






目录
简介
JDBC 就是使用 Java 代码来操作数据库。市面上有很多种数据库,其中每种数据库都有着自己的一套 API,Java 为了方便,统一所有数据库都来实现 JDBC 这套API,使得所有类型的数据库在Java 中都可以按照 JDBC 这套 API 提供的方式来操作。
JDBC 是一套 API,而不同的数据库又有自己的一套 API,因此使用 JDBC 操作数据库的时候,就需要进行 API 之间的转化,数据库厂商就提供了专门的代码来进行转化——数据库驱动包( 作用类似于翻译官 )

具体操作
此处使用 MySQL 作为示例:
1. 引入驱动包
1)下载驱动包
首先,我们需要下载 MySQL 的驱动包。可以从多种渠道,例如官方网站,Github( 如果是一个开源项目 ),其中最方便的就是在 Maven 中央仓库中进行下载:https://mvnrepository.com/
在搜素框中搜索需要的数据库,然后选择所需的版本,注意大版本需要和数据库服务器版本保持一致,小版本无所谓( 小数点后的版本号 )。然后点击类似下图中的位置进行下载:

2)引入驱动包到项目中
下载完成之后,需要引入到我们现有的项目中( 下述是以一个最普通的项目来作为示例 ):
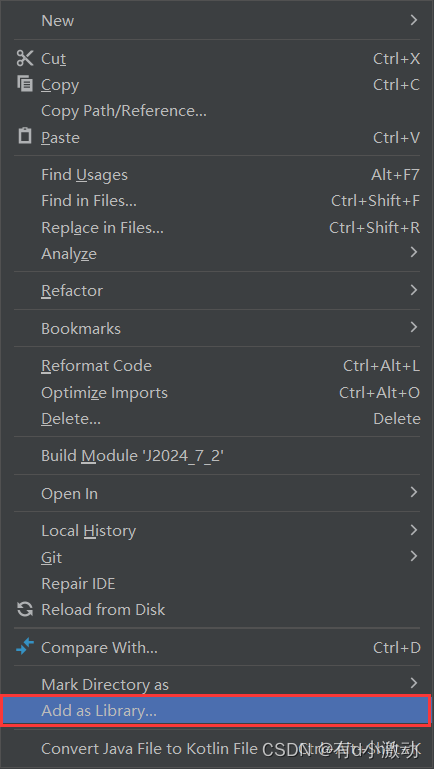
创建一个专门存放依赖包的目录,一般命名为 lib,将 jar 包放到该目录下,如果点击下图中的选项,使该目录下的 jar 包能够被正常识别:
2. 编写代码
1)创建数据源
数据源指明了我们的数据库服务器地址,具体代码如下:
DataSource dataSource = new MysqlDataSource();
((MysqlDataSource)dataSource).setUrl("jdbc:mysql://127.0.0.1:3306/testTable?characterEncoding=utf8&useSSL=false");
((MysqlDataSource)dataSource).setUser("root");
((MysqlDataSource)dataSource).setPassword("root");DataSource 是 JDBC 提供的一个 interface,MysqlDataSource 是 MySQL 驱动包提供的类,该类实现了 DataSource 这个 interface。上述调用的 setUrl、setUser、setPassword 方法都是MysqlDataSource 这个子类的方法,因此调用之前需要进行向下转型。
上述转型的写法是推荐写法,虽然下述写法是更方便的写法,但是转型的目的是希望不要让MysqlDataSource 这个类扩散到其他代码,其他代码使用 datasource 对象时,仍然是一个JDBC 提供的 DataSource 类的对象而不是一个 MySQL 驱动包提供的 MysqlDataSource 类的对象,降低 MySQL 驱动包和项目代码的耦合程度,后续方便更换数据库。
MysqlDataSource dataSource = new MysqlDataSource();
dataSource.setUrl("jdbc:mysql://127.0.0.1:3306/testTable?characterEncoding=utf8&useSSL=false");
dataSource.setUser("root");
dataSource.setPassword("root");
上述的 setURL 中的参数是一个固定模板,其中每个部分的具体含义如下:
- jdbc:mysql:表明当前这个 URL 的具体用途,是给 JDBC 的 MySQL 进行使用的;
- 127.0.0.1:当前数据源指向的数据库服务器的IP地址;
- 3306:当前数据源指向的数据库服务器的上的数据库应用程序所占据的端口号;
- testTable:数据库名字;
- characterEncoding=utf8:统一字符集为utf8,避免使用中文等其他语言时出现乱码;
- useSSL=false:设置数据库服务器和客户端之间的通信是否进行加密。
2)建立连接
上述只是创建了一个数据源,真正连上数据库还需要创建一个和数据库服务器的连接:
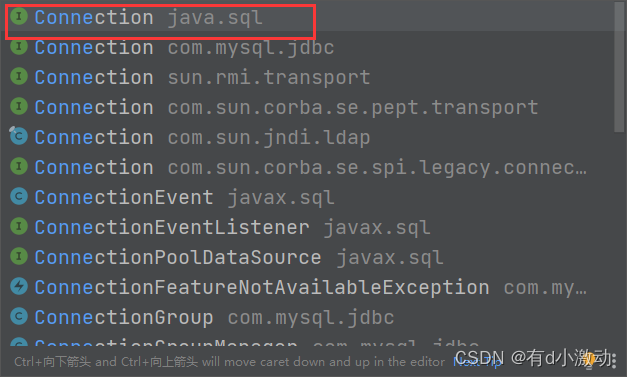
Connection connection = dataSource.getConnection();注意上述的Connection类需要导入的是JDBC下的类:
3)构造 SQL 语句
假设现在有一个表中有两列:id int,name varchar(20)
String sql = "insert into student values(1, '张三')";
PreparedStatement statement = connection.prepareStatement(sql);我们在代码中创建的SQL语句本身,是 String 类型的,但是 JDBC 并不认识字符串类型的 SQL,因此 JDBC 提供了 Statement(语句)对象,可以把 String 转换成 Statement 再发给服务器执行。但是,一般会使用 PreparedStatement(预处理的语句)对象来代替 Statement。
这二者的区别是:
- Statement 是把 SQL 直接发给数据库服务器,数据库服务器来负责解析 SQL;
- PreparedStatement 会先在客户端这边初步解析一下 SQL( 验证语法格式是否符合要求啥的 ),此时服务器就不用做这些检查了,从而降低服务器的负担。
除了上述这种写死的语句,也可以动态构造 SQL 语句:
注意下述这种写法:
String sql = "insert into student values(" + id + ", '" + name + "')";
PreparedStatement statement = connection.prepareStatement(sql);虽然这种写法也可以,但是存在问题:可读性低,代码混乱和存在SQL注入风险。
因此更推荐下述写法:
String sql = "insert into student values(?, ?)";
PreparedStatement statement = connection.prepareStatement(sql);
statement.setInt(1, id);
statement.setString(2, name);具体步骤:
- 使用" ? "来作为参数的占位符
- 使用特定的 setXXX 方法,来设置占位符所需要的变量。注意此处的的占位符顺序是从 1 开始的。执行过程中,setXXX 方法会对参数进行严格校验,避免了 SQL 注入问题。
4)执行 SQL 语句
执行 SQL 语句时,有两个方法可以选择:
executeQuery:用于执行写操作,用于执行查询语句。其中返回值是 ResultSet,是一个临时表格。当我们拿到结果集的时候,就需要遍历这个临时表格。
ResultSet resultSet = statement.executeQuery();
while (resultSet.next()) {
int id = resultSet.getInt("id");
String name = resultSet.getString("name");
}使用 resultSet.next() 方法效果如下:
1)存在一个光标,初始位置指向临时表的第一行记录的前面;
2)每次执行 next 方法,光标都会往下走,如果存在记录返回 true,否则返回 false。如果存在记录则可以拿到该行记录中的每一列,具体是使用该列的数据类型对应的 getXXX 方法,传入列名来获取。
executeUpdate:用于执行写操作,用于执行增加、删除、修改语句。其中返回值就是影响的行数。
int n = statement.executeUpdate();5)释放资源
创建的语句对象和连接对象等,都会持有一些计算机的 硬件 / 软件 上的资源,这些资源不用了就需要及时释放。注意关闭顺序:先创建的后关闭。
resultset.close();
statement.close();
connection.close();总结
上述就是使用 JDBC 的全部流程,整体过程相对比较繁琐,因此大佬们针对 JDBC 操作进行进一步封装,得到了一些针对数据库操作的框架,统称为 ORM,例如:Mybatis、Mybatis-plus。但是这些框架的背后原理还是使用 JDBC。















 1583
1583

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









