







1:需求描述
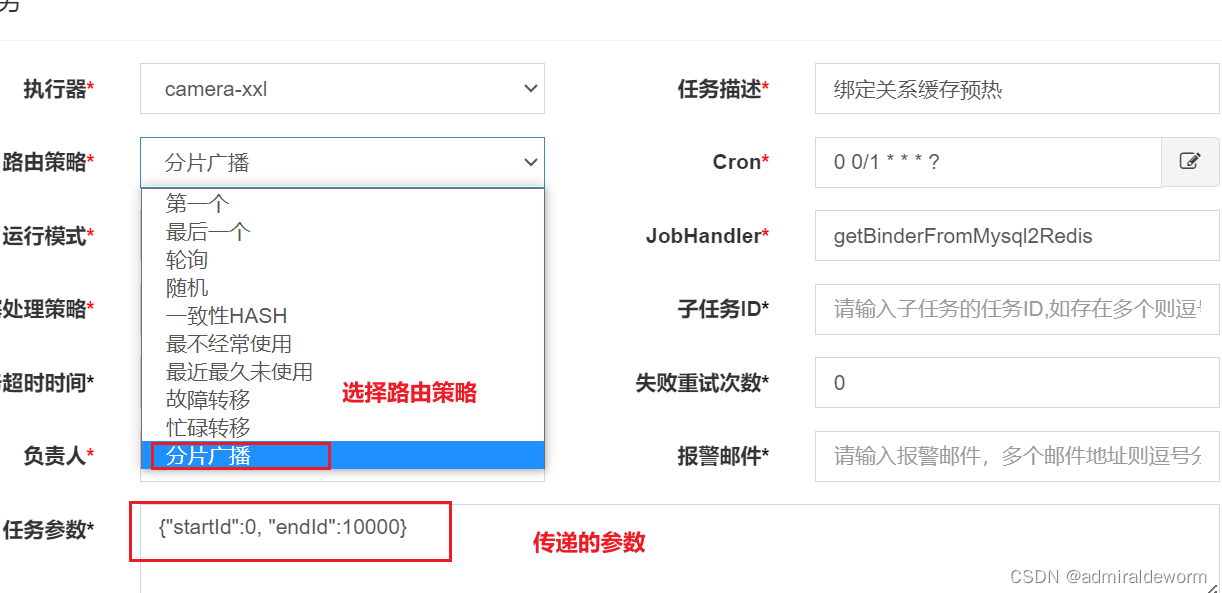
开发redis新集群定时任务缓存预加载功能:目前表中现存的需要缓存的信息有两千五百多万条,需要新开一个定时任务,将这两千多万条的信息,写入redis缓存中,实现缓存的预热,线上redis集群,考虑到性能任务路由策略选择”分片广播”
2:需求分析
采用分片广播模式的优势:xxl-job调度中心只要发出一次调度,所有的相关节点会全部执行一次,既只要在代码逻辑中编写好分片策略,就可以让2千五百万的数据,均匀分配到所有节点,每个节点只需要执行所分配到的数据即可;相比常用的轮询策略,效率提升,轮询调度只会调度某一台节点,就是说这2千万条数据会全部由一台节点执行,效率无法达标。
总结:
分片广播 以执行器为维度进行分片,支持动态扩容执行器集群从而动态增加分片数量,协同进行业务处理;在进行大数据量业务操作时可显著提升任务处理能力和速度。
3:开发分片任务
执行器集群部署时,任务路由策略选择”分片广播”情况下,一次任务调度将会广播触发对应集群中所有执行器执行一次任务,同时系统自动传递分片参数;可根据分片参数开发分片任务;
取分片参数方式:
int shardIndex = XxlJobHelper.getShardIndex();
int shardTotal = XxlJobHelper.getShardTotal();分片参数属性说明:
index:当前分片序号(从0开始),执行器集群列表中当前执行器的序号;
total:总分片数,执行器集群的总机器数量;
4:代码实现
以下隐私代码以用***代替
@Component
@Slf4j
public class BinderPreloadJob {
@Autowired
private UserCameraDaoMybatis userCameraDaoMybatis;
@Autowired
private LittlecConfig littlecConfig;
public static final String DEVICE_BIND = "device.bind.";
//redis 过期时间,30天
public static final Integer EXPIRED_SECONDS = 30 * 24 * 3600;
@XxlJob("getBinderFromMysql2Redis")
public ReturnT<String> getBinderFromMysql2Redis(String param) {
//相当于XxlJobHelper
ShardingUtil.ShardingVO shardingVO = ShardingUtil.getShardingVo();
//获取到当前节点的index和总节点数
int current = shardingVO.getIndex();
int total = shardingVO.getTotal();
XxlJobLogger.log("当前节点的index = {}, 总结点数 = {}, param={}", current, total, param);
//执行工作
executeJob(param, current, total);
return ReturnT.SUCCESS;
}
public void executeJob(String param, int current, int total) {
log.info("getBinderFromMysql2Redis begin execute! currentShard={}, totalShard={}, param={}", current, total, param);
//GetBinder2RedisParamDto实体类里只有startId和endId,获取到xxl-job传来的startId和和endId参数
GetBinder2RedisParamDto paramDto = JSON.parseObject(param, GetBinder2RedisParamDto.class);
//分片策略,返回分片范围
Pair<Integer, Integer> totalRange = calculateRange(paramDto.getStartId(), paramDto.getEndId(), current, total);
log.info("the range in current shard is:{}, current={}, total={}", totalRange, current, total);
//执行分片逻辑
shardingExecute(totalRange.getLeft(), totalRange.getRight());
log.info("getBinderFromMysql2Redis success");
}
/**
* 分片策略,先[end-start]/total=step和余数,然后每个分片计算当前分片区间数据为:[current*step, (current+1)*step],
* 最后一个分片,需要额外加上余数部分数据,不考虑临界点的重复
* 每个分片内部,再按照10000一次进行查询比较即可。
*
* @param startId
* @param endId
* @param current
* @param total
* @return
*/
private static Pair<Integer, Integer> calculateRange(Integer startId, Integer endId, int current, int total) {
Integer step = (endId - startId) / total;
Integer remainder = (endId - startId) % total;
Integer start = startId + step * current;
Integer end = startId + step * (current + 1);
// 考虑余数
if (current == total - 1) {
end += remainder;
}
return Pair.of(start, end);
}
public void shardingExecute(int startId, int endId) {
try {
int temp = startId;
int max = endId;
int size = 10000;
while (temp <= max) {
int start = temp;
if (temp + size > max) {
break;
}
int end = start + size;
//执行主要缓存逻辑
getBinderUser2Redis(start, end);
temp += size;
}
// 最后一次循环中断情况
if (temp < max) {
// //执行主要缓存逻辑
getBinderUser2Redis(temp, max);
}
} catch (Exception e) {
log.error("shardingExecute error, startId={}, endId={}", startId, endId, e);
}
}
private void getBinderUser2Redis(int start, int end) {
//boss配置redis的过期时间,30天
int expired = littlecConfig.getConfigAsInt("***", EXPIRED_SECONDS);
//查询每次缓存的数据集合
List<UserCameraDto> userCameraDtoList = userCameraDaoMybatis.getBinderUser(start, end);
log.info("In getBinderFromMysql2Redis: userCameraDtoList size {}, id range: [{}, {}]", userCameraDtoList.size(), start, end);
//循环没条数据进行缓存预热
if (userCameraDtoList.size() > 0) {
for (UserCameraDto dto : userCameraDtoList) {
String cacheBindKey = ***;
String binder = ***;
//redis的key,value,过期时间
RedisManager.getRedisManager("redis.alarm.config").setEx(cacheBindKey, expired, binder);
log.info("getBinderFromMysql2Redis write redis success, macId={}, binder={}", dto.getMacId(), binder);
}
}
}sql:
SELECT uc.id AS id,
uc.mac_id AS macId,
uc.user_id_enc AS userId
FROM t_user_camera uc
WHERE uc.id between #{startId} and #{endId}
and uc.bind_state = 1
and uc.shared = 0注意:最开始使用startId和limit进行逻辑编写,但是跑sql的时候,跑了六秒多(limit是先查出所有再去截取),优化成startId和endId,用between进行
5:xxl-job调度中心配置















 6885
6885











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











