







目录
GloVe(Global Vectors for Word Representation)
Rotary Position Embedding(RoPE)
项目
项目背景
原项目基于 Transformer 架构构建了一个古诗词生成模型,采用标准的 Multi-head Attention(MHA)作为核心注意力机制,结合Positional Embedding、Layer Normalization和Dropout进行建模,使用AdamW优化器和Cross Entropy Loss进行优化,通过自回归方式预测下一个字。
个人贡献
(1)深入理解并实现Grouped Query Attention(GQA),优化注意力计算效率,减少显存占用
(2)引入Mixture of Experts(MoE)机制,增加expert,通过稀疏激活提升模型容量和计算效率
(3)修改模型核心模块代码(Head、FFN、Block),确保新结构可训练并保持原有功能
成果产出
成功构建支持GQA + MoE的模型,推理效率提升
Self-BLEU降低,生成内容多样性提升;Distinct-2提高,生成内容更丰富
词嵌入
Word2Vec
基于分布式假设(上下文相似的单词,在语义或语法上也相似)
两种训练方式:
-
CBOW(Continuous Bag of Words):通过上下文预测中心词。输入是上下文单词的one-hot编码,隐藏层是上下文词向量平均后投影到低维空间,输出层用Softmax计算中心词的概率。适用于数据量较小或者高频词较多。
-
Skip-gram:通过中心词预测上下文。输入是中心词的one-hot编码,隐藏层直接映射为中心词的低维向量,输出层对每个上下文位置独立预测单词。Skip-Gram在⼤型语料中表现更好。
两种加速训练的方法:
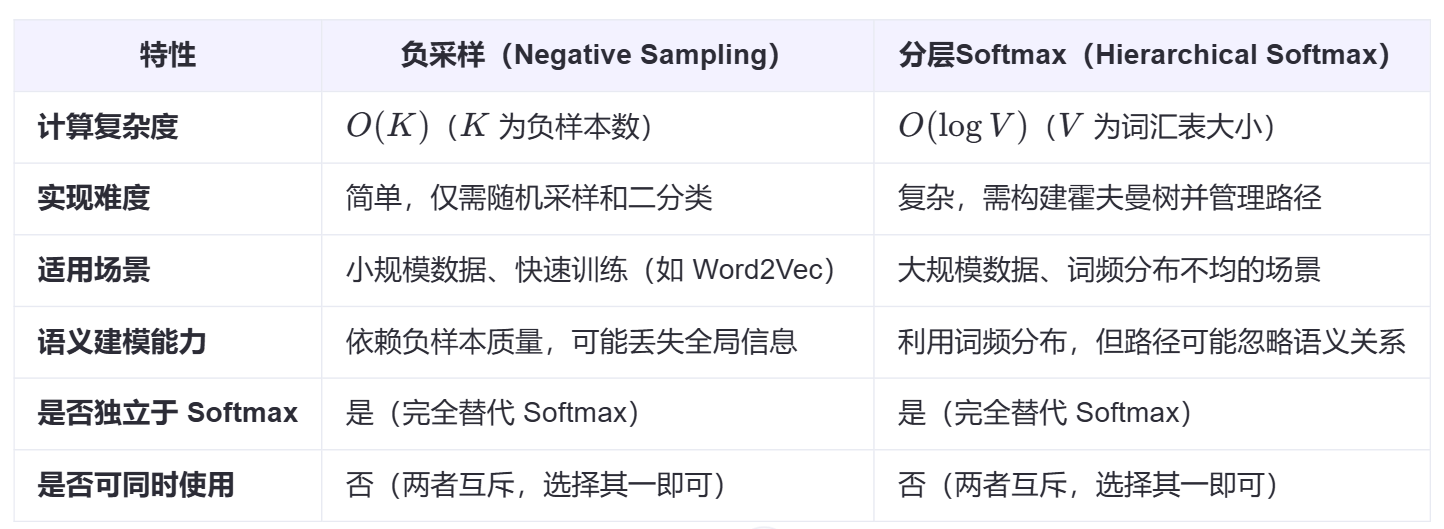
- 负采样(Negative Sampling)将多分类问题(预测上下文词)转化为二分类问题(区分正样本和负样本)。正样本:真实的上下文词(目标词);负样本:从词汇表中随机采样的“噪声词”(与目标词不相关的词)。通过只更新少量负样本的权重,大幅减少计算量。
- 分层Softmax(Hierarchical Softmax)将词汇表构造成一棵 二叉树(霍夫曼树),每个叶子节点对应一个词。通过路径上的二分类决策逐步预测目标词,避免直接计算所有 VV 个词的概率。
抖音推荐系统通过用户点击行为序列中的“关键词”与内容关键词的 Word2Vec 向量匹配,优化推荐算法。将用户行为序列和内容标签嵌入统一语义空间,计算相似性。
GloVe(Global Vectors for Word Representation)
利用整个语料库的词共现矩阵(co-occurrence matrix)。
静态词向量无法捕捉上下文依赖,动态词嵌入模型逐渐成为主流
FastText
传统的词向量模型(如 Word2Vec)将每个词视为整体进行建模,无法处理未登录词(OOV,模型在训练时未见过的词,例如新词、拼写错误、专有名词等,导致模型无法为其分配有效的词向量或语义表示)或形态学变化丰富的词汇(如“running” vs “run”)。
FastText 将单词拆分为字符级别的 n-gram(子词建模),例如将“apple”拆分为 <ap、app、ppl、ple 等子词,并为每个子词学习独立的向量。最终,单词的向量是其所有子词向量的平均值。
输出层可以使用层次化 Softmax 或负采样技术进行分类或预测
2022年梅奥诊所用FastText处理专业术语和罕见词汇。2025年香港科技大学提出PreSelect方法,通过 fastText 评分器高效筛选高质量数据。
ELMo(Embeddings from Language Models)
ELMo 使用的双向 LSTM 语言模型(biLM),所要优化的目标:最大化对数前向和后向的似然概率

⾸先在⼤型语料库上训练语⾔模型,得到词向量模型,然后在特定任务上对模型进⾏微调,得到更适合该任务的词向 量,ELMo⾸次将预训练思想引⼊到词向量的⽣成中,使⽤双向LSTM结构,能够捕捉到词汇的上下⽂信息,⽣成更加丰富和准确的词向量表示。
第1个阶段是利⽤语⾔模型进⾏预训练; 第2个阶段是在做特定任务时, 从预训练⽹络中 提取对应单词的词向量作为新特征补充到下游任务中。动态词向量:同一个词在不同上下文中生成不同的向量,解决了多义词问题。多层上下文建模:通过多层 LSTM,ELMo 能够捕捉不同层次的语言特征(如语法、语义)。
ELMo模型也存在⼀些问题,如模型复杂度⾼、训练时间⻓、计算资源消耗⼤等。
MHA、GQA、MLA
MHA(Multi-Head Attention)是 Transformer 模型的核心组件,通过并行计算多个注意力头(Query-Key-Value 对)来捕捉输入序列中不同位置的依赖关系。每个头独立计算注意力权重,最终通过拼接和线性变换输出结果。
GQA (Grouped Query Attention)是 MHA 和 MQA(多查询注意力)的折中方案,通过将查询头分组并共享 Key-Value 头,减少计算和存储开销。每组共享的 Key-Value 头数量少于 MHA,但多于 MQA(仅一个头),从而在速度和质量间取得平衡。
MLA(Multi-Head Latent Attention)进一步优化注意力机制,通过将 Key-Value 缓存压缩到低维潜在空间,显著减少内存占用。具体步骤包括:低秩压缩:使用投影矩阵将 Key-Value 向量映射到低维空间。共享投影矩阵:合并 Key 和 Query 投影矩阵以减少计算量。动态重建:在推理时从潜在空间重建 Key-Value 对。
prompt engineering
简述大模型prompt engineering技巧,如何设计有效的提示词提升模型输出质量
-
明确指令:用具体任务描述和输出格式要求(如“用李白风格写七夕情诗,每句含‘星河’意象”),避免模糊指令(如“写首诗”),并通过分隔符(如
""")界定输入边界; -
嵌入上下文:提供背景信息和约束条件(如领域限制、语言风格),帮助模型聚焦任务(例如“分析销量时限定在电商领域”);
-
示例与分步引导:结合Few-shot示例或CoT(Chain-of-Thought)分步推理(如“先列出关键步骤再生成答案”),并可融合角色扮演(如“你是一个时间管理专家”)增强任务适配性。
Few-shot示例在提示中提供少量(通常 1-10 个)输入-输出示例,帮助模型快速理解任务模式,无需大量训练数据。通过示例展示任务的逻辑、格式或规则,引导模型生成符合要求的输出。
Chain-of-Thought(CoT)通过分步骤推理引导模型逐步解决问题,模拟人类“思考链”过程,提升复杂任务的准确性和可解释性。模型先生成中间推理步骤,再输出最终答案,避免直接猜测导致的逻辑错误。
为什么引入CoT?
大模型通常直接输出最终答案,但面对需要多步逻辑推导的任务(如数学计算、符号操作)时,可能因跳过关键步骤或逻辑错误导致结果错误。传统模型直接输出结果,用户无法验证其逻辑是否正确,导致信任度低,例如模型可能凭直觉“猜”出答案,但无法解释其依据(黑箱问题)。企业需要模型具备可解释性和可控性(如医疗诊断、法律咨询),而CoT满足了这一需求。
位置编码
RNN模型中,token是一个接一个进入其中的,它们进入的顺序已经隐含了位置信息
位置编码主要分为两类:
-
绝对位置编码(Absolute Positional Encoding)为每个位置分配一个唯一的向量(如正弦/余弦函数或可学习嵌入)。
-
相对位置编码(Relative Positional Encoding)关注位置之间的相对距离(如旋转位置编码RoPE、相对注意力机制)。
正余弦编码(三角式)
Transformer中位置编码是使用正余弦函数进行编码的
通过不同周期的三角函数,使得任意两个位置的编码在平移后保持相对关系(例如 PE(pos+k)PE(pos+k) 可由 PE(pos)PE(pos) 的线性变换表示)

可学习位置编码(训练式)
可学习位置编码通过参数化设计(如nn.Embedding层),使模型能根据任务需求自主学习最优的位置表示。一般的认为它的缺点是没有外推性,即如果预训练最大长度为512的话,那么最多就只能处理长度为512的句子,再长就处理不了了。BERT、GPT
经典相对位置编码
更适合长序列建模(因为不依赖于绝对位置)

T5 相对位置编码
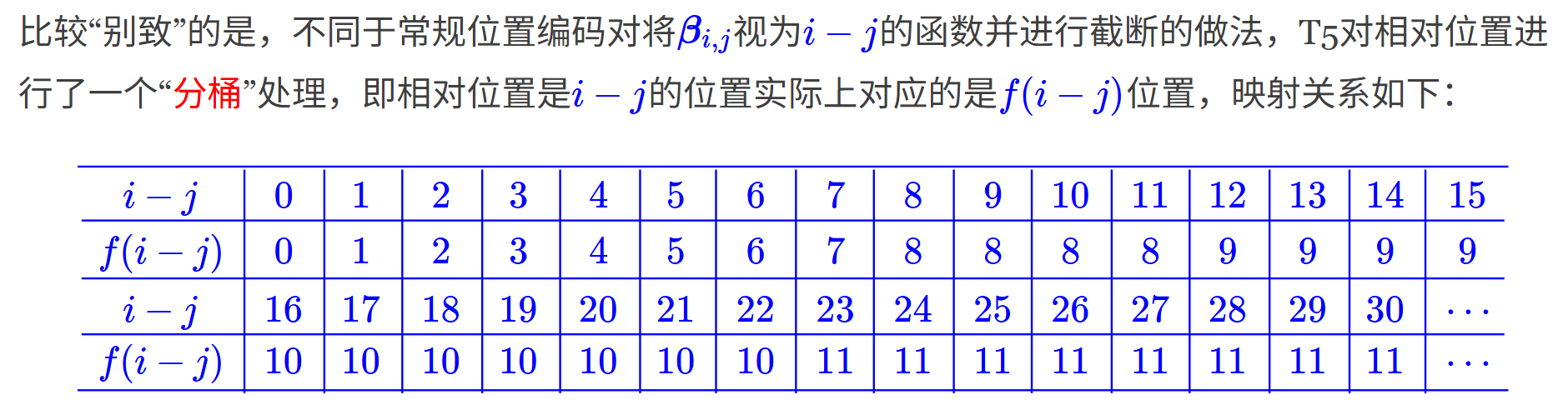
比较邻近的位置(0~7),我们需要比较得精细一些,所以给它们都分配一个独立的位置编码,至于稍远的位置(比如8~11),我们不用区分得太清楚,所以它们可以共用一个位置编码,距离越远,共用的范围就可以越大
使用了一个固定长度的桶(bucketing)机制,将相对距离映射到有限数量的位置上。可以控制最大相对距离,例如 max_relative_position = 32。每个 token 对之间的相对距离都会被映射进 bucket,然后查表获取 embedding。优点是节省参数、适合长序列。
Rotary Position Embedding(RoPE)
核心思想:假设向量 x 和 y 是二维向量, 如果将其绕原点旋转一定的角度, 那么改变的仅仅是两个向量之间的夹角, 此时, 将旋转后的向量点乘, 其结果一定包含 旋转弧度的相对信息
RoPE应添加在Q和K的注意力计算之前,通过旋转变换(Rotation)将位置信息嵌入到Query(Q)和Key(K)向量中。
如何实现外推?减小 theta 或增大 base(base 通常是 10000)

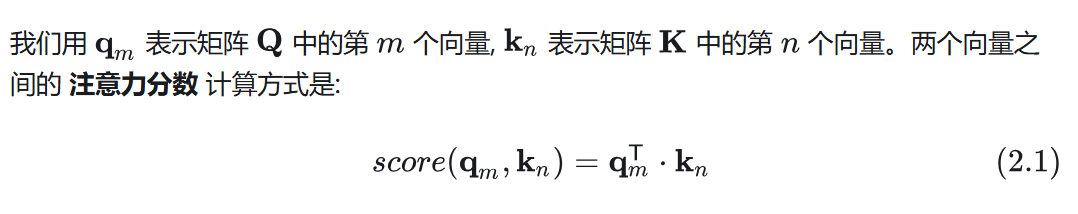


ReRoPE:核心思想是: 如果向量 q 和 k 的相对位置超过 w, 那么就进行 截断, 直接将其设置为 w。
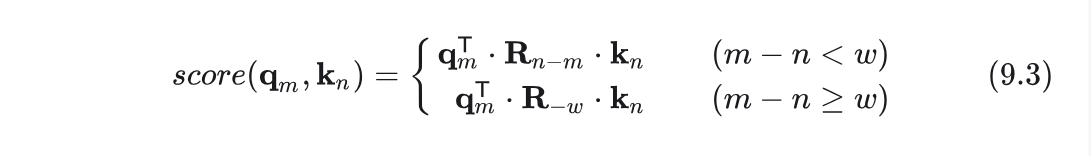
attention
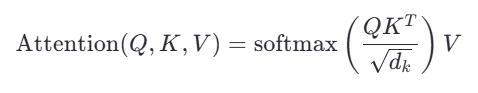
-
Q (Query): 查询矩阵,表示需要关注的位置(例如当前词)。
-
K (Key): 键矩阵,表示输入序列中每个位置的特征(例如其他词)。
-
V (Value): 值矩阵,表示输入序列中每个位置的实际信息(例如词向量)。
-
: 键向量的维度(Key的维度)。
-
: 缩放因子,用于稳定梯度。
:计算查询(Q)与键(K)之间的相似度。点积越大,表示两个向量越相似。
:当
较大时,点积
的值会变得非常大(因为每个维度的乘积相加),导致 softmax 函数的梯度消失。将点积除以
,使数值分布更稳定。假设每个维度的元素是独立同分布的随机变量,均值为 0,方差为 1。点积
的方差为
(因为
个独立项相加)。除以
后,方差变为 1。
为什么是,可以是吗
如果直接除以,点积会被过度缩小,导致注意力权重过于平缓(无法有效区分重要性)。
Softmax 函数
将相似度转换为概率分布(权重分布),确保所有权重的和为 1。高相似度的键会获得更高的权重,低相似度的键权重趋近于 0。
参考文章
Transformer Architecture: The Positional Encoding - Amirhossein Kazemnejad's Blog Let's use sinusoidal functions to inject the order of words in our model![]() https://kazemnejad.com/blog/transformer_architecture_positional_encoding/Transformer架构:位置编码(sin/cos编码)_transformer位置编码为啥用sin和cos-CSDN博客
https://kazemnejad.com/blog/transformer_architecture_positional_encoding/Transformer架构:位置编码(sin/cos编码)_transformer位置编码为啥用sin和cos-CSDN博客![]() https://blog.csdn.net/weixin_43406046/article/details/130745363#:~:text=%E4%BD%9C%E8%80%85%E6%8F%90%E5%87%BA%E7%9A%84%E7%BC%96%E7%A0%81%E6%96%B9%E6%B3%95%E6%98%AF%E4%B8%80%E4%B8%AA%E7%AE%80%E5%8D%95%E8%80%8C%E5%8F%88%E5%A4%A9%E6%89%8D%E7%9A%84%E6%8A%80%E6%9C%AF%EF%BC%8C%E6%BB%A1%E8%B6%B3%E4%BA%86%E4%B8%8A%E9%9D%A2%E6%89%80%E6%9C%89%E7%9A%84%E6%A0%87%E5%87%86%E3%80%82%E9%A6%96%E5%85%88%EF%BC%8C%E5%AE%83%E4%B8%8D%E5%8F%AA%E6%98%AF%E4%B8%80%E4%B8%AA%E6%95%B0%E5%AD%97%EF%BC%8C%E8%80%8C%E6%98%AF%E4%B8%80%E4%B8%AA相对位置编码(relative position representation) - 知乎
https://blog.csdn.net/weixin_43406046/article/details/130745363#:~:text=%E4%BD%9C%E8%80%85%E6%8F%90%E5%87%BA%E7%9A%84%E7%BC%96%E7%A0%81%E6%96%B9%E6%B3%95%E6%98%AF%E4%B8%80%E4%B8%AA%E7%AE%80%E5%8D%95%E8%80%8C%E5%8F%88%E5%A4%A9%E6%89%8D%E7%9A%84%E6%8A%80%E6%9C%AF%EF%BC%8C%E6%BB%A1%E8%B6%B3%E4%BA%86%E4%B8%8A%E9%9D%A2%E6%89%80%E6%9C%89%E7%9A%84%E6%A0%87%E5%87%86%E3%80%82%E9%A6%96%E5%85%88%EF%BC%8C%E5%AE%83%E4%B8%8D%E5%8F%AA%E6%98%AF%E4%B8%80%E4%B8%AA%E6%95%B0%E5%AD%97%EF%BC%8C%E8%80%8C%E6%98%AF%E4%B8%80%E4%B8%AA相对位置编码(relative position representation) - 知乎![]() https://zhuanlan.zhihu.com/p/397269153层次分解位置编码,让BERT可以处理超长文本 - 科学空间|Scientific Spaces
https://zhuanlan.zhihu.com/p/397269153层次分解位置编码,让BERT可以处理超长文本 - 科学空间|Scientific Spaces![]() https://spaces.ac.cn/archives/7947让研究人员绞尽脑汁的Transformer位置编码 - 科学空间|Scientific Spaces
https://spaces.ac.cn/archives/7947让研究人员绞尽脑汁的Transformer位置编码 - 科学空间|Scientific Spaces![]() https://spaces.ac.cn/archives/8130
https://spaces.ac.cn/archives/8130
旋转式位置编码 (RoPE) 知识总结 - 知乎![]() https://zhuanlan.zhihu.com/p/662790439
https://zhuanlan.zhihu.com/p/662790439
datawhalechina/happy-llm: 📚 从零开始的大语言模型原理与实践教程![]() https://github.com/datawhalechina/happy-llm Matthew E. Peters, Mark Neumann, Mohit Iyyer, Matt Gardner, Christopher Clark, Kenton Lee, and Luke Zettlemoyer. 2018. Deep Contextualized Word Representations. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), pages 2227–2237, New Orleans, Louisiana. Association for Computational Linguistics.
https://github.com/datawhalechina/happy-llm Matthew E. Peters, Mark Neumann, Mohit Iyyer, Matt Gardner, Christopher Clark, Kenton Lee, and Luke Zettlemoyer. 2018. Deep Contextualized Word Representations. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), pages 2227–2237, New Orleans, Louisiana. Association for Computational Linguistics.
Deep Contextualized Word Representations![]() https://aclanthology.org/N18-1202.pdf
https://aclanthology.org/N18-1202.pdf


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









