






一、赛题情况介绍
星河杯隐私计算大赛“诈骗电话识别-联邦学习”赛题,要求参赛者基于纵向联邦学习的方式完成诈骗电话识别模型的训练与预测功能。基于多方持有的用户个人基本信息、套餐使用信息、上网流量、通话信息等特征数据进行联合建模,实现诈骗电话的检测、识别。具体应完成以下两项任务:
- 任务一
诈骗电话识别模型训练。参与方A提供部分特征及标签数据,参与方B提供其他部分特征数据。采用两方纵向联邦学习的方式,基于融合数据集训练联合模型,各方持有部分模型。参与方之间网络带宽限定在100Mbps。要求各方的原始数据、计算结果无泄漏,针对计算过程中涉及的中间数据进行有效保护。
- 任务二
基于任务一得到的模型进行诈骗电话批量预测。参与方A、参与方B各提供部分特征数据和模型,使用两方合并的完整模型对融合数据集进行预测。参与方之间网络带宽限定在100Mbps。要求在预测过程中不会泄漏各方原始数据和模型信息。
二、方案整体说明
根据赛题要求,比赛的场景为数据垂直切割于两方,数据特征平均由两方持有,其中A方持有标签属性。需要进行多方联合建模,预测样本是否为诈骗电话,是一个典型的二分类场景。此外,安全要求是原始数据以及中间计算结果无泄漏。
以下为数据集统计信息:
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
整体思路
针对上述需求,主要有两个问题解决:
1.依据两方提供的数据构建符合赛题场景的二分类模型
2.避免泄露各方的数据,即需要在两方垂直分割的数据场景下进行联合建模
针对问题(1),首先需要对数据做充分的数据探索,然后对数据进行合理的预处理以及特征工程,依据赛题评价指标AUC筛选最佳算法结构方案;
针对问题(2),数据集分布在两方,如果按照传统建模流程进行本地聚合会涉及隐私问题,又或者分布式机器学习,但是同样面临特征与标签泄露的风险。因此我们需要做到在不泄露各方数据信息的基础上完成联合建模,保护各方的特征不被泄露,保护持有标签的一方标签信息不被泄露。
基于上述分析,可以考虑使用隐语开源框架提供的联合建模能力(如LR,XGB模型)在垂直场景上完成上述任务。
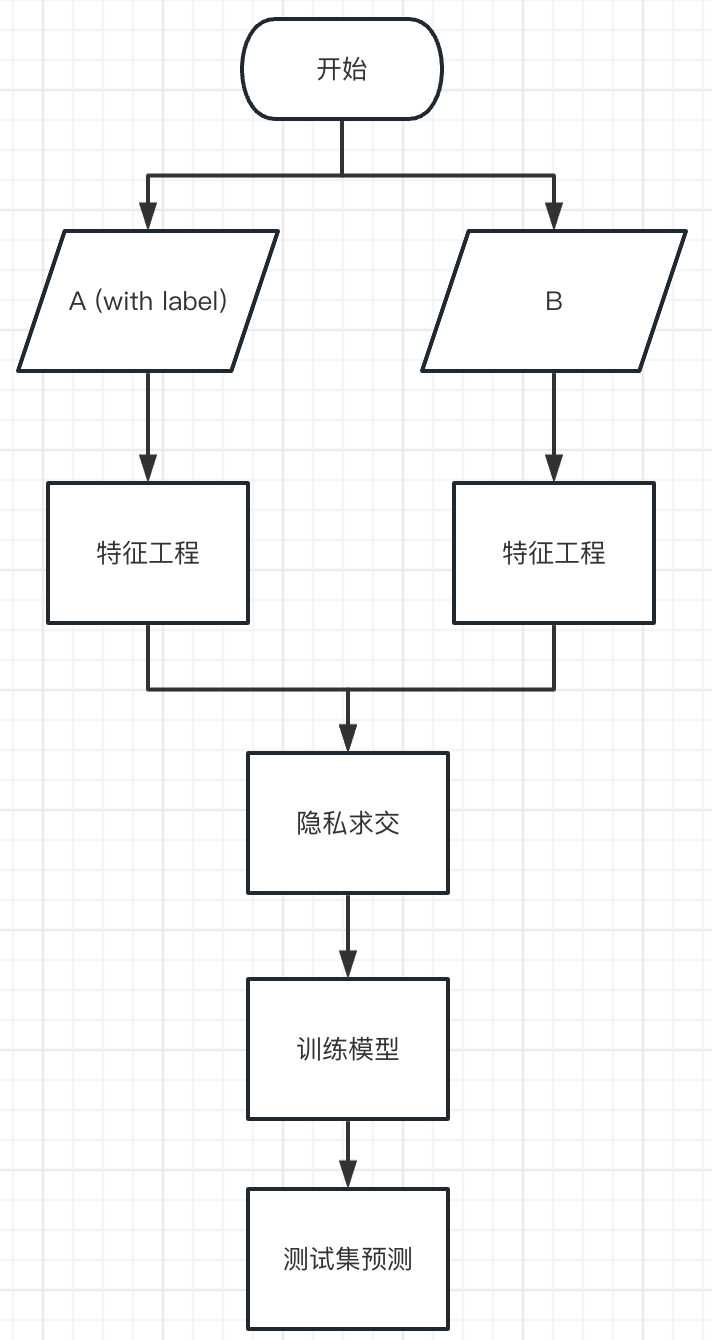
具体步骤如下:
1.由于是垂直场景,首先可以各方本地对原始数据进行数据预处理。
2.多方之间对上述预处理后的数据进行数据对齐,可以使用PSI完成
3.(optional)对对齐后的联合数据进行联合预处理
4.构建模型进行训练与预测
三、方案原理介绍
此处使用LR和XGB作为示例,隐语也支持更为丰富的NN建模能力,包括垂直和水平场景,以及基于MPC、FL等不同技术路线的实现方案。
1.明文模型
逻辑回归模型(LR)
逻辑回归模型是形式简单且使用非常广泛的一类统计模型。逻辑回归模型的计算涉及到计算预测值 pred = sigmoid(batch_x * w)。其中,sigmoid可使用泰勒展开、分段函数、根号逆S形函数等近似。默认采用MSELoss作为损失函数,并计算模型参数的梯度,完成更新。最终通过多轮迭代之后得到最终的模型参数。
树模型(XGBoost)
在标准的XGBoost模型中,核心在于按层建树的时候,枚举所有分裂方案,选出带来最优增益值的方式执行分裂,通过多轮迭代,得到多棵树,集成的结果对应每一个样本的得分。
2.隐语联合建模能力
LR联合建模
隐语提供了 SS-SGD/HESS-SGD 两种实现
-
SS-SGD: SS-SGD 是 secret sharing SGD training 的缩写,使用秘密分享协议计算模型的前后向传播。
-
HESS-SGD [1]: HESS-SGD 是 HE & secret sharing SGD training 的缩写,结合HE计算batch_x * w 提高效率。
考虑到:
-
Secret Sharing对带宽和延迟比较敏感,而同态加密方案会消耗更多的CPU算力。局域网/万兆环境下SS能更快的完成建模,带宽受限且延迟较高的网络环境可以用HE提高建模速度。
-
HESS-SGD 针对垂直场景可以结合HE提高效率
因此,针对此次大赛,推荐使用基于HESS-SGD的建模,更加适合带宽受限下的多方垂直联合建模。
XGB联合建模
隐语提供了SS-XGB 和 SGB 两种实现
-
SS-XGB [2]:SS-XGB模型中,其使用秘密分享协议计算分裂增益值和叶权重,通过安全比较协议得到每一层上面最优分裂点信息,只有持有分裂特征的一方知道分裂点当前对应的特征值以及阈值是什么,其他特征持有方队分裂特征与阈值无感知。在最终的分类问题上,使用了密态的Sigmoid函数将预测值转换为概率,同时使用Logloss作为损失函数。
-
SGB [3]:SecureBoost是一种经典算法,它优先保护垂直分区数据集中的标签信息。它使用同态加密技术实现标签加密和密文中的关键树增强步骤执行。
考虑到:
-
SS-XGB 由于基于MPC实现,提供了可证安全,但是通信开销大
-
SGB 能够更高效地支持垂直场景
因此,针对此次大赛,推荐使用基于SGB的建模,更加适合带宽受限下的多方垂直联合建模。
小结:
针对此次大赛,可以使用隐语提供的不同建模能力。以下说明将以SGB为例,对其他建模能力感兴趣的同学欢迎查看官方文档 [4]。
四、方案安全性说明
算法安全性:
原始论文参考[3],详见Section 7 Security Discussion.
主要训练预测的流程为Active 方(label的持有方) 把一阶导数和二阶导数 加密(半同态,例如Paillier加密)后发送给 Passive方,加密可以保护 Active 方的标签。整个训练过程中各方的原始数据都是被保护的,不会泄露对应的明文信息。
上述方案存在的信息泄露分析如下:
参与方知道每个结点上的样本分布情况:
一方面,所有结点都会知道一定的特征排序信息;
另一方面,属于同一叶节点的样本,往往标签是相同或相近的,因此叶结点的父结点持有方可以知道这个相近信息(针对这个问题,文中的改进方案为第一棵树由主动方独立完成,则后续泄露的就是残差的相似性,文中认为这个泄露可接受)。
主动方知道被动方导数累积和原始值: 有反推出被动方特征排序的风险,比如当导数值各不相同且分桶数等于样本个数时。
P.S. malicious下存在可能的攻击方案[5]。
通信安全:
隐语使用mTLS对通信进行加密,配置方式见[6]
SPU mTLS配置可参考隐语官网API说明[7]
安全参数:
隐语中初始化HEU(同态加密计算设备)时可以配置key的bit size,有等效的安全强度。
Paillier使用2048-bit 的秘钥,对应112 bits 的安全强度
结果安全:
详见原始论文[3]
密码安全:
隐语支持多种半同态加密算法[8],如OU,Paillier。
五、具体实现与性能
1.环境配置
两台阿里云ECS:ecs.r6.4xlarge (CentOS, 16C128G)
tc qdisc del dev eth0 root
tc qdisc add dev eth0 root handle 1: tbf rate 100mbit burst 128kb latency 800ms
tc qdisc add dev eth0 parent 1:1 handle 10: netem delay 25ms limit 8000
tc -s qdisc ls dev eth0
2.运行指令
在两台PC上分别执行下述指令。以下将两方命名为alice和bob,其中alice为持有label的一方。
以下代码以alice为例:
安装环境:
- Install MiniConda[9].
conda create -n $NAME python=3.8
pip install secretflow
各方预处理
- 自定义预处理输出到csv文件即可
部署ray集群
RAY_DISABLE_REMOTE_CODE=true \
ray start --head --node-ip-address=${ip} --port=${port} --resources={\"${party}\":${num_cpus}} --include-dashboard=False
- 主要需要传入三个参数:ip,port以及party。注意此处:party should be in [‘alice’, ‘bob’].
修改IP配置 (改成实际机器的IP)
- config_alice.json / config_bob.json
{
"parties": {
"alice": {
"address": "127.0.0.1:21212",
"listen_addr": "0.0.0.0:21212"
},
"bob": {
"address": "127.0.0.1:21211",
"listen_addr": "0.0.0.0:21211"
}
},
"self_party": "alice"
}
- run_task.py 中的 spu_config 参数
spu_config = {
"nodes": [
# YOUR IP & free port
{"party": "alice", "id": "local:0", "address": "127.0.0.1:5566"},
# YOUR IP & free port
{"party": "bob", "id": "local:1", "address": "127.0.0.1:5577"},
],
"runtime_config": {
"protocol": spu.spu_pb2.SEMI2K,
# <<< !!! >>> specifically, use FM128 for [SEMI2K] protocol and FM64 for [ABY3, CHEETAH] protocols, pls change field if protocol is changed.
# 这里改环大小,SEMI2K 用 FM128, [ABY3, CHEETAH] 用 FM64
"field": spu.spu_pb2.FM128,
},
}
跑训练和预测脚本 (****run_task.py见下面SGB实现)
-
-d 表示读取csv文件路径,可以自定义
-
–ip 设置为机器IP,–port和上述ray集群启动的port一致
-
party should be in [‘alice’, ‘bob’]
python run_task.py -d fe_output --ip $ip --port $port --cluster_config config_$party.json
3.特征工程
以下仅作为Baseline使用了几个预处理的方法,有兴趣挖的同学可以尝试更多的方法。
- WOE
-
night_call_cnt_rate
-
opp_belo_cnt
- onehot + PCA 类别数据
onehot_features = [
"pretty_num_typ",
"rcn_chnl_id",
"rcn_chnl_typ",
]
onehot_features = [
"belo_camp_id",
"belo_group_cust_id",
"charge_package_unify_code",
"befo_pri_package_code",
"basic_package_id",
"term_brand",
"term_mdl",
"pretty_num_typ_name",
"stp_typ",
]
- 缺失值填充
4.SGB实现
############# Init SF ##################
ip = 127.0.0.1
port = 9999
cluster_config = 'config_alice.json'
with open(cluster_config, "r") as inf:
config_def = json.loads(inf.read())
sf.init(address="{0}:{1}".format(ip, port), cluster_config=config_def)
alice = sf.PYU("alice")
bob = sf.PYU("bob")
# SPU settings
spu_config = {
"nodes": [
# YOUR IP & free port
{"party": "alice", "id": "local:0", "address": "127.0.0.1:5566"},
# YOUR IP & free port
{"party": "bob", "id": "local:1", "address": "127.0.0.1:5577"},
],
"runtime_config": {
"protocol": spu.spu_pb2.SEMI2K,
# <<< !!! >>> specifically, use FM128 for [SEMI2K] protocol and FM64 for [ABY3, CHEETAH] protocols, pls change field if protocol is changed.
# 这里改环大小,SEMI2K 用 FM128, [ABY3, CHEETAH] 用 FM64
"field": spu.spu_pb2.FM128,
},
}
my_spu = sf.SPU(spu_config)
# HEU settings
heu_config = {
"sk_keeper": {"party": "alice"},
"evaluators": [{"party": "bob"}],
"mode": "PHEU", # 这里修改同态加密相关配置
"he_parameters": {
"schema": "ou",
"key_pair": {
"generate": {
"bit_size": 2048,
},
},
},
"encoding": {
"cleartext_type": "DT_I32",
"encoder": "IntegerEncoder",
"encoder_args": {"scale": 1},
},
}
import copy
heu_x = sf.HEU(heu_config, spu_config["runtime_config"]["field"])
heu_config = copy.deepcopy(heu_config)
sk_keeper = heu_config["sk_keeper"]
evaluator = heu_config["evaluators"][0]
heu_config["sk_keeper"] = evaluator
heu_config["evaluators"][0] = sk_keeper
heu_y = sf.HEU(heu_config, spu_config["runtime_config"]["field"])
############# Loading data ##################
start = time.time()
train_vdf = v_read_csv(
{alice: train_alice_path, bob: train_bob_path},
keys="row_num",
drop_keys="row_num",
spu=my_spu,
)
test_vdf = v_read_csv(
{alice: test_alice_path, bob: test_bob_path},
keys="row_num",
drop_keys="row_num",
spu=my_spu,
)
X_train = train_vdf.drop(columns="label")
y_train = train_vdf["label"]
y_train_ = reveal(y_train.partitions[alice].data)
X_test = test_vdf
logging.info(f"IO times: {time.time() - start}s")
############# Training ##################
xgb = Sgb(heu_x)
start = time.time()
params = {
# <<< !!! >>> change args to your test settings.
# for more detail, see Xgb.train.__doc__
"num_boost_round": 3,
"max_depth": 5,
"learning_rate": 0.05,
"sketch_eps": 0.05,
"objective": "logistic",
"reg_lambda": 1,
"subsample": 0.75,
"colsample_by_tree": 0.9,
"base_score": 0.58,
}
model = xgb.train(params, X_train, y_train)
logging.info(f"main train time: {time.time() - start}")
############# Inference ##################
start = time.time()
# FIXME: replace to test dataset
spu_yhat = model.predict(X_train)
yhat = reveal(spu_yhat)
logging.info(f"main predict time: {time.time() - start}")
logging.info(f"main auc: {roc_auc_score(y_train_, yhat)}")
precision, recall, thresholds = precision_recall_curve(y_train_, yhat)
plt.plot(recall, precision)
plt.xlabel("Recall")
plt.ylabel("Precision")
plt.title("PR Curve")
plt.savefig("PR Curve.pdf")
5.实验结果
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
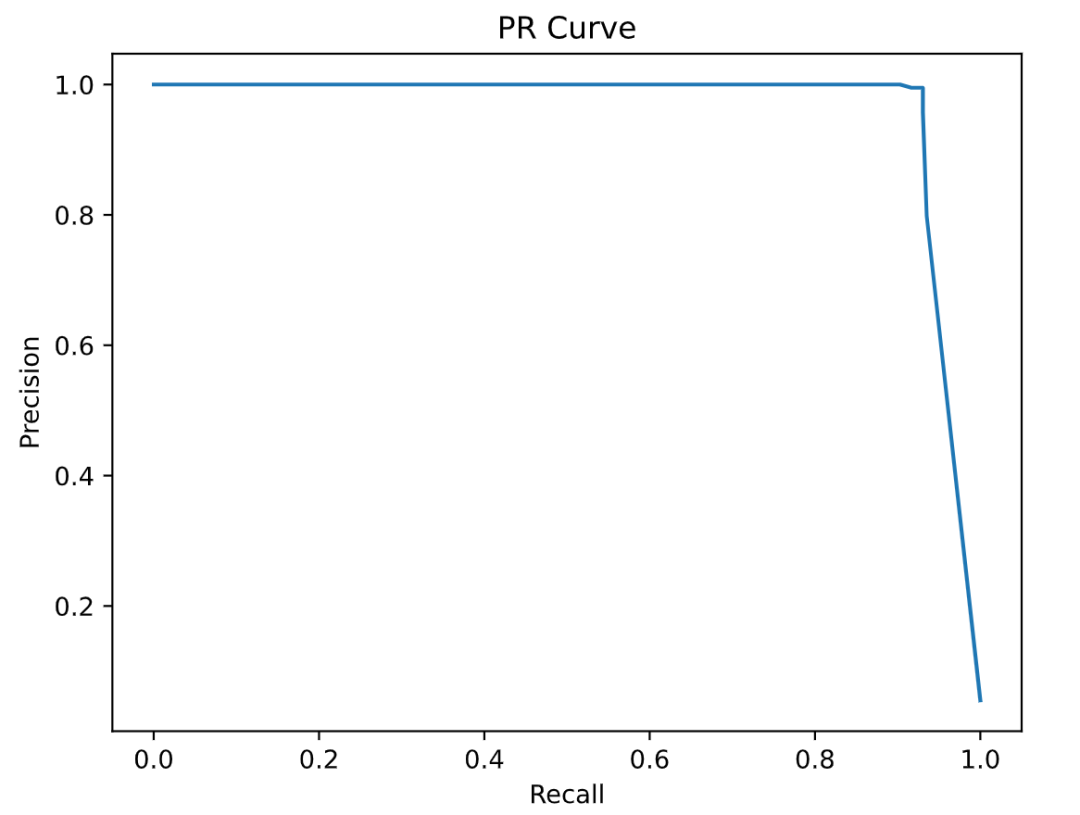
“num_boost_round”: 3, “max_depth”: 5 训练结果
6.自定义调试
可以尝试不同的预处理方法,做一些特征筛选;此外可以使用不同的模型参数去取得模型auc和训练效率的trade-off。
六、Reference
【1】When Homomorphic Encryption Marries Secret Sharing: Secure Large-Scale Sparse Logistic Regression and Applications in Risk Control.
https://dl.acm.org/doi/10.1145/3447548.3467210
【2】Large-Scale Secure XGB for Vertical Federated Learning.
https://arxiv.org/pdf/2005.08479.pdf
【3】SecureBoost: A Lossless Federated Learning Framework.
https://arxiv.org/abs/1901.08755
【4】https://www.secretflow.org.cn/docs/secretflow/zh_CN/tutorial/index.html
【5】Practical Privacy Attacks on Vertical Federated Learning.
https://arxiv.org/pdf/2011.09290.pdf
【6】https://www.secretflow.org.cn/docs/secretflow/zh_CN/getting_started/deployment.html#suggestions-for-production
【7】https://www.secretflow.org.cn/docs/secretflow/en/source/secretflow.html#secretflow.SPU.__init__
【8】https://www.secretflow.org.cn/docs/heu/zh_CN/getting_started/algo_choice.html
【9】https://docs.conda.io/en/latest/miniconda.html


















 239
239

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









