






在实际工作中,我们经常需要更改数据库中的数据,更新数据用到的关键词是UPDATE,其基本语法是:
UPDATE 表名
SET 列名1 = 新值1, 列名2 = 新值2, ...
WHERE 条件;其中UPDATE 后面指定要更新数据的表,再用SET设置需要更新的列及其新值,可以同时更新多个列,用逗号分隔,where后面则加条件指定哪些行的数据需要被更新。例如,有如下一张Student表:
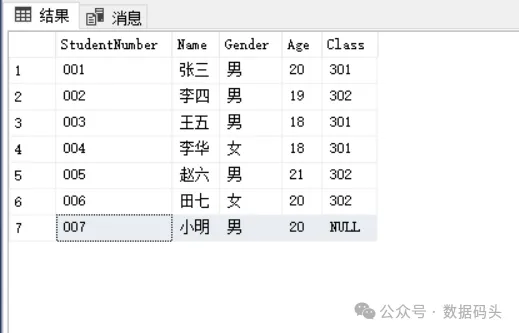
现在需要将小明的班级更新为301,同时他的年龄应该是21岁,那么可以写成:
UPDATE dbo.Student
SET Class = '301',
Age = 21
WHERE Name = '小明';如果省略了WHERE 子句,即不加任何限定条件,那么表中所有行的数据都会被更新(即所有学生的class都成了301,age都是21了),这在大多数情况下不是我们想要的结果,因此使用时需格外注意。在实际工作中,强烈建议大家在执行update之前,先将指定的条件用select语句查一遍,确保要更新的数据是对的。记得我刚开始工作的时候,害怕更新错或者删错数据,每次update或者delete都在事务中进行,确保没问题后再提交(事务我后面会介绍)。
上面是update的基本用法,也还有其他的情况,比如where后面所接的指定条件,可以是大于某个数或者在某个范围内,或者跟一个子查询等等,即这里where后面能写的条件跟select中是类似的。因为更新前,先将需要更新的数据筛选出来,再执行更新操作。例如将所有不及格同学的成绩都改为60分,可以写成:
UPDATE dbo.Score
SET Score = 60
WHERE Score < 60;更新后的值也可以是一个表达式,而非某个具体的值,例如将学号001同学所有课程的分数都加上10分,可以写成:
UPDATE dbo.Score
SET Score = Score + 10
WHERE StudentNumber = '001';要提醒的一点是:更新某条数据时,各列是同一时间更新的,例如有下面一个SQL:
UPDATE dbo.T
SET colA= colA + 10 , colB =colA+10;执行完之后,colA和colB的结果是一样的,并不是说colB在A已经加了10的基础上再执行加10。
联表更新:
在查询数据的时候,如果要的数据是通过不同的条件指定的,这些条件并不在同一张表中,我们需要将多表关联进行查询。同理,如果在更新数据的时候,给我们的条件也不全在同一张表中,我们就需要联表来进行更新。例如,Score表数据结构如下:
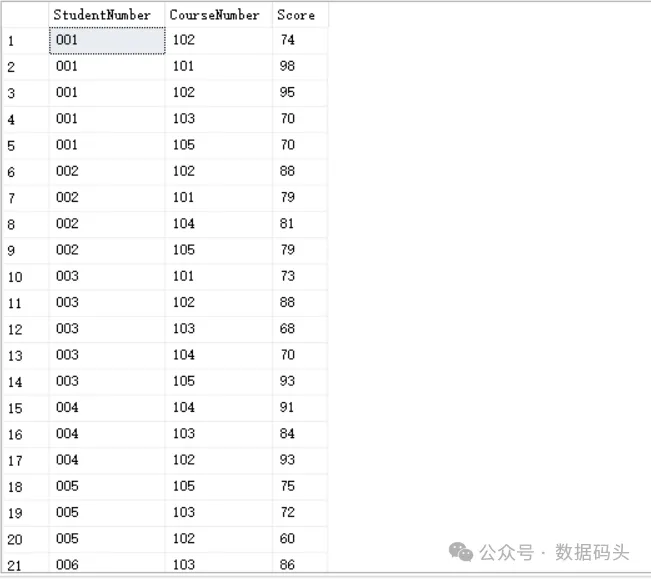
现要求将李华同学 操作系统这门课程 的成绩加一分,应该怎么写SQL呢?
我们肯定要找到他对应的学号和操作系统这门课程的编号是多少,因为Score表里有的只是编号而没有具体的值或课程名。(为什么不在Score表里存这些具体的值呢?这在后面表的设计原则中会介绍)。
所以我们可以分3步,查“李华”的StudentNumber--->查“操作系统”对应的CourseNumber--->再将这两次查到的结果放在update语句where后面的条件中。只是有点繁琐,可以用联表更新将这3步合为一步,即:
UPDATE A
SET A.Score = A.Score + 1
FROM dbo.Score AS A
INNER JOIN dbo.Student AS B
ON B.StudentNumber = A.StudentNumber
INNER JOIN dbo.Course AS C
ON C.CourseNumber = A.CourseNumber
WHERE B.Name = '李华'
AND C.Name = '操作系统';写上面这个SQL的逻辑也是建立在多表关联查询的基础上,即首先写的SQL是:
SELECT A.Score
FROM dbo.Score AS A
INNER JOIN dbo.Student AS B
ON B.StudentNumber = A.StudentNumber
INNER JOIN dbo.Course AS C
ON C.CourseNumber = A.CourseNumber
WHERE B.Name = '李华'
AND C.Name = '操作系统';通过关联Student表和Course表查出我们要更新的数据,然后再将SELECT换成UPDATE,update之后是我们要更新的那个表名。通过上面使用表的别名大家应该也能看出,虽然update是写在一开始的,但是它执行的逻辑顺序却是最后。在这里补充一点关于SQL语句的执行顺序:
对于常见的查询(SELECT语句),其书写顺序如下:
-
SELECT:用于指定要查询的列。例如
SELECT column1, column2,你可以选择一个或多个列,也可以使用*来表示查询所有列。 -
FROM:指定要从哪个表中查询数据。例如
FROM table_name,这是数据来源的表。 -
WHERE:用于对数据进行筛选,添加条件来过滤数据。例如
WHERE column1 = value,只有满足条件的行才会被返回。 -
GROUP BY:用于对结果集进行分组。例如
GROUP BY column1,通常和聚合函数(如COUNT()、SUM()等)一起使用,对每个分组进行操作。 -
HAVING:在分组后对分组进行筛选,它和WHERE的区别在于HAVING是针对分组后的结果进行筛选,而WHERE是对原始数据进行筛选。例如
HAVING COUNT(column1) > 10。 -
ORDER BY:用于对结果集进行排序。例如
ORDER BY column1 ASC(升序,默认)或ORDER BY column1 DESC(降序),可以指定一个或多个列进行排序。
但SQL语句的执行顺序和书写顺序有所不同,主要的执行顺序是:
-
FROM:首先确定数据来源的表,这是整个查询的基础,即要查哪张表。数据库会加载指定的表,为后续的操作提供数据源。
-
WHERE:在确定了表之后,再对表中的数据进行筛选,根据WHERE子句中的条件过滤出符合条件的行。这一步可以减少后续操作的数据量,提高查询效率。
-
GROUP BY:对WHERE筛选后的结果集进行分组操作。按照指定的列将数据分成不同的组,为后续的聚合操作做准备。
-
聚合函数(如在SELECT中使用的COUNT、SUM等):在分组的基础上,对每个分组应用聚合函数进行计算。例如计算每个分组的行数、总和等。
-
HAVING:对分组后的结果进行筛选。这是在聚合函数计算之后进行的,根据HAVING子句中的条件过滤分组。
-
SELECT:最后确定要返回的列。此时已经完成了数据的筛选、分组和聚合等操作,根据SELECT子句指定的列从最终的结果集中提取数据。
-
ORDER BY:对最终的结果集进行排序。这是最后一步,根据指定的列对结果进行升序或降序排列。
执行顺序对理解SQL语句的运行非常有帮助!
说回更新语句,首先是要查询到需要更新的数据,即确定表--->筛选行--->计算新值(set语句)--->再更新数据。
关于update更新数据的知识,大概就这么多,大家需要掌握:
1.更新单列、更新多列
2.不同的限定条件来更新数据
3.基于表达式更新
4.表关联更新
最后还想重复一句,执行update的时候一定要慎重,不要忘记where限定条件,最好先将更新语句中指定的条件用select语句查一遍,确保要更新的数据是对的(后面说删除也是同理),在实际工作中如果弄错重要数据,后果很严重。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









