






若想深入探究大模型核心参数的效果与作用,就务必先弄清大模型的工作流程,明确核心参数在流程各阶段的效能与功能,知晓其具体含义。
一,大模型的工作流程
大模型运行时的工作原理可以概括为输入处理→特征提取→模型推理→结果生成四个核心阶段,整个过程融合了深度学习架构、自然语言处理技术以及分布式计算能力。
从用户输入到大模型输出,整个工作的处理流程如下:
输入文本 → 分词 → 嵌入 + 位置编码 → Transformer多层处理(自注意力 + FFN) → Logits → 采样 → Token生成 → 循环直至终止 → 后处理 → 最终输出
通过上述流程,大模型实现了从原始输入到智能输出的端到端处理,其核心优势在于Transformer架构对长距离依赖的捕捉能力,以及海量参数对复杂模式的记忆与泛化实际应用中还需结合业务场景优化采样策略与后处理逻辑。下面我将对市场成熟模型的具体工作过程以及相关概念进行介绍。
(一)输入处理阶段
1.内容审查(部分模型适用)
用户输入文本首先经过敏感词过滤和合规性检查(如阿水AI大模型算法中的审查机制),确保生成内容符合伦理与法律规范。
2.分词(Tokenization)
输入文本被拆解为Token(如单词、子词或字符)。例如“Hello, AI!”可能被拆分为
['Hello', ',', 'AI', '!']
分词方法包括BPE、WordPiece等,依赖预训练的分词器实现。
3.文本预处理
包括统一大小写、去除停用词(如“的”“和”)、处理标点符号等,以降低噪声干扰
(二)向量化与位置编码
1.向量嵌入(Embedding)
每个Token通过嵌入层转换为高维向量(如768维),该向量包含语义和语法信息。例如“猫”和“狗”的向量在嵌入空间中距离较近,而“猫”和“计算机”的向量距离较远。
2.位置编码(Positional Encoding)
为每个Token添加位置信息,因为Transformer架构本身不具备顺序感知能力,需通过正弦函数或可学习参数为Token添加位置信息,确保模型理解词序(如“猫追狗”与“狗追猫”的区别)。
(三)Transformer核心处理阶段
输入向量经过多层Transformer结构(如GPT-3有96层),每层包含两个核心模块:
1.自注意力机制(Self-Attention)
通过自注意力机制实现全局语义捕捉,彻底改变传统RNN/CNN的序列处理模式。该机制允许模型动态计算每个token与序列其他位置的关联权重,例如在"猫追老鼠"的语境中,能自动建立"追"与"猫""老鼠"的语义联系。相较于RNN的线性计算,这种并行处理能力使计算效率提升10倍以上。并行计算多组注意力权重,动态聚焦关键上下文。
公式:
Attention
(
Q
,
K
,
V
)
=
softmax
(
Q
K
T
d
k
)
V
\text{Attention}(Q,K,V) = \text{softmax}\left( \frac{QK^T}{\sqrt{d_k}} \right)V
Attention(Q,K,V)=softmax(dkQKT)V
- 符号说明:
- Q Q Q:查询矩阵(Query)
- K K K:键矩阵(Key)
- V V V:值矩阵(Value)
- d k d_k dk:键向量的维度(用于缩放点积,防止梯度爆炸)
2.前馈神经网络(Feedforward Network)
通过线性变换和非线性激活(如ReLU)进一步提取特征,公式为:
公式:
FFN
(
x
)
=
max
(
0
,
x
W
1
+
b
1
)
W
2
+
b
2
\text{FFN}(x) = \max(0, xW_1 + b_1)W_2 + b_2
FFN(x)=max(0,xW1+b1)W2+b2
- 符号说明:
- W 1 , W 2 W_1, W_2 W1,W2:权重矩阵(维度变换: d model → d ff → d model d_{\text{model}} \to d_{\text{ff}} \to d_{\text{model}} dmodel→dff→dmodel)
- b 1 , b 2 b_1, b_2 b1,b2:偏置项
- max ( 0 , ⋅ ) \max(0, \cdot) max(0,⋅):ReLU激活函数
(四)推理与结果生成阶段
-
输出转换与概率分布
模型最后一层将隐藏状态映射为词表大小的Logits向量,通过Softmax函数转换为概率分布,表示每个Token的生成可能性。
-
采样策略
-
贪心采样:选择最高概率的Token(易导致重复)
-
温度采样:调整概率分布的平滑度(温度值低则结果保守,高则更具创造性)
-
Top-p采样:在累积概率前p%的候选中随机选择(平衡多样性与相关性)
-
-
自回归生成
将新生成的Token重新输入模型,循环预测后续内容,直到达到终止条件(如输出结束符
<EOS>或达到最大长度限制)。
(五)后处理阶段
-
解码与文本拼接
将生成的Token序列还原为自然语言文本,例如将
['J', '.', 'K', '.', '罗琳']拼接为“J.K.罗琳”。
-
结果优化
去除冗余空格、修正标点格式,部分模型结合语法检查或人工审核确保可读性。
二,模型相关参数介绍
(一)vllm引擎参数对模型的性能影响
让我们先看一个vllm部署qwen3-32b模型的命令示例:
CUDA_VISIBLE_DEVICES=0,1 python -m vllm.entrypoints.openai.api_server \
--model /home/models/Qwen/Qwen3-32B \ #指定模型的下载路径
--served-model-name qwen3-32b \ #指定模型启动的名称,后续的api请求就使用该model—name
--dtype auto \ #表示让 vLLM 自动推断模型权重和计算时使用的数据类型
--trust-remote-code \ #表示允许加载并执行模型作者提供的自定义代码,为了支持那些未完全集成到官方库中的自定义模型
--gpu-memory-utilization 0.95 \ # 提升显存利用率
--tensor-parallel-size 2 \ # 保持双卡并行
--max-model-len 4096 \ # 限制最大序列长度
--block-size 16 \ # 优化缓存块大小
--max-num-seqs 16 \ # 提升并发吞吐
--enforce-eager \ #强制使用 PyTorch 的急切执行模式(Eager Execution),并禁用内核融合优化(如 CUDA Graphs)。其目的是在特定场景下牺牲部分性能以换取更高的兼容性或调试便利性。
--enable-chunked-prefill \ # 启用分块预填充
--enable-prefix-caching # 激活前缀缓存
--host 0.0.0.0 --port 7180 #该组参数用于配置网络服务的监听地址和端口。
接下来我们看看这些参数是如何影响模型工作的:
以下是qwen3-8b模型启动后的日志:
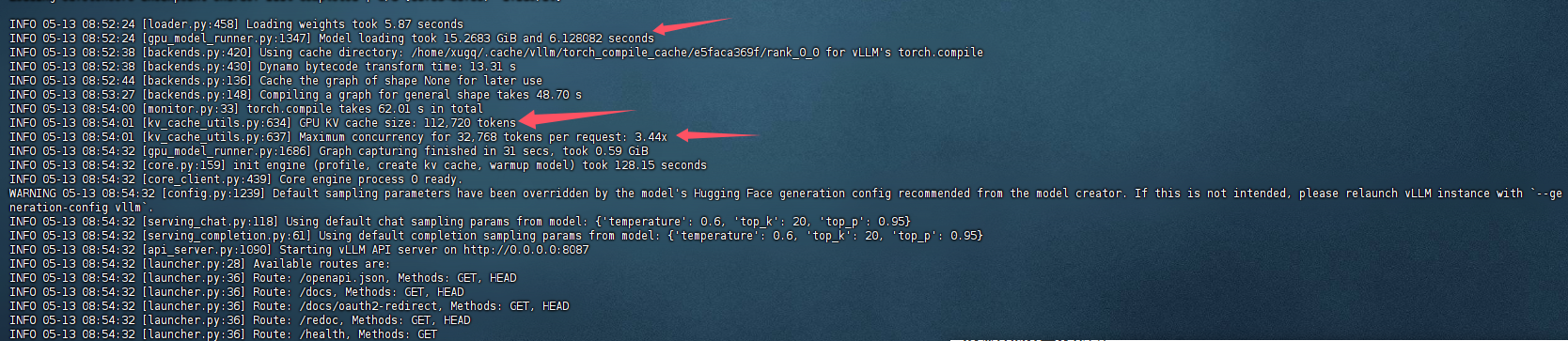
1.由日志:
INFO 05-13 08:52:24 [loader.py:458] Loading weights took 5.87 seconds
INFO 05-13 08:52:24 [gpu_model_runner.py:1347] Model loading took 15.2683 GiB and 6.128082 seconds
看出模型参数加载占用 15.27 GiB 显存,在 FP16 精度下,每个参数占用 2 字节,因此模型加载时的显存占用为 8B×2 字节 / 参数 ≈ 16GB。
2.由日志:
INFO 05-13 08:54:01 [kv_cache_utils.py:634] GPU KV cache size: 112,720 tokens
INFO 05-13 08:54:01 [kv_cache_utils.py:637] Maximum concurrency for 32,768 tokens per request: 3.44x
看出:KV缓存(键值缓存)的显存占用112,720 tokens。最大支持并发数 ≈3.44。其中kv显存是根据--gpu-memory-utilization指定模型占用显存分配比例,减去模型加载资源后自动预分配的。
KV缓存显存占用=2×层数×KV头数×头维度×Token数×(数据类型位数/8)
以日志中的数值为例,假设模型参数如下(以Qwen3-8B为例):
- 层数:32层
- KV头数:8(GQA结构)
- 头维度:128
- 数据类型:FP16(2字节)
- Token数:112,720
计算步骤:
-
单Token显存占用:2×32×8×128×816=131,072字节≈128KB
-
总显存占用:112,720 tokens×128KB=14,428,160KB≈13.76GB
-
单请求Block需求
单请求Block数=⌈max_model_len/block_size⌉
例如,若
max_model_len=32,768,block_size=16,则每个请求需2048个Block(32,768 / 16)。 -
最终并发数计算
最大并发数=(总Block数/单请求Block数)
例如,总Block数为7045(112,720 tokens / 16 tokens/Block),单请求需2048 Block,则并发数为
7045 / 2048 ≈ 3.44x。
(二)vllm引擎参数详细介绍
以下是vLLM参数的详细解释
核心性能参数:
-
block_size
- 作用:控制KV缓存块的大小(每个块存储的token数),影响内存碎片和利用率。
- 默认值:16(可选8/32/64等)。
- 调优建议:长文本场景增大(如32),小模型保持默认。
-
gpu_memory_utilization
- 作用:指定GPU显存分配比例(0-1),影响KV缓存大小和吞吐量。
- 默认值:0.9(A100/H100安全值,低端GPU建议0.8)。
- 性能影响:提高至0.9可增加20-30%吞吐量。
-
max_num_seqs
- 作用:单次迭代处理的最大并发序列数,影响调度效率。
- 默认值:256(推荐512-1024,受显存限制)。
- 注意:过高可能导致OOM。
-
max_model_len
- 作用:模型单次处理的****输入+输出****总 Token 容量。决定模型可接收的输入文本长度与生成空间的综合上限(如
max_model_length=8192时,输入 4096 Token 则输出最多 4096 Token) - 调优建议:高并发场景降低,长文本场景提高。
5.max_tokens
- 作用:模型单次处理的****输入+输出****总 Token 容量。决定模型可接收的输入文本长度与生成空间的综合上限(如
-
*控制范围*:模型单次生成的***输出内容****最大 Token 数量6,7 -
-
*作用机制*:仅限制生成文本长度,与输入无关(如设置
max_tokens=100时,输出内容最多包含 100 Token) - -
*典型应用*:
-限制回答篇幅(如要求生成100字摘要)
- 避免生成过长冗余内容(如设定 `max_tokens=500` 控制故事续写长度)
并行与分布式:
- tensor_parallel_size
- 作用:张量并行GPU数量,用于单机多卡分布式推理(如70B模型需8卡)。
- 默认值:1(单卡)。
- pipeline_parallel_size
- 作用:多机流水线并行阶段数,需与
tensor_parallel_size配合。 - 默认值:1(仅限LLaMA/GPT2等特定模型)。
- 作用:多机流水线并行阶段数,需与
推理优化:
- enable_prefix_caching
- 作用:启用前缀缓存,复用共享前缀的KV缓存(如系统提示),提升聊天场景性能10-20%。
- 默认值:v1版本默认启用。
- enable_chunked_prefill
- 作用:将长输入分块处理,优化显存使用,长文本场景提升15-25%性能。
- 默认值:关闭(需显式启用)。
- enforce_eager
- 作用:强制使用PyTorch即时执行模式(禁用CUDA图),调试时启用,生产环境关闭。
- 默认值:False(混合模式性能更优)。
内存扩展:
- cpu_offload_gb
- 作用:每GPU卸载到CPU的内存大小(GiB),扩展虚拟显存。
- 默认值:0(不卸载)。
- 示例:
--cpu_offload_gb=4。
- swap_space
- 作用:每GPU的CPU交换空间(GiB),用于临时存储请求状态。
- 默认值:4(
best_of>1时需设置)。
其他关键参数:
- guided_decoding_backend
- 作用:指定结构化输出(如JSON/SQL)的解码引擎(如
outlines或xgrammar)。 - 默认值:
auto。
- 作用:指定结构化输出(如JSON/SQL)的解码引擎(如
- scheduling_policy
- 作用:请求调度策略,
fcfs(先到先服务)或priority(优先级)。 - 默认值:
fcfs。
- 作用:请求调度策略,
- disable_custom_all_reduce
- 作用:禁用自定义All-Reduce操作,解决NCCL超时问题。
- 使用场景:多卡部署报错时启用。
多模态相关:
- limit_mm_per_prompt
- 作用:限制每个提示的多媒体(如图片)数量,如
--limit_mm_per_prompt image5。
- 作用:限制每个提示的多媒体(如图片)数量,如
- min_pixels/max_pixels
- 作用:控制输入图像分辨率范围(如
min_pixels=256 * 28 * 28)。 - 默认值:模型相关(Qwen2-VL默认4-16384)。
- 作用:控制输入图像分辨率范围(如
量化与硬件:
- model_quantization
- 作用:权重量化方法(如
awq/gptq),减少显存占用。 - 选项:支持FP8/INT4等。
- 作用:权重量化方法(如
- mm_processor_kwargs
- 作用:多媒体处理器的额外参数(如图像预处理配置)。
性能调优建议:
- 高吞吐场景:增大
max_num_seqs和gpu_memory_utilization,启用enable_chunked_prefill。 - 长文本处理:增大
block_size和max_model_len,启用CPU卸载。 - 低延迟场景:减小
max_num_batched_tokens,使用优先级调度。
(三)模型参数
从下列图片中可以看到就算是qwen3同系列同参数规模下(235B)的模型也有不同的版本和命名方式,初次接触不免让人感到疑惑。下面让我来详细介绍一下大模型的命名背后的意义。
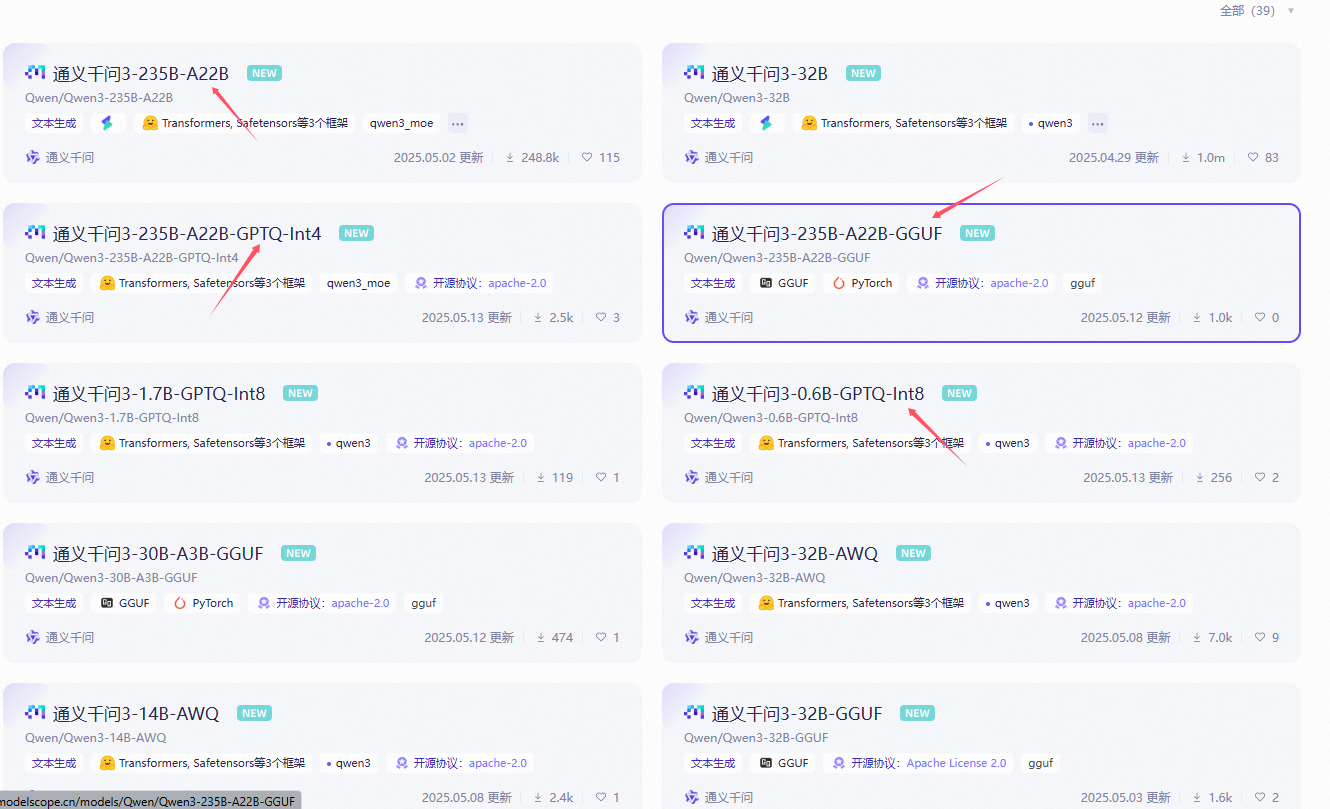
以Qwen3-235B-A22B-GPTQ-Int4为例:
Qwen3-235B-A22B-GPTQ-Int4 可拆解为五个核心部分:
[厂商前缀]-[参数量]-[激活参数]-[训练框架]-[量化精度]
↓ ↓ ↓ ↓ ↓
Qwen3 235B A22B GPTQ Int4
重点了解训练框架和量化精度对模型的影响:
以下是关于大模型中训练框架与量化精度对模型性能影响的深度解析,结合Qwen系列模型和行业实践:
训练框架(如GPTQ/AWQ)的核心影响
1. GPTQ(GPT-aware Quantization)
- 技术特点:
- 后训练量化(Post-training Quantization)
- 按权重分组优化(Group-wise Quantization)
- 基于Hessian矩阵的误差补偿
- 优势:
✅ 量化后精度损失小(<1% perplexity上升)
✅ 支持大batch推理加速(vLLM兼容性好)
✅ 显存占用直降75%(Int4 vs FP16) - 局限:
❌ 需要校准数据集(100-512样本)
❌ 仅量化权重,激活值仍用FP16
2. AWQ(Activation-aware Quantization)
- 技术特点:
- 激活值感知量化(识别敏感通道)
- 自适应缩放因子(Per-channel Scaling)
- 无需校准数据
- 优势:
✅ 更适合低显存设备(如RTX 4090)
✅ 动态范围保留更好(适合生成任务)
✅ 无需校准,即插即用 - 局限:
❌ 推理速度略慢于GPTQ(约10-15%)
❌ 量化工具链较新(社区支持弱于GPTQ)
3. FP8(NVIDIA原生量化)
- 技术特点:
- 8-bit浮点格式(E5M2/E4M3)
- TensorCore硬件加速
- 优势:
✅ 硬件加速(H100/A100专用)
✅ 精度无损(适合科学计算)
✅ 无需重训练 - 局限:
❌ 仅限NVIDIA Ampere+架构
❌ 显存节省有限(仅50%)
量化精度(如Int4/Int8)的影响维度
1. 显存占用对比
| 精度 | 权重存储量 | 235B模型显存需求 | 适用硬件 |
|---|---|---|---|
| FP16 | 16-bit | 235B×2B=470GB | 多卡集群(如8xA100) |
| Int8 | 8-bit | 235B×1B=235GB | 2-4卡中端GPU |
| Int4 | 4-bit | 235B×0.5B=117.5GB | 单卡+CPU卸载 |
2. 推理速度对比(以A100为例)
| 精度 | 生成速度(tokens/sec) | 延迟降低 | 适用场景 |
|---|---|---|---|
| FP16 | 120(基准) | - | 高精度需求 |
| Int8 | 180-200 | 1.5x | 实时对话系统 |
| Int4 | 220-260 | 2x+ | 批量数据处理 |
3. 精度损失实测(MMLU基准)
| 模型 | FP16准确率 | Int4准确率 | 下降幅度 |
|---|---|---|---|
| Qwen1.5-110B | 82.3% | 80.1% | 2.2% |
| LLaMA-2-70B | 68.9% | 66.5% | 2.4% |
| Mistral-8x7B | 72.1% | 70.8% | 1.3% |
关键选择策略
1. 硬件匹配原则
- 数据中心级GPU(A100/H100):优先选FP8 > GPTQ-Int4
- 消费级GPU(RTX 4090):AWQ-Int4 > GPTQ-Int4
- 边缘设备(Jetson):AWQ-Int4 + 模型蒸馏
2. 任务敏感度分析
| 任务类型 | 推荐量化方案 | 原因 |
|---|---|---|
| 数学推理 | FP16/FP8 | 数值精度敏感 |
| 长文本生成 | GPTQ-Int4 + CPU卸载 | 显存压力大,需高效管理 |
| 多轮对话 | AWQ-Int4 | 动态范围保留更优 |
| 代码生成 | GPTQ-Int8 | 语法结构敏感,需平衡精度 |
选型决策树
根据场景选择技术组合:
是否需要训练新模型?
├── 是 → 使用PyTorch训练
└── 否 → 进入部署优化阶段
├── 目标设备是手机/边缘端? → PyTorch静态量化
├── 需要极致推理速度? → GPTQ-Int4 + Triton推理
└── 显存极度紧张? → AWQ-Int4 + vLLM
(四)生成参数
采样参数主要作用于大语言模型的解码阶段(生成阶段),即在模型计算出下一个词元的概率分布后,通过调整概率分布形态或采样范围来控制生成结果的随机性与多样性。
温度参数(Temperature)
作用:控制生成文本的随机性和创造性。温度值越高,模型输出的概率分布越平滑,生成结果更随机、多样化;温度值越低,概率分布越尖锐,生成结果更保守、连贯
- 思考模式(
enable_thinking=True):建议设为 0.6,在保证逻辑性的前提下允许一定创造力,适合需要推理的复杂任务(如数学题)。 - 非思考模式(
enable_thinking=False):设为 0.7,略微增加随机性,适用于常规对话或需要多样性的场景(如创意写作)。
原理:温度值通过缩放模型输出的对数概率分布,改变词元选择的置信度。
核采样(TopP)
作用:动态选择累积概率超过阈值 p 的最小词元集合,平衡多样性与连贯性。例如,TopP=0.95 表示仅从概率最高的前95%词元中采样。
- 思考模式:设为 0.95,允许更广的候选范围,支持复杂推理。
- 非思考模式:设为 0.8,限制候选词数量,提高回答稳定性。
原理:TopP通过排除低概率词元减少无关输出的干扰,同时保留合理的多样性。例如,若候选词的概率分布为0.5、0.3、0.1,TopP=0.9时将选择前三个词元(累积概率0.9)。
候选词数量(TopK)
作用:固定选择概率最高的前 K 个词元作为候选池,限制生成范围。TopK=20 表示每次仅从最可能的20个词中随机选择。
- 适用场景:在两种模式下均设为 20,避免极端词元干扰,确保生成质量。
与TopP区别:TopK是静态截断,TopP是动态调整。两者可结合使用,例如TopK=20且TopP=0.95时,若前20个词元的累积概率已超过0.95,则实际候选池可能更小。
最小概率阈值(MinP)
作用:过滤掉概率低于动态阈值(pscaled=pbase×pmax)的词元,防止低质量输出。设为 0 时关闭该功能。
- 文档建议:两种模式均设为 0,可能因任务需求或模型版本调整。
原理:MinP根据当前最高概率词元动态调整阈值。例如,若最高概率为0.5且 pbase=0.1,则仅保留概率≥0.05的词元,避免极低概率词被选中。
存在惩罚(Presence Penalty)
作用:惩罚已生成词元的重复出现,鼓励多样性。取值范围 0-2,值越高,重复惩罚越强。
- 文档建议:根据框架支持情况设为 0-2,但需注意过高值可能导致语言混合或性能下降。
参数间的协同与权衡
| 参数组合 | 适用场景 | 效果特点 |
|---|---|---|
| 低T + 低top_p | 技术文档生成、代码补全 | 高确定性,输出与训练数据高度一致 |
| 高T + 高top_p | 创意写作、故事续写 | 多样性优先,可能包含非常规表达 |
| 中T + 动态k/p | 多轮对话、问答系统 | 平衡质量与多样性,避免重复回答 |
存在惩罚(Presence Penalty)
作用:惩罚已生成词元的重复出现,鼓励多样性。取值范围 0-2,值越高,重复惩罚越强。
- 文档建议:根据框架支持情况设为 0-2,但需注意过高值可能导致语言混合或性能下降。
参数间的协同与权衡
| 参数组合 | 适用场景 | 效果特点 |
|---|---|---|
| 低T + 低top_p | 技术文档生成、代码补全 | 高确定性,输出与训练数据高度一致 |
| 高T + 高top_p | 创意写作、故事续写 | 多样性优先,可能包含非常规表达 |
| 中T + 动态k/p | 多轮对话、问答系统 | 平衡质量与多样性,避免重复回答 |


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









