






日常工作中,你是否遇到这些情形:你有一个想法,但不确定市场是否真的有此需求和需求的程度如何;面对大量需求,但时间和资源有限,你需要决定先满足什么需求;有了需求,怎样分辨出哪些是真需求,哪些是伪需求?怎么判断需求的优先级?
今天介绍一个可以解决用户需求分析和优先等级排序的工具,它能解决你以上的所有疑惑,它就是卡诺KANO模型。
一、KANO模型简介
卡诺模型(KANO模型)是东京理工大学教授狩野纪昭发明的对用户需求分类和优先排序的有用工具,以分析用户需求对用户满意的影响为基础,体现了产品性能和用户满意之间的非线性关系。
卡诺模型的使用场景丰富,经常用于需要确认需求是否存在、评估需求优先级、打造爆款传播要素等场景中。
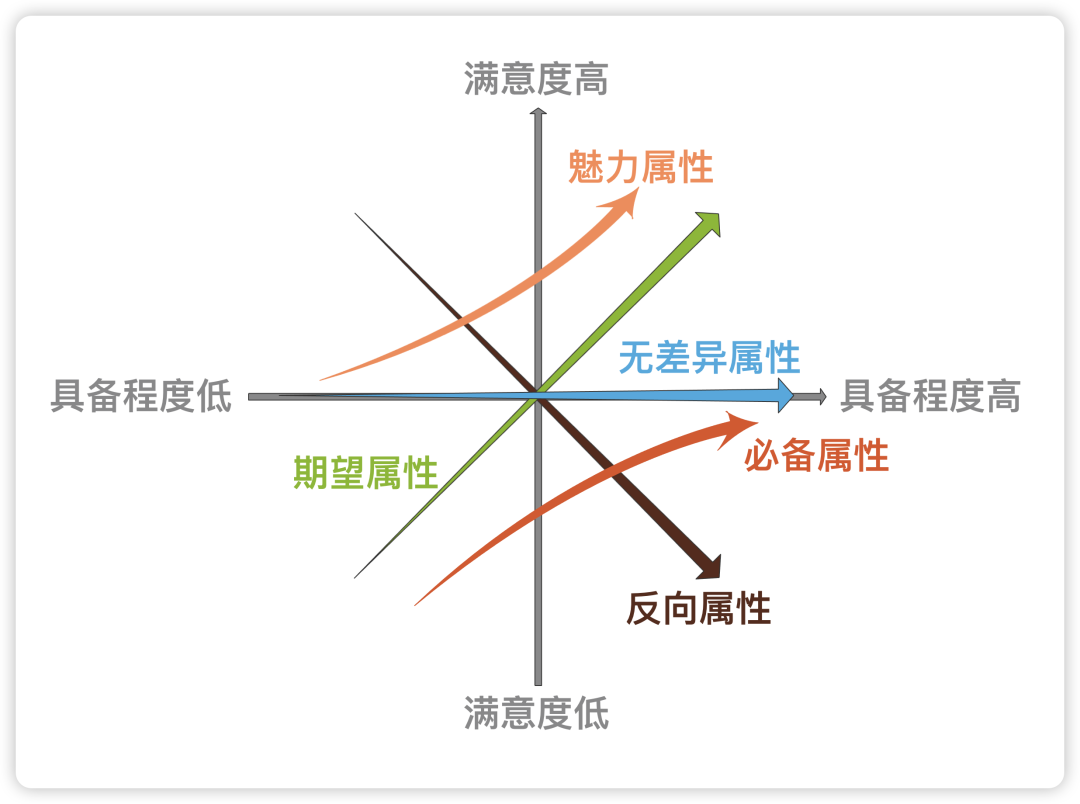
根据不同类型的质量特性与顾客满意度之间的关系,狩野纪昭将产品和服务的质量特性分为5类:必备属性、期望属性、魅力属性、无差别属性和反向属性。
点击查看模板高清原图![]() https://www.processon.com/view/6458e9d9f3388a79148411f0
https://www.processon.com/view/6458e9d9f3388a79148411f0
1、必备属性(M):这是顾客认为理所当然存在的特性或功能,如果不能满足,顾客会非常不满;但如果满足了,他们也不会因此而特别满意。
2、期望属性(O):这类需求与顾客满意度成正比关系,即提供的越多,顾客就越满意;反之,则越不满意。
3、魅力属性(A):当这种类型的需求被满足时,会给顾客带来极大的惊喜和愉悦感,但即使不提供也不会导致不满。
4、无差异属性(I):无论是否提供此类需求,对顾客来说都没有明显影响,既不会增加也不会减少他们的满意度。
5、反向属性(R):当企业提供过多此类特性时,反而会引起顾客不满。
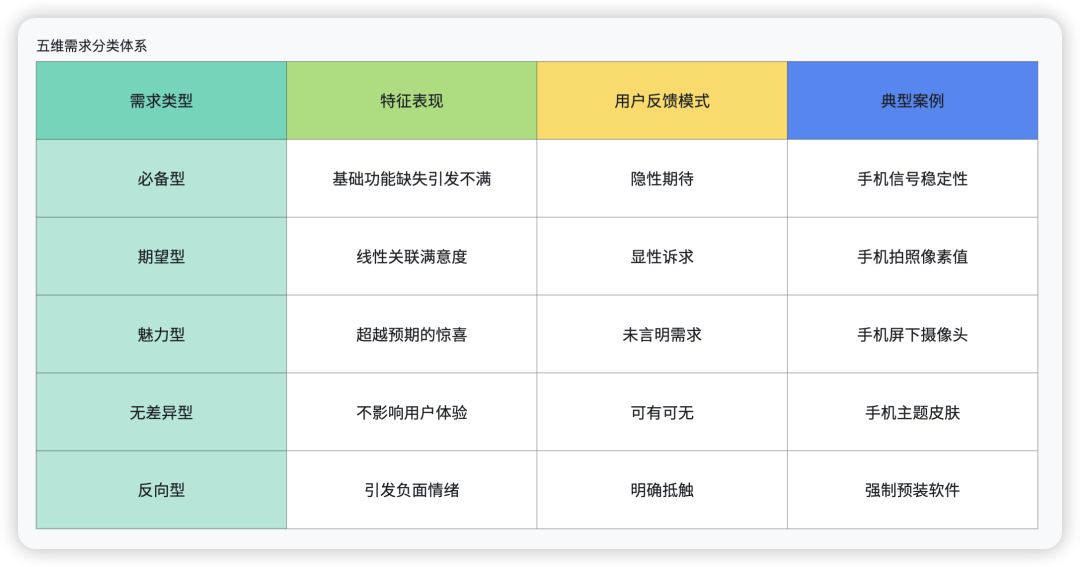
二、需求开发原则
当所有需求都在需求池里面,我们应该遵循以下原则进行开发排期:
(1)必备属性:留足资源,最优先满足;
(2)期望属性:排在第二,先做性价比更高的需求;
(3)魅力属性:尽力挖掘,先做成本低的;
(4)反向属性:避免做和商业模式无关的,同时要权衡多方利益;
(5)无差异属性:不做!
要特别注意3点:
1. 一个需求属于某种属性,只针对某一类特定用户。比如在游戏软件中,无限制地向所有用户推送广告活动,对于玩家来说是反向属性的需求,对广告主就是必备属性。
2.注意文化差异。比如在日用品领域,日本用户将包装精美归为必备属性,其他国家用户可能将其归为期望属性。
3. 需求属性,具有时效性。例如在智能手机还没普及的年代,在手机上播放视频是一个魅力属性。而现在,则是必备属性。所以当我们说一个需求属于「无差异需求」时,应该说的是「现阶段」不做。
二、如何使用KANO模型?
1.明确目的
做之前,必须明白调研的目的是什么,是否合适用KANO模型解决,为什么要用KANO 模型解决。
2.设计调研问卷
在判断需求属于那种类型,一般采用问卷调查的方式进行收集分析。在KANO模型的调查问卷中,需要对一个问题从正反两个方面进行提问,同时搭配李克特五级量表的5个选项进行选择。
比如,我们正在为一款新的智能手机设计问卷,需要确定一些关键的功能来询问用户的态度,可以这样设计调研问卷:

小Tips:设计问卷时,语言尽量简单具体,避免产生歧义。同时,可以在问卷中加入简短且明显的提示说明,方便用户顺利填写。
比如,每个人对“非常喜欢、理应如此、无所谓、勉强接受、很不喜欢”等形容词的理解都不一样,所以最好有一个统一的说明,让用户进行对照。
参考指南:
-
非常喜欢:让你感到满意、开心、惊喜。
-
理应如此:你觉得是应该的、必备的功能/服务。
-
无所谓:无所谓喜不喜欢,都可以接受。
-
勉强接受:你不喜欢,最好是没有,有的话就勉强凑活。
-
很不喜欢:让你感到不开心、甚至沮丧,无法接受。
3.数据清洗统计
数据清洗是数据分析过程中至关重要的环节,直接影响分析结果的可靠性。以下是为KANO模型应用量身定制的数据清洗专业指南:
(1)二维属性分类
在整理问卷调查结果时,可以清洗掉个别明显胡乱回答的问卷,比如全部问题都选满意度高或满意度低的,再根据官方的评价结果分类对照表将需求进行分类。
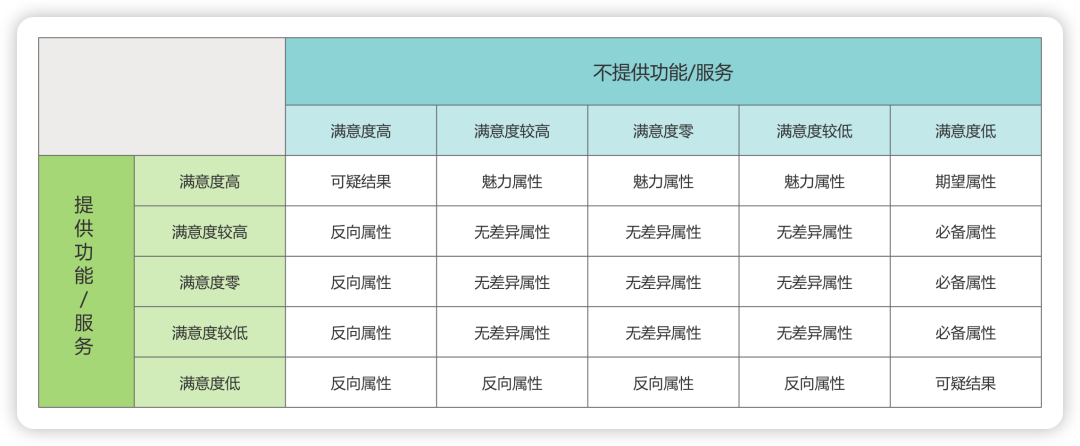
提醒:按照概念,反向属性是提供程度和用户满意度成反比,也就是产品提供了用户就不满意,所以上表只有左下角是明确的「反向属性」,其他反向属性可以考虑转为「可疑结果」,因为满意程度本身就很难衡量。
在实际工作中,建议大家不要盲目套用方法论或模型,要灵活调整,根据自己的产品、公司、地域、用户群等因素做决策。
(2)核心清洗步骤
核心清洗步骤总结为5步,仅供大家参考。
1)数据完整性审查
参考指标:问卷回收率≥85%,单条记录完整度≥95%。
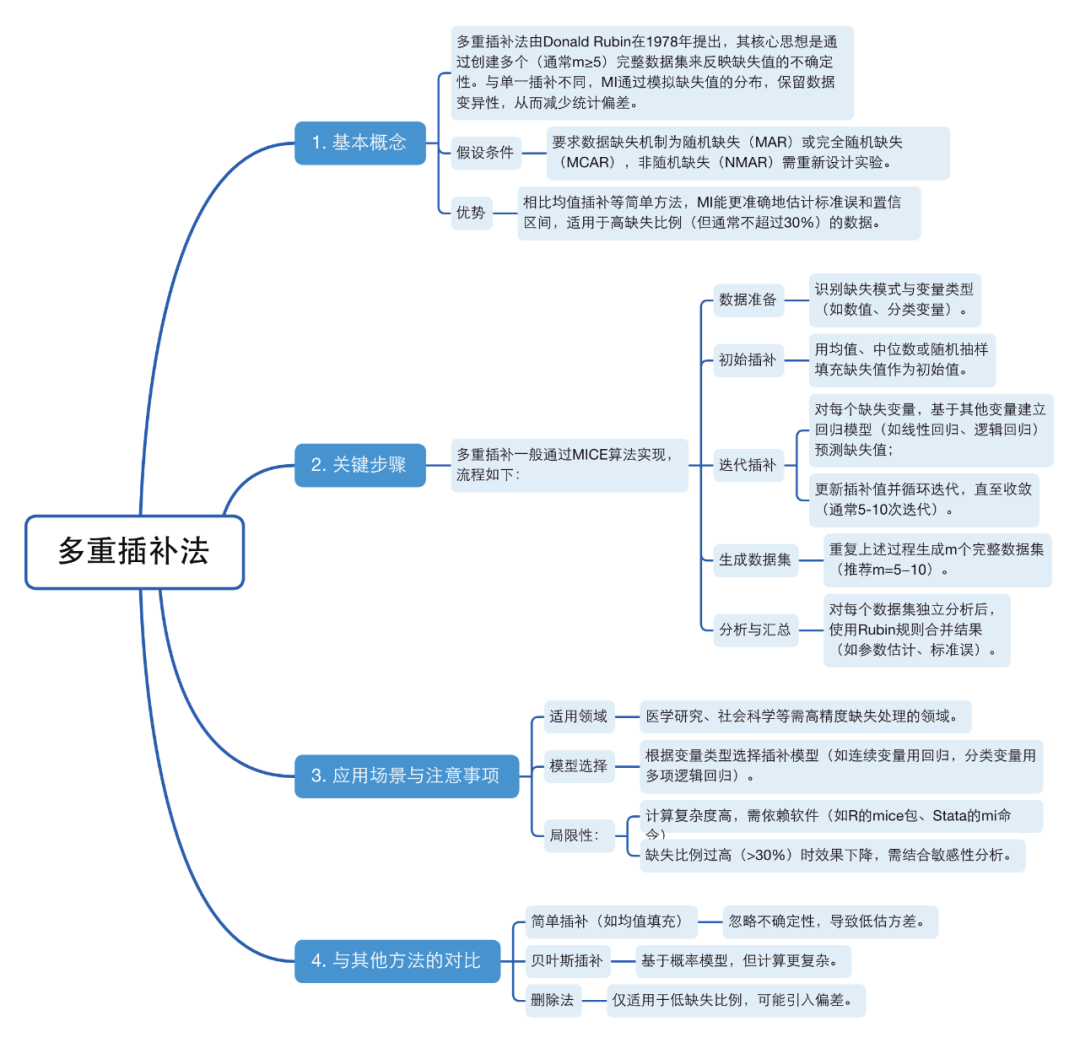
处理策略:整列缺失>30% → 剔除该特征;整行缺失>50% → 剔除该样本;少量缺失 → 多重插补法(MICE)
点击查看模板高清原图![]() https://www.processon.com/view/6809b22ee6ad2b0bea282629
https://www.processon.com/view/6809b22ee6ad2b0bea282629
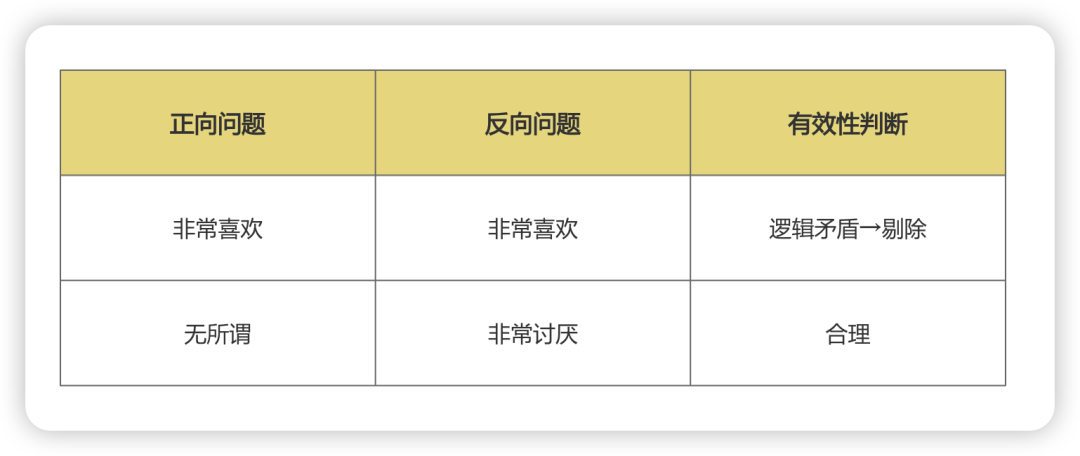
2)逻辑矛盾检测
KANO特异性规则:
正向问题:"有该功能时满意度"
反向问题:"无该功能时不满意度"
3)异常值处理
参考指标:连续10题选择同一分值;正反向题打分趋势完全一致;完成时间<正常值30%(如<90秒)
4)重复数据排查
参考使用多重校验维度:IP地址重复率>3次 → 触发验证;设备ID+时间戳重复 → 自动去重;开放式问题文本相似度>90% → 人工复核等等。
5)量化结果
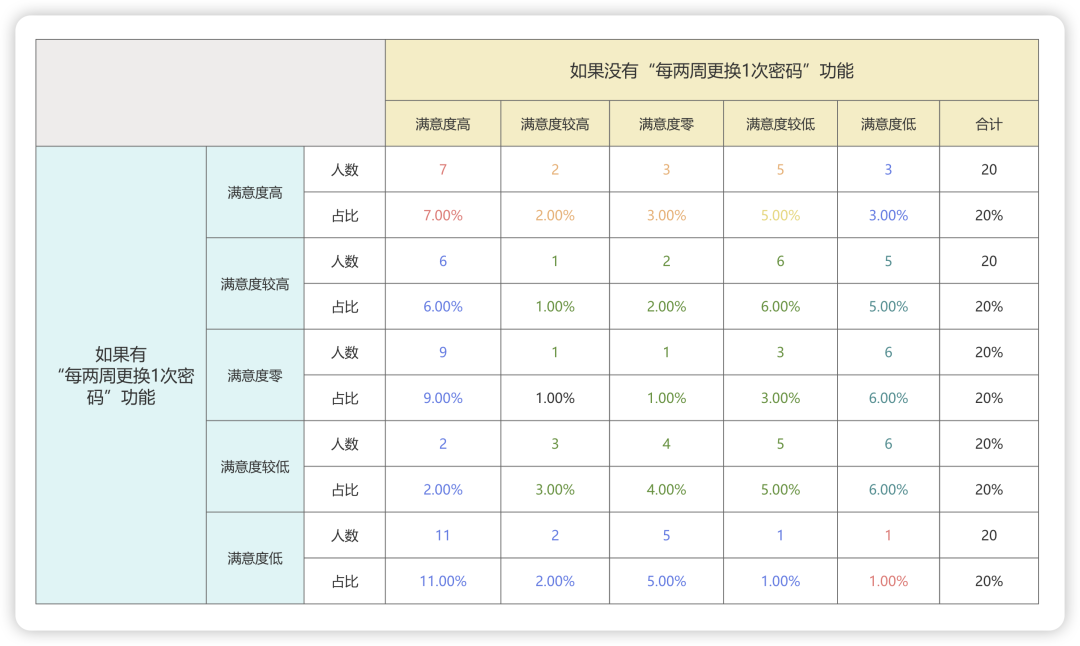
在实际工作中,我们会调研许多用户,对于同一个问题,会产生无数个答案。此时就可以根据下面这个原则来确定,需求到底属于哪个属性。计算不同属性的比例之和,总数值最高的就是这个需求的属性。
比如,某网站关于“每两周更换1次密码,并新密码不能与过去一年内的任何密码相同”的功能,回收了100份有效问卷,数值分布如下:
-
必备属性(M):17,17.00%
-
期望属性(O):3,3.00%
-
魅力属性(A):10,10.00%
-
无差异属性(I):26,26.00%
-
反向属性(R):36,36.00%
-
可疑结果(Q):8,8.00%
由以上结果得出,大多数人认为“每两周更换1次密码,并新密码不能与过去一年内的任何密码相同”功能是一个反向属性功能,还有较大比例的人认为这是一个无差异属性功能,所以这个功能现在不应该做。
有一种情况需要特别说明一下,如果调研结果中几个属性的数值接近或相同,我们就需要增加样本数量,扩大调研范围。
三、Better-Worse系数
除此之外,KANO模型中有一个重要的工具——Better-Worse系数,用于评估产品特性对用户满意度的影响。具体来说,它衡量的是某个功能的存在与否对用户满意程度的正面或负面影响,通过计算Better和Worse系数,可以帮助企业了解哪些功能最能提升用户满意度,以及哪些功能的缺失会导致最大的不满。
这个工具在产品经理、项目管理、市场营销、产品需求用户调研和产品运营、活动策划等中运用的比较广泛,它同时也被其他岗位慢慢的熟知,多掌握一个职场工具,就是给自己找到一种新的解决问题的方法。
Better系数(满意度增益指数):表示某功能存在时能带来多少满意度提升,值越大越能创造用户愉悦感。
Better= (A+O)/(A+O+M+I)
Worse系数(不满意度衰减指数):表示某功能缺失时会导致多少不满意度增加,绝对值越大越容易引发用户不满。
Worse= -1*(M+O)/(A+O+M+I)
将上部分内容中回收的100份问卷结果代入公式,可得:
Better= (10+3)/(10+3+17+26) =23.21%
Worse= -1*(17+3)/(10+3+17+26)=-35.71%
结果解读:
Better=23.21% → 该功能存在时,23.21%用户会感到满意
Worse=-35.71%→ 该功能缺失时,35.71%用户会产生不满
结论和上面的一致,这是一个具有无差异属性的功能,现在不应该做。
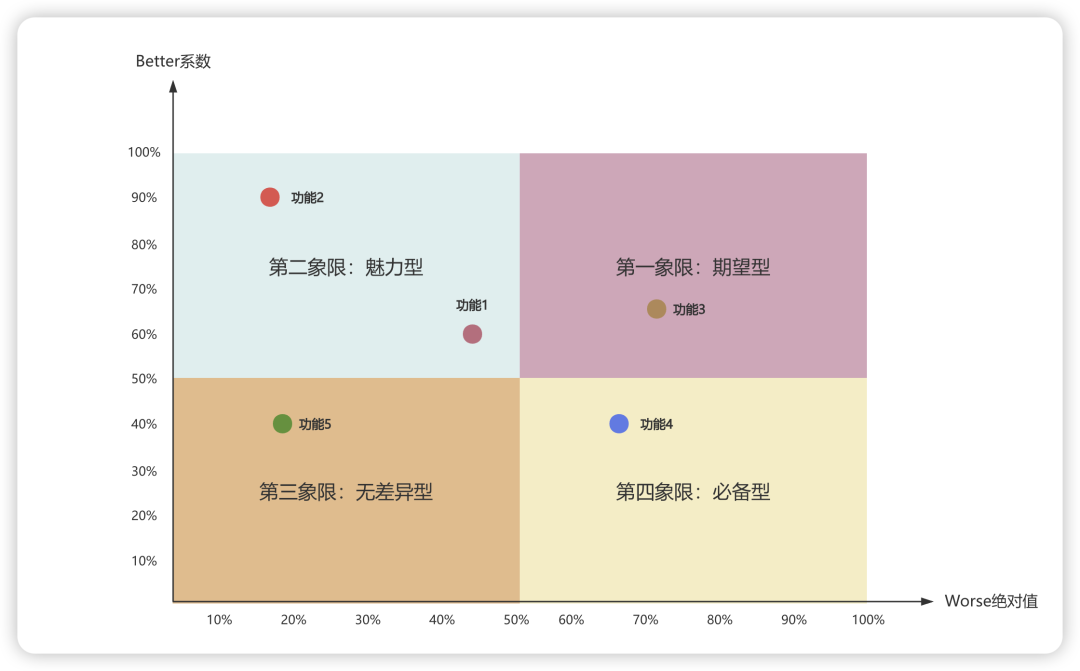
通过Better-Worse系数值,Better-Worse系数四象限图划分为四个象限,以Better系数值为横坐标,Worse系数绝对值为纵坐标,将功能/需求分布到象限图中。
第一象限:期望型需求
第二象限:魅力型需求
第三象限:无差异型需求
第四象限:必备型需求
Better-Worse系数四象限分布举例
第一象限Better值高、Worse绝对值也高,表示提供此类型功能,用户满意度会提升,因此在这个象限的需求都是期望型。
第二象限Better低,Worse绝对值高,表示不提供此类型功能,用户满意度会大幅下降,因此在这个象限的需求都是必备型。
第三象限Better值低、Worse绝对值也低,表示有没有此类型功能,用户满意度都不会有太大变化,因此这个象限的需求都是无差异型。
第四象限Better值高、Worse绝对值低,表示提供此类型功能,用户满意度会大幅提升,因此这个象限的需求都是魅力型。
通过上面几个步骤,我们可以知道上面5个功能的属性和开发原则:功能1和功能2属于魅力型、功能3属于期望型、功能4属于必备型、功能5属于无差别型。开发顺序为:必备型需求 > 期望型需求 > 魅力型需求 > 无差异型需求
以上就是今天的分享,希望大家都能有所收获。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









