







一、实验内容
对表4-2 客户信息数据进行数据处理,随后进行降维、聚类、可视化。
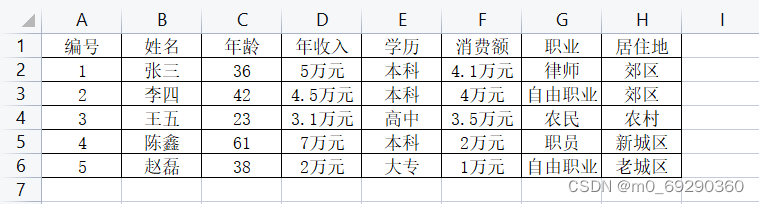
表4-2 客户信息数据
二、实验步骤
1. 读取数据
import numpy as np
import pandas as pd
from pandas import Series,DataFrame
data=pd.read_excel('./4-2 客户信息数据.xlsx')
print(pd.read_excel('./4-2 客户信息数据.xlsx'))执行结果如下:

2. 去除唯一属性
del data['编号']
del data['姓名']
print(data)执行结果如下:

3. 对属性进行编码
data = [[36,50000,4,41000,1,1],
[42,45000,4,40000,2,1],
[23,31000,2,35000,3,2],
[61,70000,4,20000,4,3],
[38,20000,3,10000,2,4]]
print(data)执行结果如下:
![]()
4. 数据归一化
np.set_printoptions(suppress=True)
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
scaler.fit(data)
MinMaxScaler(copy=True,feature_range=(0,1))
print(scaler.transform(data))执行结果如下:

5. 降维-4个维度
from sklearn.decomposition import PCA
pca=PCA(n_components=4)
reduced_x=pca.fit_transform(data)6. 聚类 (K-Means算法)
from sklearn.cluster import KMeans
from sklearn.metrics import fowlkes_mallows_score
data_target=[1,1,0,1,0.5]
for i in range(1,4):
kmeans=KMeans(n_clusters=i,random_state=123).fit(reduced_x)
score=fowlkes_mallows_score(data_target,kmeans.labels_)
print('聚{}类,FMI评价分值为{}'.format(i,score))执行结果如下:
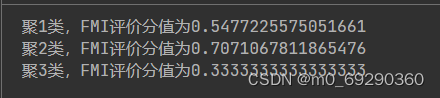
7. 可视化
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
red_x,red_y=[],[]
blue_x,blue_y=[],[]
green_x,green_y=[],[]
y=[1,1,0,1,0,1]
for i in range(len(reduced_x)):
if y[i]==1:
red_x.append(reduced_x[i][0])
red_y.append(reduced_x[i][1])
elif y[i]==0:
blue_x.append(reduced_x[i][0])
blue_y.append(reduced_x[i][1])
plt.scatter(red_x,red_y,marker='x')
plt.scatter(blue_x,blue_y,marker='D')
plt.show()执行结果如下:
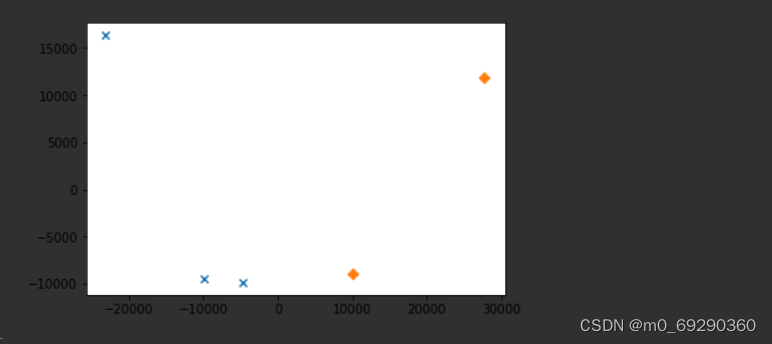















 633
633











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









