






本项目基于Yolov4源码修改后的代码训练自己的数据集。Yolov4是一种目标检测算法,它的原理是将物体检测问题转化为一个回归问题,用于识别图像或视频中的物体。本实验要求最终实现并对目标物体全部识别。
1.环境搭建
1.1安装依赖库和工具
包括OpenCV图像处理库、Python3.8编程环境、labelImg_exe等。
注:labelImg_exe是一个在图像上标注目标并生成标注文件的工具(xml数据集获取时使用)。

2.由于每个人电脑使用情况不同,已安装的库和模块也会不同,所以在运行过程中就是:缺什么库(模块)就自行安装对应的库(模块)。
2.数据集
2.1.xml数据集获取
使用labelImg_exe在图像上标注目标并生成标注文件。

2.2数据集准备
在/VOCdevkit/VOC2007目录下建立三个文件夹Annotations、JPEGImages、ImageSets,我这个数据集主要有dog 一个类别的图片,共计200张,数据集图片和标签是分开的,其中,
Annotations:用来存放图片对应的xml
JPEGImages:用来存放图片


2.3添加类别
在voc_classes.txt文件中删改类别,我的数据集只有dog一个类别,所以在voc_classes.txt中只需要写dog。

2.4新建文件夹Main
在ImageSets下新建文件夹Main,用来存放txt文件(后续会生成)
2.5运行voc_annotation.py
运行voc_annotation.py,会生成txt文件,并且生成2007_train.txt和2007_val.txt。至此,所需要的数据就做好了。


3.训练模型
注:训练前仔细检查自己的格式是否满足要求,该库要求数据集格式为VOC格式,需要准备好的内容有输入图片和标签.输入图片为.jpg。输入图片如果后缀非jpg,需要自己批量转成jpg后再开始训练。标签为.xml格式,文件中会有需要检测的目标信息,标签文件和输入图片文件相对应。
3.1运行train.py文件
在yolo训练模型中,UnFreeze_Epoch是一个超参数,用于控制何时解冻所有层进行整体训练。具体来说,UnFreeze_Epoch表示训练过程中经过多少个epoch后解冻所有层。(我设置UnFreeze_Epoch的数值为5,可以根据自己具体情况设置其他的数值。)

4.模型测试
4.1predict.py运行报错(如果没有报错可忽略)
AttributeError: 'ImageDraw' object has no attribute 'textsize'

1、可以使用 pip 安装 Pillow
2、查看您的 Pillow 版本。可知当前pillow的版本为10.1(如果它早于 10.0,则可能是其他问题。)
pip install Pillow

3.解决方案是降级您的版本(没有规定一定是9.5.0),如果是10.0改为9.5还不行,再次尝试一个版本,比如说,9.4.0:
pip install Pillow==9.5.0
PS.可以通过查看requirements.txt,获知本项目所需库(模块)的版本,如:
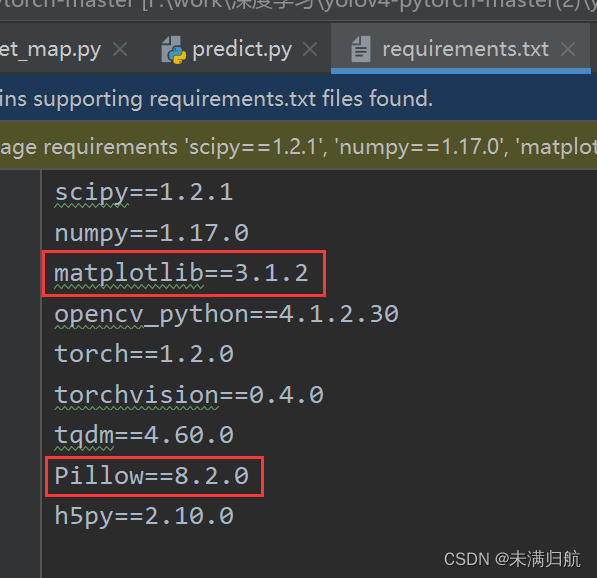
4.2运行predict.py文件
使用加载的模型对测试图像进行目标检测。将测试图像输入模型,得到目标的预测结果。fps_image_path与Input image filename两个输入的图片路径是一致的。

5.总结
基于YOLOv4源码修改后训练自己的数据集以成功识别图片上的目标,以下是我从这次实验中得出的一些心得:
5.1数据集准备的重要性
数据集的质量直接决定了模型的性能。在准备数据集时,我注意到以下几点尤为重要:
- 标注准确性:目标框的标注需要尽可能准确,否则模型在训练时可能会学习到错误的信息。
- 数据多样性:数据集应包含不同场景、不同角度、不同大小的目标,以增强模型的泛化能力。
- 数据增强:通过旋转、缩放、裁剪等方式进行数据增强,可以有效提高模型的鲁棒性
5.2训练过程中的监控与调整
在训练过程中,以下几个关键指标需要关注:
- 损失值:通过观察损失值的变化,可以判断模型是否正在收敛。如果损失值长时间不下降或出现异常波动,可能需要调整学习率或修改模型结构。
- 验证集性能:在验证集上评估模型的性能可以反映模型的泛化能力。如果验证集性能不佳,可能需要增加数据量、进行数据增强或调整模型参数。
- 过拟合与欠拟合:通过对比训练集和验证集的性能差异,可以判断模型是否出现过拟合或欠拟合现象。针对这些问题,我尝试了早停、正则化、模型剪枝等方法进行缓解。
5.3实验结果分析与总结
在实验结束后,我对结果进行了以下的分析和总结:
- 成功之处:模型在识别目标数量方面取得了不错的性能,说明数据集准备、模型修改和训练过程都做得比较到位。
- 不足之处:在某些复杂场景下,模型的识别精度还有待提高。这可能是由于数据集不够丰富、模型结构不够优化或训练策略不够合适等原因导致的。
- 未来改进方向:针对不足之处,我计划进一步丰富数据集、优化模型结构、调整训练策略,并尝试引入更先进的目标检测算法和技术来提高模型的性能。
总的来说,这次基于YOLOv4源码修改后训练自己的数据集的实验让我深刻体会到了深度学习在实际应用中的挑战和乐趣。通过不断尝试和调整,我逐渐找到了适合当前任务的模型和方法,并取得了一定的成果。同时,我也认识到了自己在深度学习领域还有许多需要学习和提高的地方,未来我将继续努力探索和实践。















 3579
3579











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









