






一、集合体系结构 (单例集合)
1 、结构图
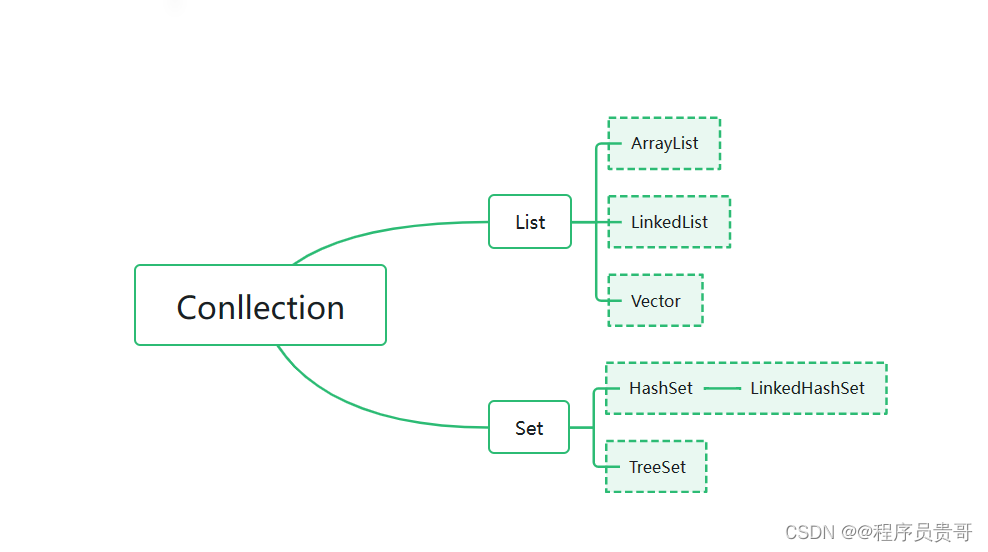
2、集合的特点
List:系列集合:添加元素的时候是有序、可重复,有索引
这里所说的有序:是存储的顺序,和取出的顺序是一样的
可重复:存储可以重复存储相同的元素
索引:通过索引可以获取集合中的元素
Set系列集合:添加元素的时候是无序、不可重复,无索引
无序: Set集合中存储的顺序和获取顺序可能不想同的
不可重复:Set集合中不能存储相同的元素
无索引:Set集合中是不可以通过索引来获取Set集合中的元素
3、Conllection
(1) Conllection是单列集合的顶层接口,他的功能是全部单例集合都可以继承使用的。
4、Conllection的遍历
1.迭代器
(1)迭代器在遍历集合的时候是不依赖索引的
(2)迭代器的四个细节:
a.如果当前位置没有元素,还要强行获取,则会报异常NoSushElementException
b.迭代器遍历完毕的时候,指针不会复位
c.循环体中只能用一个next
d.迭代遍历的时候,不能使用集合中的方法进行增加删除
2.增强for遍历
(1)增强for的底层就是迭代器,为了简化迭代器的代码书写的
(2)他是JDK5之后出现的,其内部原理就是一个iterator迭代器
(3)所有的单例集合和数组才能用增强for来遍历
(4)修改增强for中的变量(第三方的变量),不会改变集合中原本的数据
3. Lambda表达式
(1)得意于jdk8开始的新技术Lambda表达式,提供一种更简单的更直接的遍历集合的方式
default void forEach(Consumer<? super T> action) 结合Lambda遍历集合
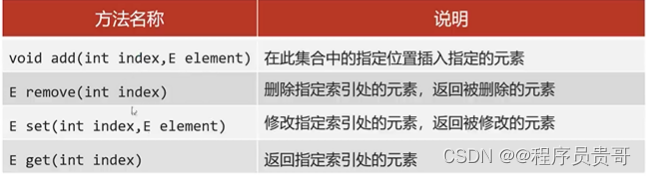
5、List集合特有的方法
1.Collction的方法List都继承了
2.List集合有索引,所以多了很多索引操作的方法。
1.list遍历以及什么使用
(1)迭代器遍历 : 在遍历的过程中,需要删除元素,就可以用迭代器
// (1)迭代器遍历
List<String> list = new ArrayList<>();
list.add("aaa");
list.add("bbb");
list.add("ccc");
Iterator<String> iterator = list.iterator();
while(iterator.hasNext()){
String next = iterator.next();
System.out.println(next);
}(2)增强for遍历:如果我们就只是想遍历元素,则就可以使用增强for
(2)增强for遍历
// 下面的s变量,其实一个第三方的的变量而已,在循环过程中,一次表示集合中的每一个元素
for (String s : list) {
System.out.println("这是增强for");
// s = "QQQ";
System.out.println(s);
}
System.out.println(list);(3)Lambda表达式遍历:如果我们就只是想遍历元素,则就可以使用增强for
System.out.println(list);
// (3)Lambda表达式遍历
System.out.println("Lambda表达式遍历-------------");
list.forEach(s->System.out.println(s)); //简写(4)列表迭代器遍历:在遍历过程中,需要添加元素,就可以用列表迭代器遍历
// 获取列表迭代器对象,里面的指针默认也是指向0
// 额外的添加了功能,在遍历的过程中,可以添加元素
System.out.println("-------这是列表迭代器遍历----------");
ListIterator<String> listIterator = list.listIterator();
while (listIterator.hasNext()){
String next = listIterator.next();
if (next.equals("bbb")){
listIterator.add("QQQ");
}
System.out.println(next);
}
System.out.println(list);(5)普通for循环遍历(因为fList集合存在索引):如果遍历的时候想操作索引,可以用普通for遍历
// 普通for循环
System.out.println("-------普通for遍历---------");
for (int i = 0; i < list.size(); i++) {
String s = list.get(i);
System.out.println(s);
}6.数据结构
1.数据结构的特点
数据结构是计算机底层的存储、组织数据的方式
是指数据相互之间是以什么方式排列在一起的
数据结构是为了更加方便的管理和使用数据,需要结合具体的业务场景来进行选择
2.数据结构(栈)
特点:先进后出,后进先出
3.数据结构(队列)
特点:先进先出,后进后出
4.数据结构(数组)
1.查询速度快:查询数据通过地址值和索引定位,查询任意数据耗时相同(元素在内存中是连续存储的)
2.删除效率低:要将元数据删除,同时后面的元素都要向前面移动
3。添加效率低:添加的位置后面的元素都要向后移动,在添加元素
5.数据结构(链表)
单列链表: 链表中的每一个节点是独立的对象,在内存中不是连续的,每一个节点包含数据值和下一个节点的地址
链表的查询速度慢:无论查询哪个数据都要从头开始找
链表的增加和删除效率高
有单列链表和双列链表
双列链表:如果查询时,他会先判断是离头近还是离尾近,那边近就从那边开始查找
7.ArraryList集合底层原理
1.ArraryList的底层结构是数组,数组的默认长度为10
2.当数组添加满了后,会自动扩容为1.5倍
3.ArraryList底层扩容的原理
(1)利用空参创建的集合,在底层会创建默认长度为0的数组
(2)添加第一个元素时,在底层会创建一个新的长度为10的数组
(3)存满时,会扩容1.5倍
(4)如果一次添加多个元素,1.5倍还放不下,则会创建新的数组的长度为实际的长度
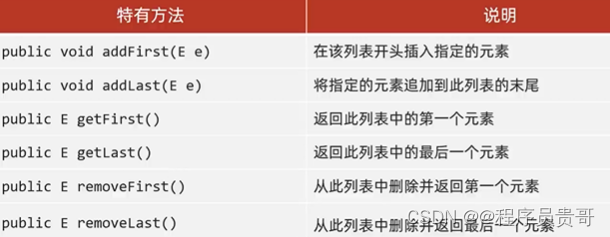
4.LinkedList集合
(1)底层数据结构是双链表,查询慢,增删块,但是如果操作的是首尾元素,速度也是极快的
(2)LinkedList本身多了很多直接操作首尾元素的特有的API
8.泛型
1.泛型:是jdk5中映入的特性,可以在编译阶段约束操作的数据类型,并进行检查
2.泛型的格式:<数据类型>
3.泛型的好处:
(1)统一数据类型
(2)把运行时期的问题提前到了编译期间,避免了强制类型转换可能出现问题,因为在编译阶段类型就确定下来了
8.泛型类
1.使用场景:当一个类中,某个变量的数据类型不确定时,就可以定义带有泛型的类
2.格式:修饰符 class 类名<类型> {}
举例
public class ArraryList<E>{
}3.此处的E可以理解为变量,但是不是用来记录数据的,而是记录数据的类型,可以写:E F K V 等
4.泛型的细节:
泛型中不能写基本数据类型,指定泛型具体类型后,专递数据时,可以传入该类型和其他的子类类型,如果不写泛型,类型默认是Object
9.哪里定义泛型
泛型类:在类名后面定义泛型,创建该类对象的时候,确类型
泛型方法:在修饰符后面定义,调用该方法时候,确定该类型
泛型接口:在接口后面定义泛型,实现该类确定类型,实现类延续泛型
10.泛型的继承和通配符
泛型不具备继承性,但是数据具有继承性
泛型通配符:?
? extend E
? super E
11.使用场景
1.定义类,方法,接口的时候,不知道类型确定,就可以定义泛型
2.如果类型不确定,但知道能知道是哪个继承体系中,可以使用泛型的通配符
12 .Set集合
1.set集合添加无序,不可重复,无索引
13.Set集合的实现类
1.HashSet:无序,不可重复,无索引
2.LinkedHashSet: 有序,不可重复,无索引
3.TreeSet;可排序,不可重复,无索引
14.HashSet底层原理
HashSet集合底层采取哈希表存储数据
哈希表对应增删改查的数据性能都比较好的结构
哈希表的组成:
jdk8之前:数组+链表
jdk8开始:数组+链表+红黑树
二、双例集
1.双例集合特性
(1)双列集合一次需要存一对数据,分别是键和值
(2)键不能重复,值可以重复
(3)键和值是一 一对应的,每一个键只能找到自己对应的值
(4)键+值这个整体我们称为“键值对”或者 “键值对对象”,在java中叫做“Entry对象”
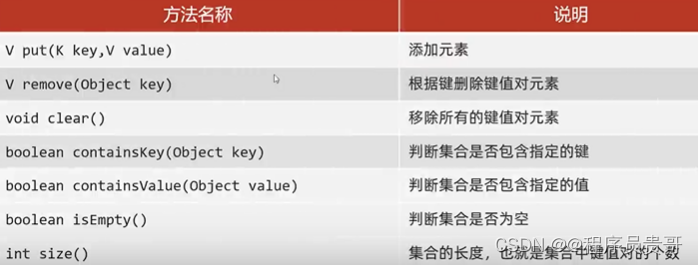
2.Map的常见的API
map是双列集合的顶层接口,他的功能是全部双列集合都可以继承使用的。
3.HashMap集合的特点
(1)HashMap是Map里的一个实现类,
(2)没有额外需要学习的特有的方法,直接使用Map里面的方法就可以 了
(3)特点都是有键决定:无序,不重复,无索引
(4)hashMap()底层是哈希表结构
(5)依赖于hashCode方法和equals方法保证键的唯一
(6)如果键存储的对象是自定义的,需要重写hashCode方法和equals方法,如存储值是自定义对象,不需要重写hashCode和equals()方法
4.linkedHashMap
(1)有序,不可重复,无索引
(2)底层原理:底层数据结构依然是哈希表,只是每个键值对元素额外的多了一个双链表的机制记录存储的顺序
5.TreeMap
(1)TreeMap跟TreeSet底层原理一样,都是红黑树结构的
(2)由键决定特性:不重复,无索引,可排序
(3)默认按照键的从小到大排序,也可以自己规定键的排序规则
排序有两种规则
(1)实现Comparable接口,指定比较规则
(2)创建集合时传递Comparator比较器对象,指定比较规则
(3)可排序:他是按照键来排序的,默认从小到大,Iterget ,从小到大,String类型,按照ASCII码表中对应的数字进行升序
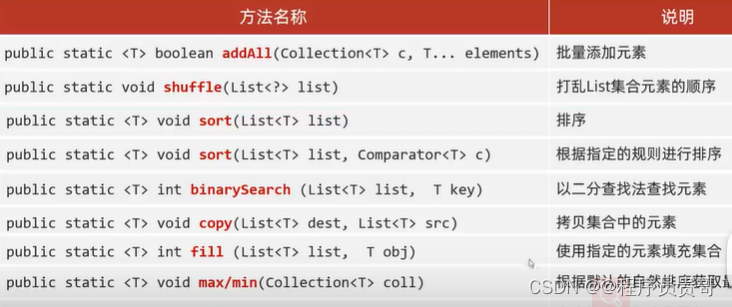
6.Colletions
(1)java.util.Colltions:是集合的工具类、
(2)作用:Colletions不是集合,而是集合的工具类
(3)Colletions常用的API
















 3945
3945











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









