






目录
概述
纵观现在使用的分布式架构,不管服务于什么业务形式,高可用都是绕不开的一个话题,我把高可用分为自己业务应用的高可用(业务开发同学来保证)和中间件(nosql数据库,关系型数据库,消息中间件)的高可用,高可用方案是互通的,可以相互借鉴。
通用高可用方案
主从模式
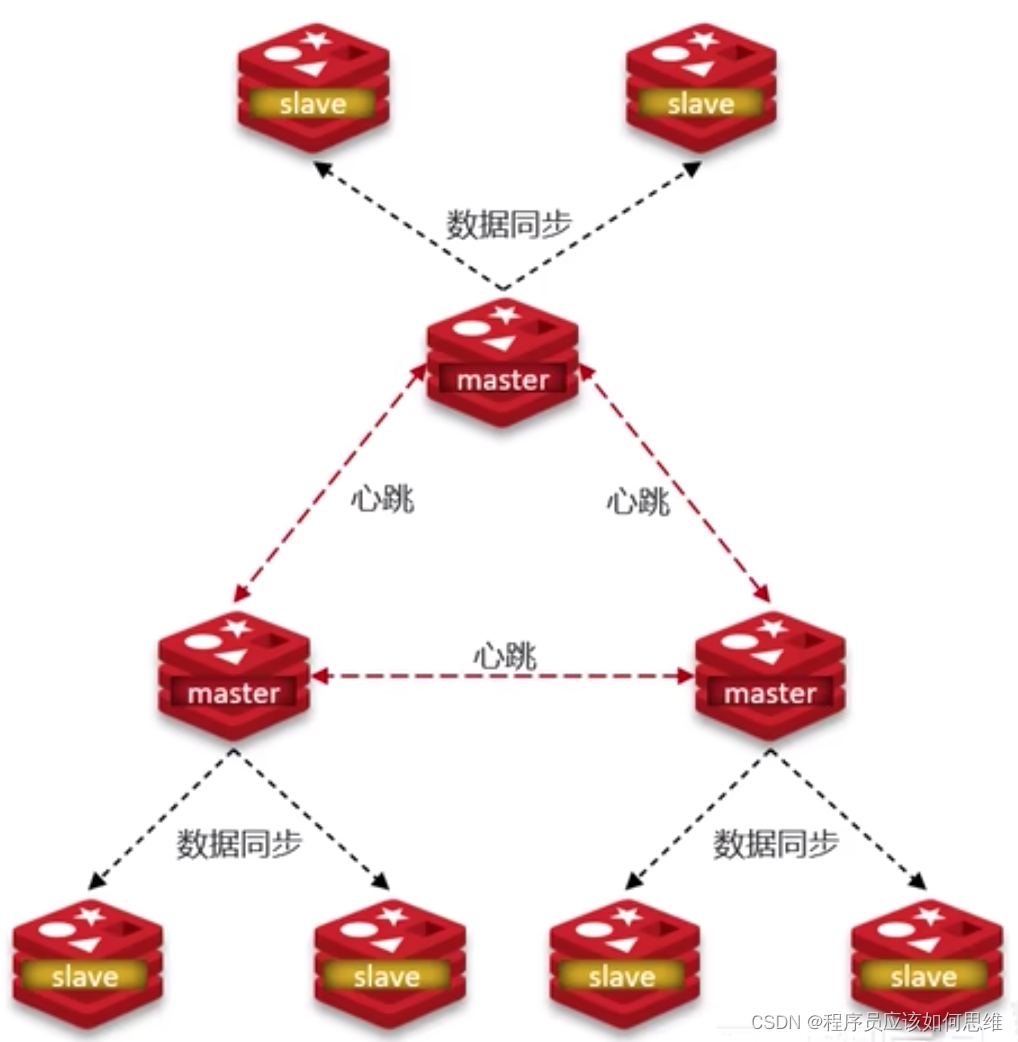
一般中间件都会提供主从模式来维持高可用性,一主一从或者一主多从,一般主节点主要作用是进行数据的读写操作,而从节点可以分担读数据的压力,从而保证业务读数据的读写能力;因为写操作只在主节点,所以使用有主从数据复制或者数据同步来维持主从数据的一致性(关于数据一致性操作下篇文章),基本架构图,以redis主从架构图为例:
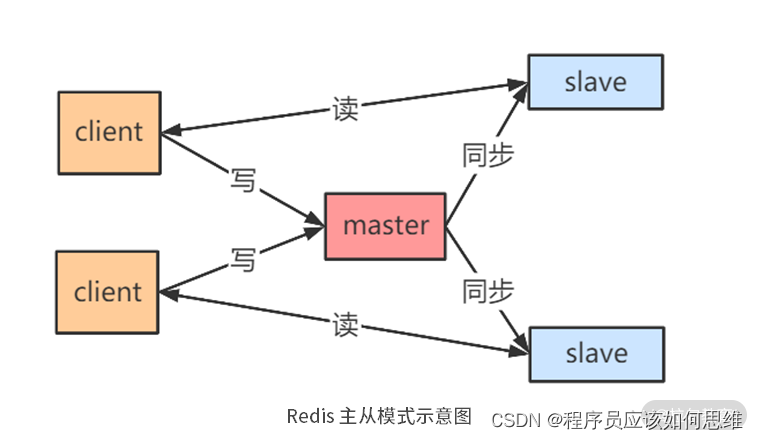
关于主从节点中问题的解决
主节点一旦挂掉以后,需要使用一定的策略来产出新的主节点来,一般的选举策略就是选择数据和原来主节点保持一致的从节点来作为主节点。
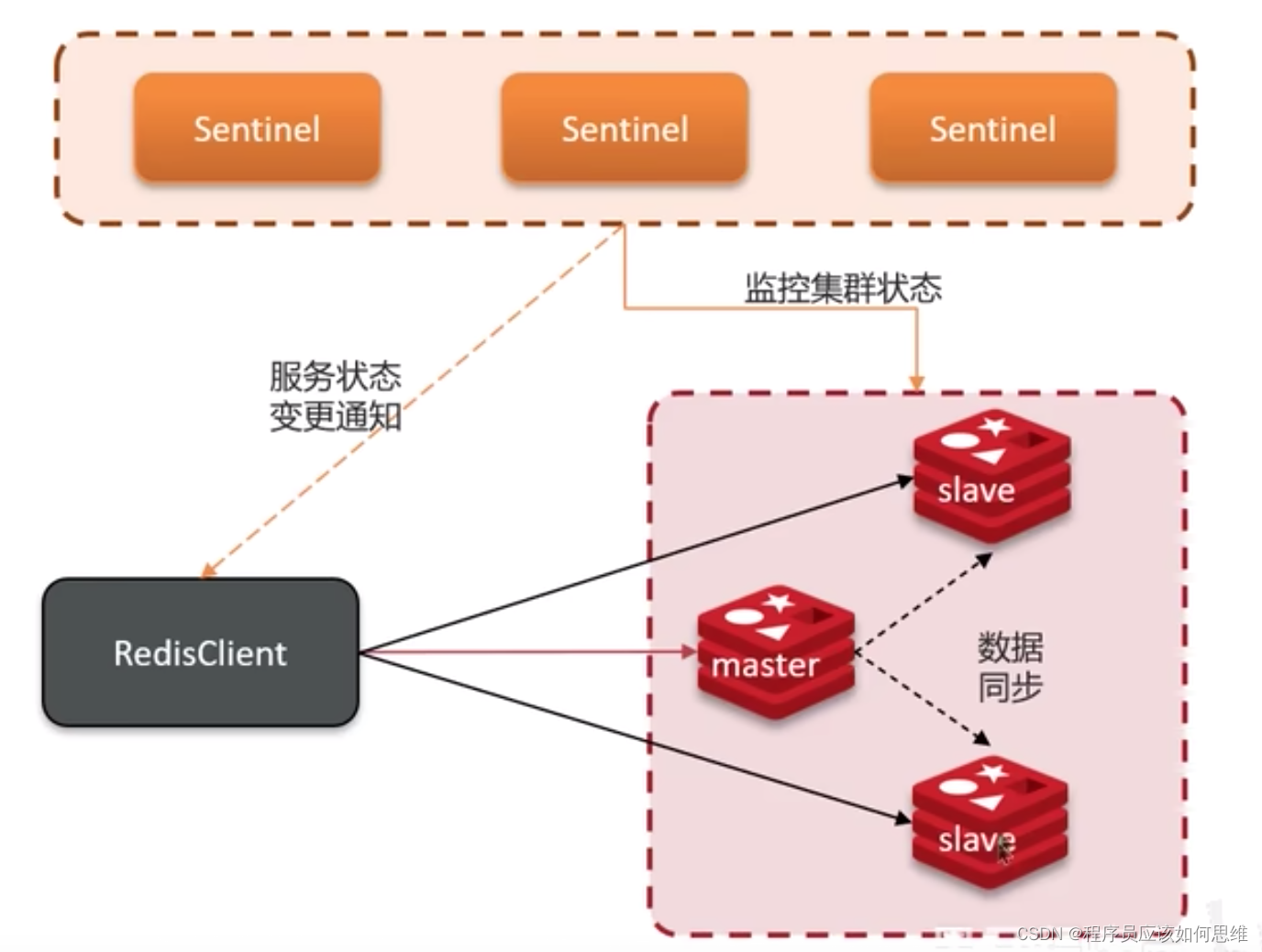
缓存数据库(redis)
加入的哨兵节点来完成主节点的选举工作,形成了主从模式的升级版哨兵模式,哨兵节点不光可以使用主节点的选举,还可以检测各个节点的健康状态。
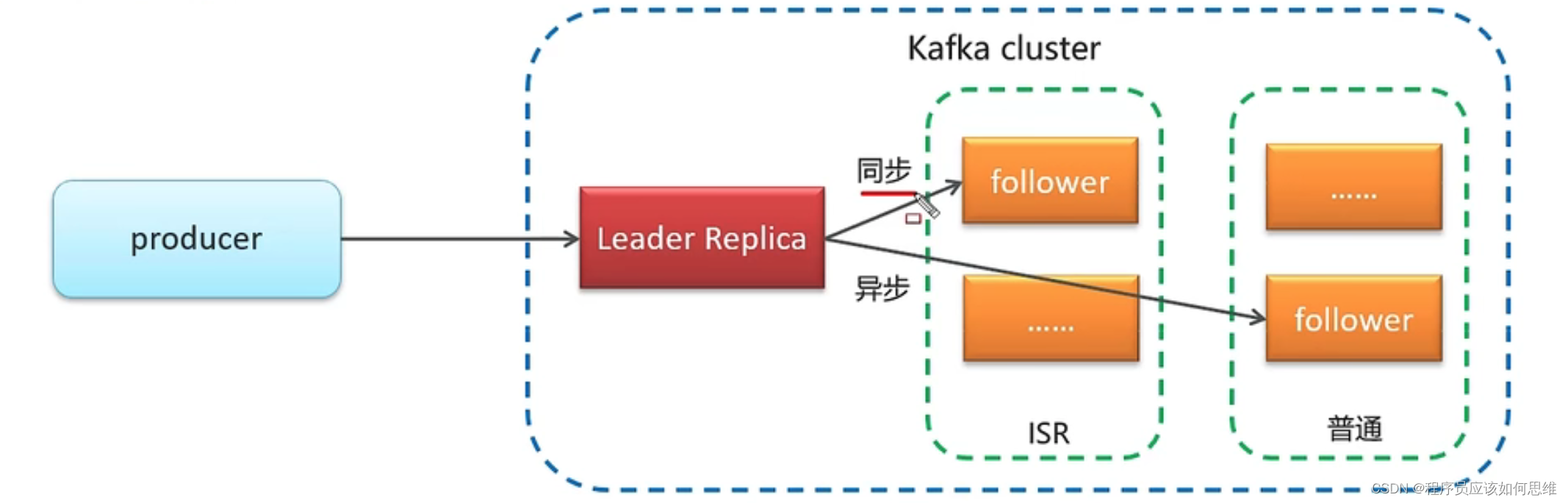
消息中间件(kafka)
使用ISR(同步方式保持数据一致性的分区节点,一般该节点数据是最完成的)分区节点来作为主节点
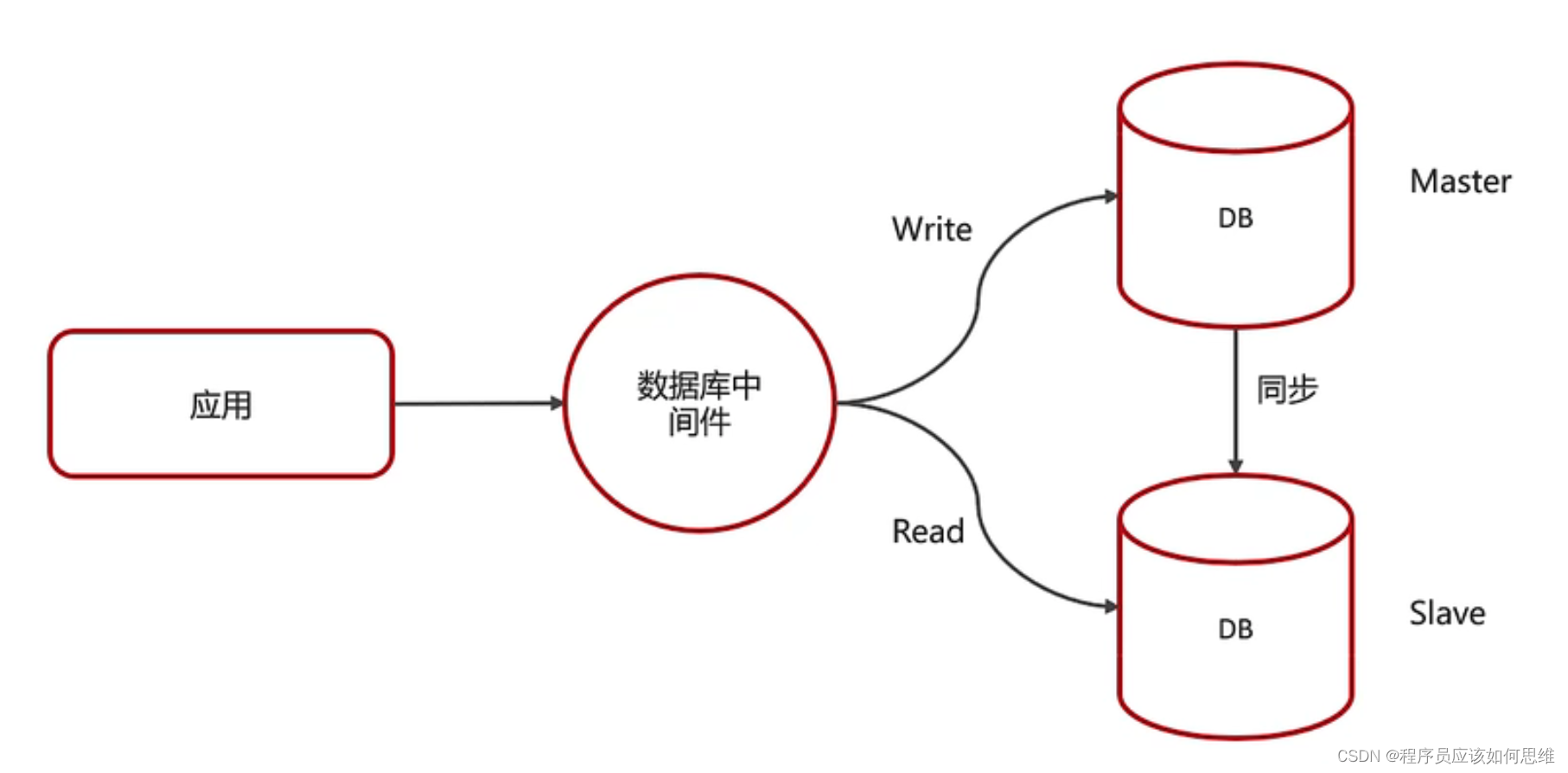
关系型数据库(mysql)
由于关系型数据库持久化存储了业务数据,对于mysql的主从架构,当主节点宕机后,需要将业务访问切换的从节点,因为数据需要持久化到硬盘,所以一般数据同步比较慢,数据同步的问题成为mysql主从架构的关键性问题,关于数据同步涉及到一些比较经典的方案(异步复制和半同步复制),下篇文件会进行分析,mysql主从架构方案图如下:

集群模式
集群模式属于比主从模式更加完善的高可用方案,对于高并发,高流量,海量数据有更好的适用性,一般集群模式属于主从模式的扩展,一个集群中会包含多组主从节点,而每一组主从节点存储的数据可能不同,从而使数据的存储能力和中间件对海量数据写操作,高流量的适应成为可能,一般适用于中大规模公司。
缓存数据库(redis)
分片集群模式:
集群中有多个主节点
每个master保存不同的数据
每个主节点有多个从节点
每个主节点直接彼此进行健康检测
架构图如下:
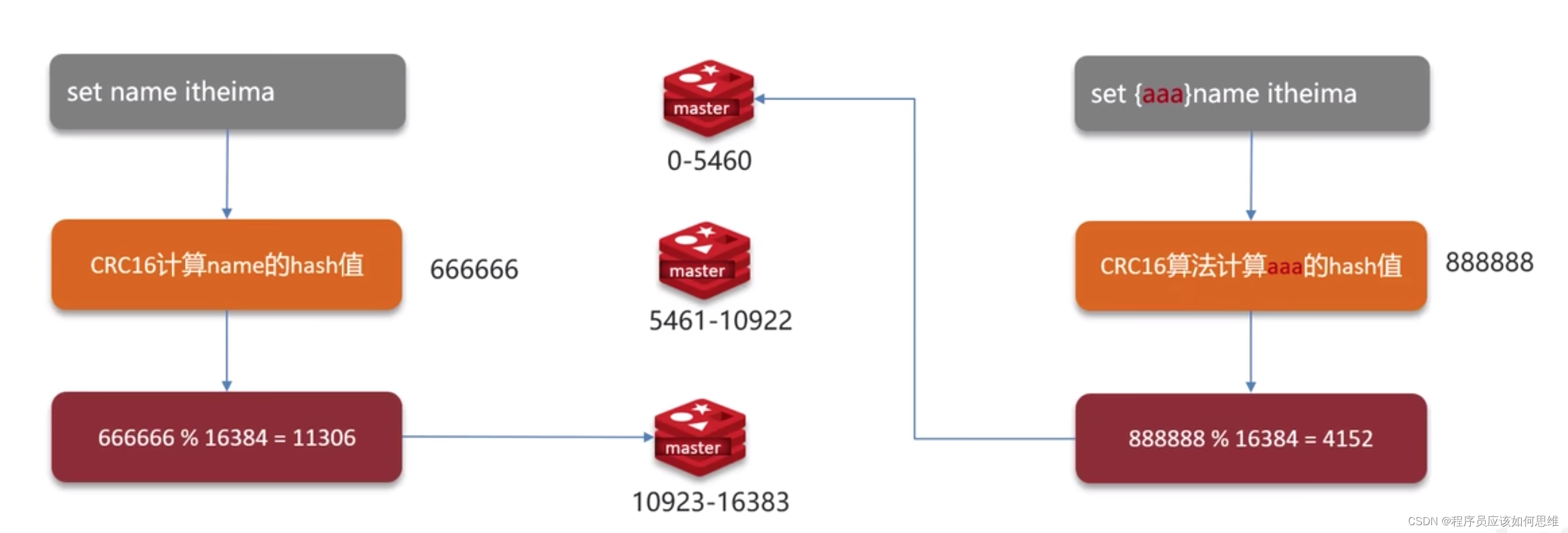
数据读写策略,引入了hashh槽的概念,hash槽就是把所有的物理节点映射到[0-16383]个slot上,对key采用crc16算法得到hash值后对16384取模,基本上采用平均分配和连续分配的方式。
消息中间件(kafka)
因为zookeeper来管理集群,zookeeper中主要存储kafka的元数据(关于元数据可以自行百度)和消费者消费数据的偏移量,有了这两个数据以后zookeeper就可以定位kafka消息队列的主要信息以及消费者消费过程中broker挂掉如果更好的保证reblance,从而避免重复消费和无法消费的问题

关系型数据库(mysql)
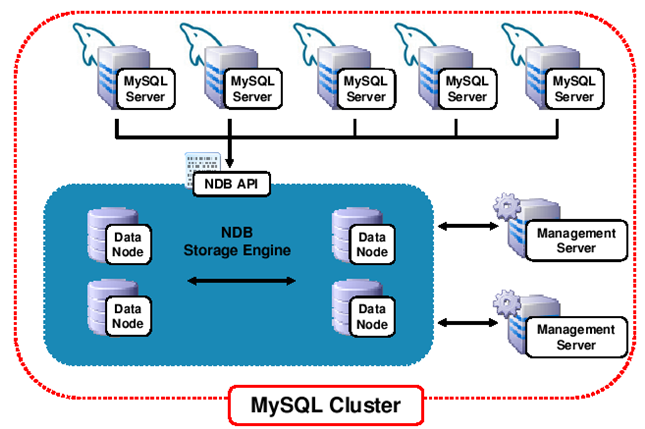
MySQL 集群包含两个关键部分--sql node(MySQL Server)、data node(storage或者ndbd)
数据节点主要完成数据的持久化存储,服务节点主要提供给应用程序访问的前端
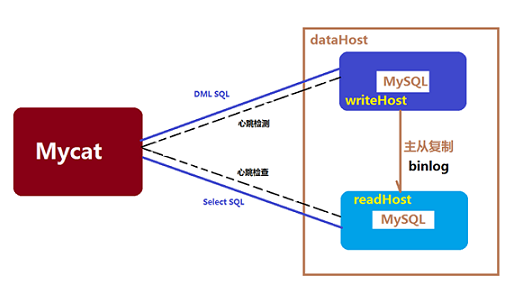
可以借助Mycat来实现集群模式,从定义和分类来看,它是一个开源的分布式数据库系统,是一个实现了MySQL协议的服务器,前端用户可以把它看作是一个数据库代理,用MySQL客户端工具和命令行访问,而其后端可以用MySQL原生协议与多个MySQL服务器通信,也可以用JDBC协议与大多数主流数据库服务器通信,其核心功能是分表分库,即将一个大表水平分割为N个小表,存储在后端MySQL服务器里或者其他数据库里。
mycat架构图:
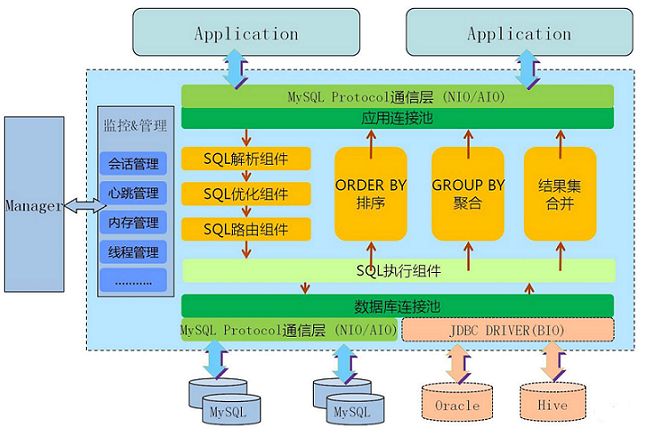
另外mycat还支持基于MySQL主从复制状态的高级读写分离控制机制


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









