







题目:初识pandas库与缺失数据的补全
按照示例代码的要求,去尝试补全信贷数据集中的数值型缺失值
- 打开数据(csv文件、excel文件)
- 查看数据(尺寸信息、查看列名等方法)
- 查看空值
- 众数、中位数填补空值
- 利用循环补全所有列的空值
完成后在py文件中独立完成一遍,并且利用debugger工具来查看属性(不借助函数显式查看)----养成利用debugger工具的习惯
# 读取数据
import pandas as pd
data = pd.read_csv(r'day04_data.csv')type(data) # 类pandas.core.frame.DataFrame
方法 :人.跳舞()
属性: 人.年龄
data.isnull() # 布尔矩阵显示缺失值,这个方法返回一个布尔矩阵,也是dataframe对象,其中True表示对应位置的值是缺失值,False表示对应位置的值不是缺失值。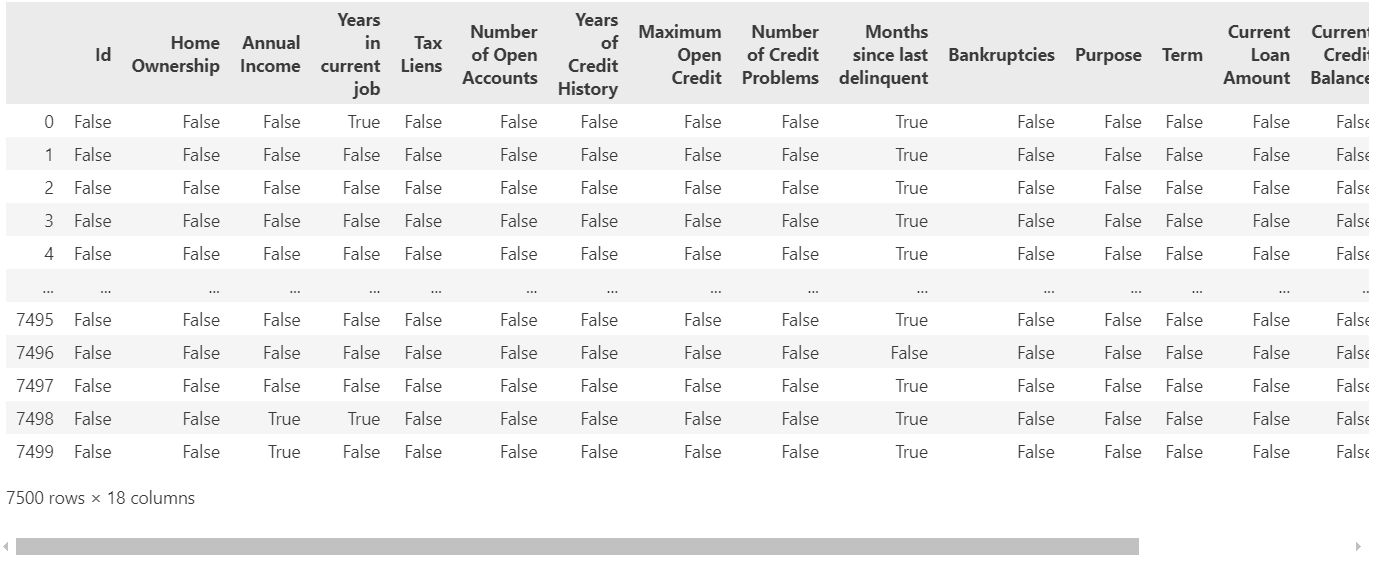
data.head(10)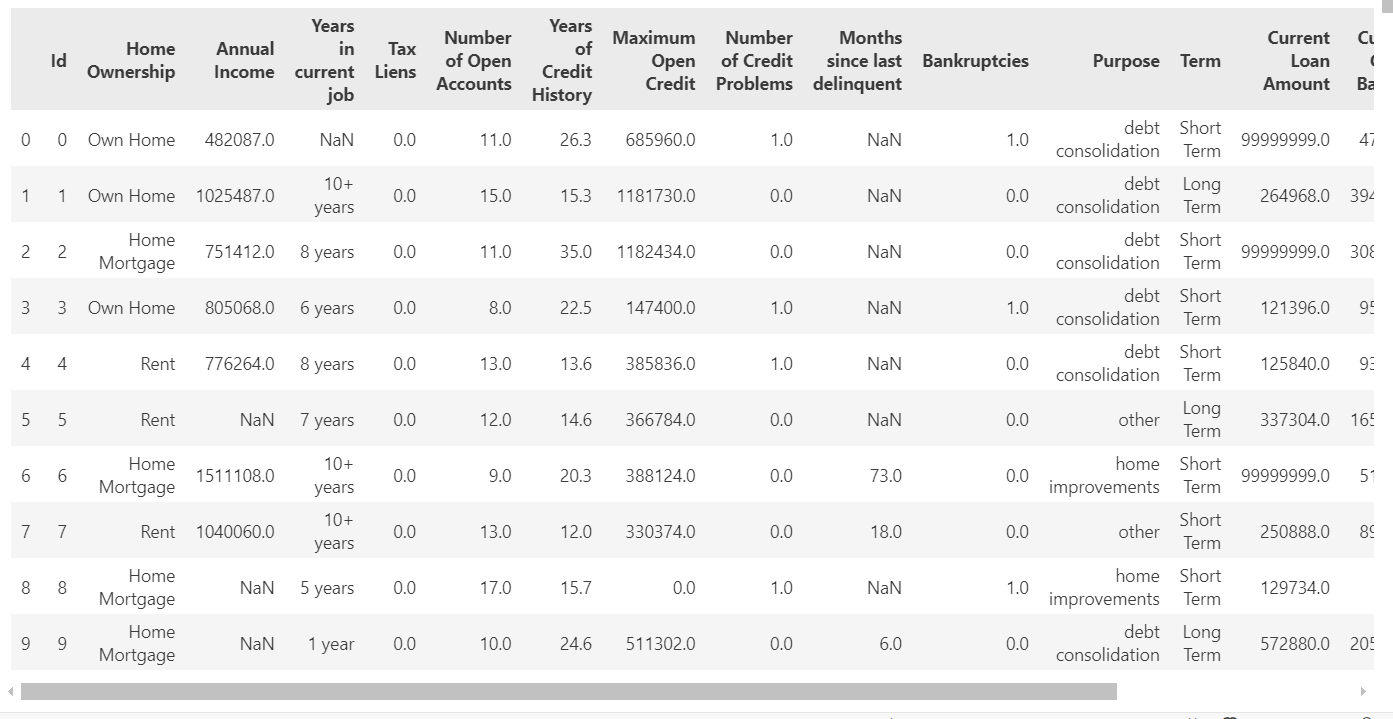
# pip install openpyxl
# pandas读取excel需要安装openpyxl库,去anaconda prompt中安装
data2 =pd.read_excel('day04_data.xlsx')
data2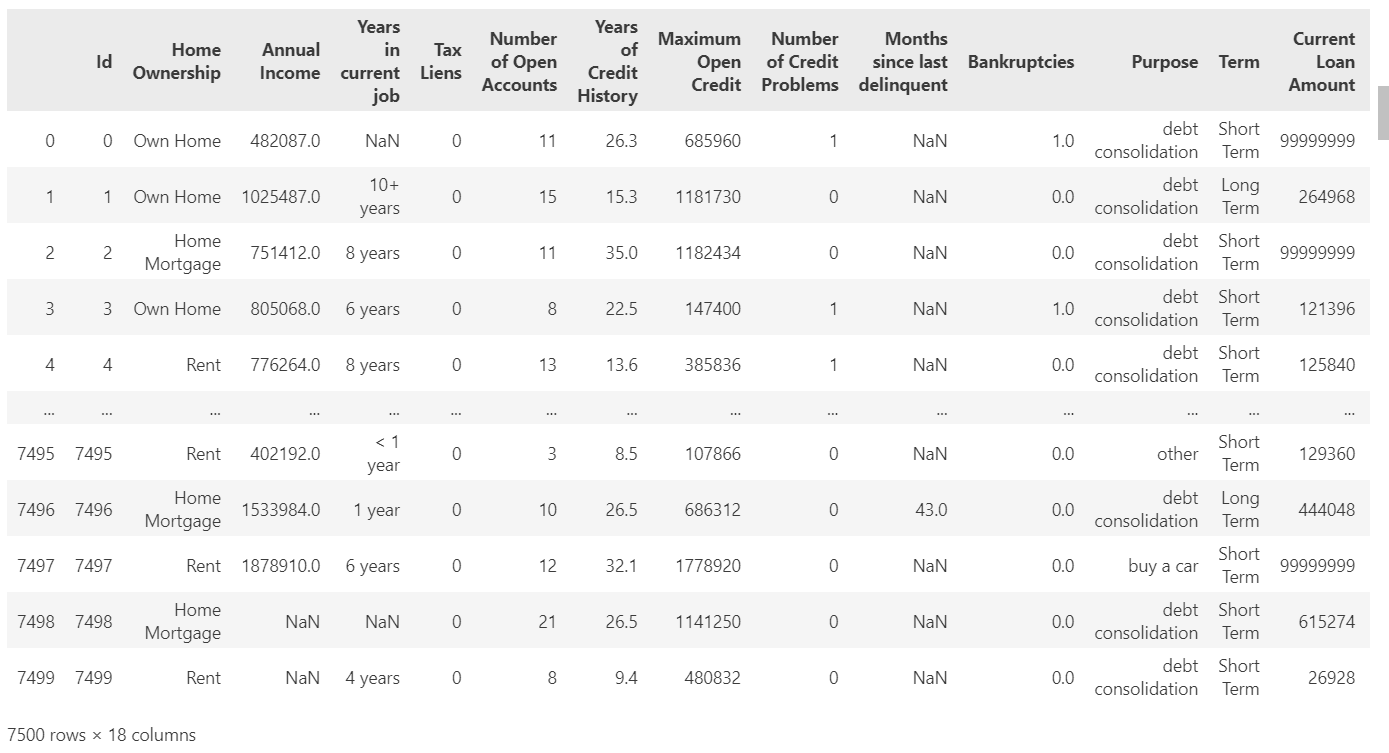
data.head(10)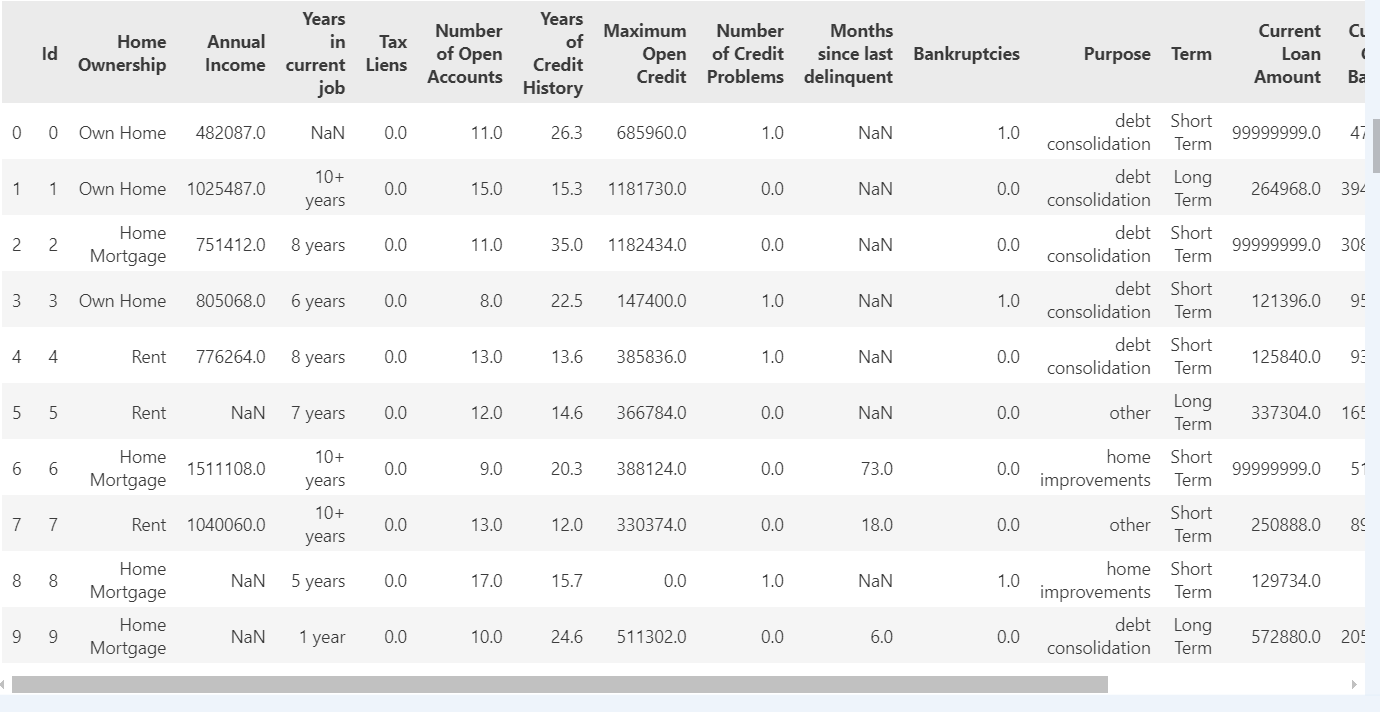
数据信息的查看
此时data是一个dataframe类型的对象,可以理解为dataframe类的实例。实例就具有类的属性和方法。
属性的调用格式为:实例名.属性名。
方法的调用格式为:实例名.方法名()。
data.info() # 列名、非空值、数据类型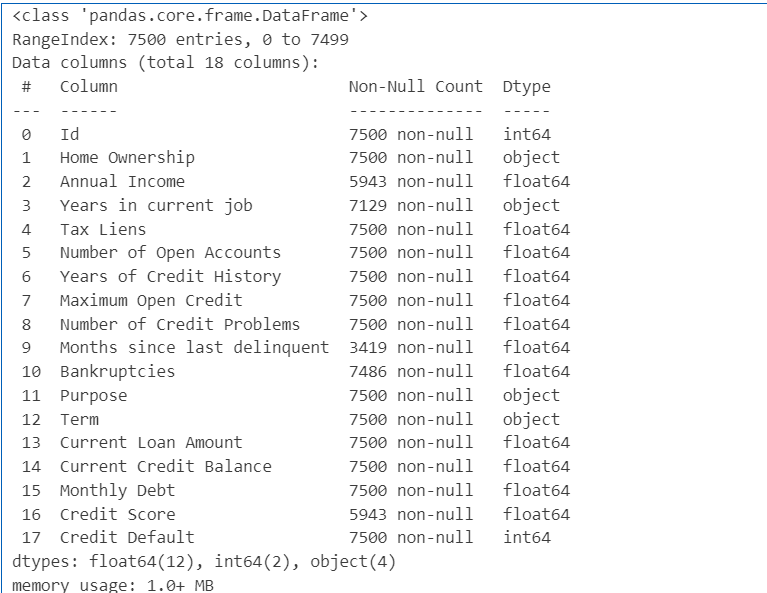
data.shape # (行数, 列数) data的属性(7500, 18)
data.columns # 所有列名 data的属性Index(['Id', 'Home Ownership', 'Annual Income', 'Years in current job',
'Tax Liens', 'Number of Open Accounts', 'Years of Credit History',
'Maximum Open Credit', 'Number of Credit Problems',
'Months since last delinquent', 'Bankruptcies', 'Purpose', 'Term',
'Current Loan Amount', 'Current Credit Balance', 'Monthly Debt',
'Credit Score', 'Credit Default'],
dtype='object')
data.describe() # 数值列的基本统计量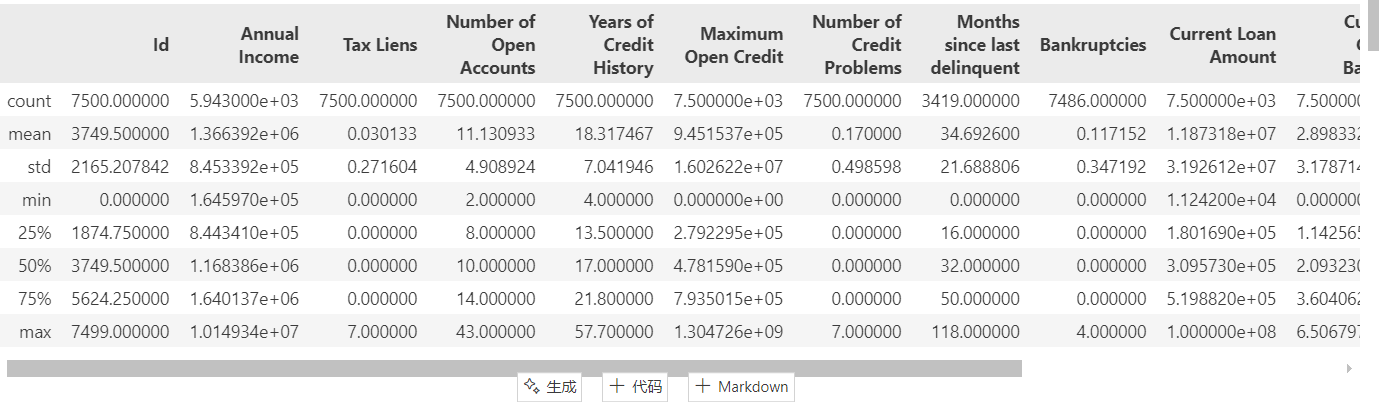
# dtype 是 data type 的缩写,用于描述数据类型。后续会频繁借助这个方法来查看某一列数据的属性
data.dtypes # 各列数据类型
data.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 7500 entries, 0 to 7499
Data columns (total 18 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Id 7500 non-null int64
1 Home Ownership 7500 non-null object
2 Annual Income 5943 non-null float64
3 Years in current job 7129 non-null object
4 Tax Liens 7500 non-null float64
5 Number of Open Accounts 7500 non-null float64
6 Years of Credit History 7500 non-null float64
7 Maximum Open Credit 7500 non-null float64
8 Number of Credit Problems 7500 non-null float64
9 Months since last delinquent 3419 non-null float64
10 Bankruptcies 7486 non-null float64
11 Purpose 7500 non-null object
12 Term 7500 non-null object
13 Current Loan Amount 7500 non-null float64
14 Current Credit Balance 7500 non-null float64
15 Monthly Debt 7500 non-null float64
16 Credit Score 5943 non-null float64
17 Credit Default 7500 non-null int64
dtypes: float64(12), int64(2), object(4)
memory usage: 1.0+ MB
data["Annual Income"].dtype # 查看某一列的数据类型dtype('float64')
data.isnull() # 布尔矩阵显示缺失值,这个方法返回一个布尔矩阵,也是dataframe对象,其中True表示对应位置的值是缺失值,False表示对应位置的值不是缺失值。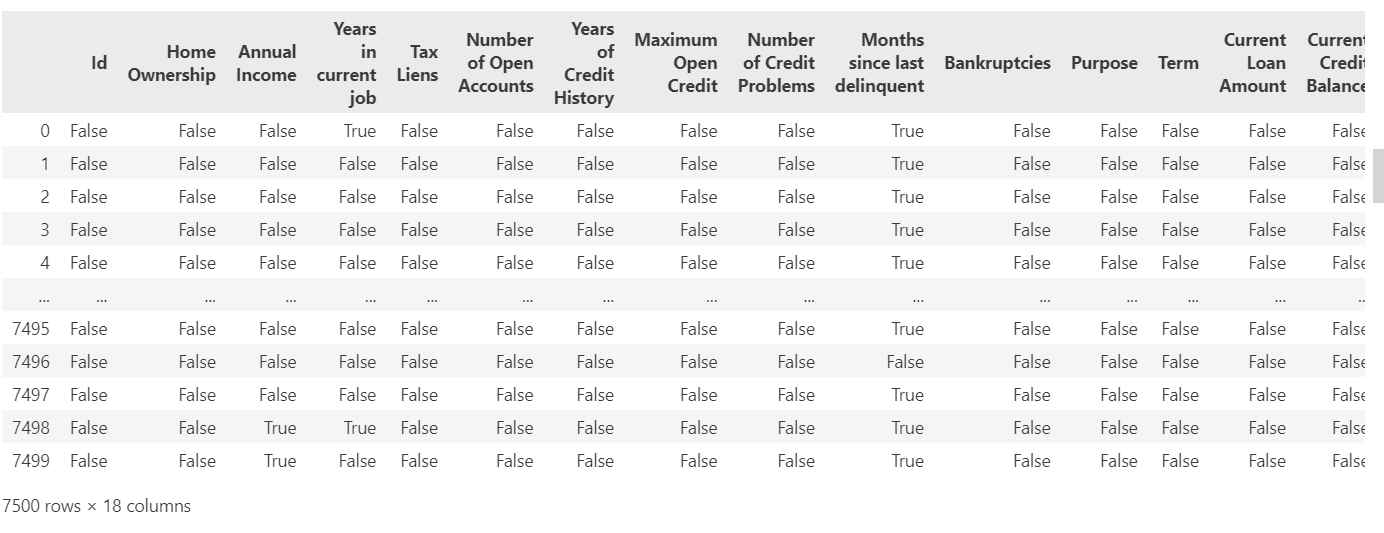
type(data.isnull()) # 布尔矩阵显示缺失值,这个方法返回一个布尔矩阵,其中True表示对应位置的值是缺失值,False表示对应位置的值不是缺失值。pandas.core.frame.DataFrame
data.isnull().sum() # 每列缺失值计数,sum方法为求每一列的和Id 0
Home Ownership 0
Annual Income 1557
Years in current job 371
Tax Liens 0
Number of Open Accounts 0
Years of Credit History 0
Maximum Open Credit 0
Number of Credit Problems 0
Months since last delinquent 4081
Bankruptcies 14
Purpose 0
Term 0
Current Loan Amount 0
Current Credit Balance 0
Monthly Debt 0
Credit Score 1557
Credit Default 0
dtype: int64
缺失值的填补
尝试用众数 中位数进行填补
data['Annual Income']0 482087.0
1 1025487.0
2 751412.0
3 805068.0
4 776264.0
...
7495 402192.0
7496 1533984.0
7497 1878910.0
7498 NaN
7499 NaN
Name: Annual Income, Length: 7500, dtype: float64
type(data['Annual Income'])
# dataframe里单独的一列是seriespandas.core.series.Series
# 计算 'Annual Income' 列的中位数(会自动忽略 NaN 值)
median_income = data['Annual Income'].median()
median_income1168386.0
# 使用计算出的中位数填补该列的 NaN 值
# inplace=True 参数表示直接在原 DataFrame 上进行修改
# 如果不设置该参数,fillna() 方法会返回一个新的 DataFrame,原 DataFrame 不会被修改
data['Annual Income'].fillna(median_income, inplace=True)# 检查下是否有缺失值
data['Annual Income'].isnull().sum()0
# 使用众数填充缺失值
import pandas as pd
data = pd.read_csv('day04_data.csv') #需要重新读取一遍数据
mode = data['Annual Income'].mode()
# mode() 会返回数据中出现频率最高的所有值,如果频次相同,会返回最多每个值。
mode0 969475.0
1 1043651.0
2 1058376.0
3 1161660.0
4 1338113.0
Name: Annual Income, dtype: float64
# 这里返回了4个最多频次的值,我们一般保留第一个
mode = mode[0]# 众数填补
data['Annual Income'].fillna(mode, inplace=True)
# 检查下是否有缺失值
data['Annual Income'].isnull().sum()填补所有的数值型缺失值
从上面的打印信息可以看到,缺失值的数值列包括:Annual Income、Months since last delinquent、Bankruptcies、Credit Score。这些列的缺失值数量分别为1557、4081、14和1557。
data.columnsIndex(['Id', 'Home Ownership', 'Annual Income', 'Years in current job',
'Tax Liens', 'Number of Open Accounts', 'Years of Credit History',
'Maximum Open Credit', 'Number of Credit Problems',
'Months since last delinquent', 'Bankruptcies', 'Purpose', 'Term',
'Current Loan Amount', 'Current Credit Balance', 'Monthly Debt',
'Credit Score', 'Credit Default'],
dtype='object')
type(data.columns)pandas.core.indexes.base.Index
很自然的 我们想要遍历打印这个对象中的每一个元素,如果是数值,就补全缺失值
# 介绍一下tolist方法,将numpy数组和pandas对象转换成list
import numpy as np
a =np.array([1,2,3])
a.tolist()[1, 2, 3]
c = data.columns.tolist()
type(c)list
# 循环遍历c这个列表中的每一列
for i in c:
# 找到为数值型的列
if data[i].dtype != 'object': # 找到为数值型的列
if data[i].isnull().sum() > 0: # 找到存在缺失值的列
#计算该列的均值
mean_value = data[i].mean()
#用均值填充缺失值
data[i].fillna(mean_value, inplace=True)
data.isnull().sum()Id 0
Home Ownership 0
Annual Income 0
Years in current job 371
Tax Liens 0
Number of Open Accounts 0
Years of Credit History 0
Maximum Open Credit 0
Number of Credit Problems 0
Months since last delinquent 0
Bankruptcies 0
Purpose 0
Term 0
Current Loan Amount 0
Current Credit Balance 0
Monthly Debt 0
Credit Score 0
Credit Default 0
dtype: int64
代码实现

















 438
438

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









