






1.js的前世今生
1990年蒂姆博士 发明了 --》定义文本的格式(html 超文本标记语言)--》传输文本的方式(http协议 超文本传输协议)--》文本的展示(浏览器 www万维网)
1995年 Brendan Eich 10天发明javascript语言(脚本语言) 脚本语言是无法调用系统的硬件,需要依赖与环境 通过宿主环境解析器解析成机器语言后执行
1996年微软加入浏览器市场 出现第一款ie浏览器 同时微软与网景公司出现利益竞争,之后网景公司把Javascript交给了ECMA(国际标准组织) 希望能够提升知名度与微软抗衡
2001年出现windowXp以及ie6浏览器(ie6 强大之处就是把原本在页面的渲染引擎中的内嵌js解析引擎抽离出来 独立运行)
2008年谷歌浏览器出世 研制出blink内核 同时强大的jsV8引擎(1.把代码直接解析成机器码,跳过字节码 2.独立于浏览器运行) 之后甲骨文公司收购sun公司以至于javascript版权归甲骨文公司
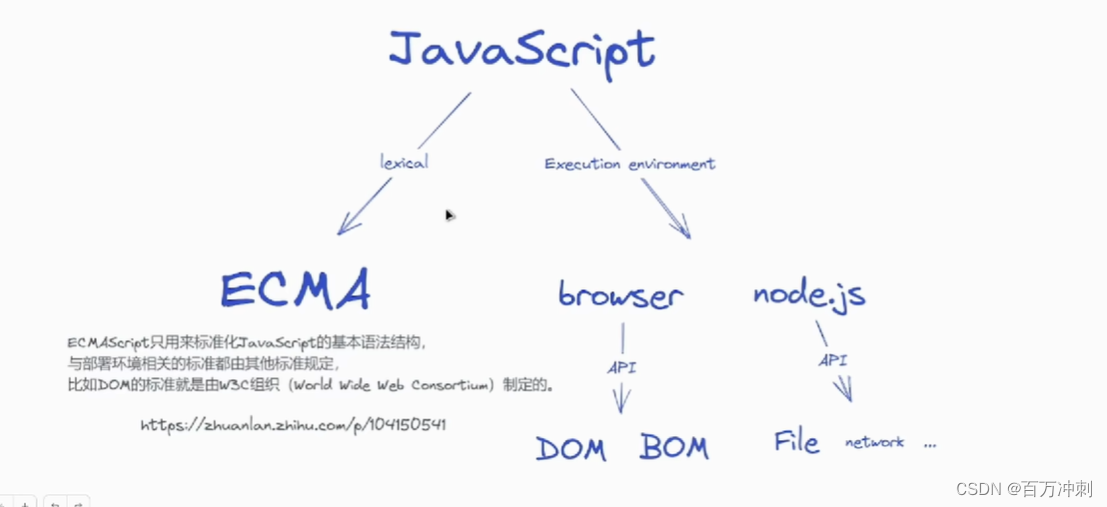
2.ECMAscript与javascript关系?
ecma定义js的语法结构而js的执行需要依赖于环境(浏览器或node环境)通过环境提供的api来对js进行更复杂的操作
3.了解程序,进程,线程
程序是保存到磁盘中的 当需要执行程序的时候 电脑的操作系统会把程序的代码放置内存中以至于会被电脑的cpu去加载运行
程序被加载到内存中所分配空间 结构如下图
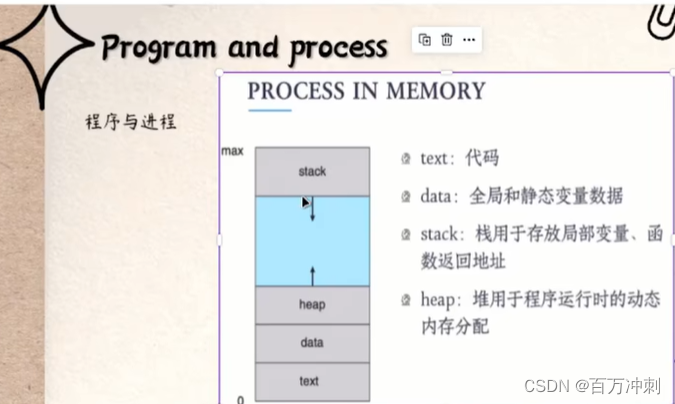
程序:程序员所写的编程语言通过解析器解析成能够被计算器所识别的机器语言叫程序 程序是静态的是被动执行的
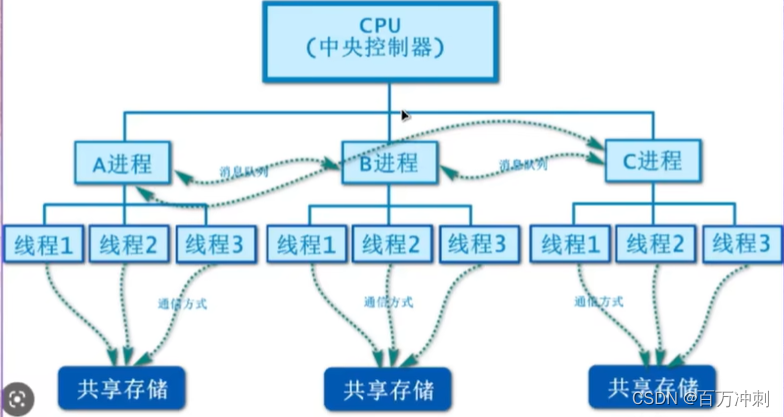
进程: 操作系统为程序执行,为程序所分配的资源(内存) 注意:进程是并发的 缺点是进程与进程之间是独立的互相通信比较困难, 浪费资源
线程: 线程为cpu执行的最小单位 优点:节省空间,资源共享,弥补进程缺点而出现的线程
并行:同时执行的过程 相当于两辆车同时从起点出发运行
并发:多个程序进行执行 分配多个进程 由于是共享一个cpu而cpu执行速度快 会在进程中来回切换执行造成并行的假象
关系图 如下
4.现代浏览器的架构
多进程浏览器
大致进程分类




前端主要关注渲染进程
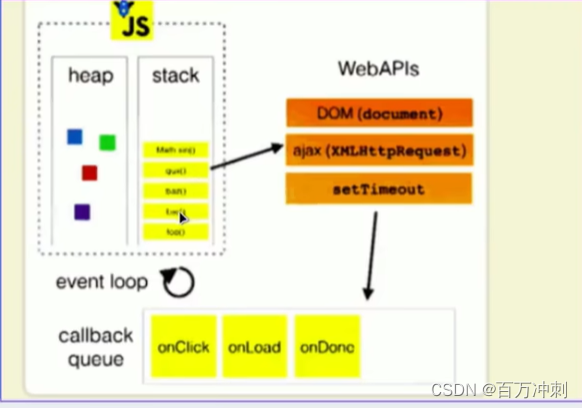
渲染进程是多线程的进程(也是采用沙箱模式 为了安全考虑 不能直接与硬件接触) 渲染进程分为渲染引擎 和 js引擎 两者如何配合?---》 通过任务队列配合
任务队列分类 如下图

渲染引擎 和 js引擎 工作在同一个渲染进程的主线程里(两者互斥) 而同时注意js执行是单线程的 意味着js执行会堵塞html解析 --》 出现堵塞的解决方案 --》异步编程方案 通过事件循环 来配合解决 如下图
浏览器渲染引擎执行机制
过程如下图

解析html文本 可包含对元素标签 css js 不同的处理
元素标签--》解析成dom树
css--》 cssom tree 只对操作者向外暴露自己写的css内容 底层c++语言写的默认浏览器css不对外提供操作 通过document.styleSheets 查看
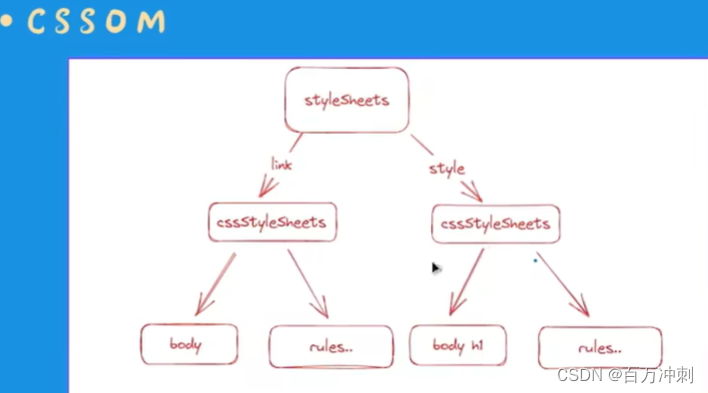
两者结合 通过样式计算把cssom和dom生成含有所有css的dom节点 如下图
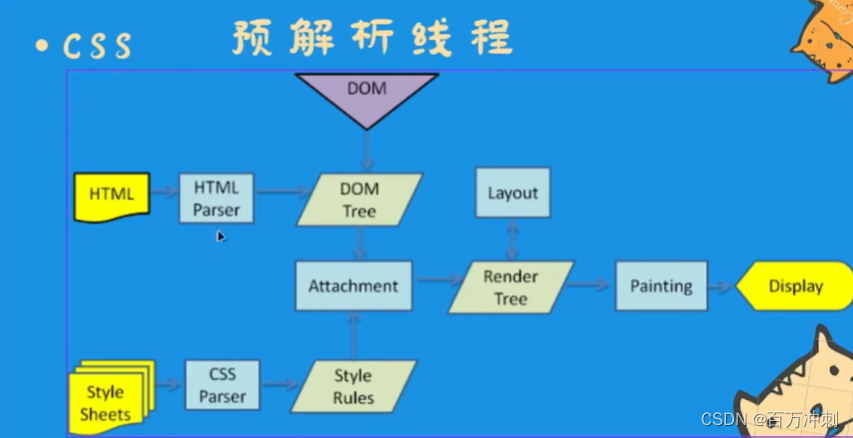
css不会堵塞dom解析但是会堵塞dom渲染 因为css在另一个线程
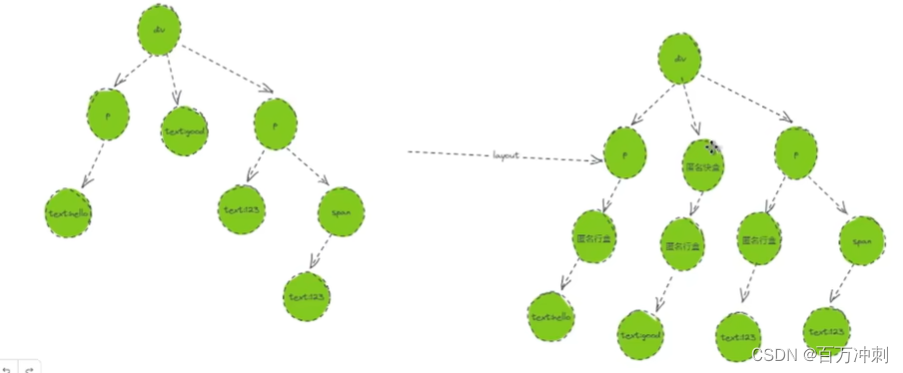
上图中 css和html合并之后生成具有css内容的dom树 再生成布局树过程 有一些规则需要注意
1. 布局中 每一个文本节点要在匿名行盒里 同一行要么都是块级要么都是行级 有行级就新增匿名块盒
2. html中向 部分元素是不具有几何信息的 比如meta ,head, link标签
3. css伪元素没有加content 也不具有几何信息 也就是不会在布局树里
之后再进行分层(不同的图层)处理 --》可在控制台--》更多工具--》图层 查看
再接着 开始绘制

之后再在 合成线程(compositor Thread)里面完成接下来的内容 在合成线程里开始进行分块(titling)处理之后进行光栅化(raster)处理成位图(draw) 最后把位图内容交给GPU进程 GPU进程再交给硬件(显示器) 去展示最终的页面
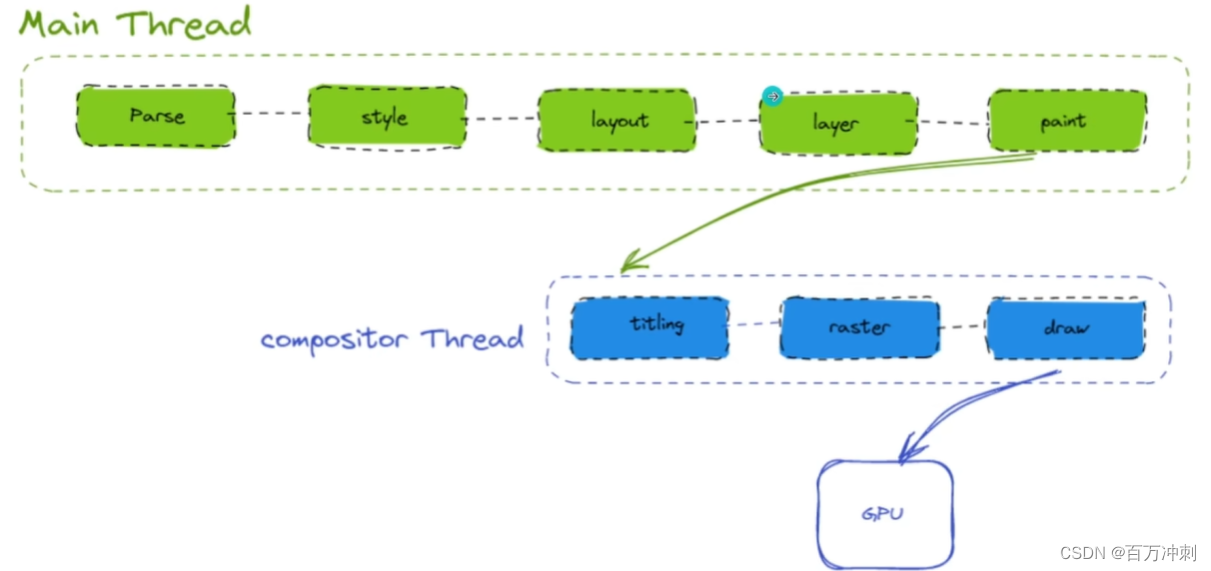
以上步骤 就是大致的渲染引擎的工作机制
refllow(重排) :当你改变节点的几何信息 就会重新生成布局树 ,生成新的布局树还会重新走后面的流程 ,开销就会很大 性能不好
浏览器js引擎
语言解释
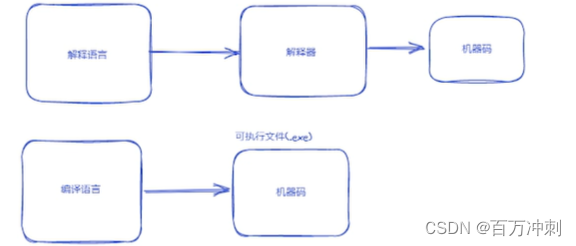
解释语言是需要依赖环境通过解释器解释成机器码
编译语言可以通过一些特殊处理直接生成机器码 可以直接发给别人使用
js解释器 流程如下图

词法分析 如下
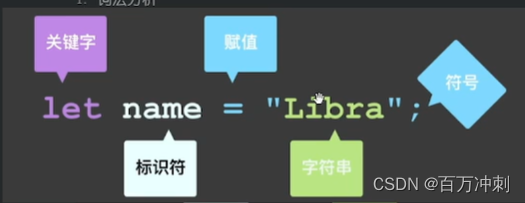
1. 词法分析拆分成 语法单元 类似数组结构
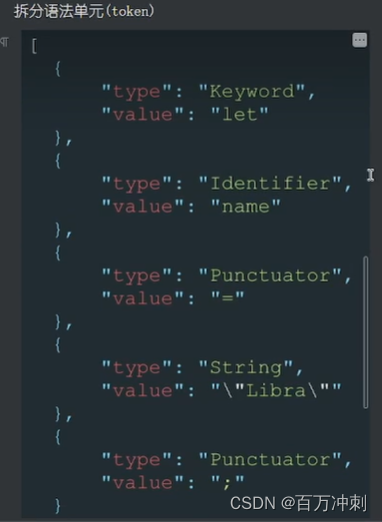
2. 语法分析 根据token(词法单元) --> 生成ast语法树(具有逻辑关系) 如下图

js执行 步骤 预解析和代码执行
预解析(根据ast树)
执行上下文: 执行上下文简单理解为程序读写数据所查找的地方
执行上下文 分为全局执行上下文和函数执行上下文
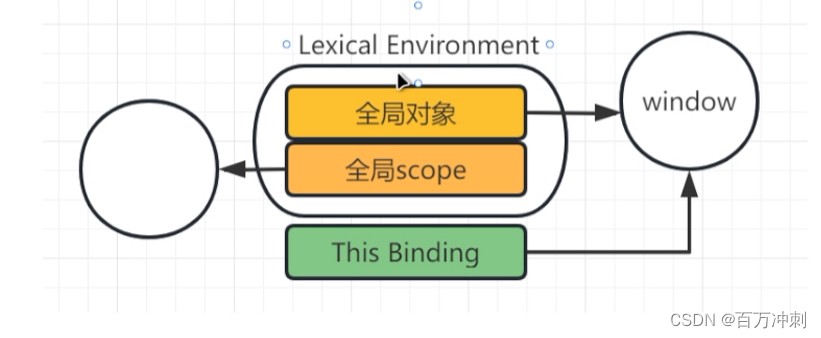
全局执行上下文:广义上分为 词法环境(Lexical enviroment)和this.binding
Lexical enviroment组成
1. 全局对象
2.全局scope
3.outter -----》全局执行上下文中指向null
this.binding: this的指向 全局执行上下文中this指向window(严格模式下也是一样的)
函数执行上下文:(函数执行时需要先创建函数上下文)

函数内部的声明变量都是在全局scope中 因为没有全局对象
函数执行上下文的执行环境中的 outter 指向 执行函数前创建的函数对象的[[SCOPE]]指向的当前执行上下文(始终是指向执行上下文栈的栈顶)
在执行上下文中找不到变量时,则会查找outter指向的执行上下文(作用域链底层机制)
练习:画图
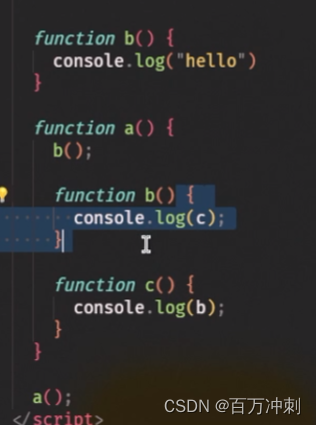
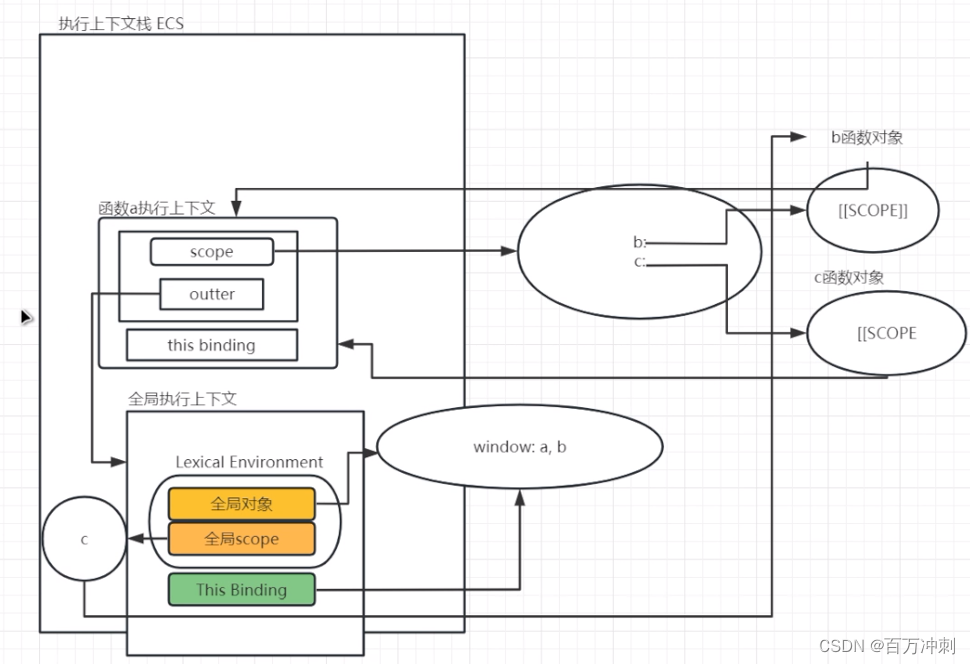
执行上下文的创建流程 (将程序中的变量声明进行处理后,存储到执行上下文中)
1.处理声明


2.检查重复定义

规则: var声明会变量提升,以function fn(){}这种形式声明的函数,会被提升到作用域的最最顶部,然后再是变量的提升。同时注意在全局对象中有相同声明的变量,当遇到第二个声明的会忽略变量声明直接等待执行后面的代码
3.创建绑定
1) var变量声明的会赋值会undefined
2) 函数声明的会创建函数对象,并且该变量会指向这个函数对象
注意:对于let const class 声明的不进行赋值,js中对于未赋值的变量进行访问会保存(TDZ)
什么是函数对象呢?

至此 执行上下文创建结束(js执行时)
3.生成字节码
4.生成机器码 硬件执行















 7762
7762











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









