







今天开讲dfs:
目录
dfs简述:

如果说每次递归只有两个分支,那么如下图所示
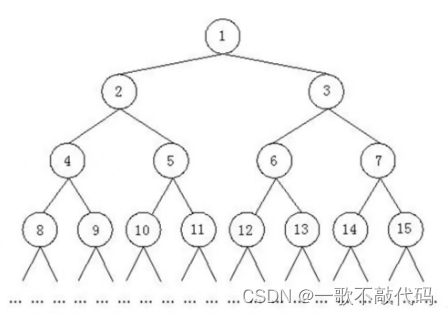
遍历顺序为:1-2-4-8-9-5-10-11-3-6-12-13-7-14-15,对吧!这个节点号是二叉树的节点,相当于先序遍历二叉树
下面,就给出模板了啊
// dfs(回溯模板)
void dfs(int k){
if(所有东西已经选完了){
判断最优解/记录答案;return;
}
for(枚举填的所有情况){
if(如果这个情况是合法的){ //保存现场和恢复现场的就是回溯思想(试错了就恢复然后试下一个情况)
记录下这个情况(保存现场)
dfs(k+1);
取消这个情况(恢复现场)
}
}
}
回溯是啥呢?回溯就相当于是回来的时候再去做的事情,比如dfs_topo,比如恢复现场避免影响下次dfs。就是写在dfs后面的操作
划重点:
dfs思想我们常常有搜索和递推两个用途:对于搜索dfs还可以剪枝操作加快速度,对于递推操作也可以记忆化达到和动归一样的效率 。(我们后面再讲)
但是!这个回溯一般太慢了,我们一般在判断一个情况成立不成立的时候,往往用下面这个更快的dfs模板
//bool dfs模板 (适用于寻找有唯一的答案)
bool dfs(cnt){
if(cnt==max) return true; //找到答案就返回true。若最内层的cnt==max时返回了true,就会一路绿灯返回true到最外层然后瞬间结束dfs
for(int i=0;i<n;i++){
if(vis[i]) continue;
vis[i]=1;
if(check()&&dfs(cnt+1)) return true;//先让当前的满足条件,再让后面的都满足条件(模板)
vis[i]=0;
if(判错)return false; //在for循环内的false和true有着同样的迅速传递效果
}
return false; //最终的false
}这个模板在处理判断类题目时候,效率超超超级好。(不过,今天我们先讲上面那个)
好的,Action!
我们先来做一道全排列的题吧!
全排列
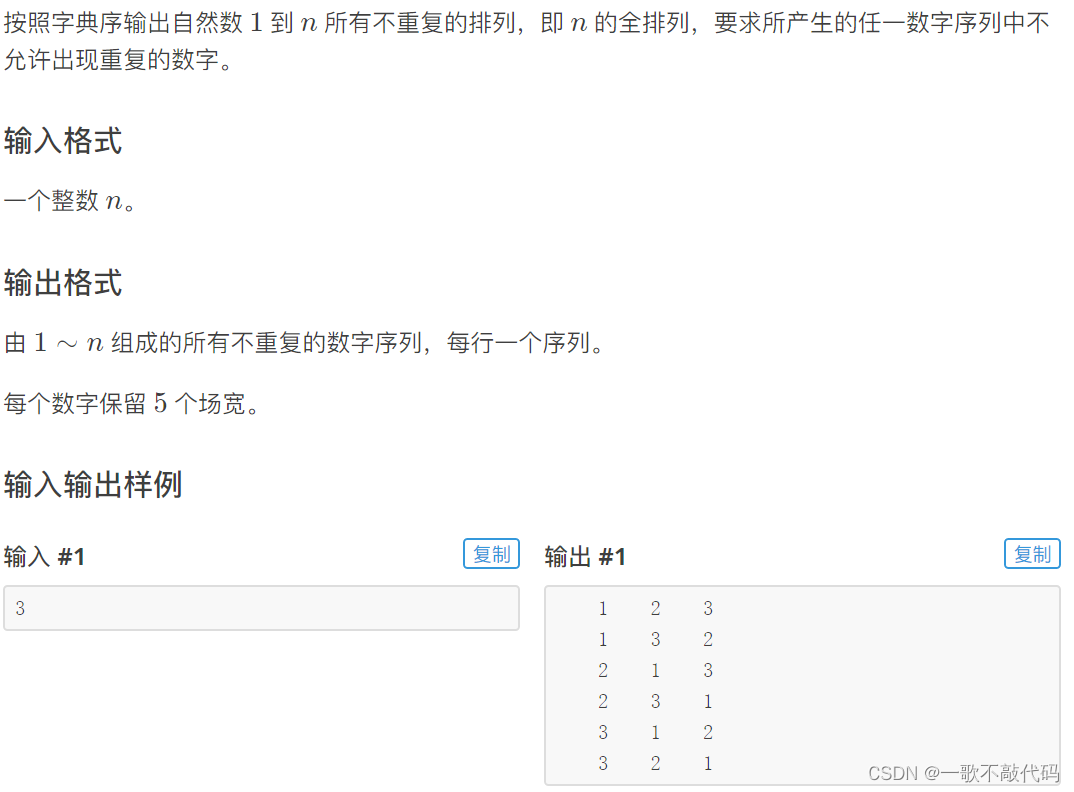
思路:
dfs+回溯即可
#include <iostream>
using namespace std;
int a[10],n; //最大为9
bool vis[10]; //标记被访问的数
void dfs(int cnt){
if(cnt==n+1){ //cnt为几就说明要处理第几个数,为n+1就代表要结束了
for(int i=1;i<=n;i++)printf("%5d",a[i]);
cout<<'\n';return ;
}
for(int i=1;i<=n;i++){ //我们不用设置upx是因为1,2,3和3,2,1是不一样的
if(!vis[i]){
vis[i]=true;a[cnt]=i; //对访问的标记
dfs(cnt+1);//处理下一个数
vis[i]=false; //解除标记,因为这个数现在不处理它了
}
}
}
int main(){
cin>>n;
dfs(1);//从第一个数开始处理
return 0;
}最终效果:
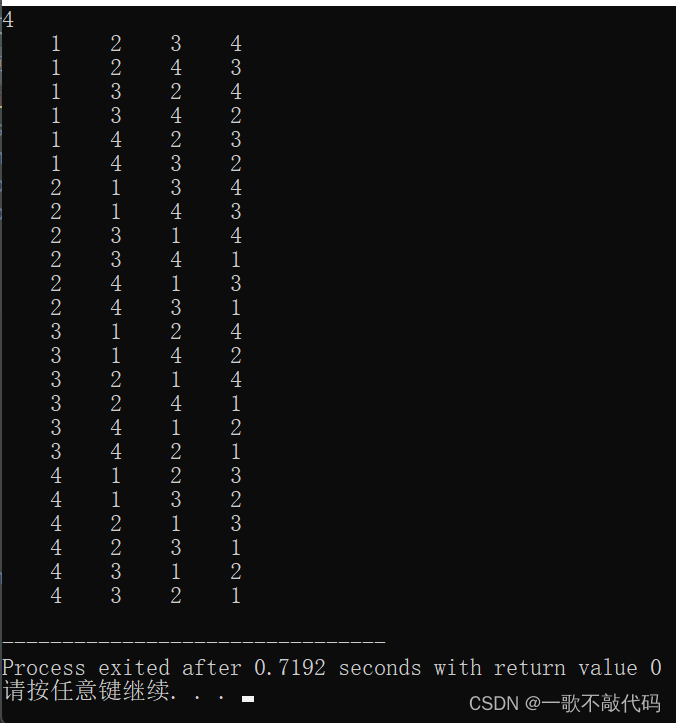
好的,非常完美!
然后,我们再来一道组合的题:
组合

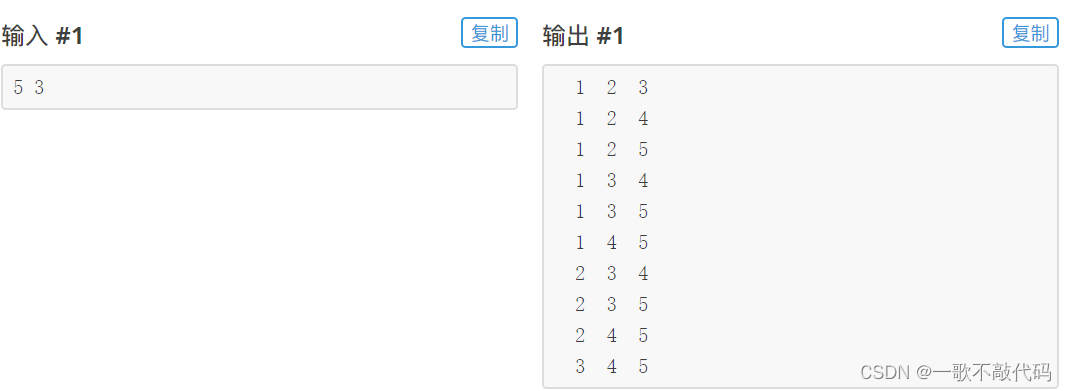
思路:
哎呀,直接上代码算了
#include <iostream>
using namespace std;
int n,k,a[21];
void dfs(int cnt,int upx) //cnt表示已选的个数,upx表示已经使用的最大下标,防止重复
{
if(cnt==k)
{ for(int i=0;i<k;i++)printf("%3d",a[i]);cout<<'\n';return ;
}
for(int i=upx;i<=n;i++) //对于组合,我们必须保证下标是不递减才能只有一种唯一的顺序
{ a[cnt]=i;dfs(cnt+1,i+1); //保存,选下一个数
}
}
int main()
{
cin>>n>>k;
dfs(0,1);return 0;
}最终效果:
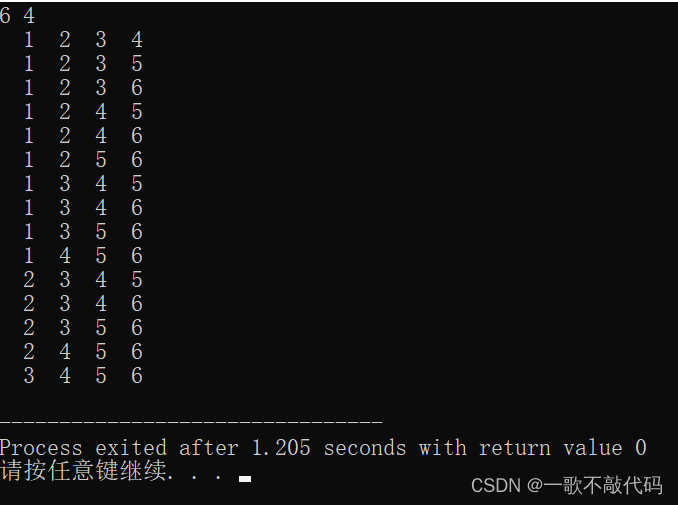
也是非常完美!你可能问: 为什么组合的递归是dfs(cnt+1,i+1),但是排列的是dfs(cnt+1) ?
这是因为排列的话我们不需要考虑数字顺序,比如1,2,3,4和1,2,4,3我们都要统计,因为这是不同的排列。但是组合就不一样了,它们可是同一个组合,我们不能都统计,所以,我们需要dfs(cnt+1,i+1),来保证下一次选的第一个数就比之前的数大,只有这样,才能保证组合的不重复(说白了,就是让它单增即可)。
好了,为什么要讲排列和组合呢,因为很多dfs题基本都是这种思想,也就是最暴力最朴素的解法。
下面的东西就有意思了:(两种常见的dfs思路)
假如我现在要计算严格单减的序列个数。易知3打头有:3;2;1;3 2;3 1;3 2 1;2 1这几个。
那么下面是dfs3的实现方式。原理是利用每个数一定都有两种状态:取和不取。
#include <bits/stdc++.h>
using namespace std;
int a[10];
void dfs3(int x,int l){
if(x==0){
for(int i=1;i<=4;i++)cout<<a[i]<<' ';
cout<<'\n';return;
}
dfs3(x-1,l);//不取
a[l]=x;
dfs3(x-1,l+1);//取
a[l]=0;
}
int main(){
dfs3(4,1);
}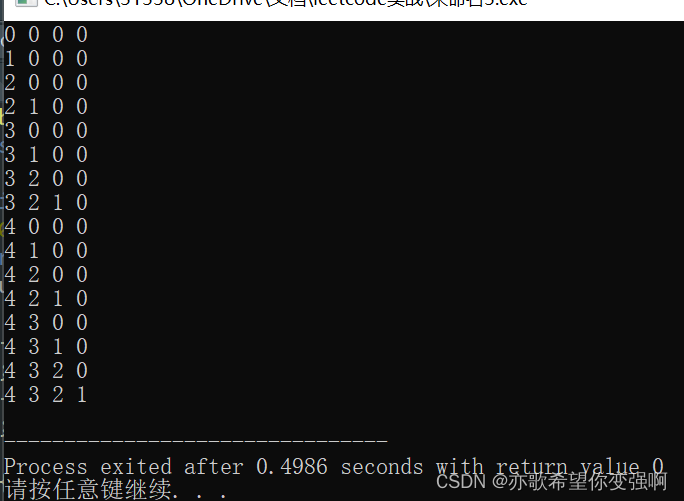
非常完美。
下面是dfs1的实现方案。原理是每层取所有可能的数。越往下层备选数越少。
void dfs1(int x,int l){
if(x==0){
for(int i=1;i<=4;i++)cout<<a[i]<<' ';
cout<<'\n';return;
}
for(int i=x;i>=1;i--){
a[l]=i;
dfs1(i-1,l+1);
a[l]=0;
}
}

不过好像结果不太对哦!
这里只需要把for拿出来就行了(你知道为什么吗?)
void dfs2(int x,int l){
for(int i=1;i<=4;i++)cout<<a[i]<<' ';cout<<'\n';
if(x==0)return ;
for(int i=x;i>=1;i--){
a[l]=i;
dfs2(i-1,l+1);
a[l]=0;
}
}

尽管两个dfs的原理并不相同,但是都达到了一样的效果,它们的速度其实都是差不多的。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









