







 本文介绍了Kettle作为ETL工具在数据仓库开发中的应用,涵盖数据抽取、转换和加载过程。Kettle支持多种数据源,提供丰富的转换操作,并能进行任务调度和监控。通过转换和作业文件,实现数据处理的完整流程,同时讨论了任务调度的多种方法及监控方案。
本文介绍了Kettle作为ETL工具在数据仓库开发中的应用,涵盖数据抽取、转换和加载过程。Kettle支持多种数据源,提供丰富的转换操作,并能进行任务调度和监控。通过转换和作业文件,实现数据处理的完整流程,同时讨论了任务调度的多种方法及监控方案。
由于Kettle的众多优点(免费、开源;易部署,多平台支持;可视化、拖拽式操作,组件功能丰富,易上手等),很多企业会选择它来作为ETL开发的工具。
ETL的主要过程,就是完成对数据的抽取(Extract)、转换(Transform)、加载(Load),如果再同时做好任务的流程控制、自动调度和监控,一份完整的数仓开发就实现了。
下面将结合ETL主要过程和数仓开发思路,对Kettle的使用做下概述。
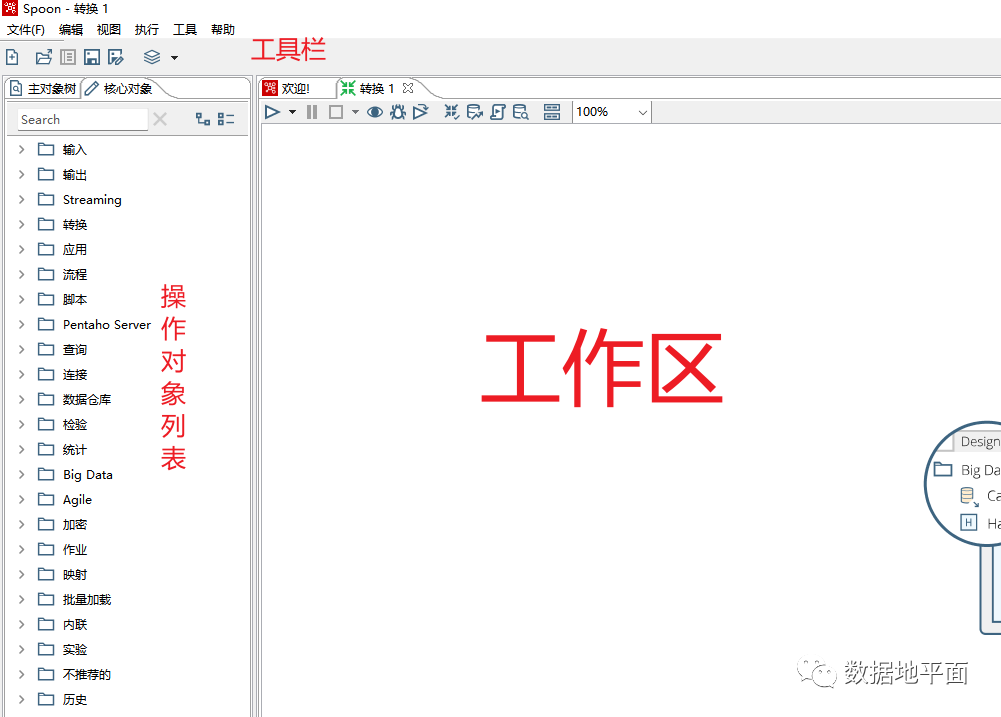
脚本文件和操作界面
在Kettle中只存在两种脚本文件,分别是转换(ktr)和作业(kjb),任何开发工作都是在这两类文件中完成的。从文件的类别名称就基本可以知道,转换文件主要负责对数据进行处理,作业文件主要负责整体任务的有序执行。
以转换文件为例,操作界面如下所示:
数据抽取(Extract)
“数据抽取”操作,主要依靠Kettle中的“输入”组件来完成,支持的数据源类型非常多,有Acess、Excel、CSV、XML、数据库表等,如下图所示。其中“表输入”(下图未展示)指的就是数据库表的输入,支持目前的主流数据库类型。
对于大数据类型的数据输入,可以选择“Big Data”组件里的控件来完成工作。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 991
991











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









