






总结一下pandas基础命令
库导入
import pandas as pd # 导入pandas库并简写为pd
import numpy as np # 导入numpy库并简写为np数据导入
pd.read_csv(filename) # 导入csv格式文件中的数据
pd.read_table(filename) # 导入有分隔符的文本 (如TSV) 中的数据
pd.read_excel(filename) # 导入Excel格式文件中的数据
pd.read_sql(query, connection_object) # 导入SQL数据表/数据库中的数据
pd.read_json(json_string) # 导入JSON格式的字符,URL地址或者文件中的数据
pd.read_html(url) # 导入经过解析的URL地址中包含的数据框 (DataFrame) 数据
pd.read_clipboard() # 导入系统粘贴板里面的数据
pd.DataFrame(dict) # 导入Python字典 (dict) 里面的数据,其中key是数据框的表头,value是数据框的内容。数据导出
df.to_csv(filename) # 将数据框 (DataFrame)中的数据导入csv格式的文件中
df.to_excel(filename) # 将数据框 (DataFrame)中的数据导入Excel格式的文件中
df.to_sql(table_name,connection_object) # 将数据框 (DataFrame)中的数据导入SQL数据表/数据库中
df.to_json(filename) # 将数据框 (DataFrame)中的数据导入JSON格式的文件中创建测试对象


![]()




数据的查看和检查
1.head()
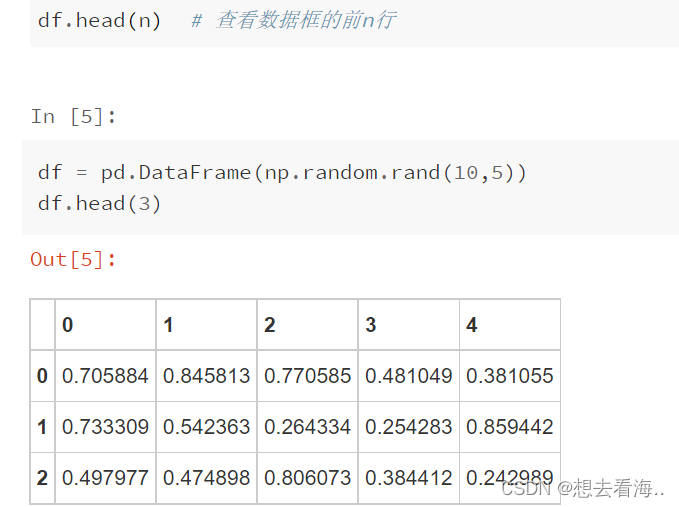
2.tail()
 3.shape()
3.shape()

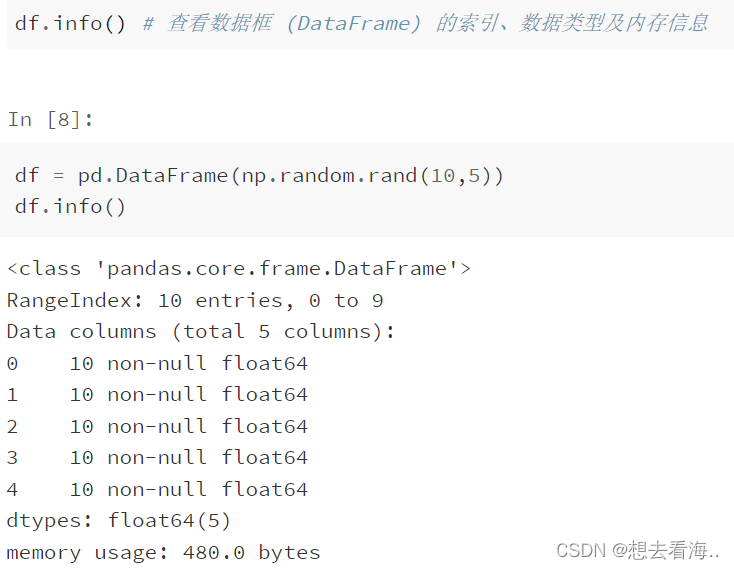
4.info()
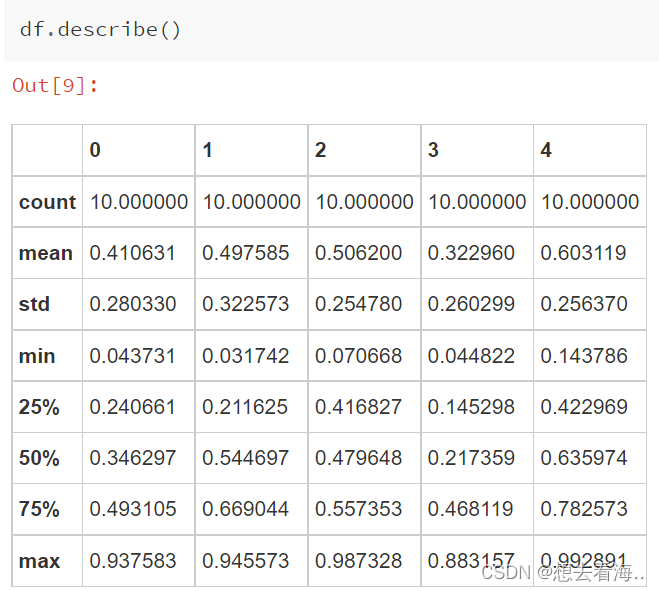
 5.describe()
5.describe()

6.value_counts()


数据的选取
取列

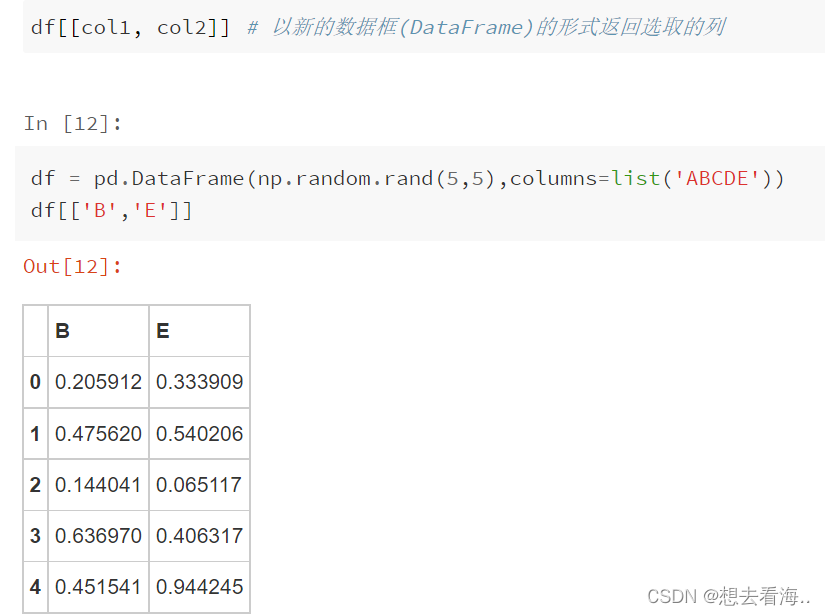
取多列作为新的dataframe
loc()
按照标签索引取


iloc()
按照位置索引取

数据清洗

isnull()

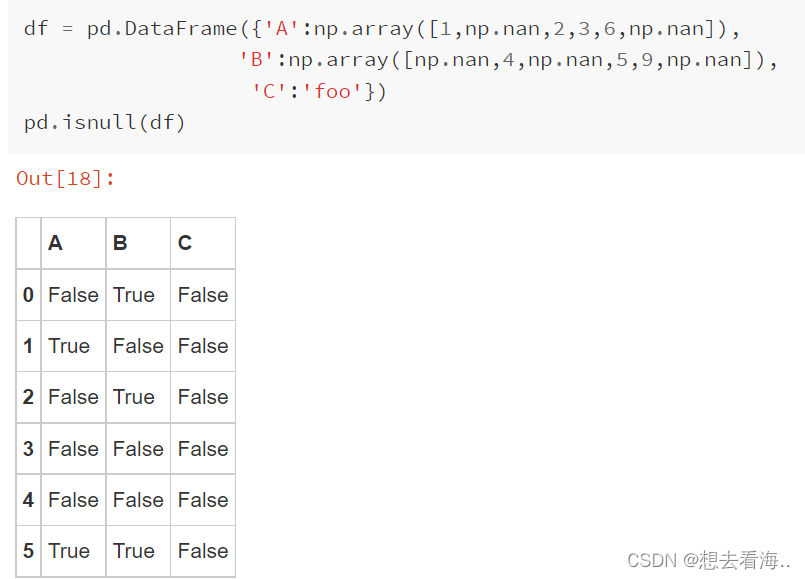
notnull()


dropna()
默认axis=0,对行操作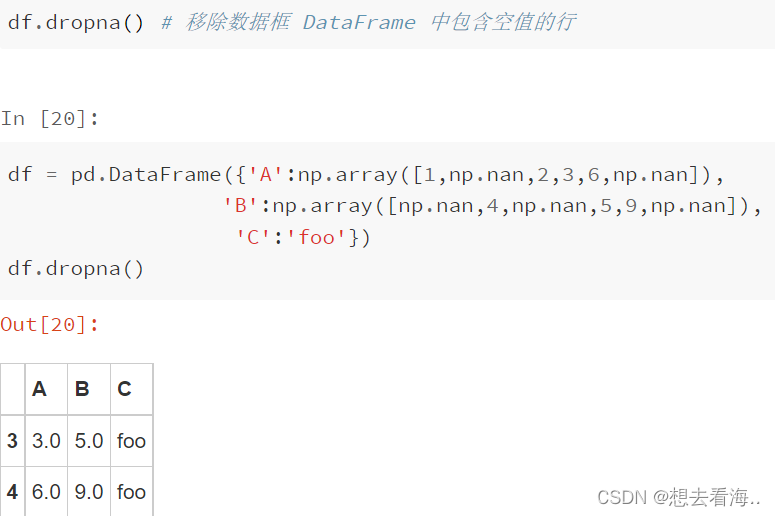
删除空的列设置axis=1即可
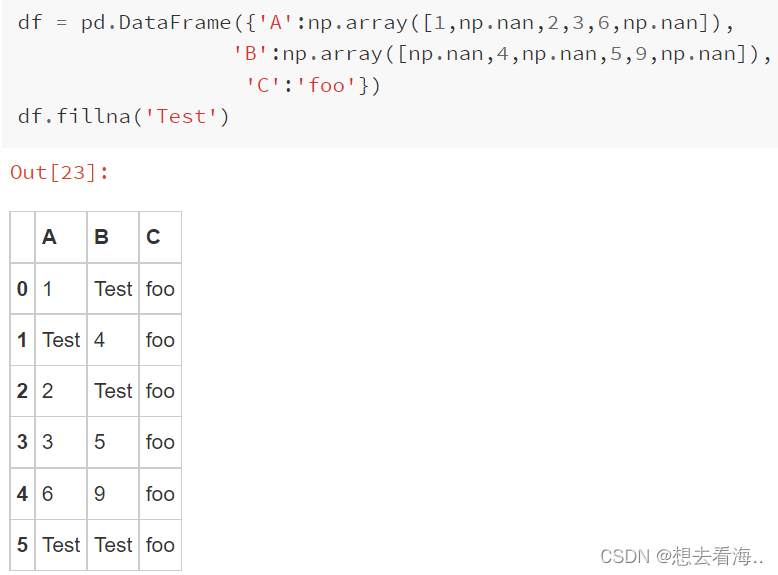
fillna()
![]()
astype()

replace()

若要真正的改动,还需要加上 inplace=True
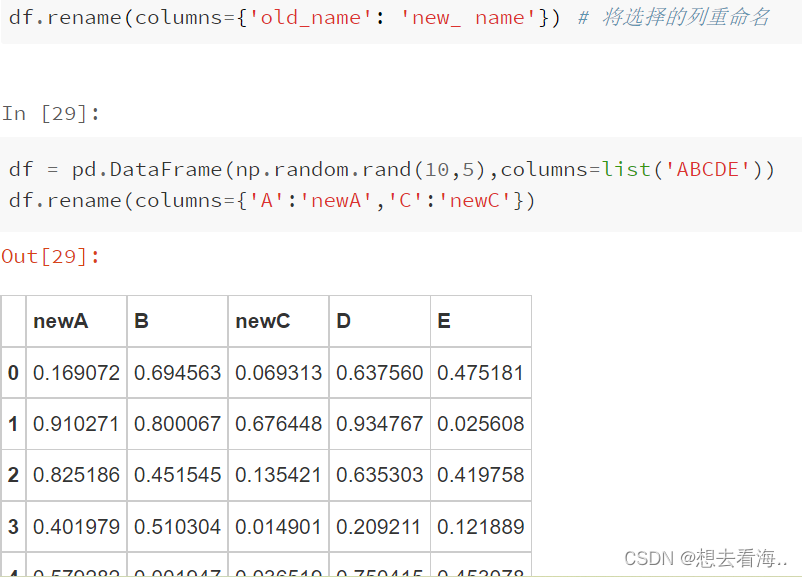
rename()
该函数既可以改变列名,也可以改变索引。

set_index()

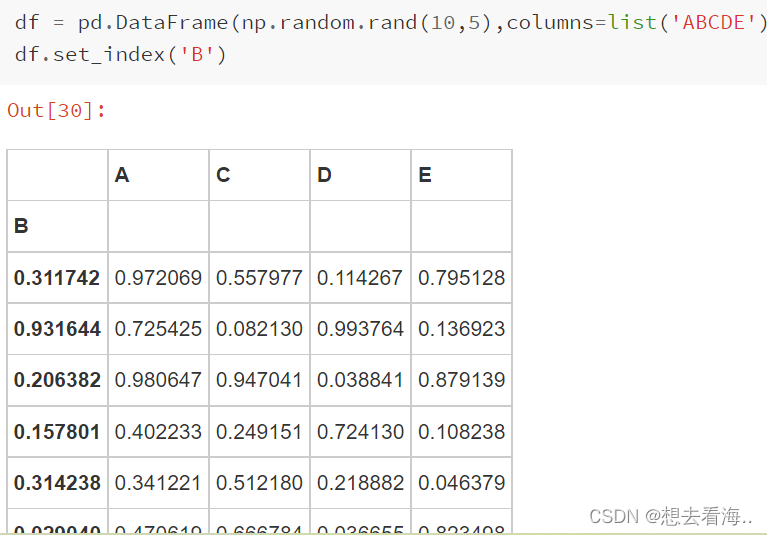
数据的过滤(filter),排序(sort),分组(group by)
1.用True过滤

sort_values()
默认升序


group by
分组的时候会将分组的列作为索引,若不需要,需设置 as_index = False
![]()



pivot_table()

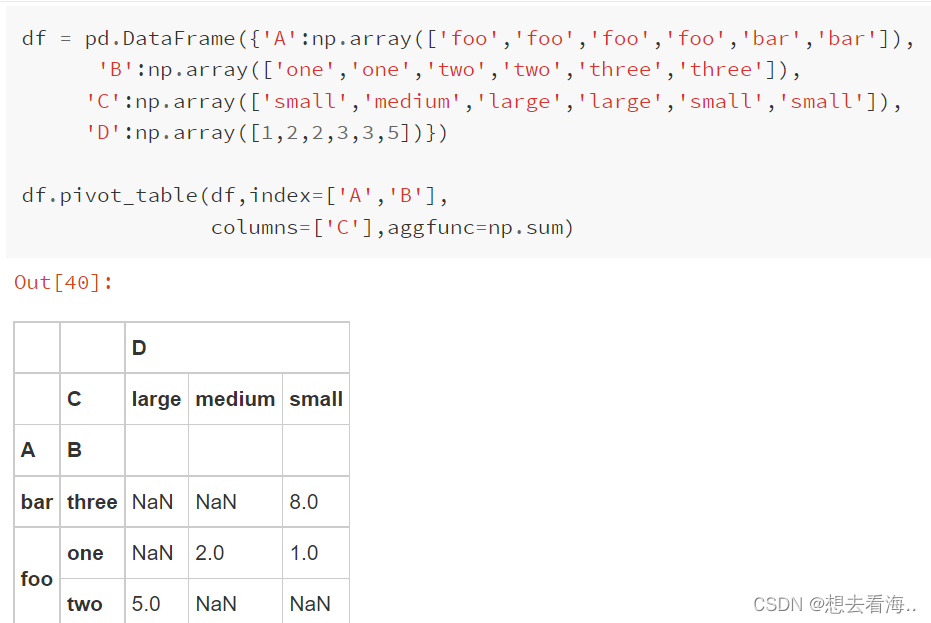
pivot_table()参数如下

apply()
这个函数是对dataframe的行或列操作
注意默认axis=0 ,我的理解是聚合行,对列数据进行操作,反之axis=1是聚合列,对行进行操作。

数据的连接和组合
concat()



join()
![]()


这个笔记希望对学习数据分析的小伙伴有帮助。















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









