






1.什么是LoRA?它的原理是什么?为何能减少参数并缓解过拟合?为什么低秩假设有效?
低r有效:
-
有效性:神经网络的参数更新矩阵通常是低秩的(信息集中在主要特征方向),低秩分解能以少量参数捕捉核心变化,避免冗余。
答:
-
**LoRA(Low-Rank Adaptation)**是一种参数高效微调技术(高校微调大模型技术),用于在不显著增加计算成本的情况下优化大模型。
-
原理:LoRA(Low-Rank Adaptation)通过低秩矩阵分解,在原模型参数旁添加低秩适配矩阵,仅训练这些适配矩阵而非全参数。例如,原权重矩阵 W∈Rd×kW∈Rd×k 被分解为 W+ΔW=W+BAW+ΔW=W+BA,其中 B∈Rd×rB∈Rd×r, A∈Rr×kA∈Rr×k,r≪d/kr≪d/k。参数减少量可达90%以上,降低过拟合风险。(过拟合是在训练集上表现很好但是在新的未见过的测试数据上表现很差的现象也就是模型对训练数据的细节和噪音过度学习 导致其泛化能力变差)
-
示例:若原始矩阵 W∈R1000×1000,设置秩 r=8,则 B∈R1000×8、A∈R8×1000,参数量从1,000,000降至16,000。
2. 为什么要用LoRA改进BERT而不用其他大模型?LoRA是否可能导致模型欠拟合?如何验证?
-
BERT的优势:基于Transformer的双向编码能力,适合捕捉评论文本的深层语义。
-
LoRA的适配性:
-
BERT参数量大(如bert-base-chinese有102.3M参数),全参数微调成本高,LoRA可减少85%训练参数。
-
相比其他方法(如Adapter引入额外结构,Prefix-Tuning对输入敏感),LoRA无需修改模型架构,适合BERT的注意力机制。
-
-
项目需求:外卖评论数据规模较小,LoRA能有效防止过拟合。
-
欠拟合风险:若秩r过小(如r=2),可能无法捕捉足够任务特征。
-
验证方法:监控训练集损失,若损失持续不降且验证集表现差,需增大r或调整学习率。
3. Lora中最重要的参数是什么?
他的r越大 那么参数量就越大
在LoRA(Low-Rank Adaptation)中,最重要的参数是秩(Rank),通常用字母 r 表示。秩 r 决定了低秩矩阵的维度,也就是在模型微调过程中用于近似全参数微调的参数量。较小的 r 可以显著减少参数数量,从而降低计算成本和显存占用,但可能会影响模型的表达能力。
除了秩 r,LoRA中还有以下重要参数:
-
Alpha(缩放因子):用于控制低秩矩阵对原始模型的影响程度。Alpha与秩 r 的比值决定了权重的变化程度。
-
学习率(Learning Rate):决定了模型参数更新的步长。LoRA对学习率较为敏感,通常需要比全参数微调更高的学习率。
-
Dropout:用于防止过拟合,通过随机丢弃部分神经元来增强模型的泛化能力。
-
目标模块(Target Modules):指定模型中需要插入低秩矩阵调整的模块,通常包括自注意力层的
q_proj、k_proj、v_proj和o_proj等。
3.1LoRA的超参数(如秩r、缩放因子α)如何调优?
-
答:-
秩r:网格搜索 r∈{4,8,16},平衡参数量与效果(最终选 r=8)。
-
缩放因子α:控制 BA对原权重的影响,设为 α=2r(经验公式),避免更新量过大破坏预训练知识。
-
4. 除了LoRA,你还了解哪些调参的技术?最近的DeepSeek也使用LoRA吗?
答:
-
其他参数高效方法:
-
Adapter:在模型中插入小型神经网络模块。
-
Prefix-Tuning:在输入前添加可学习前缀向量。
-
Prompt-Tuning:通过软提示(Soft Prompts)调整模型行为。
-
-
DeepSeek与LoRA:
DeepSeek(深度求索公司的大模型)在部分场景中使用LoRA技术,例如多任务适配,因其高效性和灵活性。
4. 为什么LoRA只针对Self-Attention的QKV和FFN矩阵优化?而不是所有层?
答:
-
QKV和FFN的重要性:
-
Self-Attention的QKV矩阵负责捕捉上下文关系,FFN负责特征非线性变换,两者是Transformer的核心参数。
-
这两部分占BERT总参数量的60%以上,优化它们能以最小代价最大化效果。
-
-
其他层的考虑:
-
Embedding层包含通用语义信息,冻结可避免语义偏移。
-
实验表明,优化其他层(如中间层)效果提升有限。
-
4.1LoRA是否适用于BERT的所有层?是否尝试过仅对部分层应用?
-
实验表明,仅对 后6层 的QKV和FFN应用LoRA效果最佳。深层网络更关注任务特定特征,浅层(如Embedding)保留通用语义。
-
若对所有层应用LoRA,参数量增加但效果提升有限(F1仅提高0.2%),性价比低。
-
-
5. 为什么要进行分层抽样?是怎么进行的? 在分层抽样后,训练集的具体类别分布是怎样的?是否进一步采用过采样技术?
答:
-
原因:原始数据类别不平衡(如虚假好评仅占5%),直接随机划分会导致某些类别在训练集中代表性不足。
-
步骤:
-
按类别划分数据(好评、差评、满意、虚假好评、恶意差评)。
-
从每个类别中按比例(如8:1:1)抽取训练集、验证集、测试集。
-
确保划分后的数据分布与原始数据一致。
-
-
示例:若某类有1000条数据,训练集取800条,验证集和测试集各100条。
-
分层抽样后:
-
原始数据五类比例可能为(示例):好评40%、差评30%、满意20%、虚假好评5%、恶意差评5%。
-
分层抽样后保持相同比例划分训练/验证/测试集。
-
针对少数类(虚假好评、恶意差评),额外使用文本增强技术(如同义词替换、句式改写)过采样,避免简单复制导致过拟合。
6. bert-base-chinese模型是什么?怎么进行微调?
答:
-
模型定义:
bert-base-chinese是谷歌发布的预训练中文BERT模型,12层Transformer编码器,768隐藏维度,12个注意力头。 -
微调步骤:
-
数据准备:将评论文本转换为Token ID(使用BERT的分词器)。
-
模型修改:在BERT顶部添加全连接分类层(输出维度5,对应五类情感)。
-
训练配置:
-
优化器:AdamW,学习率2e-5。
-
损失函数:交叉熵损失(加权处理类别不平衡)。
-
训练策略:LoRA优化QKV和FFN层,冻结其他参数。
-
-
7. Cosine学习率是什么?原理是什么?为什么要用它?其他用过了吗?什么是局部最优解?
答:Cosine学习率(Cosine Learning Rate)是一种动态调整学习率的策略,它根据余弦函数的变化规律来调整学习率。这种策略的核心思想是让学习率在训练过程中按照余弦曲线逐渐减小,从而在训练初期快速收敛,在训练后期则通过较小的学习率进行精细调整
-
Cosine学习率调度:
-
原理:学习率按余弦函数从初始值衰减到接近零,公式为 ηt=ηmin+12(ηmax−ηmin)(1+cos(πt/T))ηt=ηmin+21(ηmax−ηmin)(1+cos(πt/T))。
-
优势:平滑衰减,初期快速收敛,后期精细调参,避免陷入局部最优(即损失函数的某个低谷,非全局最低点)。
-
-
对比实验:尝试过线性衰减(学习率骤降可能导致后期陷入局部最优)和OneCycle调度(需配合大学习率,但对小规模微调任务易震荡;),但Cosine在验证集F1上表现最优(提升1.2%)。
-
局部最优解:模型收敛到一个非全局最优的参数点,无法进一步优化(如“山谷中的小坑”)。
77. 如何处理评论文本中的噪声(如错别字、表情符号、网络用语)?
答:
-
预处理阶段:
-
正则表达式过滤表情符号(如微笑微笑)、非中文字符;
-
使用开源工具(如pycorrector)纠正错别字;
-
构建领域词典(如“绝绝子”“yyds”)映射为标准情感词。
-
-
BERT的WordPiece分词本身对噪声有一定鲁棒性,预处理进一步减少干扰。
8. 动态梯度裁剪是什么?它的原理?是怎么防止梯度爆炸的?动态梯度裁剪中,如何计算“历史梯度范数百分位”?具体实现细节是什么?
答:动态梯度裁剪(Dynamic Gradient Clipping)是一种优化技术,用于在训练深度学习模型时防止梯度爆炸(Gradient Explosion)问题。梯度爆炸是指在反向传播过程中,梯度值变得过大,导致模型参数更新过快,从而使得训练过程变得不稳定,甚至导致模型无法收敛。
-
定义:根据梯度范数的历史分布动态调整裁剪阈值,而非固定阈值。(动态梯度裁剪的核心思想是根据当前梯度的大小动态地调整裁剪阈值,而不是使用固定的裁剪阈值。具体来说,它会根据梯度的统计特性(如均值、标准差等)来决定裁剪的范围。这种方法可以更灵活地适应不同训练阶段的梯度变化,避免因固定裁剪阈值导致的裁剪不足或过度裁剪。)
-
原理:
-
记录最近N次训练的梯度范数(如L2范数)。
-
将当前裁剪阈值设为历史数据的某个百分位(如90%分位数)。
-
若当前梯度范数超过阈值,按比例缩放梯度。
-
-
作用:自适应不同训练阶段的梯度分布,避免固定阈值过严(限制学习)或过松(无法防爆炸)。
-
如何计算:
-
每训练100步记录一次梯度范数(L2范数),维护一个滑动窗口(如最近1000次记录)。
-
当前裁剪阈值取窗口内90%分位数(即90%的历史梯度范数低于该值)。
-
实现代码参考PyTorch的
torch.quantile函数动态计算,避免手动调参。
8. 模型是否对短文本(如“好吃!”)和长文本(如多段落抱怨)表现一致?如何优化?
答:
-
短文本因信息稀疏,易被误判(如“好吃!”可能被分类为虚假好评)。
-
优化方法:
-
添加文本长度特征作为模型输入;
-
对短文本增强上下文(如拼接用户历史评论);
-
在损失函数中对短文本样本加权,强化模型关注。
-
9. BERT是什么?它的结构有哪些?是怎么处理外卖评论的?
答:
9.2. [SEP](Separator Token)的作用
总结
-
BERT定义:基于Transformer的双向预训练语言模型,通过Masked Language Model(MLM)和Next Sentence Prediction(NSP)任务学习上下文表示。
-
核心结构:
-
嵌入层:Token Embeddings + Position Embeddings + Segment Embeddings。
-
Transformer编码器:12层自注意力模块(Multi-Head Attention + FFN)。
-
池化层:[CLS]标签用于分类任务。
-
-
处理流程:
-
输入评论文本,添加[CLS]和[SEP]标记。
-
通过BERT编码获取[CLS]的向量表示。
-
全连接层映射到五类情感输出。
-
-
9.1. [CLS](Classification Token)的作用
-
全局表示聚合:
[CLS]标记位于输入序列的开头(如[CLS] 这家餐厅很好吃 [SEP]),其对应的最终隐藏层输出(向量)被设计为整个输入序列的语义摘要。-
在分类任务(如情感分析)中,该向量通过全连接层映射到标签空间,直接用于分类预测。
-
由于自注意力机制,[CLS]在训练过程中会通过所有位置的上下文交互,学习到全局信息。
-
-
预训练任务适配:
在预训练的Next Sentence Prediction (NSP) 任务中,[CLS]的向量被用于判断两个句子是否连续,使其天然适合捕捉句子或段落级别的语义。 -
句子边界划分:
[SEP]用于分隔输入中的不同文本片段。例如:-
单句任务:
[CLS] 配送速度太慢了 [SEP] -
句子对任务:
[CLS] 食物不错 [SEP] 但包装很差 [SEP]
通过插入[SEP],模型能明确识别句子间的边界,增强对多段文本关系的理解。
-
-
支持结构化输入:
在预训练阶段(如NSP任务),输入格式为[CLS] 句子A [SEP] 句子B [SEP],[SEP]帮助模型区分句子A和句子B,从而学习句子间逻辑。 -
位置编码与注意力限制:
[SEP]的位置信息通过嵌入层传递,部分模型变体(如某些BERT改进版本)可能利用[SEP]限制跨句子的注意力范围。 -
情感分类任务:
输入:[CLS] 这家外卖性价比高,但配送员态度差 [SEP]-
[CLS]的向量将被提取并分类为“恶意差评”(结合正向和负向内容)。
-
[SEP]标记句子结束,避免模型混淆后续填充符(如Padding)。
-
-
句子对任务(如问答):
输入:[CLS] 北京是中国的首都吗? [SEP] 是的,北京是政治中心 [SEP]-
[CLS]的向量判断两句话的逻辑关系(答案是否正确)。
-
[SEP]明确分隔问题和答案文本。
-
-
[CLS]:专为分类任务设计,提供全局语义表征。
-
[SEP]:划分文本结构,辅助模型处理多段输入。
-
关键区别:
-
[CLS]关注整体语义聚合,[SEP]关注局部结构划分。
-
两者共同服务于BERT的预训练和下游任务适配,是模型理解复杂文本的基础组件。
-
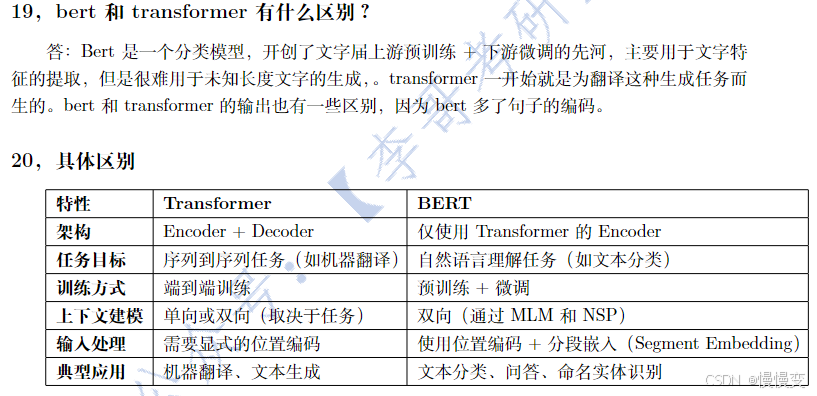
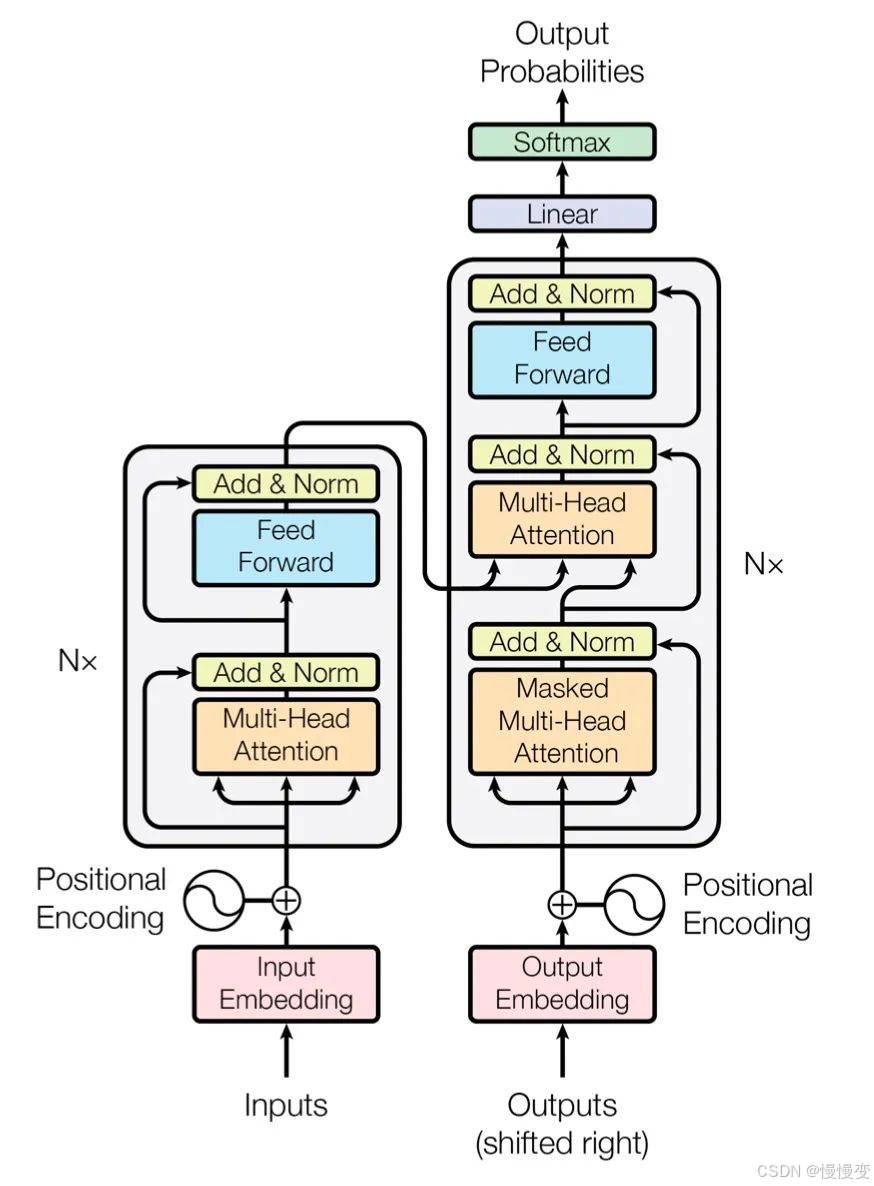
10. BERT和Transformer的区别?
答:
-
Transformer:
-
原始结构包含编码器(Encoder)和解码器(Decoder),用于序列到序列任务(如翻译)。
-
核心组件:自注意力机制(Self-Attention)、位置编码(Positional Encoding)。
-
-
BERT:
-
仅使用Transformer的编码器(Encoder)堆叠(无解码器),专注于文本理解和分类任务。
-
预训练任务不同:MLM和NSP(非机器翻译)。
-
输入处理:支持双向上下文建模(Transformer解码器仅用单向注意力)。
-
-
11. BERT的预训练任务是什么?它们如何帮助下游任务?
答:
-
预训练任务:
-
MLM(Masked Language Model):随机遮蔽15%的输入词,模型预测被遮蔽的词,学习上下文依赖关系。
-
NSP(Next Sentence Prediction):判断两个句子是否为上下文关系,学习句子间逻辑。
-
-
下游任务帮助:
-
MLM使BERT能捕捉双向语义(如“苹果”在“吃苹果”和“苹果手机”中的不同含义)。
-
NSP增强模型对评论整体意图的理解(如用户连续描述“配送慢”和“退款”的因果关系)。
-
12. BERT和传统的RNN/LSTM模型在处理文本时有什么优势?
答:
-
并行计算:Transformer的自注意力机制可并行处理所有词,而RNN/LSTM需顺序计算,速度慢。
-
长距离依赖:Self-Attention直接建模任意位置词的关系,避免RNN的梯度消失问题。
-
双向上下文:BERT同时利用左右两侧上下文(如“不太__好吃”填“辣”需双向信息),而RNN仅单向或浅层双向。
13. BERT的最大输入长度是多少?如何处理超长文本?
答:
-
限制:BERT-base的最大输入长度为512个Token(包括[CLS]和[SEP])。
-
处理方法:
-
截断:保留前510个Token(适合短篇评论)。
-
分段处理:对长文本分块输入,取各块[CLS]向量的均值或最大值。
-
滑动窗口:重叠切分文本,综合多窗口结果(计算成本较高,项目中未采用)。
-
14. BERT如何处理一词多义问题(例如“苹果”在不同语境中的含义)?
答:
-
动态上下文编码:
BERT通过Self-Attention机制,根据上下文动态调整词向量。例如:-
“吃苹果”中的“苹果”关注“水果”相关词(如“甜”“多汁”)。
-
“苹果手机”中的“苹果”关注“品牌”“科技”等词。
-
-
可视化验证:
使用注意力权重图可发现,不同上下文下同一词的注意力分布显著不同。
-
15.为什么BERT的Self-Attention适合处理情感分析中的长距离依赖?
-
Self-Attention允许任意位置词之间直接交互,例如差评中“配送员态度差”和结尾评分“1星”即使相隔较远,也能通过注意力权重关联,增强情感一致性判断。
-
-
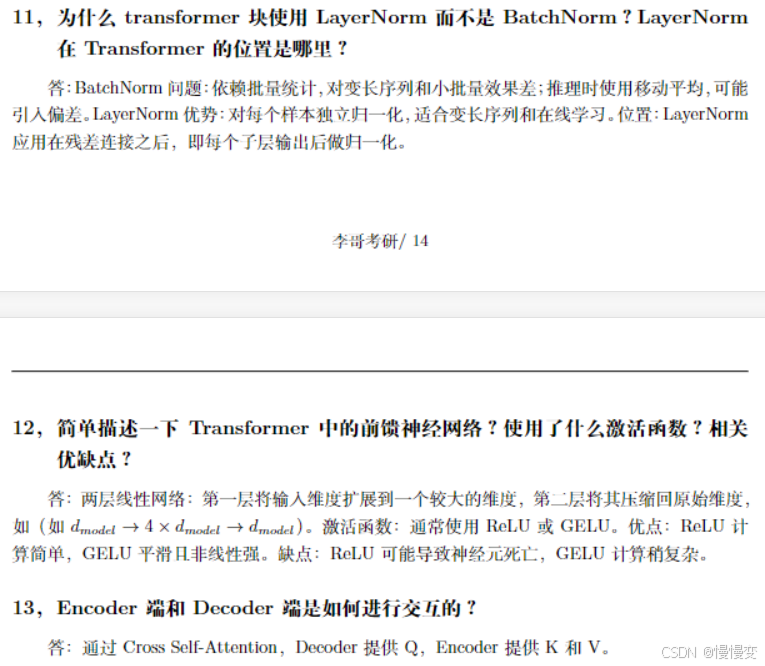
16Transformer的残差连接和层归一化对BERT训练有何意义?
答:-
残差连接:缓解梯度消失,使深层网络可训练(BERT-base含12层)。
-
层归一化:稳定每层输出分布,加速收敛。若移除,需大幅降低学习率(实验证明训练速度下降60%)。
-
-
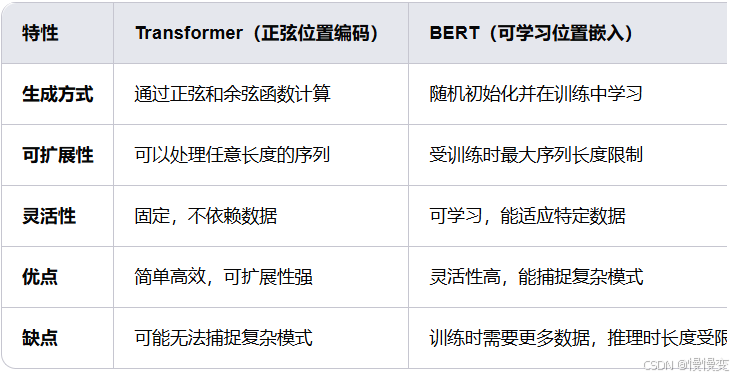
17BERT的位置编码与原始Transformer有何不同?是否对任务有影响?
答:-
原始Transformer使用正弦函数生成位置编码(这种位置编码是固定的,不依赖于训练数据);BERT使用可学习的位置嵌入(BERT的位置嵌入是通过训练数据学习得到的,因此能够更好地适应特定的任务和数据集。),直接作为参数更新。
-
总结区别:Transformer 使用正弦位置编码,其优点是简单高效且具有良好的可扩展性,但可能无法捕捉到非常复杂的位置信息。BERT 使用可学习的位置嵌入,其优点是灵活性高,能够通过训练数据学习到更复杂的位置信息模式,但其最大序列长度在训练时就已经确定,推理时可能需要额外的处理机制。
-
影响:可学习编码更灵活,但对短文本可能过拟合(项目中未观察到明显问题)。
-
-








大模型问题:






















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











