






镜像选择
docker pull prom/prometheus:v2.37.6
docker pull prom/node-exporter
docker pull prom/alertmanager:v0.23.0
docker pull grafana/grafana:7.0.4prometheus
prometheus配置文件
vim /data/prometheus/prometheus.yml
# my global config
global:
scrape_interval: 15s #每15s采集一次数据
evaluation_interval: 15s # 每15s做一次告警检测
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs: #静态配置
- targets: #获取目标
- alertmanager:9093 #alertmanager的ip端口
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - rule文件的位置
- /data/prometheus/rules.yml
#指定prometheus要监控的目标
scrape_configs:
#作业名称将作为标签`job=<job_name>`添加到从此配置中抓取的任何时间序列中。
- job_name: "135"
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
#静态配置,向谁获取node exports
static_configs:
- targets: ["localhost:9090"]
labels: #为不同的机器定义标签
service: 135
from: Fujian_XiarMen
- job_name: "136"
static_configs:
- targets: [ #监控多个主机的写法
"192.168.211.136:9100",
"192.168.211.137:9100"
]
labels:
service: 136
from: Fujian_ZhangZhou
#通过基于文件的服务发现方式下,Prometheus会定时从文件中读取最新的Target信息,因此,你可以通过任意的方式将监控Target的信息写入即可
- job_name: 'file_sd_test'
scrape_interval: 10s #每10s采集一次数据,覆盖global的配置
file_sd_configs:
- refresh_interval: 30s # 30s重载配置文件,默认5m
files:
- /data/prometheus/static_conf/*.yml
- /data/prometheus/static_conf/*.json
基于文件的服务自动发现
将需要添加的服务器写入该文件,prometheus会按规定的时间去读取文件的内容并对其进行监控
vim /data/prometheus/static_conf/*.yml
- targets: ['192.168.1.220:9100']
labels:
app: 'app1'
env: 'game1'
region: 'us-west-2'
- targets: ['192.168.1.221:9100']
labels:
app: 'app2'
env: 'game2'
region: 'ap-southeast-1'rule告警匹配规则
vim /data/prometheus/rules.yml
groups:
- name: example #组名称
rules: #告警规则
# Alert for any instance that is unreachable for >5 minutes.
- alert: InstanceDown #告警规则名称
expr: up == 0 #查询语句,达成条件
for: 10m #评估时间,可选参数
labels: #标签
severity: page
alert: node
annotations: #描述
summary: "Instance {{ $labels.instance }} down" #简述
description: "{{ $labels.instance }} of job {{ $labels.job }} has been down for more than 10 minutes." #详细信息alertmanager
alertmanager配置文件
vim /data/prometheus/alertmanager.yml
global:
# 经过此时间后,如果尚未更新告警,则将告警声明为已恢复。(即prometheus没有向alertmanager发送告警了)
resolve_timeout: 5m
# 配置发送邮件信息
smtp_smarthost: 'smtp.163.com:465'
smtp_from: 'lhj18054979020@163.com'
smtp_auth_username: 'lhj18054979020@163.com'
smtp_auth_password: '' #邮箱授权码
smtp_require_tls: false
# 读取告警通知模板的目录。
templates:
- '/etc/alertmanager/*.tmpl'
# 所有报警都会进入到这个根路由下,可以根据根路由下的子路由设置报警分发策略
route:
group_by: ['alertname', 'service']
group_wait: 5m #组告警等待时间。在等待时间结束后,如果有同组告警一起发出
group_interval: 5m #两组告警间隔时间。
repeat_interval: 3h #重复告警间隔时间,减少相同邮件的发送频率。
# 指定默认的接收器
receiver: 135-mails
# 下面配置的是子路由,子路由的属性继承于根路由(即上面的配置),在子路由中可以覆盖根路由的配置
# 下面是子路由的配置
routes:
# 使用正则匹配告警标签 match_ce
# 使用完全匹配告警标签
- match:
# 这里可以匹配出标签含有service=136的告警
service: 136
# 指定接收器为136-mails
receiver: 136-mails
- match:
service: 135
receiver: 135-mails
# 下面是关于inhibit(抑制)的配置,先说一下抑制是什么:抑制规则允许在另一个警报正在触发的情况下使一组告警静音。其实可以理解为告警依赖。比如一台数据库服务器掉电了,会导致db监控告警、网络告警等等,可以配置抑制规则如果服务器本身down了,那么其他的报警就不会被发送出来。
inhibit_rules:
#下面配置的含义:当有多条告警在告警组里时,并且他们的标签alertname,cluster,service都相等,如果severity: 'critical'的告警产生了,那么就会抑制severity: 'warning'的告警。
- source_match: # 源告警(我理解是根据这个报警来抑制target_match中匹配的告警)
severity: 'critical' # 标签匹配满足severity=critical的告警作为源告警
target_match: # 目标告警(被抑制的告警)
severity: 'warning' # 告警必须满足标签匹配severity=warning才会被抑制。
equal: ['alertname', 'service'] # 必须在源告警和目标告警中具有相等值的标签才能使抑制生效。(即源告警和目标告警中这三个标签的值相等'alertname', 'cluster', 'service')
# 下面配置的是接收器
receivers:
# 接收器的名称、通过邮件的方式发送、
- name: '136-mails'
email_configs:
# 发送给哪些人
- to: 'lhj18054979020@163.com'
# 是否通知已解决的警报
send_resolved: true
# 接收器的名称、通过邮件的方式发送、发送给哪些人
- name: '135-mails'
email_configs:
- to: 'lhj18054979020@163.com'alertmanager告警模板
vim /data/prometheus/test.tmpl
{{ define "email.default.html" }}
{{ range .Alerts }}
告警实例: {{ .Labels.instance }} <br>
告警状态:{{ .Status }} <br>
告警级别: {{ .Labels.severity }} 级 <br>
告警类型: {{ .Labels.alertname }} <br>
触发阀值:{{ .Annotations.value }} <br>
告警详情: {{ .Annotations.description }} <br>
告警时间:{{ .StartsAt.Format "2006-01-02 15:04:05" }} <br>
{{ end }}{{ end }}运行prometheus
!!!需要将数据持久化的目录授予777权限,否则启动失败!!!
docker run -itd -p 9090:9090 --name prometheus --restart=always \
-v /data/prometheus/data:/prometheus/data \
-v /data/prometheus/prometheus.yml:/data/prometheus/prometheus.yml \
-v /data/prometheus/rules.yml:/data/prometheus/rules.yml \
prom/prometheus --config.file=/data/prometheus/prometheus.yml \
--web.enable-lifecycle --storage.tsdb.retention=90d
# --net="host" 网络模式,host网络互通模式
# --web.enable-lifecycle 热更新
数据持久化目录chown 777 /data/prometheus/data运行alertmanager
docker run -itd -p 9093:9093 --name alertmanager \
-v /data/prometheus/alertmanager.yml:/etc/alertmanager/alertmanager.yml \
-v /data/prometheus/test.tmpl:/etc/alertmanager/test.tmpl \
prom/alertmanager
# -d --detach=false, 指定容器运行于前台还是后台,默认为false
# --net 网络模式,host网络互通模式
# --restart=always 还可以设置自动重启容器运行node exports
docker run -itd --name node-exporter -p 9100:9100 prom/node-exporter运行grafana
!!!需要将数据持久化的目录授予777权限,否则启动失败!!!
docker run --restart=always \
-d --name grafana -p 3000:3000 \
-v "/home/grafana/grafana.ini:/etc/grafana/grafana.ini" \
-v "/home/grafana/data:/var/lib/grafana" \
grafana/grafana:7.0.4
数据持久化目录/home/grafana/data
配置文件映射 /home/grafana.ini配置grafana数据源及dashboard
访问grafana 浏览器访问: http://ip:3000,用户名admin,密码admin,首次登录需要改密码
选择数据源,框内输入prometheus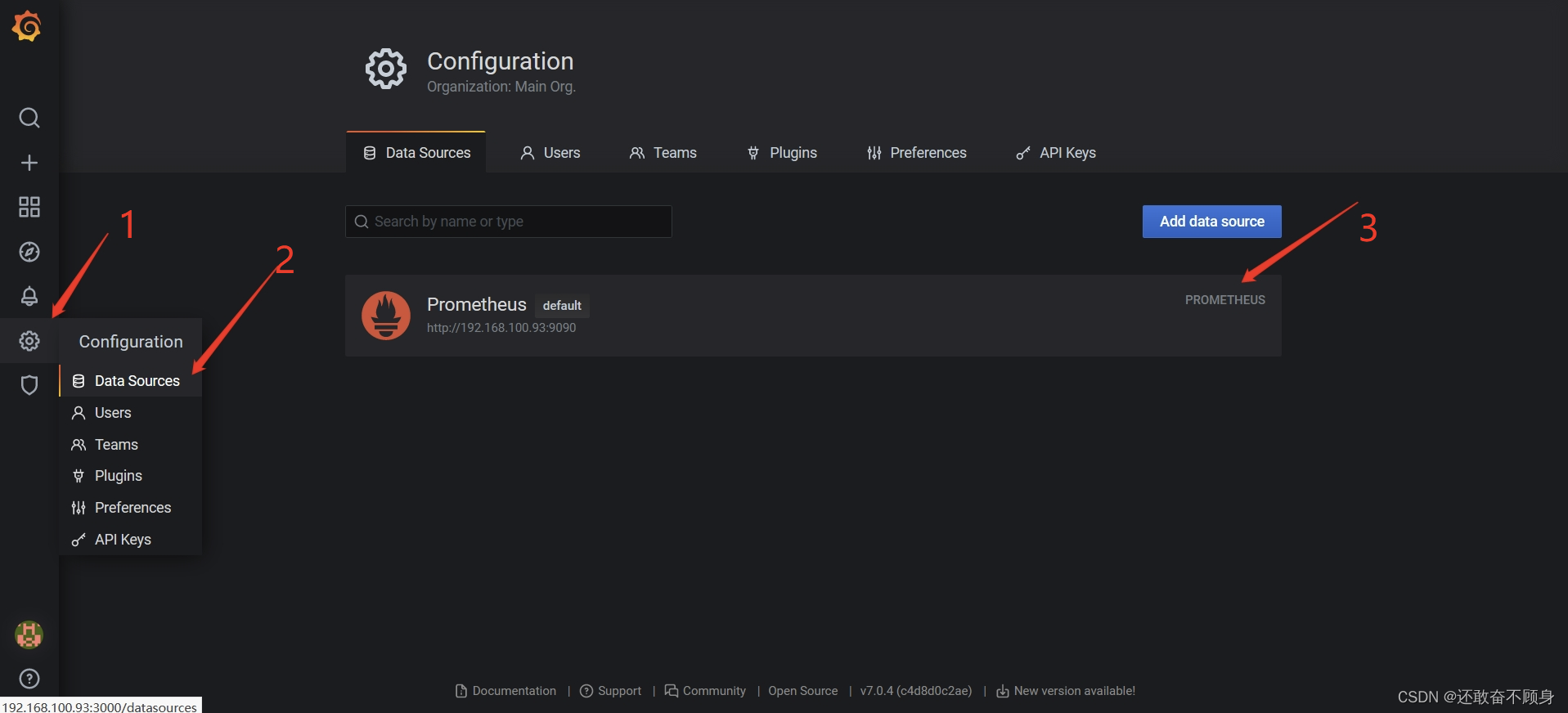
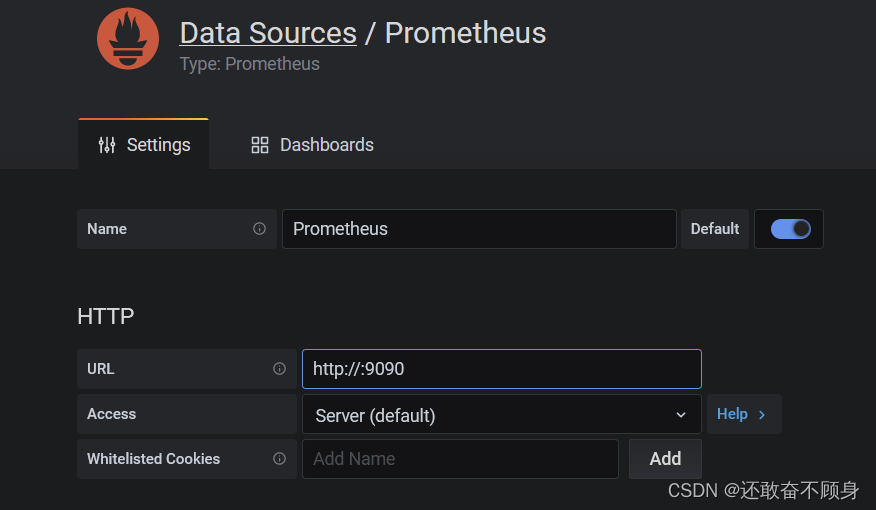
输入prometheusURL地址端口,最后测试保存
如果测试保存失败可以试试http://127.0.0.1:9090
创建dashboard仪表盘
https://grafana.com/grafana/dashboards/ 这里有许多精美的仪表盘,选择对应的数据源,收集器类型后就可以选择自己喜欢的dashboard了
数据源:prometheus,收集器:node exports,我在这里选择编号10242的dashboard
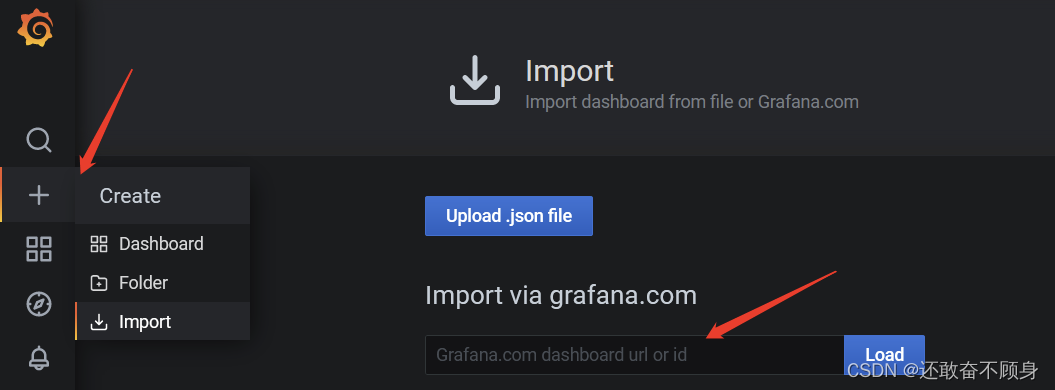
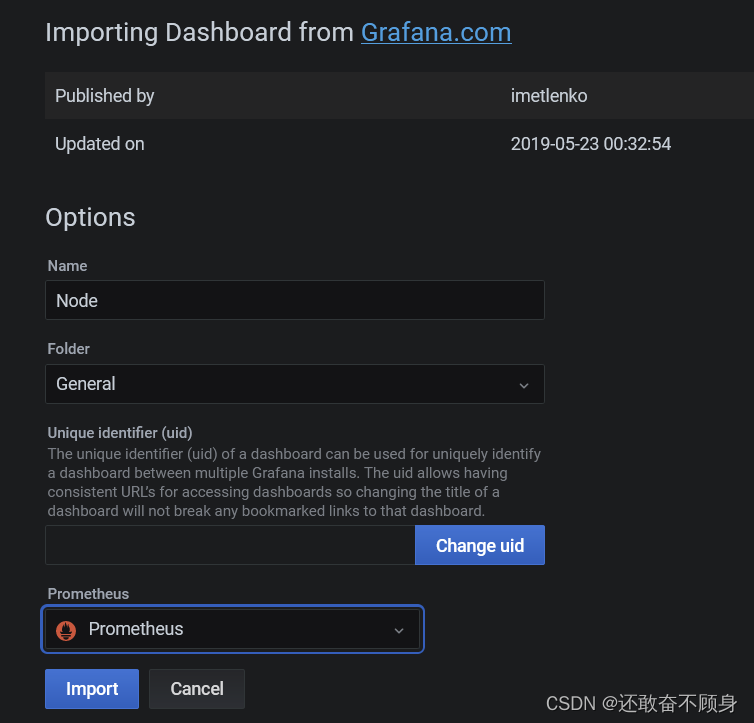
输入对应的ID,点击 Load导入,选择对应的数据源点击import应用即可
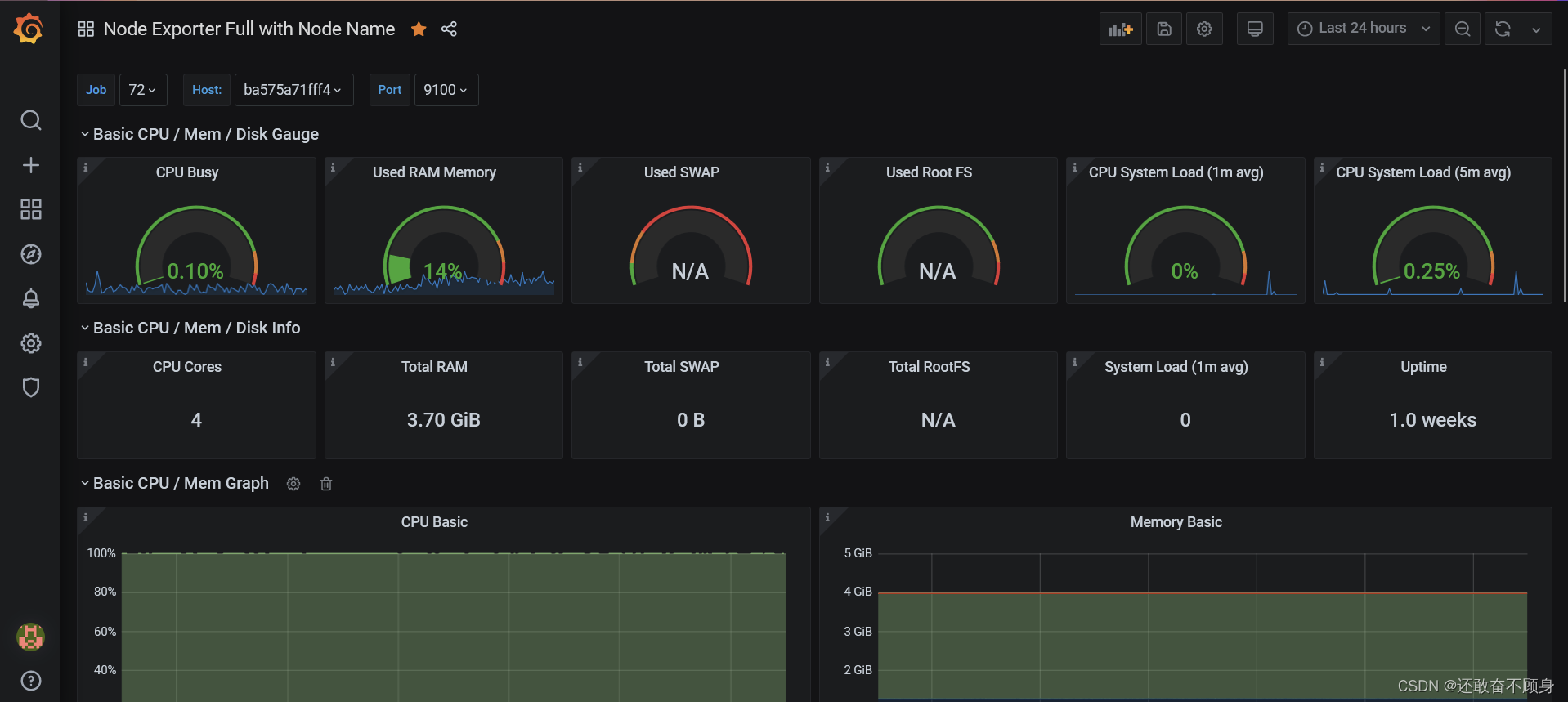
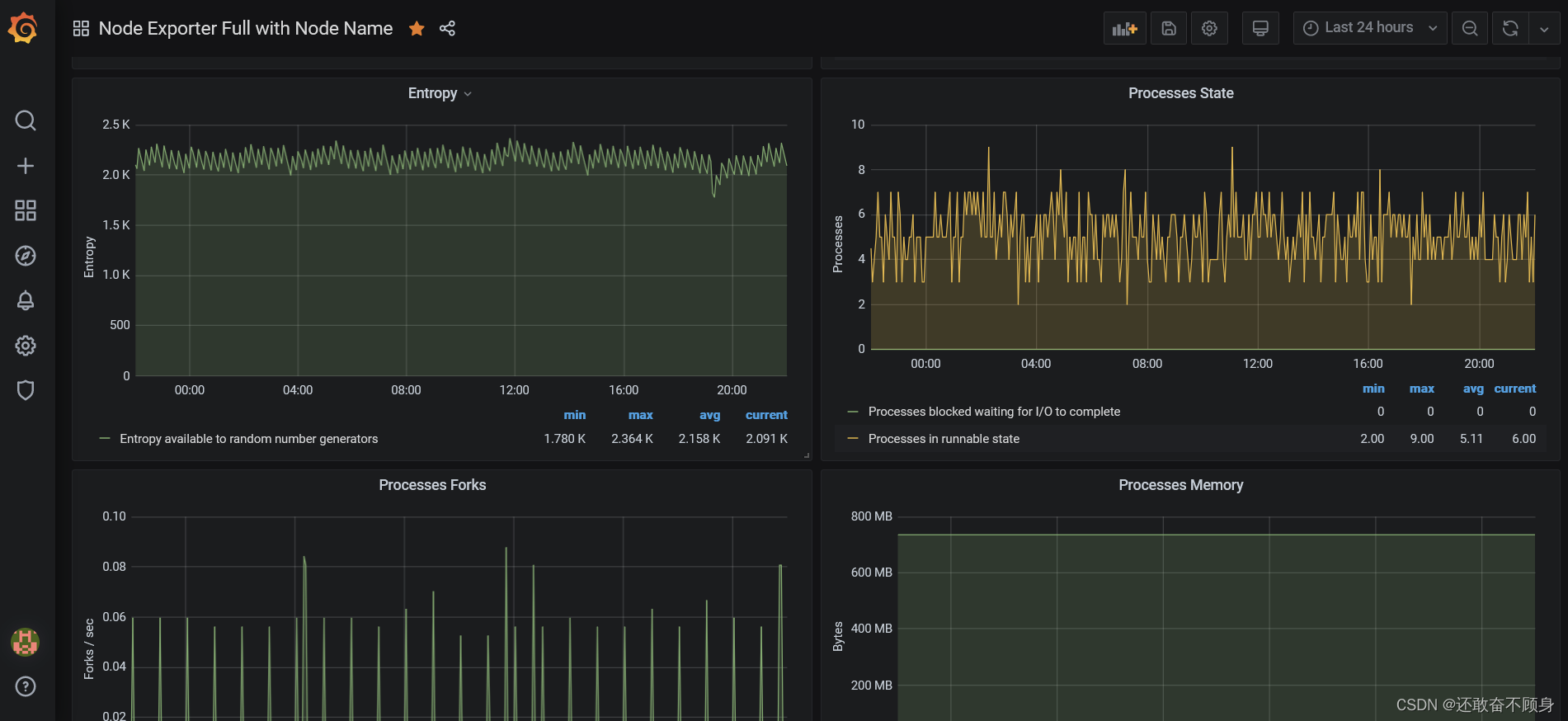
最后,看看效果图吧















 4136
4136











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









