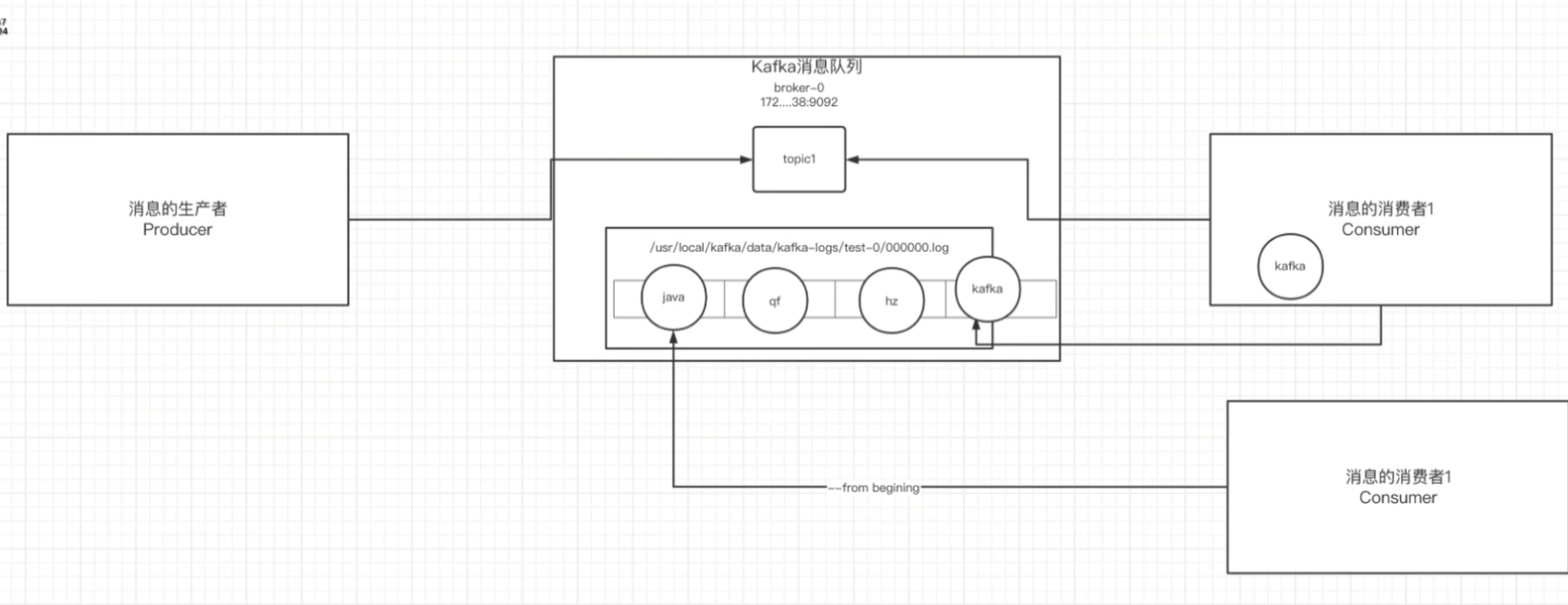
生产者将消息发送给broker,broker会将消息存储到日志文件中
/usr/local/kafka/data/kafka-logs/主题-分区/00000000. log消息的保存是有序的,通过offset偏移量来保存消息的顺序;
消费者消费消息是也是根据消息的偏移量来获取当前需要的消息的位置
单播消息
如果多个消费者在同一个消费者组中,那么只有一个消费者可以接收到订阅的topic的一个分区的消息;换言之:每个分区的消息在一个消费者组中只被一个消费者消费。
./kafka-console-consumer.sh --bootstrap-server 192.168.88.130:9092--consumer-property group.id=testGroup --topic test多播消息
一个主题的消息可以被多个消费者组同时订阅和消费。多个消费者组订阅同一个主题时,主题的每个分区都会被该组中的一个消费者消费
./kafka-console-consumer.sh --bootstrap-server 192.168.88.130:9092 --consumer-property group.id=testGroup1 --topic test
./kafka-console-consumer.sh --bootstrap-server 192.168.88.130:9092 --Consumer-property group.id=testGroup2 --topic test
消费者组信息查看
./kafka-consumer-groups.sh --bootstrap-server 192.168.88.130:9092 --list
./kafka-consumer-groups.sh --bootstrap-server 192.168.88.130:9092 --describe --group GroupName可以查看到
| group | |
| topic | |
| partion | 分区 |
| Current_Offset | 消费者组当前消费topic的偏移量 |
| Log_end_Offset | topic组中的最后一条消息偏移量 |
| LAG | (积压消息量)未消费数量 |
| Consumer-id | |
| host |
主题与分区
topic
概念:在kafka中是一个逻辑概念,用来划分消息种类,不同topic的消息,会被订阅该topic的消费者消费
问题:topic中的消息非常多,因为消息是存在日志文件中的,占用空间比较大,为了解决这个文件过大的问题,kafka提出了分区
分区
概念:一个主题的消息量是非常大的,因此可以通过分区设置,分布式存储消息;
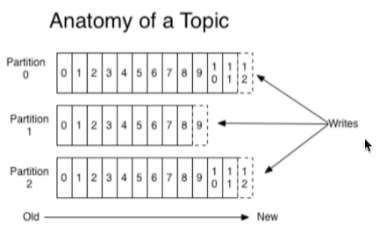
优点: 1.分区存储解决了topic日志文件过大的问题
2.可以并行读、并行写topic,提高了消息读写的吞吐量
./kafka-topics.sh --create --zookeeper 192.168.88.130:2181 --partitions 2 --topic test1
分区下可以根据稀疏索引快速定义到消息的具体位置
日志下各个文件存储的内容(重点)
test1-0:存储主题test1,分区0的消息,文件夹里面包括了稀疏索引00000.index文件,和000000.log消息文件
_consumer_offset-49:kafka内部自己创建了_consumer_offset主题包含50个分区。这个主题用来存放消费者消费某个主题的偏移量;消费者会定期将自己分区的偏移量offset提交给kafka内部的_consumer_offset主题中key是consumergroup+topic+分区号,value就是当前分区的offset,kafka会定期清除_consumer_offset中的消息,只保留最新的那条数据。
为什么要有50个_consumer_offset分区:为了抗高并发,通过consumegroupId的hash值在取模操作,得到消费者组应该提交的分区。
集群
创建主题时候除了可以指定分区,还可以指定备份
副本:副本是为主题中的分区设置多个备份,多个副本在kafka集群中的多个分区中,只有一个是leader,其他都是follower。
生产者 消费者处理消息都是在leader副本上,其他副本起的作用就是做数据备份
./kafka-topics.sh --create --zookeeper 192.168.88.130:2181 --replication-factor 3 --partitions 2 --topic my-replicated-topic

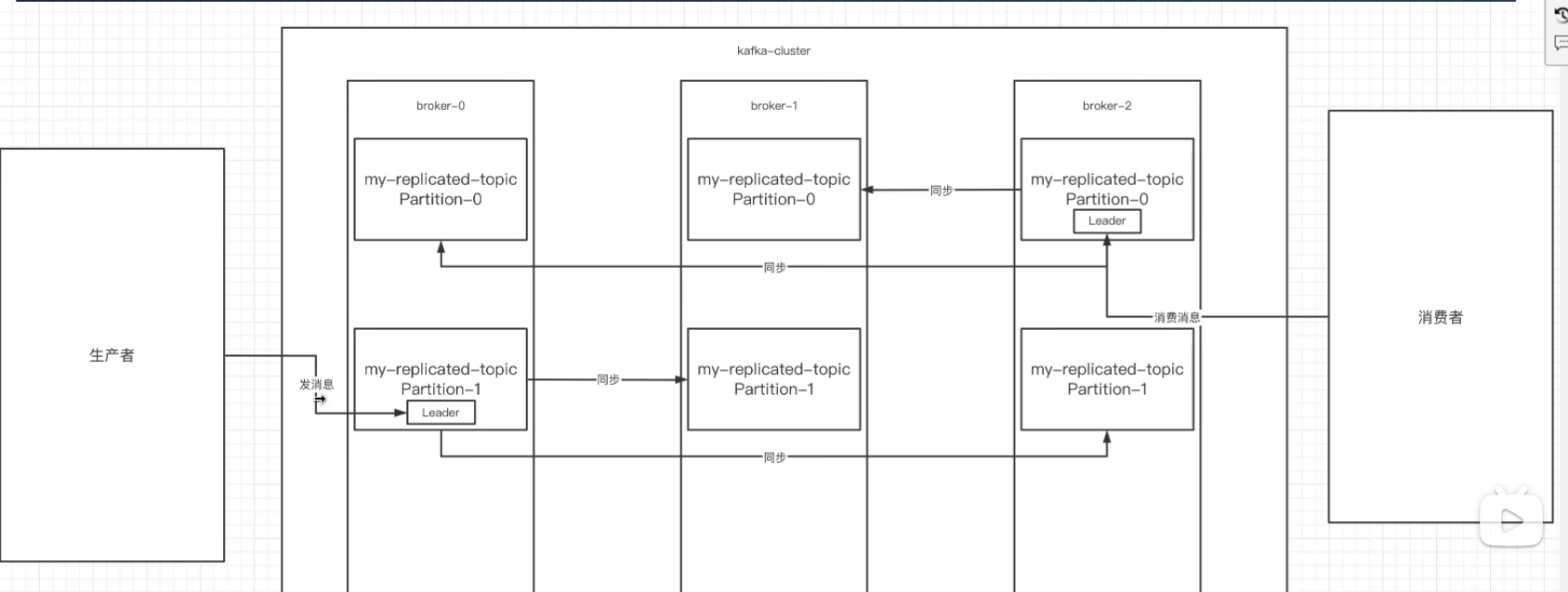
leader:生产者 消费者处理消息都是在leader副本上,leader把数据同步到其他副本。leader挂了,经过主从选举,从多个follower中选取新的leader
follower:接收leader同步过来的数据
isr:一个集合,用来存储可以同步和已经同步的节点,当leader挂了,会从isr中选举出新的leader;当某个节点性能太差,副本内容同步差的太多,就会从isr中剔除
关于集群消费-消费者组与分区(重点)
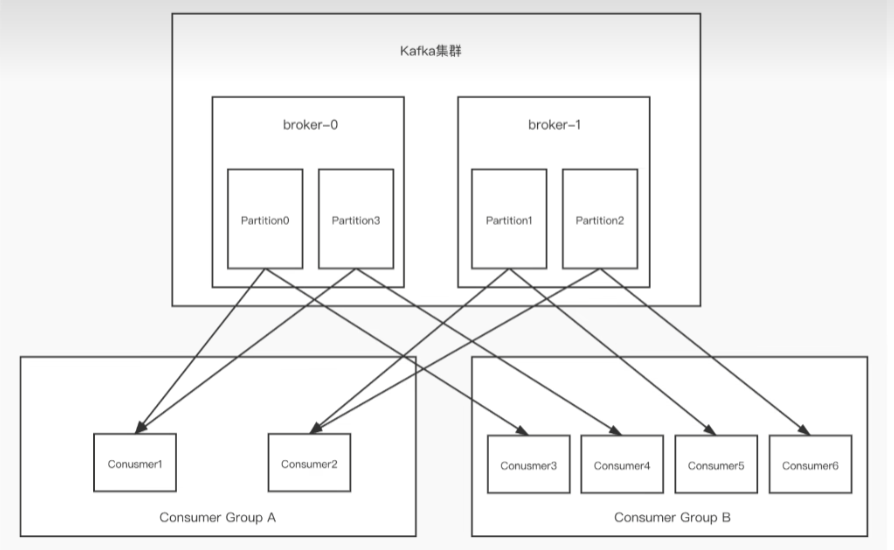
一个分区只能被一个消费者组的其中一个消费者消费,从而保证主题分区内消费消息的顺序性和一致性
一个消费者组可以订阅多个主题,一个主题也可以被多个消费者组订阅;
一个主题可以划分为多个物理分区,即 一个主题下的消息被存放在多个分区中,因为一个分区在一个消费者组中的只能被一个消费者消费,所以消费者组的数量一般不超过订阅的主题的分区数,消费者组内的每个消费者都会被分配一部分主题分区进行消费。
引:如何保证不在同一个分区的消息的顺序消费
生产者
发送消息的同步与异步
同步发送:生产者乡broker发送消息后阻塞等待接收broker的ack,收到ack后继续发送消息
void sendSyncMessage() throws ExecutionException, InterruptedException {
try {
//不指定分区的化,默认为(key.hashCode)% partitionNum
ProducerRecord<String, String> record = new ProducerRecord<>(TOPIC_NAME, "hello", "hello world");
RecordMetadata metadata = (RecordMetadata) producer.send(record).get();
System.out.println("Topic:" + metadata.topic() + ", Partition:" + metadata.partition() + ", Offset:" + metadata.offset());
} catch (Exception e) {
e.printStackTrace();
//发送失败的处理
}
}
这个get方法就相当于是同步阻塞,阻塞获取发送消息的结果异步发送:生产者向broker发送消息后,无需等待ack,接着发送下一条消息
private static final CountDownLatch countDownLatch = new CountDownLatch(5);
@Test
void sendAsyncMessage() throws InterruptedException {
ProducerRecord<String, String> record = new ProducerRecord<>(TOPIC_NAME, "hello", "hello world");
for (int i = 0; i < 5; i++) {
producer.send(record, (metadata, exception) -> {
if (exception == null) {
if (metadata != null)
System.out.println("Topic:" + metadata.topic() + ", Partition:" + metadata.partition() + ", Offset:" + metadata.offset());
} else {
exception.printStackTrace();
}
countDownLatch.countDown();
});
}
countDownLatch.await();
}ack参数
Kafka producer有三种ack机制 初始化producer时在config中进行配置;
Properties prop = new Properties();
prop.put(ProducerConfig.ACK_CONFIG = '2')ack = 0:意味着producer不等待broker同步完成的确认,继续发送下一条(批)信息
提供了最低的延迟。但是最弱的持久性,当服务器发生故障时,就很可能发生数据丢失。例如leader已经死亡,producer不知情,还会继续发送消息broker接收不到数据就会数据丢失。
ack = 1(默认):意味着producer要等待leader成功收到数据并得到确认,才发送下一条message。此选项提供了较好的持久性较低的延迟性。
Partition的Leader死亡,follwer尚未复制,数据就会丢失。
ack = -1:意味着producer得到x-1台follwer确认,才发送下一条数据
(有个默认的配置min.insync.replicas = x(默认为1,laeder接收就返回),x应该大于等于2)
发送失败会重试
消息重试机制能够保证消息发送的可靠性,但是可能会造成消息的重复发送,比如在网络抖动的情况下,因此在接收端broker要做好幂等性处理
Properties prop = new Properties();
props.put(ProducerConfig.RETRIES_CONFIG,3);
props.put(ProducerConfig.RETRY_BACKOFF_NS_CONFIG,300);
消息发送的缓冲区
kafka默认会创建一个32MB的缓冲区,用来存放要发送的消息,生产者会有一个本地线程从缓冲区中获取16KB的消息发送到broker,如果线程拉不到16KB的数据,间隔10ms也会发送数据到broker
prop.put(ProducerConfig.BUFFER_MEMORY_CONFIG, 33554432); prop.put(ProducerConfig.BATCH_SIZE_CONFIG, 16384);
prop.put(ProducerConfig.LINGER_MS_CONFIG, 10);消费者
java客户端创建消费者
Properties prop = new Properties();
prop.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.88.130:9092,192.168.88.130:9093,192.168.88.130:9094");
prop.put(ConsumerConfig.GROUP_ID_CONFIG, "groupTest");
prop.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
prop.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
new KafkaConsumer<>(prop);消费者的自动提交和手动提交
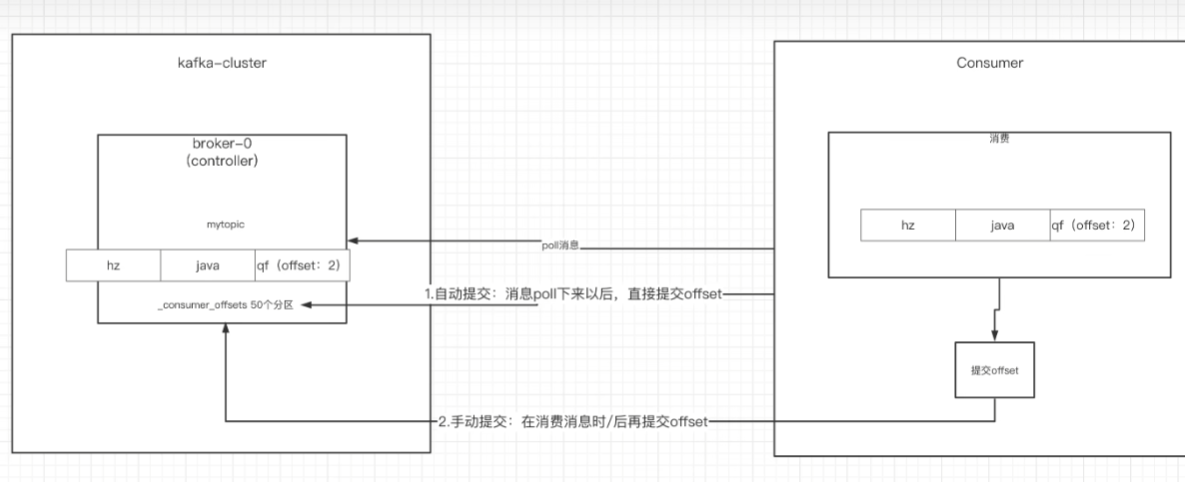
自动提交和手动提交,提交是向Consumer_offset-n中消费者消费分区内信息的偏移量->key是consumergroupID+topic+分区号,value就是当前分区的offset
自动提交:消费者从broker中poll到消息之后,马上提交偏移量
//是否开启自动提交,默认为true
prop.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "true");
prop.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, "1000");缺点:会丢消息,消费者poll下消息后,没有进行消费就挂了
手动提交:消费者poll下消息之后,对消息进行消费,消费完之后再提交偏移量
prop.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false");同步手动提交
@Test
void SyncCommit() throws InterruptedException {
consumer.subscribe(Collections.singleton(TOPIC_NAME));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000));
for (ConsumerRecord<String, String> record : records) {
System.out.println("partition: " + record.partition() +
" offset: " + record.offset() +
" value: " + record.value());
}
//手动提交偏移量,同步提交,当consumer提交完成,收到broker的ack才能停止阻塞
if (records.count() > 0) {
consumer.commitSync();
System.out.println("同步提交完成");
}
}
}
异步手动提交:
@Test
void AsyncCommit() throws InterruptedException {
consumer.subscribe(Collections.singleton(TOPIC_NAME));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000));
for (ConsumerRecord<String, String> record : records) {
System.out.println("partition: " + record.partition() +
" offset: " + record.offset() +
" value: " + record.value());
}
//手动提交偏移量,异步提交,当consumer提交完成,不用阻塞
if (records.count() > 0) {
consumer.commitAsync(new OffsetCommitCallback() {
@Override
public void onComplete(Map<TopicPartition, OffsetAndMetadata> map, Exception e) {
if (e != null) {
System.err.println("commit offset failed: " + map);
System.err.println("commit offset exception:" + e.getStackTrace());
}else{
System.out.println("异步手动提交");
}
}
});
}
}
}消费者poll消息的过程
配置:
prop.put(ConsumerConfig.MAX_POLL_RECORDS_CONFIG,"500");poll消息达到500条之后开始处理消息;
/*
* poll() 是长轮询拉消息
* */
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000));
for (ConsumerRecord<String, String> record : records) {
System.out.println("partition: " + record.partition() +
" offset: " + record.offset() +
" value: " + record.value());
}Duration.okMillis(1000),poll是一个阻塞调用,意味着它会等待直到有消息数据量达到目标量或者超时发生
如果拉去消息的条数没有达到配置的拉去条数,就会阻塞等待获取消息,当拉取时间达到这个参数时间的时候,即使没有拉取到目标条数的信息,消费者也会开始消费消息
如果拉取消息的数量达到配置数,就不用等待这个参数时间直接开始处理
如果两次poll的间隔超过30s,集群会认为该消费者的消费能力过弱,该消费者被踢出消费组,触发rebalance机制重新分配该消费者所消费的分区,rebalance机制会造成性能开销。可以通过设置这个参数,让一次poll的消息条数少一点
//一次拉取消息的最大数量 (根据消息者消费能力进行设置)
prop.put(ConsumerConfig.MAX_POLL_RECORDS_CONFIG,500);
//两次poll之间的时间间隔超过了30s,kafka就会认为该消费者消费能力差,会将该消费者从消费者组剔除,kafka就会重新分配该消费者所消费的分区
//(根据消息者消费能力进行设置)
prop.put(ConsumerConfig.MAX_POLL_INTERVAL_MS_CONFIG, 30 * 1000);消费者的健康检查,心跳检测机制
消费者向broker发送心跳的间隔时间,kafka如果超过10s没有收到心跳,kafka就会认为该消费者挂掉了,会将该消费者从消费者组剔除,然后reBalance来重新分配分区的消费者
//消费者向broker发送心跳的间隔时间
prop.put(ConsumerConfig.HEARTBEAT_INTERVAL_MS_CONFIG, 1000);
//kafka如果超过10s没有收到心跳,kafka就会认为该消费者挂掉了,会将该消费者从消费者组剔除
//kafka就会reBalance机制重新分配该消费者所消费的分区
//相当于是消费者的心跳超时时间
prop.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG, 10 * 1000);消费者消费操作
消费者通过 assign 方法显式地指派一组分区进行消费,而 seek 方法用于将指定分区的偏移量移动到特定的位置。
consumer.assign(Arrays.asList(new TopicPartition(TOPIC_NAME, 0)));consumer.assign(Arrays.asList(new TopicPartition(TOPIC_NAME, 0)));
consumer.seekToBeginning(Arrays.asList(new TopicPartition(TOPIC_NAME, 0)));consumer.assign(Arrays.asList(new TopicPartition(TOPIC_NAME, 0)));
consumer.seek(new TopicPartition(TOPIC_NAME, 0), 10);指定时间进行消费,会先获取主题的所有分区,然后遍历每个分区,根据时间获取分区内偏移量,然后poll消息
List<PartitionInfo> partitions = consumer.partitionsFor(TOPIC_NAME);
long timestamp = new Date().getTime() - 1000 * 60 * 60 * 24;
HashMap<TopicPartition, Long> map = new HashMap<>();
for (PartitionInfo partitionInfo : partitions) {
map.put(new TopicPartition(TOPIC_NAME,partitionInfo.partition()), timestamp);
}
Map<TopicPartition, OffsetAndTimestamp> parMap = consumer.offsetsForTimes(map);
for (Map.Entry<TopicPartition, OffsetAndTimestamp> entry : parMap.entrySet()) {
TopicPartition key = entry.getKey();
OffsetAndTimestamp value = entry.getValue();
if (key == null || value == null) continue;
//根据时间获取offset
Long offset = value.offset();
System.out.println("partition-" + key.partition() + "loffset-" + offset);
if (value != null) {
//根据起始偏移量进行获取消息
consumer.assign(Arrays.asList(key));
consumer.seek(key, offset);
}
while (true) {
/*
* poll() 是长轮询拉消息
* */
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000));
for (ConsumerRecord<String, String> record : records) {
System.out.println("partition: " + record.partition() +
" offset: " + record.offset() +
" value: " + record.value());
}
//手动提交偏移量,同步提交,当consumer提交完成,收到broker的ack才能停止阻塞
if (records.count() > 0) {
consumer.commitSync();
System.out.println("同步提交完成");
}
}
}新消费组对主题进行消费的消费模式
新消费者组的消费模式
earliest:从头开始消费,之后只消费最新消息
latest:从最新的offset开始消费(默认)
prop.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG,"earliest");
consumer = new KafkaConsumer<String, String>(prop);Springboot整合kafka
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
<version>2.4.3.RELEASE</version>
</dependency>spring:
kafka:
bootstrap-servers: 192.168.88.130:9092,192.168.88.130:9092,192.168.88.1303:9092
producer:
# 发生错误后,消息重发的次数。
retries: 3
#当有多个消息需要被发送到同一个分区时,生产者会把它们放在同一个批次里。该参数指定了一个批次可以使用的内存大小,按照字节数计算。
batch-size: 16384
# 设置生产者内存缓冲区的大小。
buffer-memory: 33554432
# 键的序列化方式
key-serializer: org.apache.kafka.common.serialization.StringSerializer
# 值的序列化方式
value-serializer: org.apache.kafka.common.serialization.StringSerializer
# acks=0 : 生产者在成功写入消息之前不会等待任何来自服务器的响应。
# acks=1 : 只要集群的首领节点收到消息,生产者就会收到一个来自服务器成功响应。
# acks=all :只有当所有参与复制的节点全部收到消息时,生产者才会收到一个来自服务器的成功响应。
acks: 1
consumer:
# 设置kafka的消费者组
group-id: groupTest
# 自动提交的时间间隔 在spring boot 2.X 版本中这里采用的是值的类型为Duration 需要符合特定的格式,如1S,1M,2H,5D
auto-commit-interval: 1S
# 该属性指定了消费者在读取一个没有偏移量的分区或者偏移量无效的情况下该作何处理:
# latest(默认值)在偏移量无效的情况下,消费者将从最新的记录开始读取数据(在消费者启动之后生成的记录)
# earliest :在偏移量无效的情况下,消费者将从起始位置读取分区的记录
auto-offset-reset: earliest
# 是否自动提交偏移量,默认值是true,为了避免出现重复数据和数据丢失,可以把它设置为false,然后手动提交偏移量
enable-auto-commit: false
# 键的反序列化方式
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
# 值的反序列化方式
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
listener:
#当每一条记录被消费者监听器(ListenerConsumer)处理之后提交
#RECORD
#当每一批poll()的数据被消费者监听器(ListenerConsumer)处理之后提交
#BATCH
#当每一批poll()的数据被消费者监听器(ListenerConsumer)处理之后,距离上次提交时间大于TIME时提交
#TIME
#当每一批poll()的数据被消费者监听器〈(ListenerConsumer)处理之后,被处理record数量大于等于COUNT时提交
#COUNT
#TIME | COUNT有一个条件满足时提交
#COUNT_TINE
#当每一批poll()的数据被消费者监听器(ListenerConsumer)处理之后,手动调用Acknowledgment .acknowledge()后提交
#NANUAL
#手动调用Acknowledgment.acknowledge()后立即提交,一般使用这种
#manual_immediate
# 在侦听器容器中运行的线程数。
concurrency: 5
#listner负责ack,每调用一次,就立即commit
ack-mode: manual_immediate
# 如果Broker上不存在至少一个配置的主题(topic),则容器是否无法启动,
# 该设置项结合Broker设置项allow.auto.create.topics=true,如果为false,则会自动创建不存在的topic
missing-topics-fatal: false消费者消费操作:
@KafkaListener(groupId = "groupTest",topicPartitions = {
@TopicPartition(topic = "topic1",partitions = {"0","1"}),
@TopicPartition(topic = "topic2",
partitions = {"0"},
partitionOffsets = @PartitionOffset(partition = "1",initialOffset = "100"))
},concurrency = "2")// concurrency 消费者线程数
public void listenTopicPartition(ConsumerRecord<String,String> record,Acknowledgment ack){
System.out.println("topic:"+record.topic()+" partition:"+record.partition()+" offset:"+record.offset()+" value:"+record.value());
ack.acknowledge();
}kafka集群中的controller、Rebalance、HW
Controller
Controller:kafka集群在启动的时候,每个节点都会在zookeeper中创建一个临时序号节点,节点序号最小的broker将会成为集群中的controller;controller负责管理整个集群的所有分区和副本的状态:
1.当某个分区的leader副本broker挂掉后,controller会选举新的副本作为leader;
ISR:可以和leader同步以及已经同步的节点的集合,存放顺序是根据同步的偏移量跟leader越接近,排的越靠前,controller从isr中选出靠前的节点作为leader(同步量最高的节点会被作为leader)
2.检测到某个分区的isr变化之后(集群中有broker增加或减少节点),会通知其他broker更新其元数据信息
3.当集群有新的分区增加或减少,controller会通知其他节点
rebalance
前提:消费者没有指定分区消费,如果消费者指定了分区消费,那其他broker挂掉之后,就不会讲分区rebalance给已经制定了分区的节点
触发时机:
- 当消费者两次消费间隔超过30s,会被kafka认为消费者消费能力弱,会将这个消费者从消费者组剔除,然后rebalance之前的分区给其他节点负责
- 当消费者下线,之前负责的分区也会rebalance给其他消费者
在触发rebalance之前,分区分配给消费者的策略是:
-
- range:根据公式计算得到每个消费消费哪几个分区︰第一个消费者是分区总数/消费者数量+1,之后的消费者是分区总数/消费者数量
- 轮询:大家轮着来
- sticky:粘合策略,如果需要rebalance,会在之前已分配的基础上调整,不会改变之前的分配情况。如果这个策略没有开,那么就要进行全部的重新分配。建议开启。
HW&LOE原理
HW是已完成同步的位置。消息在写入broker时,且每个broker完成这条消息的同步后, hw才会变化。在这之前消费者是消费不到这条消息的。在同步完成之后,HW更新之后,消费者才能消费到这条消息,这样的目的是防止消息的丢失。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









