






今天教大家如何设计一个评论系统,主要针对海量评论系统的架构设计,希望对大家有所帮助。
1. 引言
1.1 带货风波
今年 9 月 10 日,“带货一哥” 李佳琦直播事件闹得沸沸扬扬,稳占各大新闻榜单前 10 名。
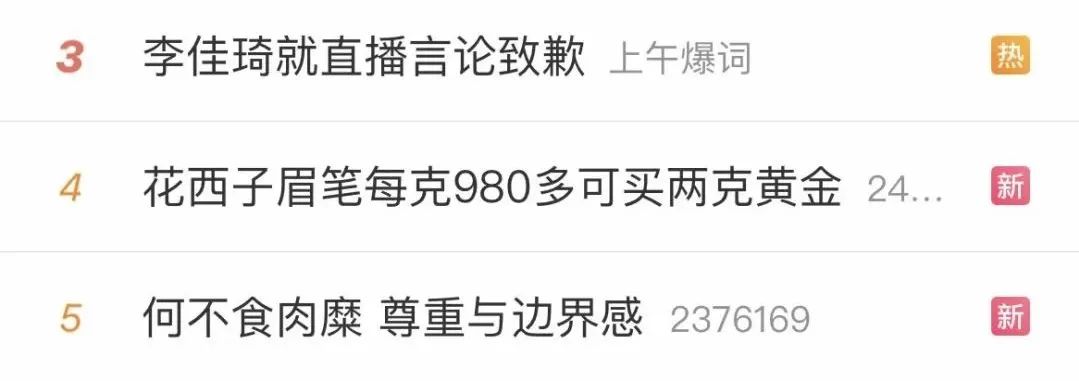
图来源:微博热点,侵删
当时,李佳琦在直播间介绍合作产品 “花西子” 眉笔的价格为 79 元时,有网友在评论区吐槽越来越贵了。他直言:哪里贵了?这么多年都是这个价格,不要睁着眼睛乱说,国货品牌很难的,哪里贵了?
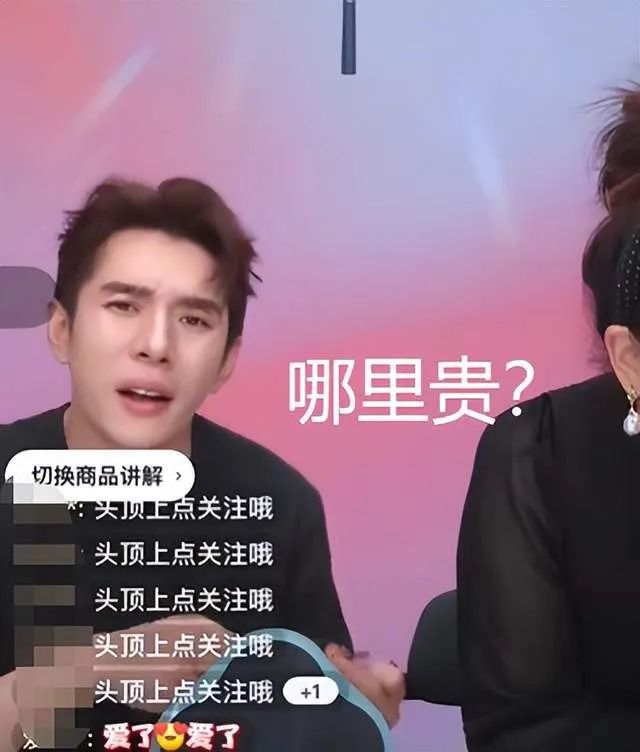
图来源:网络,侵删
之后,李佳琦接着表示:有的时候找找自己原因,这么多年了工资涨没涨,有没有认真工作?

图来源:互联网,侵删
楼仔觉得,这件事评论区网友说的没错,吐槽一下商品的价格有什么问题呢?我自己平时买菜还挑挑拣拣的,能省一毛是一毛。
毕竟,这个商品的价格也摆在那是不?

图来源:微博热点,侵删
1.2 身份决定立场,立场决定言论
但是,有一说一,从主播的角度呢,我也能理解。毕竟,不同的消费能力,说着自己立场里认可的大实话,也没啥问题。
那问题出在哪呢?
咳咳,两边都没问题,那肯定是评论系统有问题!
一边是年收入十多亿的带货主播,一边是普普通通的老百姓,你评论区为啥不甄别出用户画像,再隔离一下评论?
俗话说:“屁股决定脑袋”,立场不同,言论自然不一样。所以,这个锅,评论系统背定了!
2. 评论系统的特点
正巧,前几天在看关于评论系统的设计方案,且这类架构设计在互联网大厂的面试里出现的频率还是挺高的。所以我们今天就来探讨一下这个热门话题——《海量评论系统的架构设计》。
2.1 需求分析
首先,让我们来了解一下评论系统的特点和主要功能需求。评论系统是网站和应用中不可或缺的一部分,主要分为两种:
-
一种是列表平铺式,只能发起评论,不能回复;
-
一种是盖楼式评论,支持无限盖楼回复,可以回复用户的评论。
为了迎合目前大部分网站和应用 App 的需求,我们设计的评论系统采用盖楼式评论。
需要满足以下几个功能需求:
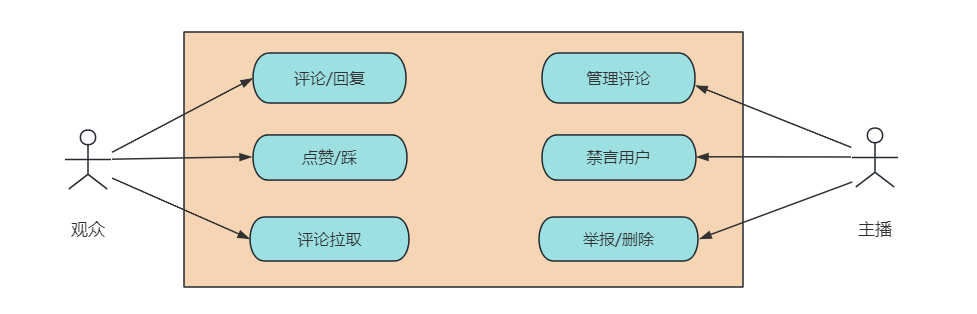
评论系统中的观众和主播相当于用户和管理员的角色,其中观众用户可以:
-
评论发布和回复:用户可以轻松发布评论,回复他人的评论。
-
点赞和踩:用户可以给评论点赞或踩,以表达自己的喜好。
-
评论拉取:评论需要按照时间或热度排序,并且支持分页显示。
主播可以:
-
管理评论:主播可以根据直播情况以及当前一段时间内的总评论数,来判断是否打开 “喜好开关”。
-
禁言用户:当用户发布了不当言论,或者恶意引流时,主播可以禁言用户一段时间。
-
举报/删除:系统需要支持主播举报不当评论,并允许主播删除用户的评论。
2.2 非功能需求
除了功能需求,评论系统还需要满足一系列非功能需求,例如应对高并发场景,在海量数据中如何保证系统的稳定运行是一个巨大的挑战。
-
海量数据:拿抖音直播举例,10 亿级别的用户量,日活约 2 亿,假设平均每 10 个人/天发一条评论,总评论数约 2 千万/天;
-
高并发量:每秒十万级的 QPS 访问,每秒万级的评论发布量;
-
用户分布不均匀:某个直播间的用户或者评论区数量,超出普通用户几个数量级;
-
时间分布不均匀:某个主播可能突然在某个时间点成为热点用户,其评论数量也可能陡增几个数量级。
3. 系统设计
评论系统也具有一个典型社交类系统的特征,可归结为三点:海量数据,高访问量,非均匀性,接下来我们将对评论系统的关键特点和需求做功能设计。
3.1 功能设计
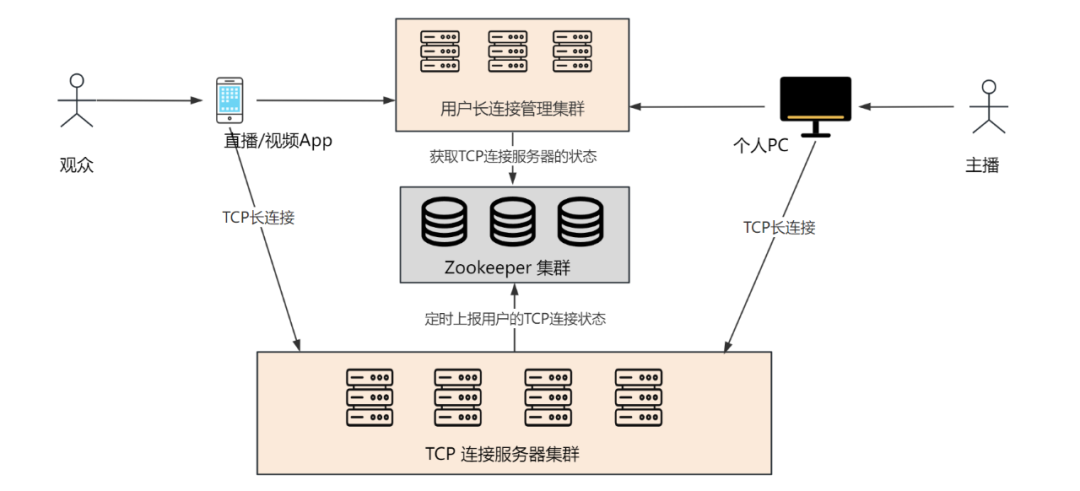
在直播平台或评论系统里,观众可以接收开通提醒,并且评论被回复之后也可以通过手机 App 收到回复消息,所以需要和系统建立 TCP 长连接。
同样地,主播由于要实时上传视频直播流,所以也需要 TCP 连接。架构图如下:
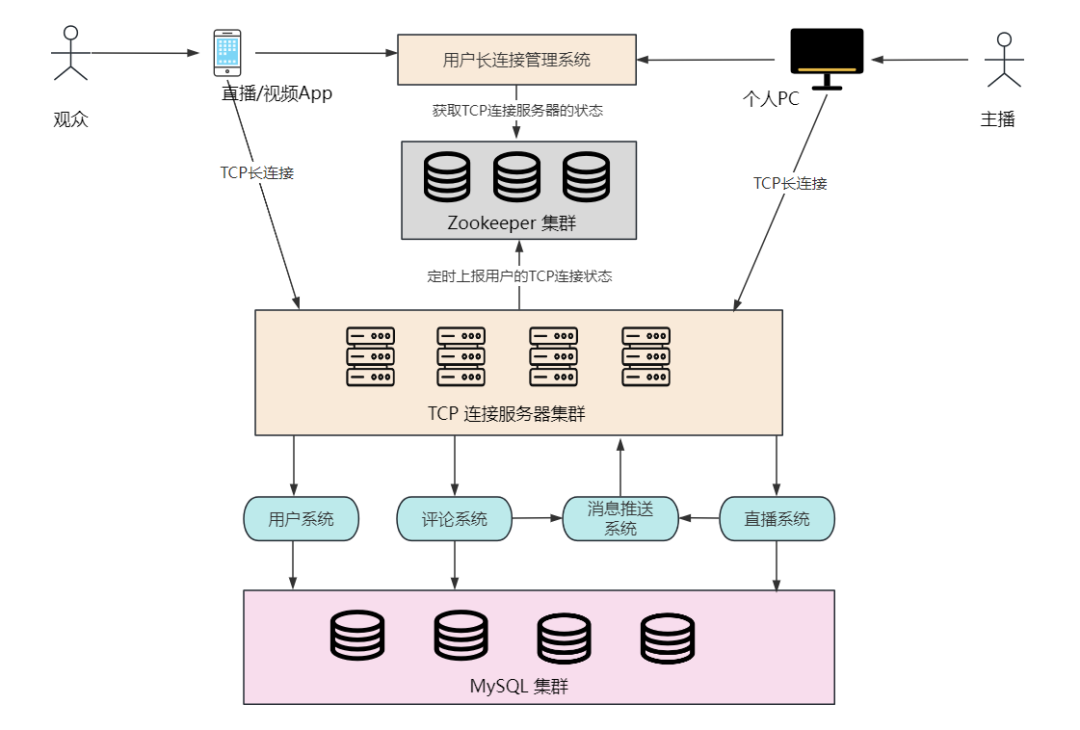
用户或主播上线时,如果是第一次登录,需要从用户长连接管理系统申请一个 TCP 服务器地址信息,然后进行 TCP 连接。
当观众或主播(统称用户)第一次登录,或者和服务器断开连接(比如服务器宕机、用户切换网络、后台关闭手机 App 等),需要重连时,用户可以通过用户长连接管理系统重新申请一个 TCP 服务器地址(可用地址存储在 Zookeeper 中),拿到 TCP 地址后再发起请求连接到集群的某一台服务器上。
用户系统
用户系统的用户表记录了主播和观众的个人信息,包括用户名、头像和地理位置等信息。
除此之外,用户还需要记录关注信息,比如某个用户关注了哪些直播间。
用户表(user)设计如下:
-
user_id:用户唯一标识
-
name:用户名
-
portrait:头像压缩存储
-
addr:地理位置
-
role:用户角色,观众或主播
直播系统
每次开播后,直播系统通过拉取直播流,和主播设备建立 TCP 长连接。这时,直播系统会记录直播表(live)信息,包括:
-
live_id:一场直播的唯一标识
-
live_room_id:直播间的唯一标识
-
user_id:主播用户ID
-
title:直播主题
参考微博的关注系统,我们可以引入用户关注表(attention),以便用户可以关注直播间信息,并接收其动态和评论通知:
-
user_id:关注者的用户ID。
-
live_room_id:被关注者的直播间ID。
这个表可以用于构建用户和主播之间的社交网络,并实现评论的动态通知。
用户关系表的设计可以支持关注、取消关注和获取关注列表等功能。
在数据库中,使用索引可以提高关系查询的性能。同时,可以定期清理不活跃的关系,以减少存储和维护成本。
评论系统
参考微博的评论系统,我们可以支持多级嵌套评论,让用户能够回复特定评论。
对于嵌套评论的存储,我们可以使用递归结构或层次结构的数据库设计,也可以使用关系型数据库表结构。评论表(comment)字段如下:
-
comment_id:评论唯一标识符,主键。
-
user_id:评论者的用户ID。
-
content:评论内容,可以是文本或富文本。
-
timestamp:评论时间戳。
-
parent_comment_id:如果是回复评论,记录被回复评论的comment_id。
-
live_id:评论所属的直播ID。
-
level:评论级别,用于标识评论的嵌套层级。
除此之外,我们可以根据业务需求添加一些额外字段:如点赞数、踩数、举报数等,以支持更多功能。
推送系统
为了提供及时的评论通知,我们可以设计消息推送系统,当用户收到关注直播间开播,或者有新评论或回复时,系统可以向其发送通知。
通知系统需要支持消息的推送和处理,当直播间关注人数很多或者用户发出了热点评论时,为了保证系统稳定,可以使用消息队列来处理异步任务。
此外,在推送时需要考虑消息的去重、过期处理和用户偏好设置等方面的问题。
3.2 性能和安全
除了最基本的功能设计以外,我们还需要结合评论系统的数据量和并发量,考虑如何解决高并发、高性能以及数据安全的问题。
1)高并发处理
评论系统面临着巨大的并发压力,数以万计的用户可能同时发布和查看评论。为了应对这个挑战,我们可以采取以下策略。
分布式架构
采用分布式集群架构,将流量分散到多个服务器上,降低单点故障风险,提升用户的性能体验。
消息队列
引入消息队列,如 Kafka,来处理异步任务。
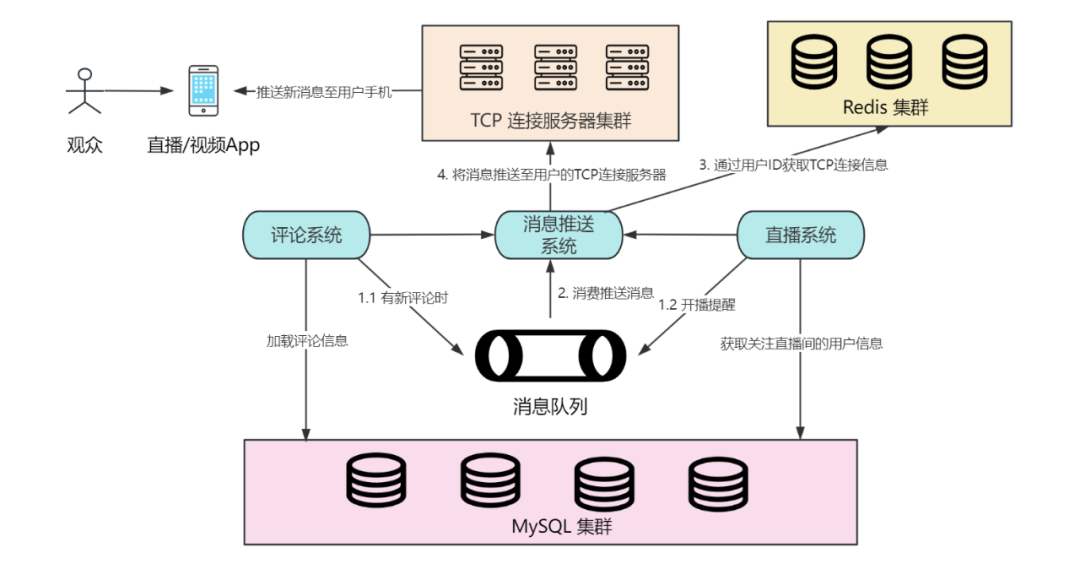
当直播间开播时,首先获取到关注该直播间的用户,然后将直播间名称、直播主题等信息,放入消息队列。
消息推送系统实时监听消息队列,当获取到开播提醒的 Topic 时,首先从 Redis 获取和用户连接的 TCP 服务器信息,然后将开播消息推送到用户手机上。
同样地,当用户评论被回复时,将评论用户名和评论信息通过消息推送系统,也推送到用户手机上。
使用消息队列一方面可以减轻服务器的流量负担,另一方面可以根据用户离线情况,消息推送系统可以将历史消息传入延时队列,当用户重新上线时去拉取这些历史消息,以此提升用户体验。
数据缓存
引入缓存层,如 Redis,用于缓存最新的评论数据,以此减轻数据库负载并提升响应速度。例如,可以根据 LRU 策略缓存直播间最热的评论、用户地理位置等信息,并定时更新。
2)安全和防护
评论系统需要应对敏感词汇、恶意攻击等安全威胁。我们可以采取以下防护措施:
文字过滤
使用文字过滤技术,过滤垃圾评论和敏感词汇。实现时,可以用 Redis 缓存或者布隆过滤器。对比性能,我们这里采用布隆过滤器来实现。
布隆过滤器(Bloom Filter)是一个巧妙设计的数据结构,它的原理是将一个值多次哈希,映射到不同的 bit 位上并记录下来。
当新的值使用时,通过同样的哈希函数,比对各个 bit 位上是否有值:如果这些 bit 位上都没有值,说明这个数不存在;否则,就大概率是存在的。
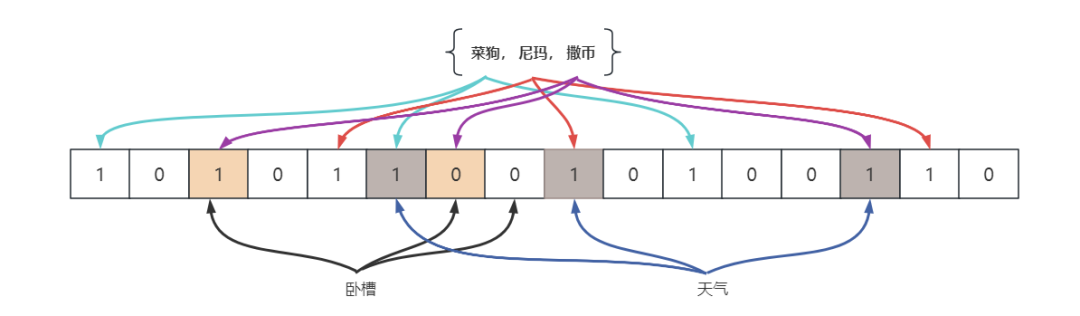
以上图为例,具体操作流程为:
-
假设敏感词汇有 3 个元素{菜狗,尼玛,撒币},哈希函数的个数也设置为 3。我们首先将位数组初始化,将每个位都置为 0。
-
然后将集合里的敏感词语通过 3 个哈希函数进行映射,每次映射都会产生一个哈希值,即位数组里的 1.
-
当查询词语是否为敏感文字时,用相同的哈希函数进行映射,如果映射的位置有一个不为 1,说明该文字一定不存在于集合元素中。反之,如果 3 个点都为 1,则判定元素存在于集合中。
当然,这可能会产生误判,布隆过滤器一定可以发现重复的值,但也可能将不重复的值判断为重复值。如上图中的 “天气”,虽然都命中了 1,但是它并没有存在于敏感词集合里。
布隆过滤器在处理大量数据时非常有用,比如网页缓存、拼写检查、黑名单过滤等。虽然它有一定的误判率(约为 0.05%),但是其判重的速度和节省空间的优点足以瑕不掩瑜。
用户限制
除了从评论信息上加以限制,我们也可以从用户侧来限制:
-
用户认证:要求用户登录后才能发布评论,降低匿名评论的风险。
-
评论限制:根据用户 ID 和直播 ID 进行限流,比如让用户在一分钟之内最多只能发送 10 条的评论。
4. 李佳琦该如何应对?
4.1 文本分析和情感分析
除了可以用布隆过滤器检测出恶意攻击和敏感内容,我们还可以引入文本分析和情感分析技术,使用自然语言处理(NLP)算法来检测不当评论。
并且,通过分析用户的评论内容,可以进行情感分析,以了解用户的情感倾向。
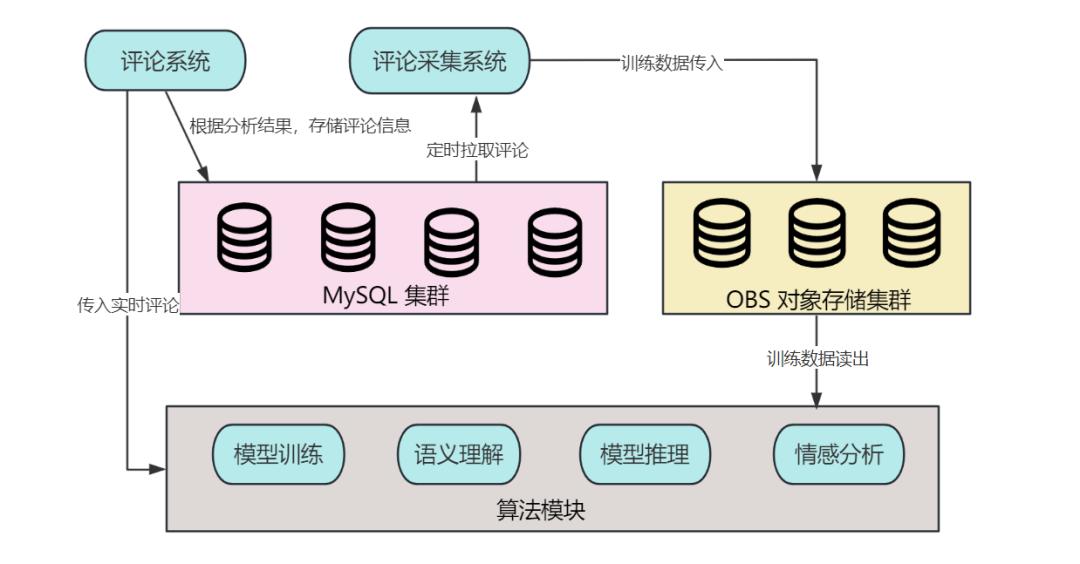
除了算法模块,我们还需要新增一个评论采集系统,定期(比如每天)从数据库里拉取用户的评论数据,传入对象存储服务。
算法模块监听对象存储服务,每天实时拉取训练数据,并获取可用的情感分析和语义理解模型。
当有新的评论出现时,会先调用算法模型,然后根据情感的分析结果来存储评论信息。我们可以在评论表(comment)里面新增一个表示情感正负倾向的字段 emotion,当主播打开喜好开关后,只拉取 emotion 为 TRUE 的评论信息,将“嫌贵的用户”或者 “评价为负面” 的评论设置为不可见。
这样,每次直播时,主播看到的都是情感正向且说话好听的评论,不仅能提升直播激情,还能增加与 “真爱粉” 的互动效果,可谓一箭三雕 🐶
但是,评论调用算法模型势必会牺牲一定的实时性与互动效果,主播也可以在开启直播时可以自己决定是否要打开评论喜好设置,并告知打开后评论会延时一段时间。
4.2 机器学习和推荐算法
除了从主播的角度,评论系统还可以引入机器学习算法来分析用户行为,根据用户的历史评论和喜好。
从观众来说,这可以提高观众的参与度和留存率,增强用户粘性。
从主播来说,可以筛选出真爱粉,脑残粉,甚至死亡芭比粉 🐶。这样,每次主播在直播时,只筛选一部分用户可以发表评论,其余的统统禁言,或者设置为不看用户评论。

除了直播领域,社交领域也经常使用推荐算法来获取评论内容。比如之前有 B 站 UP 主爆出:小红书在同一个帖子下,对女性用户和男性用户展示的评论区是不一样的,甚至评论区是截然相反的观点。
这个楼仔没有试验过,大家不妨去看一下😃
5. 小结
目前,评论系统随着移动互联网的直播和社交平台规模不断扩大,许多网站和应用已经实现了社交媒体集成,允许用户使用他们的社交媒体帐户进行评论,增加了互动性和用户参与度。
一些平台也开始使用机器学习和人工智能技术来提供个性化评论推荐,以改善用户体验。
总的来说,评论系统是在线社交和内容互动的重要组成部分,希望看过这篇文章之后,大家以后知道如何应对类似的公关危机,到时候记得回来给我点赞。

















 994
994

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









