



窗口函数:为每一行数据返回一个结果
语法:window_function ([expression]) over (聚合窗口函数)
window_function:窗口函数名称
expression:可选分析对象(字段名或表达式)
over:指定数据分析窗口,固定值
总结:
聚合窗口:
partition by :创建数据分区
order by:排序
frame_clause:指定窗口大小
排名窗口函数:
row_number:为分区的每行数据分配一个序列号,序列号从1开始
rank:返回当前行在分区中的名次,如果存在名次相同的数据,后续的排名将会产生跳跃
dense_rank:返回当前行在分区中的名次,即使存在名次相同的数据,后续的排名也是连续值
percent_rank:以百分比的形式返回当前行在分区中的名次,如果存在名次相同的数据,后续排名将会产生跳跃
cume_dist:计算当前行在分区内的累积分布,指排名在当前行之前(包括当前行)所有数据所占的比率,取值范围大于0且小于或等于1
ntile:将分区内的数据分为n等份,并返回当前行所在的分片位置
取值窗口:
lag(字段名,n):返回窗口内当前行之前的第n行数据,不支持动态的窗口大小选项,以整个分区作为分析的窗口
lead(字段名,n):返回窗口内当前行之后的第n行数据,不支持动态的窗口大小选项,以整个分区作为分析的窗口
first_value(字段名):返回窗口内的第一行数据
last_value(字段名):返回窗口内最后一行数据
nth_value(字段名,n):返回窗口内第n行数据
聚合窗口
partition by(创建数据分区)
注:在窗口函数over子句中指定了pratition by 之后,无须使用group by 子句也能获得分组统计结果。如果不指定pratition by,表示将全部数据作为一个整体进行分析
eg:
按照不同产品名称统计销量平均值
select 字段名或表达式 over (partition by 分区字段) from 表名;
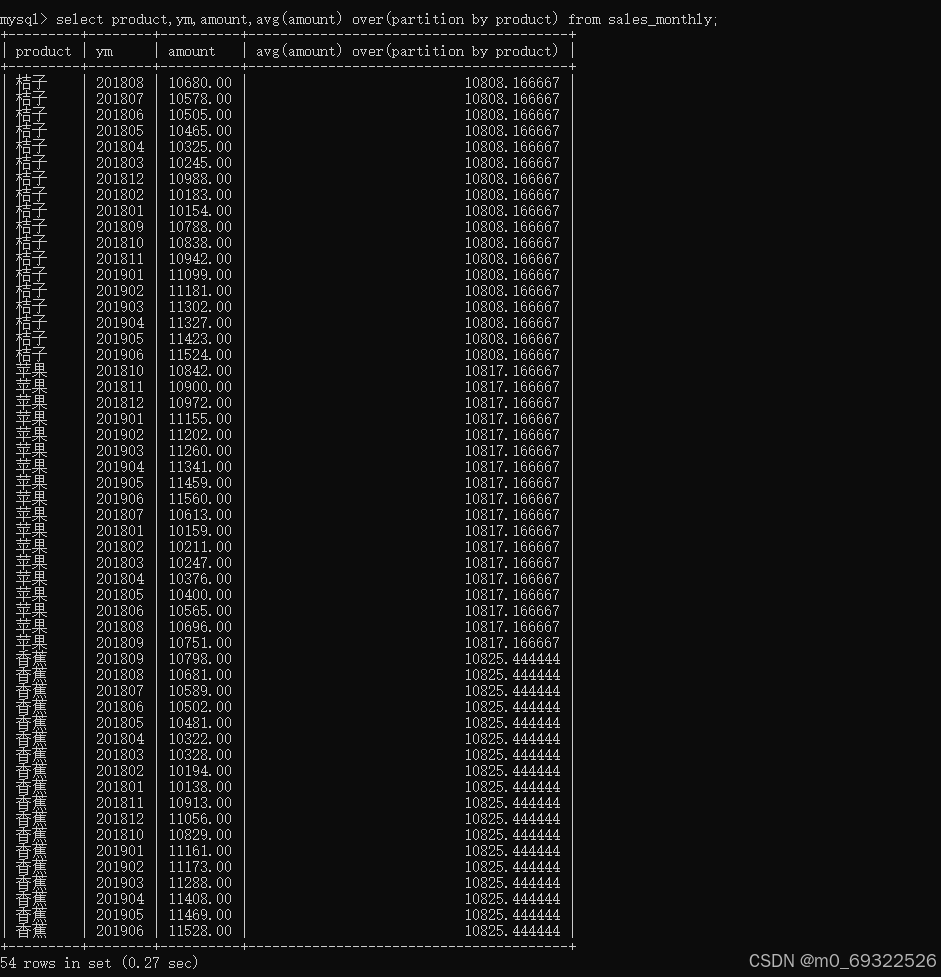
select product,ym,amount,avg(amount) over(partition by product) from sales_monthly;如下图:10808.166667为product为桔子的销量平均值,10817.166667为product为苹果的销量平均值,以此类推...
select product,ym,amount,avg(amount) over() from sales_monthly;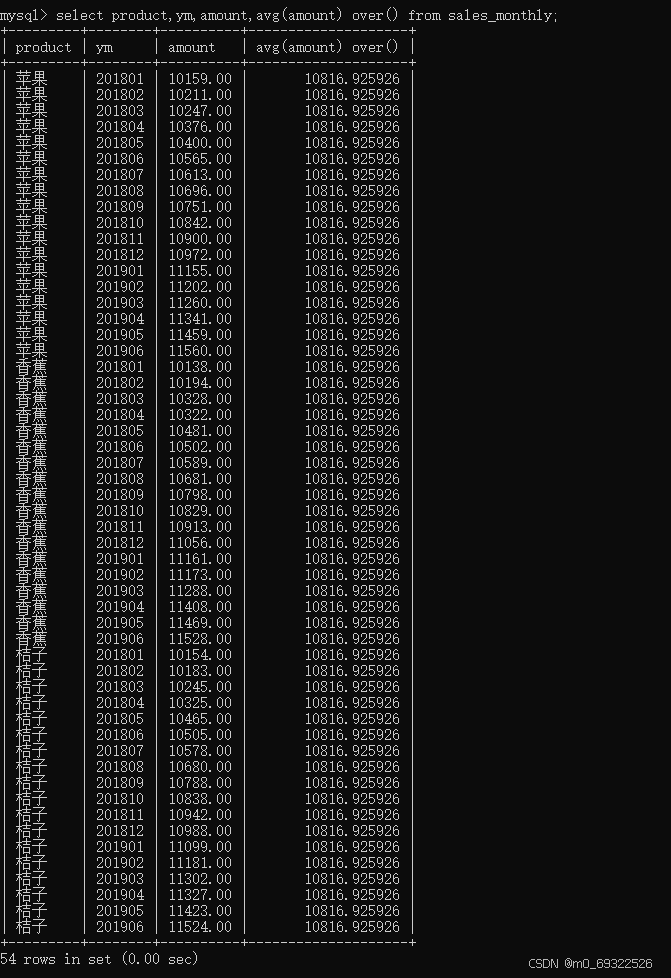
order by(排序)
作用:指定分区内数据的排序方式,类似查询语句中order by
eg:
按照不同产品名称统计销量平均值,同个产品名称按照时间从低到高排序
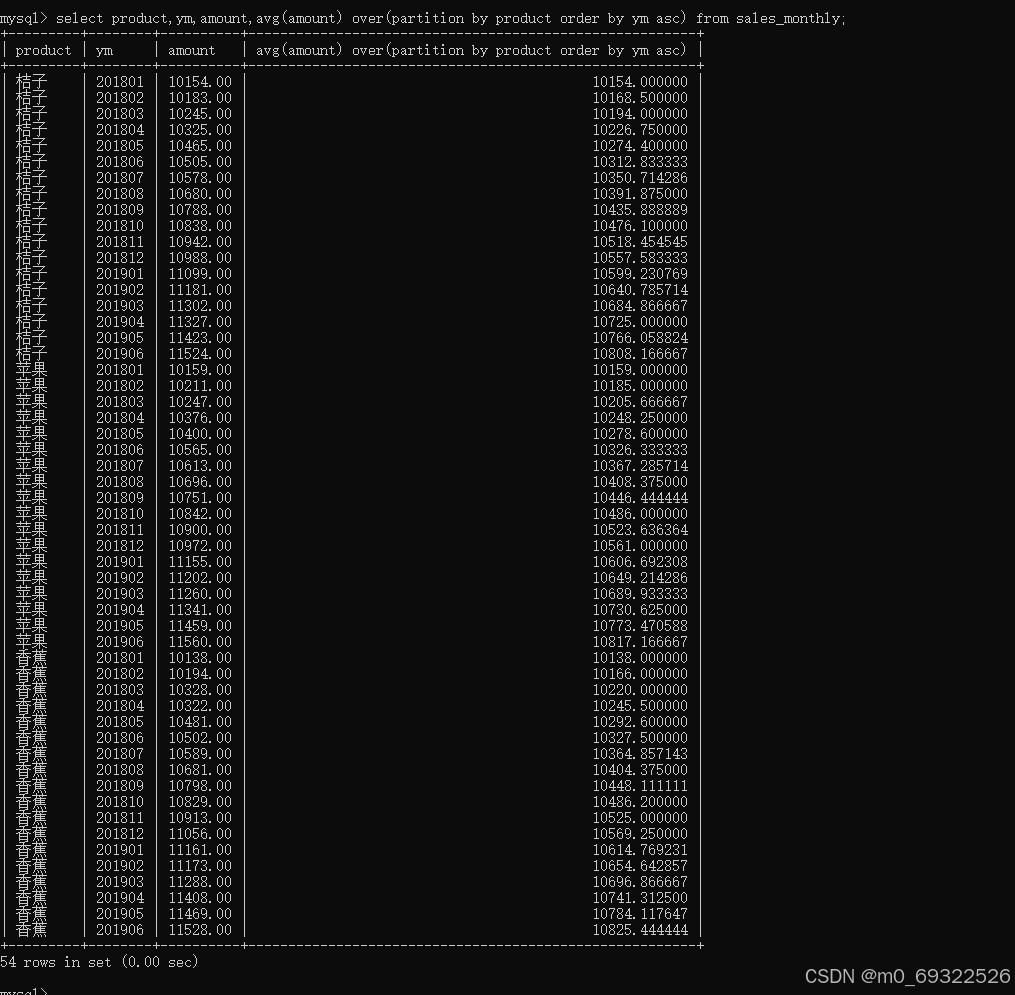
select product,ym,amount,avg(amount) over(partition by product order by ym asc) from sales_monthly;添加order by子句后,同个产品名称的销量平均值显示为逐行增加,如下图所示:product为桔子的第一个月份平均值显示为10154.000000,第二个月份平均值显示为10168.500000【(10154.00+10183.00)/2】,第三个月份平均值显示为10194.000000【(10154.00+10183.00+10245.00)/3】,以此类推...
frame_clause(指定窗口大小)
作用:用于指定一个移动的分析窗口,窗口总是位于分区的范围之内,是分区的一个子集。在指定了分析窗口之后,窗口函数不再基于分区进行分析,而是基于窗口内的数据进行分析
注:分析窗口的大小不会超过当前分区范围,每个窗口函数支持的窗口大小选项不同
【rows | range】 frame_start
【rows | range】 between frame_start and frame_end
rows:表示以数据行为单位计算窗口的偏移量
range:表示以数值(例如10天)为单位计算窗口的偏移量
frame_start:定义窗口的起始位置,可以指定以下内容之一
unbounded preceding:表示从窗口分区的第一行开始
n preceding:表示窗口从当前行之前的第N行开始
current row:表示窗口从当前行开始
frame_end:定义窗口的结束位置,可以指定以下内容之一
current row:表示窗口从当前行结束
m following:表示窗口到当前行之后的第m行结束
unbounded following:表示窗口到分区的最后一行结束
eg:
按照不同产品名称统计当前月、当前月的前两个月 销量平均值,同个产品名称按照时间从低到高排序
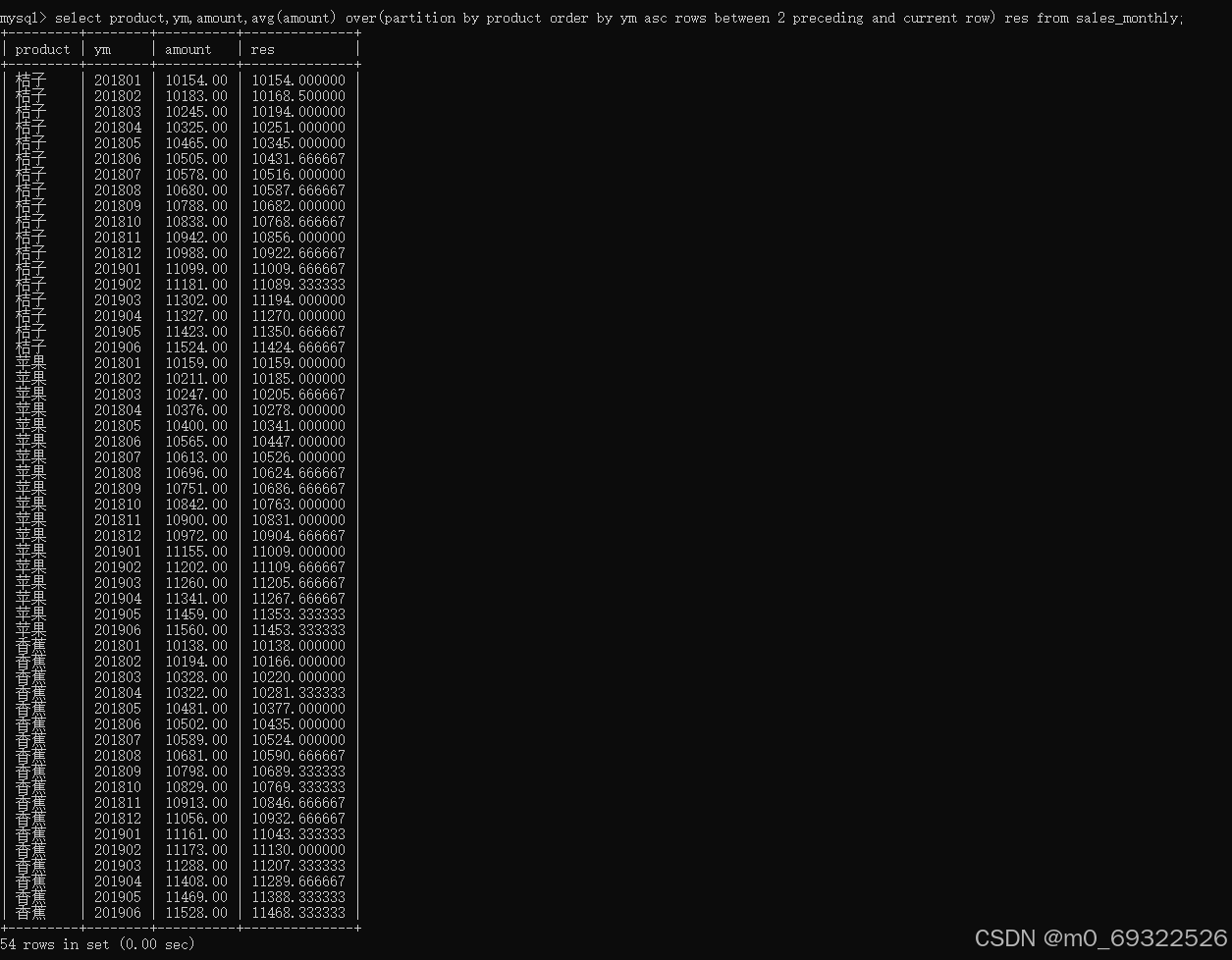
select product,ym,amount,avg(amount) over(partition by product order by ym asc rows between 2 preceding and current row) res from sales_monthly;如下图所示:product为桔子的第一个月份及前两个月平均值显示为10154.000000(表中数据201801前两个月月份没有数据),第二个月份平均值显示为10168.500000【(10154.00+10183.00)/2】(表中数据201802只有前一个月数据),第三个月份平均值显示为10194.000000【(10154.00+10183.00+10245.00)/3】,第四个月份平均值显示为10251.000000【(10183.00+10245.00+10325.00)/3】以此类推...
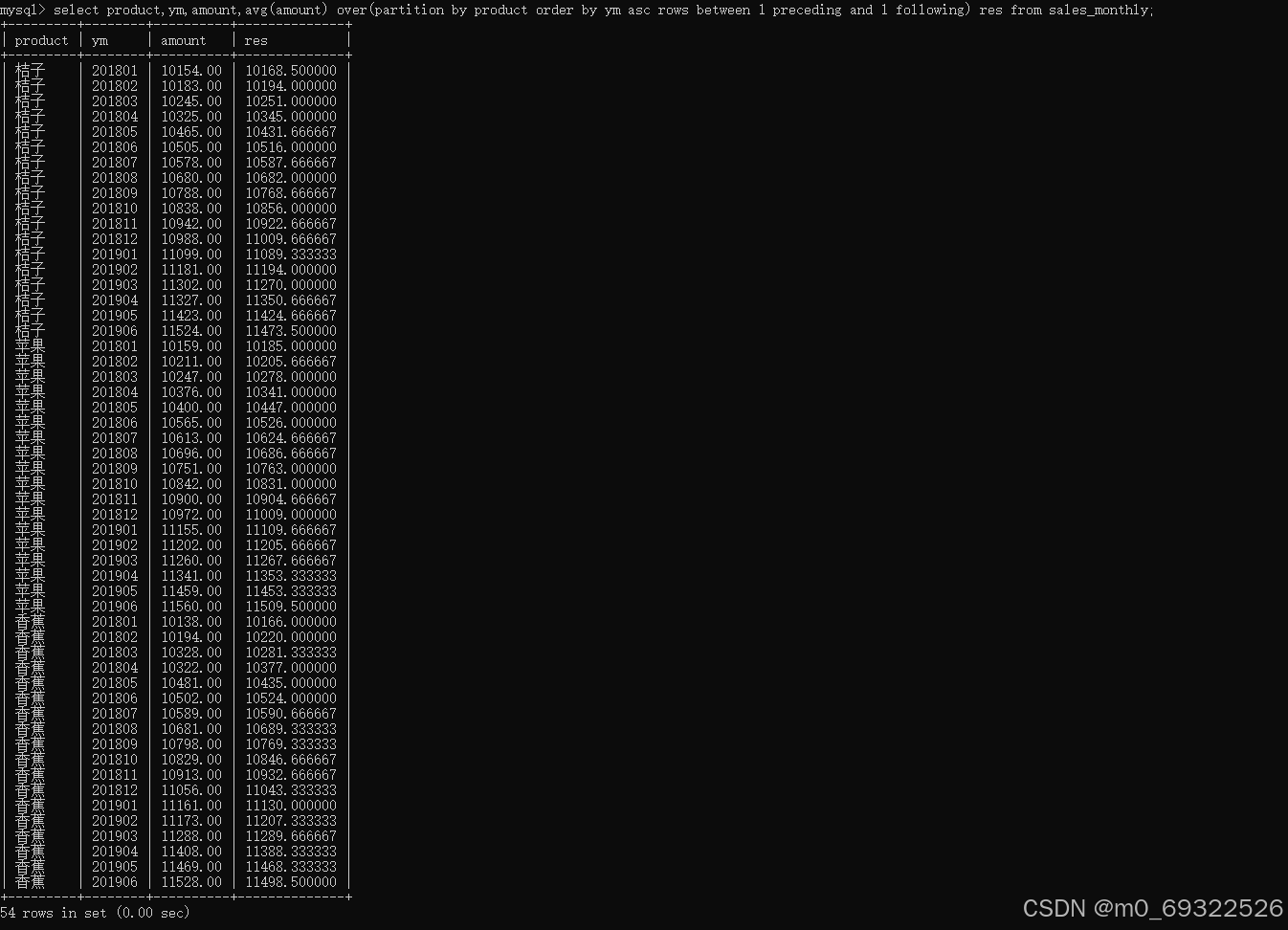
按照不同产品名称统计当前月、当前月的前一个月、当前月的后一个月 销量平均值,同个产品名称按照时间从低到高排序
select product,ym,amount,avg(amount) over(partition by product order by ym asc rows between 1 preceding and 1 following) res from sales_monthly;如下图所示:product为桔子的第一个月份及前后一个月平均值显示为10168.500000【(10154.00+10183.00)/2】(表中数据201801前一个月月份没有数据),第二个月份平均值显示为10194.000000【(10154.00+10183.00+10245.00)/3】,第三个月份平均值显示为10251.000000【(10183.00+10245.00+10325.00)/3】以此类推...
排名窗口函数
作用:用来获取数据的分类排名,不支持动态的窗口大小选项,以整个分区作为分析的窗口
常见窗口函数:
row_number:为分区的每行数据分配一个序列号,序列号从1开始
rank:返回当前行在分区中的名次,如果存在名次相同的数据,后续的排名将会产生跳跃
dense_rank:返回当前行在分区中的名次,即使存在名次相同的数据,后续的排名也是连续值
percent_rank:以百分比的形式返回当前行在分区中的名次,如果存在名次相同的数据,后续排名将会产生跳跃
cume_dist:计算当前行在分区内的累积分布,指排名在当前行之前(包括当前行)所有数据所占的比率,取值范围大于0且小于或等于1
ntile:将分区内的数据分为n等份,并返回当前行所在的分片位置
eg:
row_number、rank、dense_rank、percent_rank
查询不同部门的薪资排名
window:定义一个窗口
select name,dept_id,salary,
row_number() over(partition by dept_id order by salary desc) rn,
rank() over(partition by dept_id order by salary desc) rk,
dense_rank() over(partition by dept_id order by salary desc) dr,
percent_rank() over(partition by dept_id order by salary desc) pr
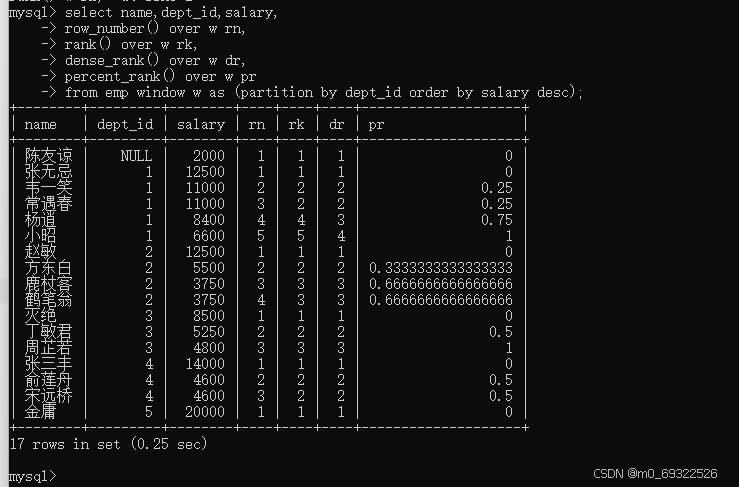
from emp;select name,dept_id,salary,
row_number() over w rn,
rank() over w rk,
dense_rank() over w dr,
percent_rank() over w pr
from emp window w as (partition by dept_id order by salary desc);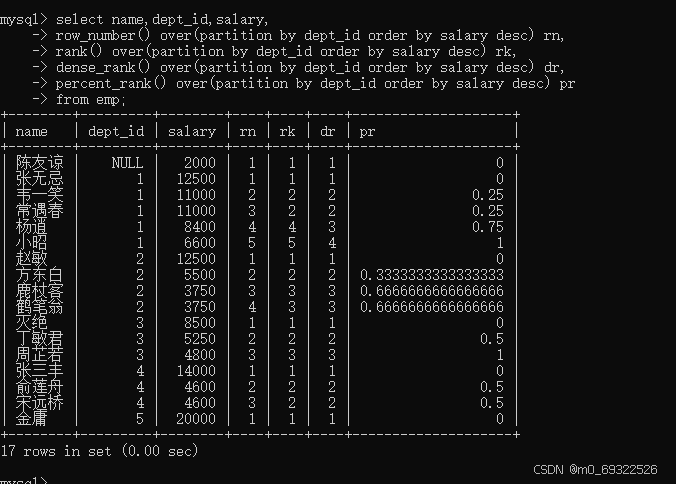
cume_dist(当前行数据所占的比率)
查看不同薪资在整个公司的占比
select name,dept_id,salary,cume_dist() over (order by salary) from emp;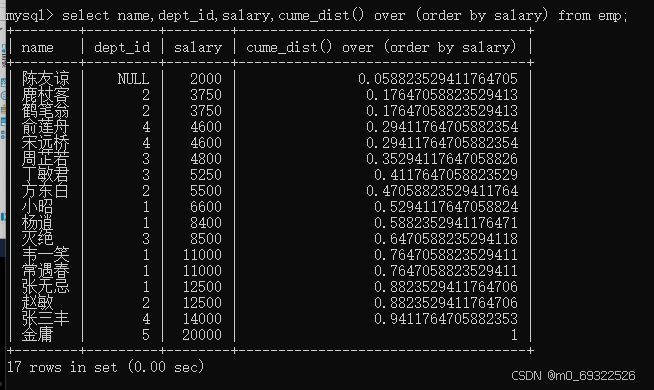
ntile(获取前行所在的分片位置)
将员工薪资从低到高分为5等份,查看不同薪资员工所在的等份
select name,dept_id,salary,ntile(5) over (order by salary) from emp;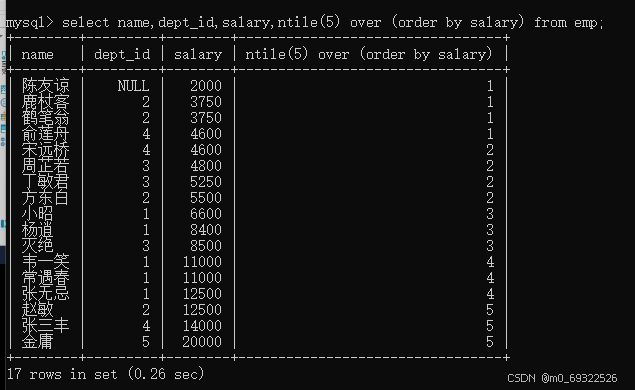
取值窗口
作用:返回窗口内指定位置的数据行
常见函数:
lag:返回窗口内当前行之前的第n行数据,不支持动态的窗口大小选项,以整个分区作为分析的窗口
lead:返回窗口内当前行之后的第n行数据,不支持动态的窗口大小选项,以整个分区作为分析的窗口
first_value:返回窗口内的第一行数据
last_value:返回窗口内最后一行数据
nth_value:返回窗口内第n行数据
eg:
lag(字段名,当前行之前的第n行数据)
对比不同产品当前月与当前月的上一个月销售金额
select *,lag(amount,1) over (partition by product order by ym) pre_amount from sales_monthly;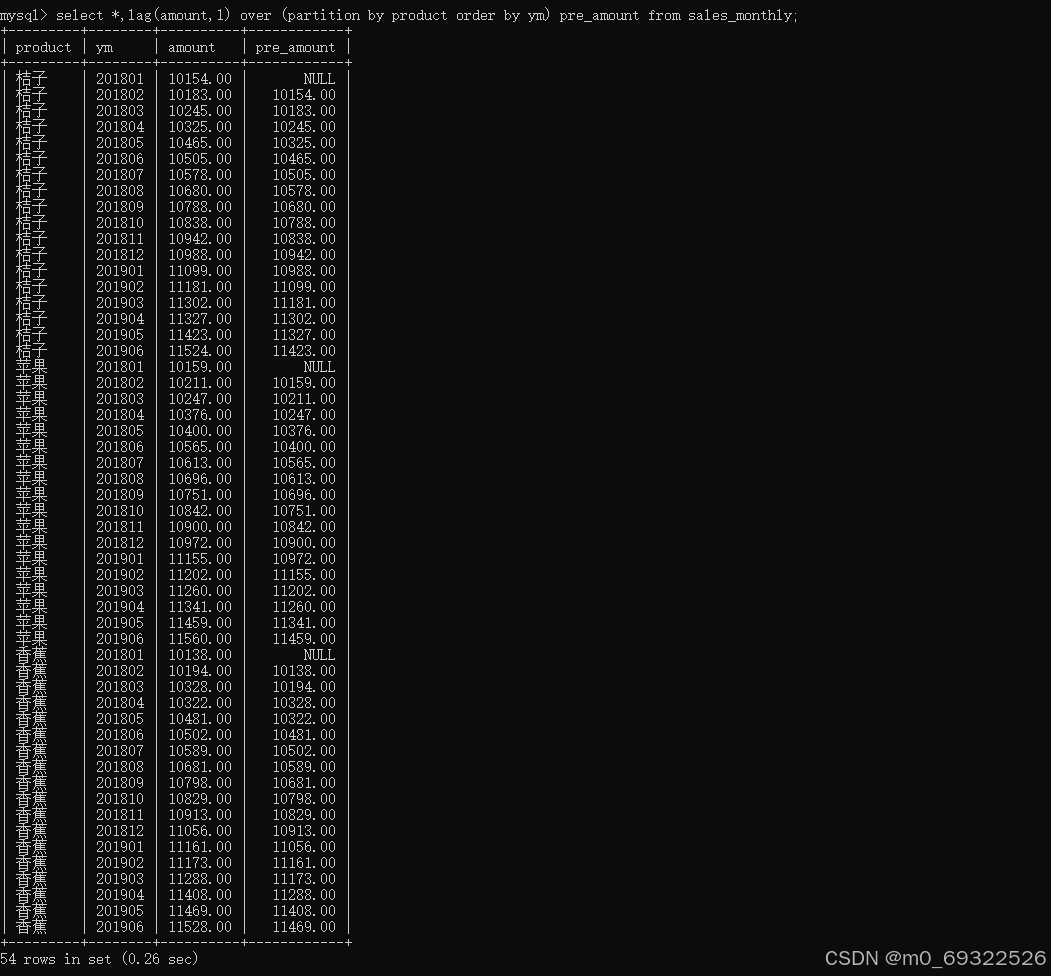
lead(字段名,当前行之后的第n行数据)
对比不同产品当前月与当前月的下一个月销售金额
select *,lead(amount,1) over (partition by product order by ym) pre_amount from sales_monthly;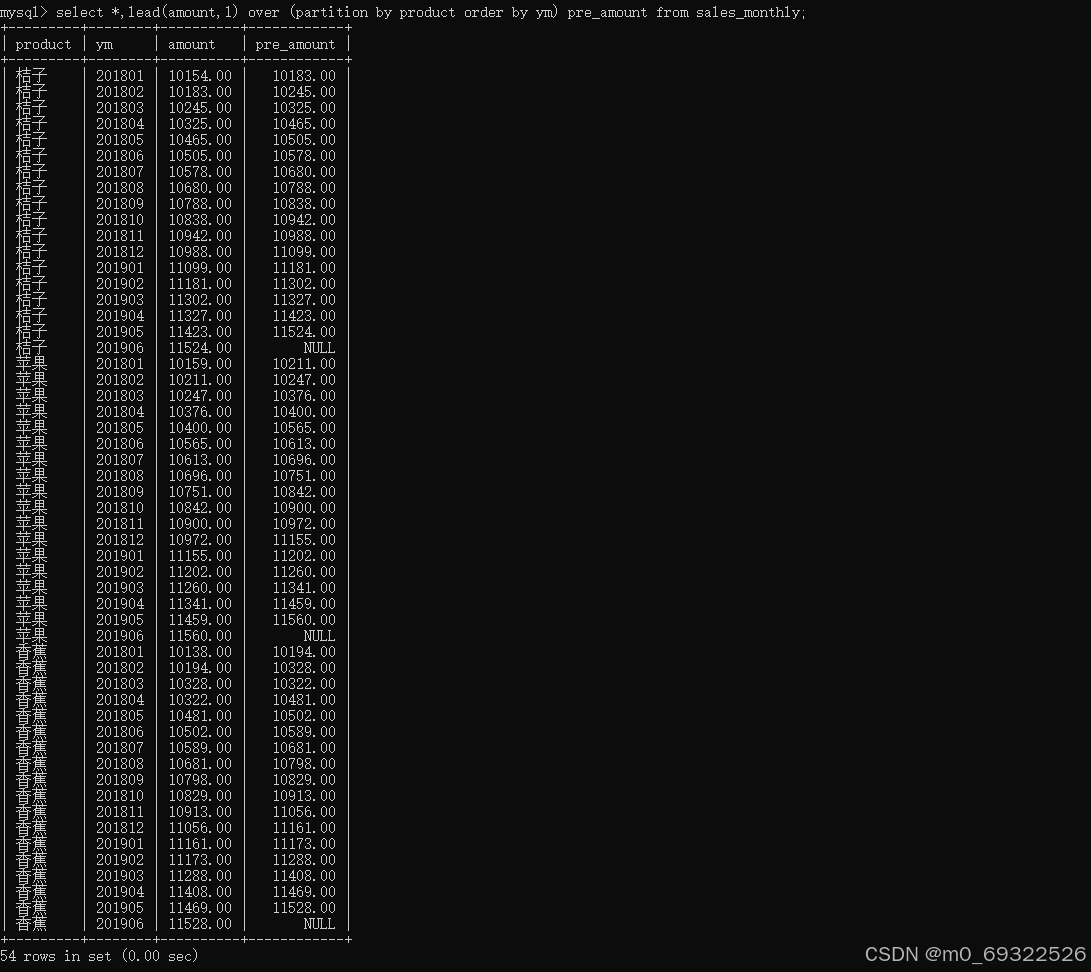
first_value(返回窗口内的第一行数据)
select *,first_value(amount) over (partition by product order by ym) pre_amount from sales_monthly;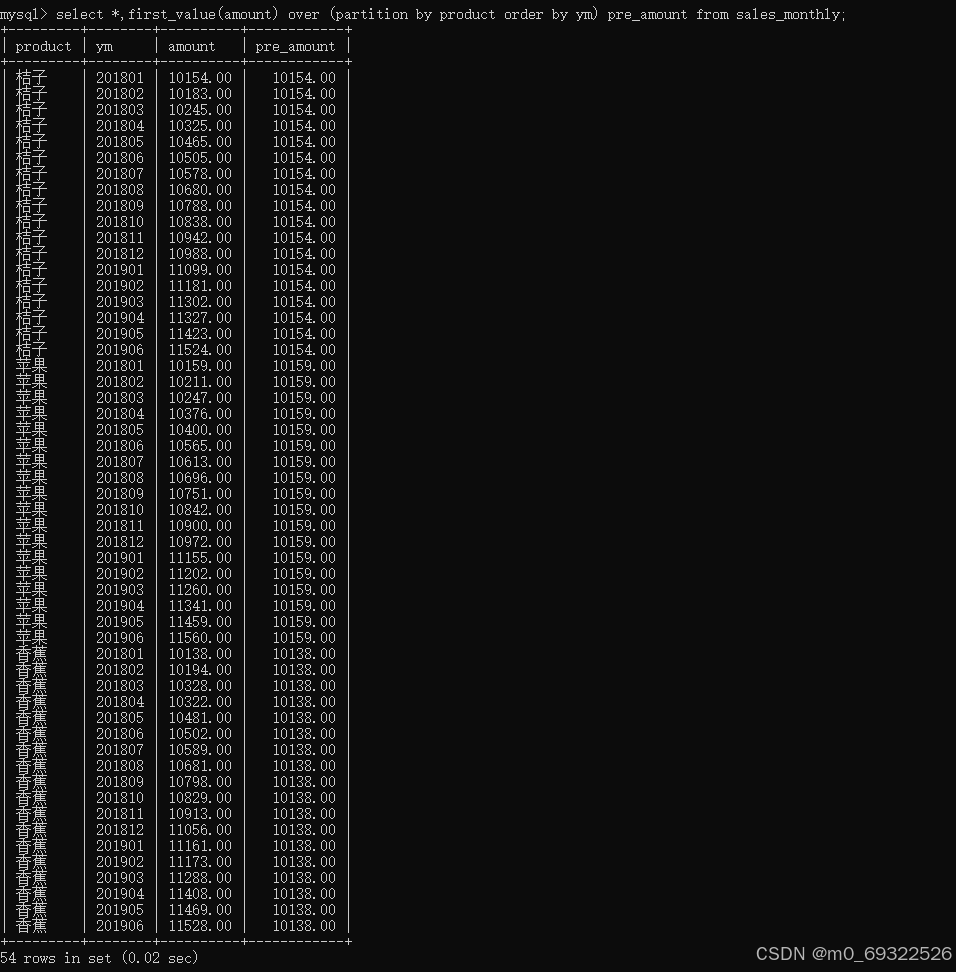
last_value(返回窗口内最后一行数据)
select *,last_value(amount) over (partition by product order by ym) pre_amount from sales_monthly;
nth_value(返回窗口内第n行数据)
select *,nth_value(amount,4) over (partition by product order by ym) pre_amount from sales_monthly;
数据准备
create table sales_monthly(product VARCHAR(20) comment '产品名称', ym VARCHAR(10) comment '年月', amount NUMERIC(10, 2)) comment '销售金额(元)';INSERT INTO sales_monthly (product,ym,amount) VALUES
('苹果','201801',10159.00),
('苹果','201802',10211.00),
('苹果','201803',10247.00),
('苹果','201804',10376.00),
('苹果','201805',10400.00),
('苹果','201806',10565.00),
('苹果','201807',10613.00),
('苹果','201808',10696.00),
('苹果','201809',10751.00),
('苹果','201810',10842.00),
('苹果','201811',10900.00),
('苹果','201812',10972.00),
('苹果','201901',11155.00),
('苹果','201902',11202.00),
('苹果','201903',11260.00),
('苹果','201904',11341.00),
('苹果','201905',11459.00),
('苹果','201906',11560.00),
('香蕉','201801',10138.00),
('香蕉','201802',10194.00),
('香蕉','201803',10328.00),
('香蕉','201804',10322.00),
('香蕉','201805',10481.00),
('香蕉','201806',10502.00),
('香蕉','201807',10589.00),
('香蕉','201808',10681.00),
('香蕉','201809',10798.00),
('香蕉','201810',10829.00),
('香蕉','201811',10913.00),
('香蕉','201812',11056.00),
('香蕉','201901',11161.00),
('香蕉','201902',11173.00),
('香蕉','201903',11288.00),
('香蕉','201904',11408.00),
('香蕉','201905',11469.00),
('香蕉','201906',11528.00),
('桔子','201801',10154.00),
('桔子','201802',10183.00),
('桔子','201803',10245.00),
('桔子','201804',10325.00),
('桔子','201805',10465.00),
('桔子','201806',10505.00),
('桔子','201807',10578.00),
('桔子','201808',10680.00),
('桔子','201809',10788.00),
('桔子','201810',10838.00),
('桔子','201811',10942.00),
('桔子','201812',10988.00),
('桔子','201901',11099.00),
('桔子','201902',11181.00),
('桔子','201903',11302.00),
('桔子','201904',11327.00),
('桔子','201905',11423.00),
('桔子','201906',11524.00);create table emp
(
id int auto_increment comment 'ID' key,
name varchar(50) not null comment '姓名',
age int comment '年龄',
job varchar(20) comment '职位',
salary int comment '薪资',
entrydate date comment '入职时间',
managerid int comment '直质领导ID',
dept_id int comment '部门ID'
) comment '员工表1' ;insert into emp values
(1,'金庸',66,'总裁',20000,'2000-01-01',null,5),
(2,'张无忌',20,'项目经理',12500,'2005-12-05',1,1),
(3,'杨逍',33,'开发',8400,'2000-11-03',2,1),
(4,'韦一笑',48,'开发',11000,'2002-02-05',2,1),
(5,'常遇春',43,'开发',11000,'2004-07-09',3,1),
(6,'小昭',19,'程序员鼓励师',6600,'2004-10-12',2,1),
(7,'灭绝',60,'财务总监',8500,'2002-09-12',1,3),
(8,'周芷若',19,'会计',4800,'2006-06-02',7,3),
(9,'丁敏君',23,'出纳',5250,'2009-05-12',7,3),
(10,'赵敏',20,'市场部总监',12500,'2002-02-05',1,2),
(11,'鹿杖客',56,'职员',3750,'2006-12-05',10,2),
(12,'鹤笔翁',19,'职员',3750,'2006-05-25',10,2),
(13,'方东白',19,'职员',5500,'2002-11-05',10,2),
(14,'张三丰',88,'销售总监',14000,'2003-06-15',1,4),
(15,'俞莲舟',38,'销售',4600,'2003-07-05',14,4),
(16,'宋远桥',40,'销售',4600,'2004-09-18',14,4),
(17,'陈友谅',42,null,2000,'2010-06-16',1,null);

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









