










目录
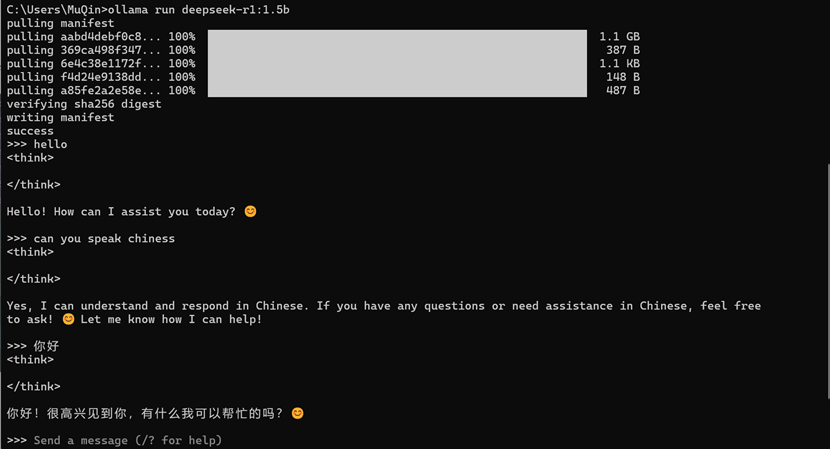
2.1.1下载安装ollama,并在cmd中执行ollama run deepseek-r1:1.5b命令:
8.5创建xiaozhi-prompt-temple.txt
LangChain4j 的目标是简化将大语言模型(LLM - Large Language Model)集成到 Java 应用程序中的过程
1.创建SpringBoot项目
1.1 创建maven项目
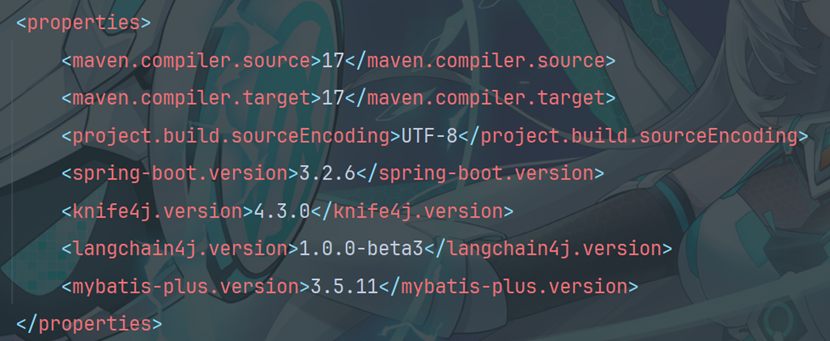
1.2导入相关依赖项
<properties>
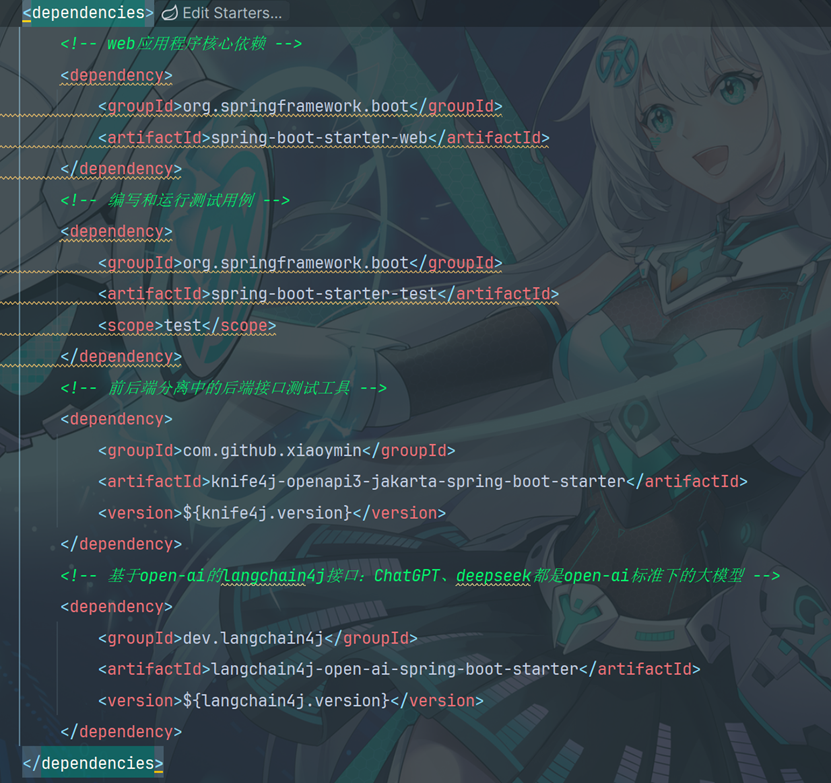
<dependencies>
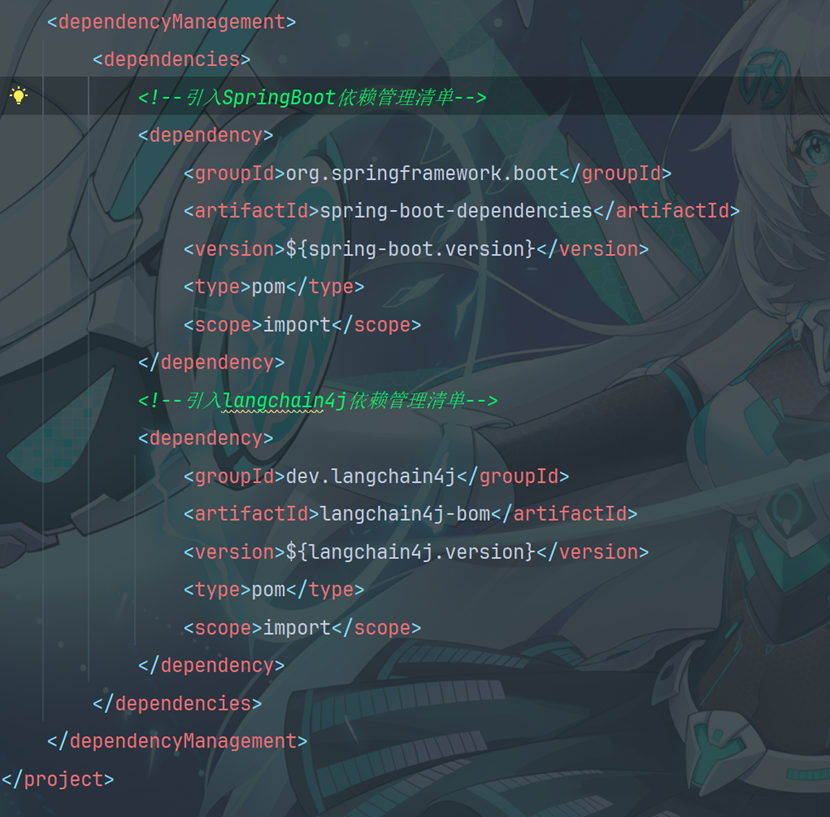
<dependencyManagement>
1.3配置模型参数
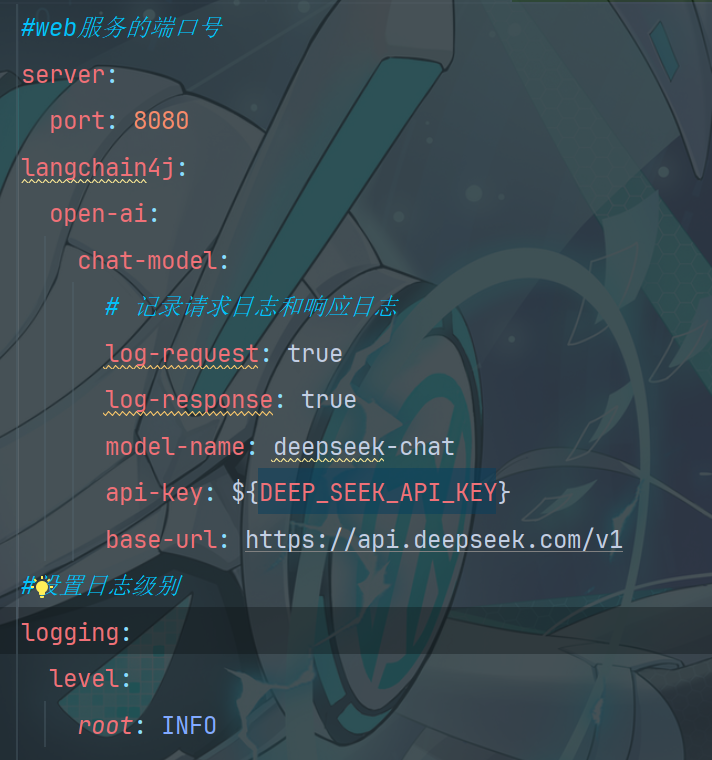
1.4创建测试类
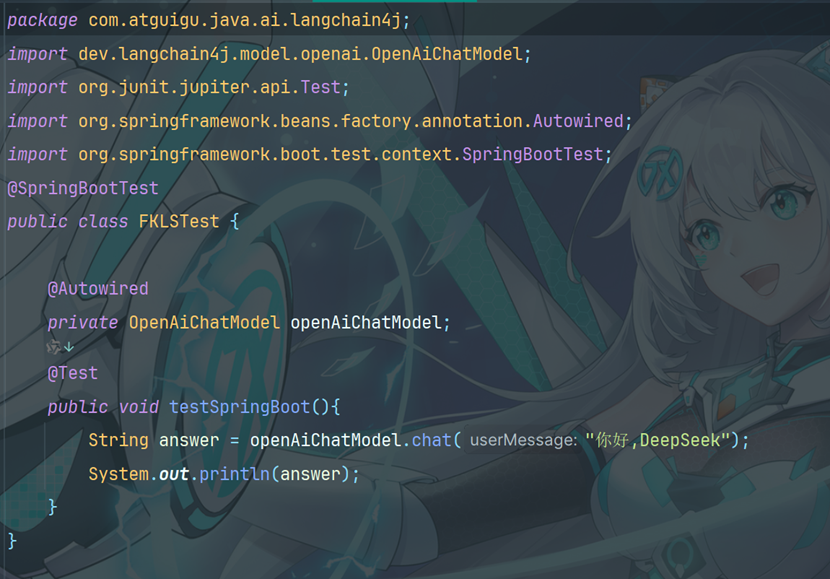
输出如下

2.ollama本地部署
Ollama 是一个本地部署大模型的工具。使用 Ollama 进行本地部署有以下多方面的原因:
数据隐私与安全:对于金融、医疗、法律等涉及大量敏感数据的行业,数据安全至关重要。
离线可用性:在网络不稳定或无法联网的环境中,本地部署的 Ollama 模型仍可正常运行。
降低成本:云服务通常按使用量收费,长期使用下来费用较高。而 Ollama 本地部署,只需一次性投 入硬件成本,对于需要频繁使用大语言模型且对成本敏感的用户或企业来说,能有效节约成本。
部署流程简单:只需通过简单的命令 “ollama run < 模型名>”,就可以自动下载并运行所需的模型。 灵活扩展与定制:可对模型微调,以适配垂直领域需求。
2.1在ollama上部署Deepseek
2.1.1下载安装ollama
并在cmd中执行ollama run deepseek-r1:1.5b命令:
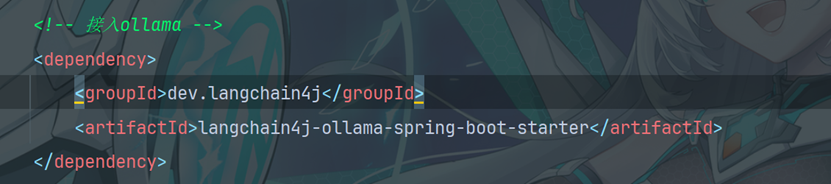
2.2导入ollama相关依赖
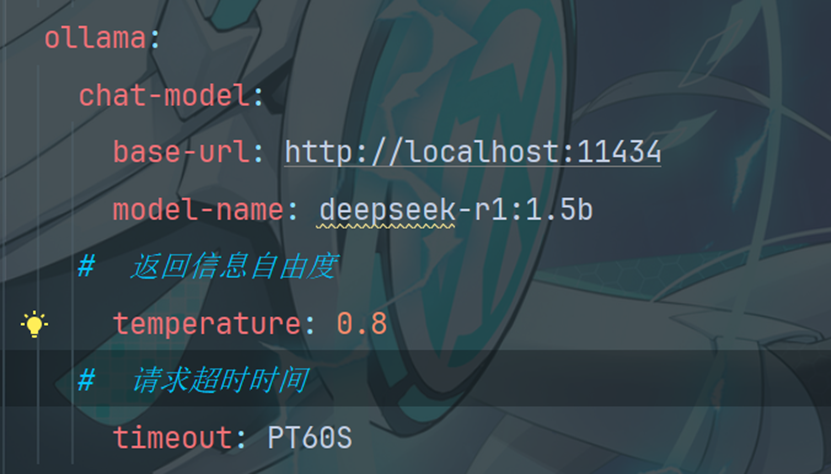
2.3添加配置模型参数
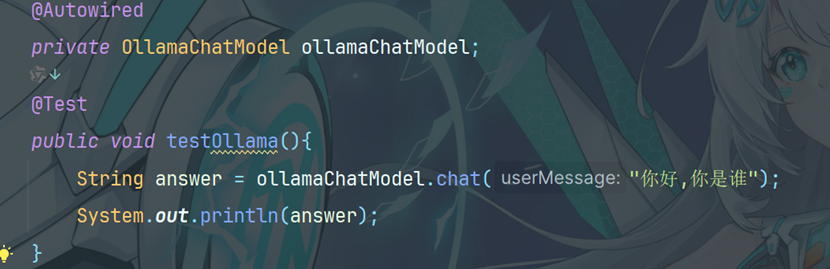
2.4编写测试方法
输出

3.接入阿里百炼
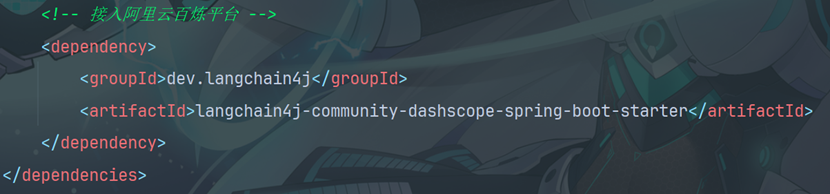
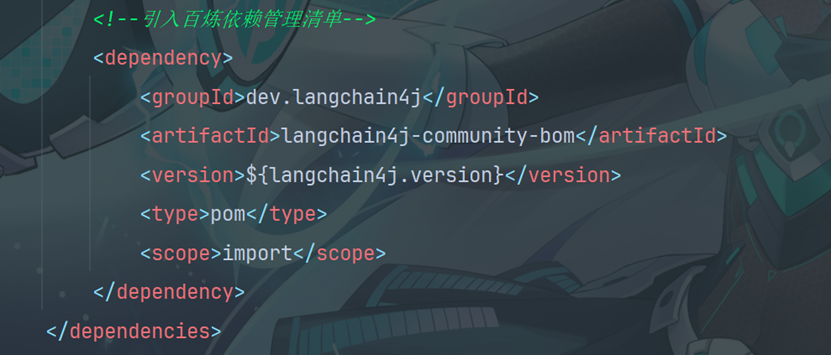
3.1导入依赖
3.2 配置模型参数
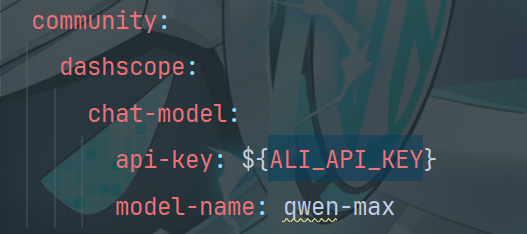
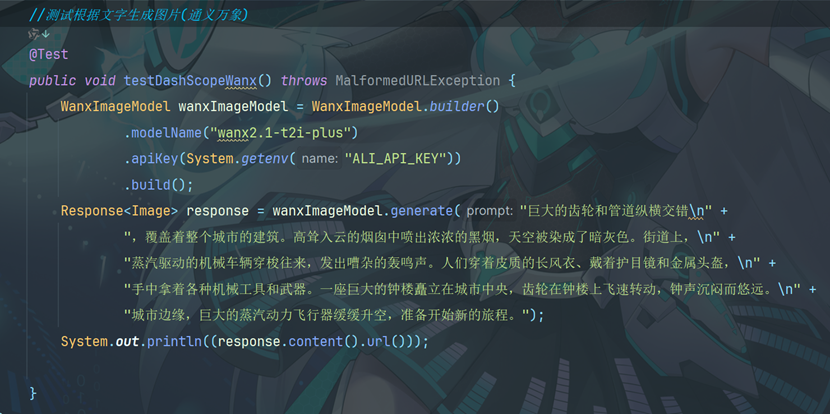
3.3 测试通义千问和通义万象
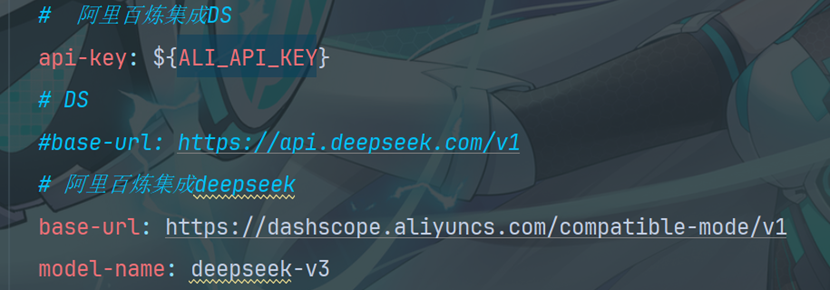
3.4阿里百炼集成Deepseek(配置模型参数)
直接运行测试类中testSpringBoot即可
4.人工智能服务AIService
4.1 AIService
AIService使用面向接口和动态代理的方式完成程序的编写,更灵活的实现高级功能
AIService可处理最常见的操作: 为大语言模型格式化输入内容 解析大语言模型的输出结果.
它们还支持更高级的功能: 聊天记忆 Chat memory 工具 Tools 检索增强生成 RAG
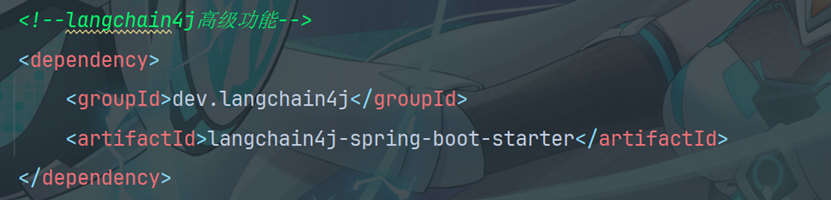
4.2 引入相关依赖
4.3 创建接口
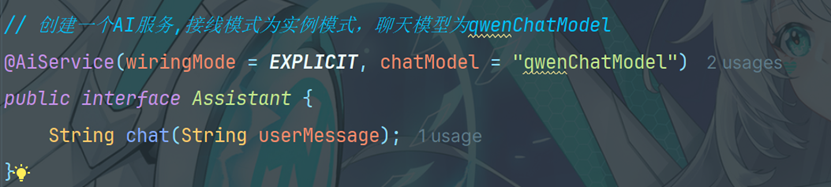
4.4编写测试方法
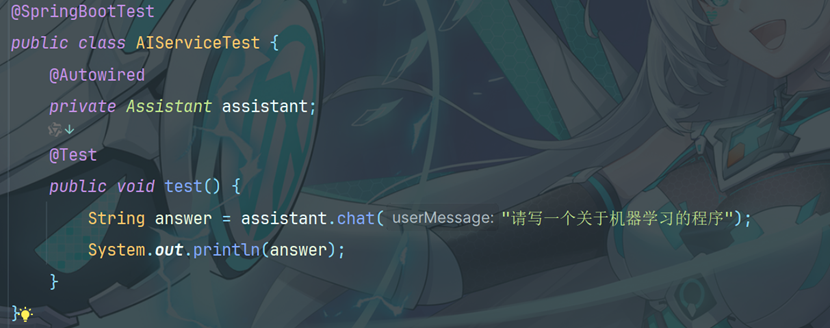
输出:

4.5原理
AiServices会组装Assistant接口以及其他组件,并使用反射机制创建一个实现Assistant接口的代理对象。 这个代理对象会处理输入和输出的所有转换工作。在这个例子中,chat方法的输入是一个字符串,但是大 模型需要一个 UserMessage 对象。所以,代理对象将这个字符串转换为 UserMessage ,并调用聊天语 言模型。chat方法的输出类型也是字符串,但是大模型返回的是 AiMessage 对象,代理对象会将其转换 为字符串。 简单理解就是:代理对象的作用是输入转换和输出转换
5.聊天记忆(chatmemory)
5.1 聊天记忆的简单实现
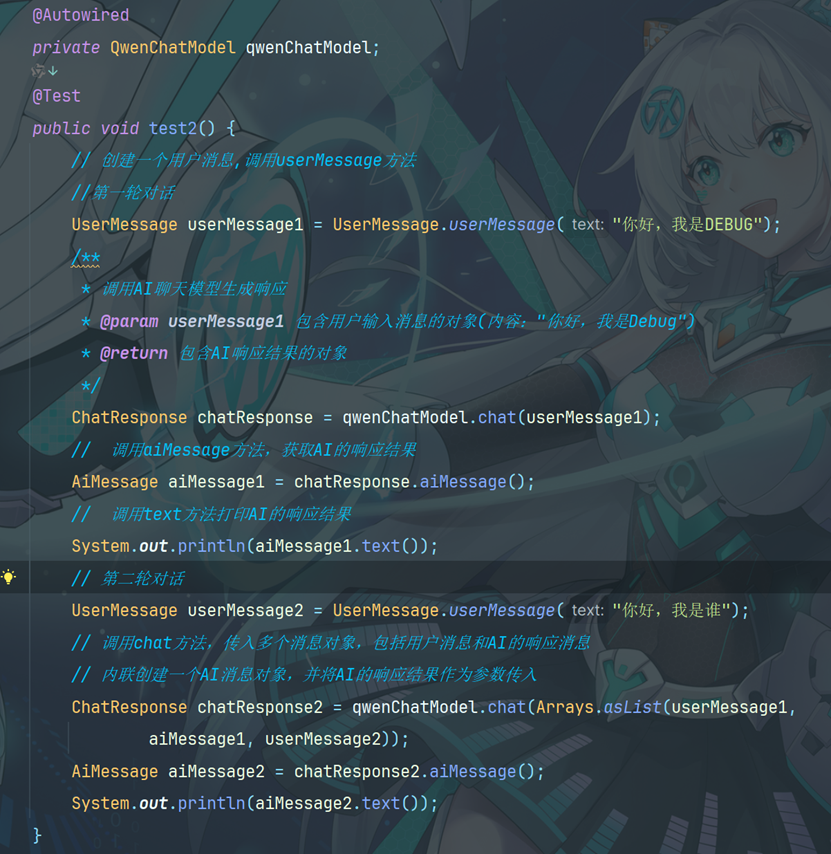

5.2创建MemoryChatAssitane接口
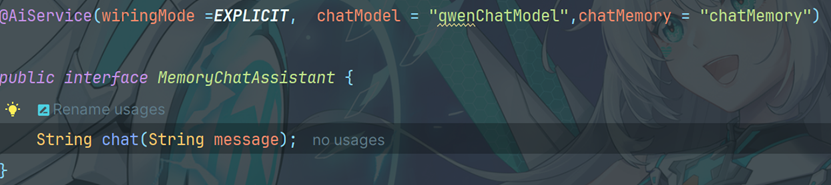
5.3创建配置类

5.4编写测试方法
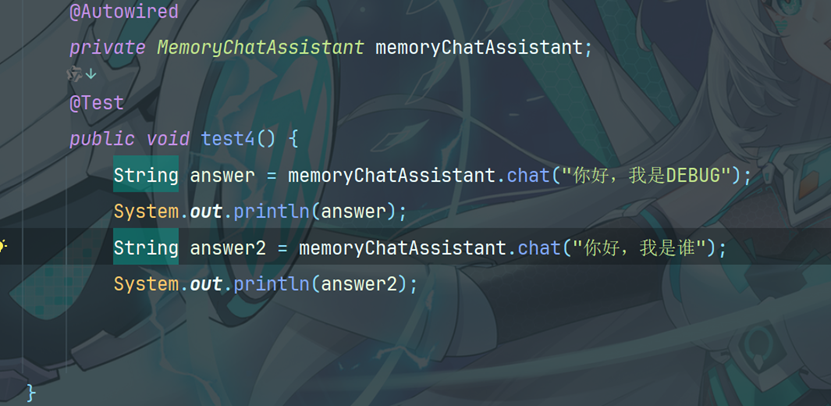
输出:
![]()
5.5隔离聊天记忆
5.5.1创建接口
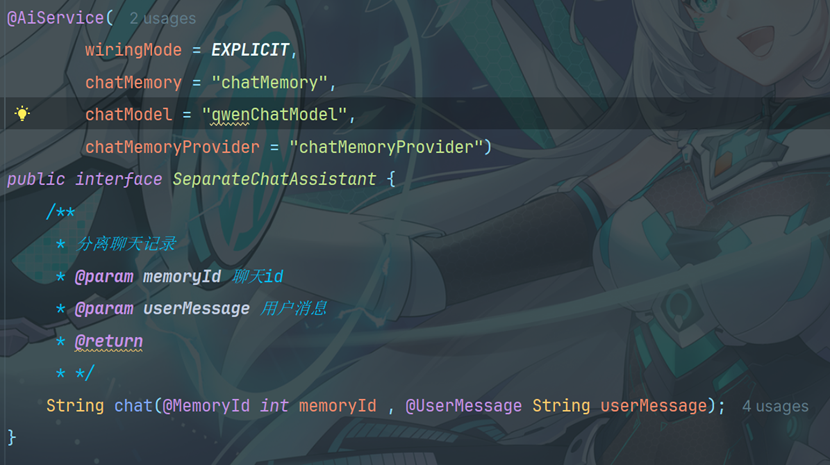
5.5.2配置模型参数
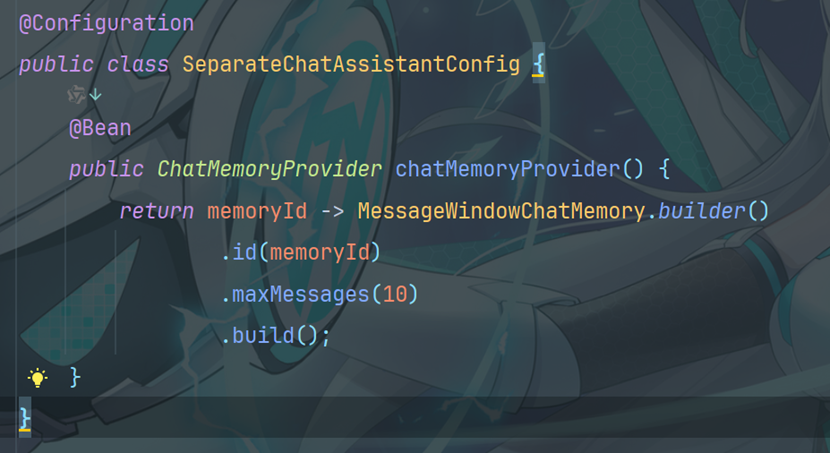
5.5.3 编写测试类

输出

6.持久化聊天记忆 Persistence
6.1优化实体类
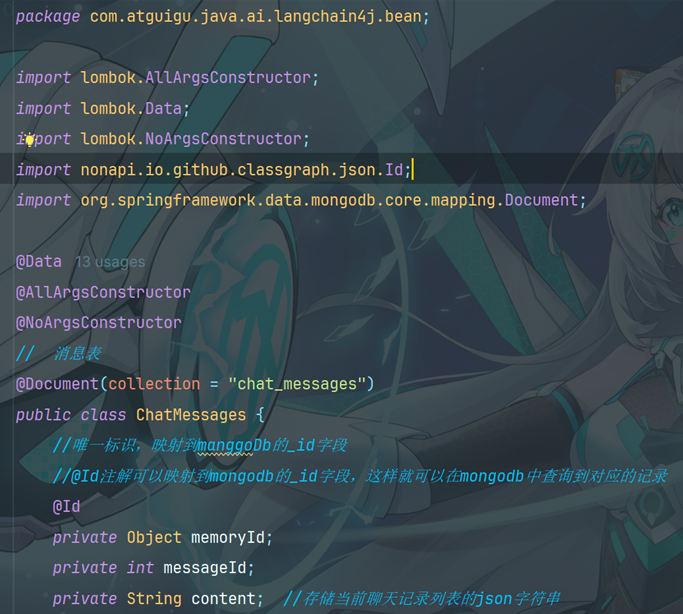
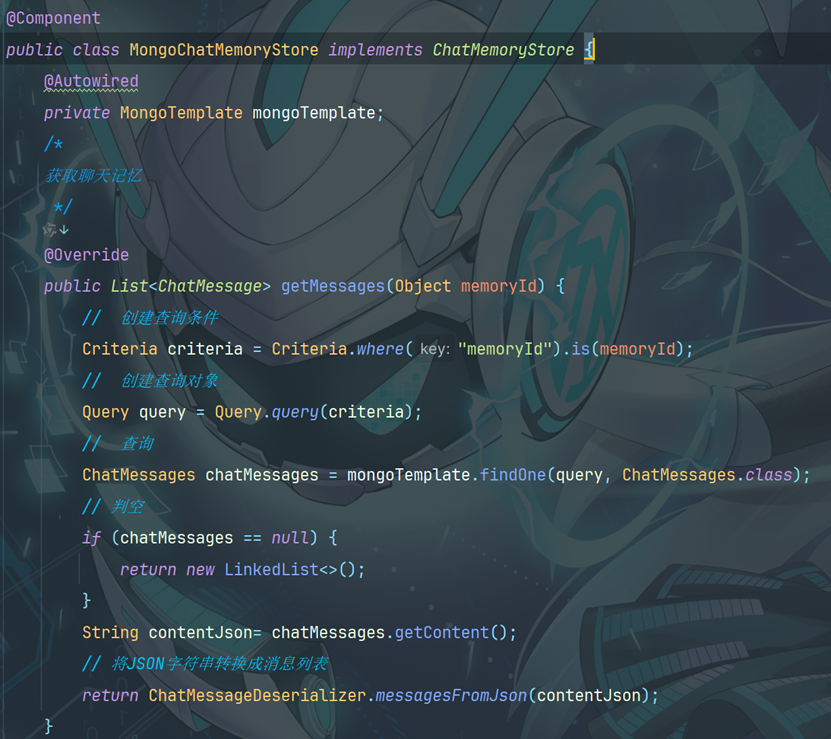
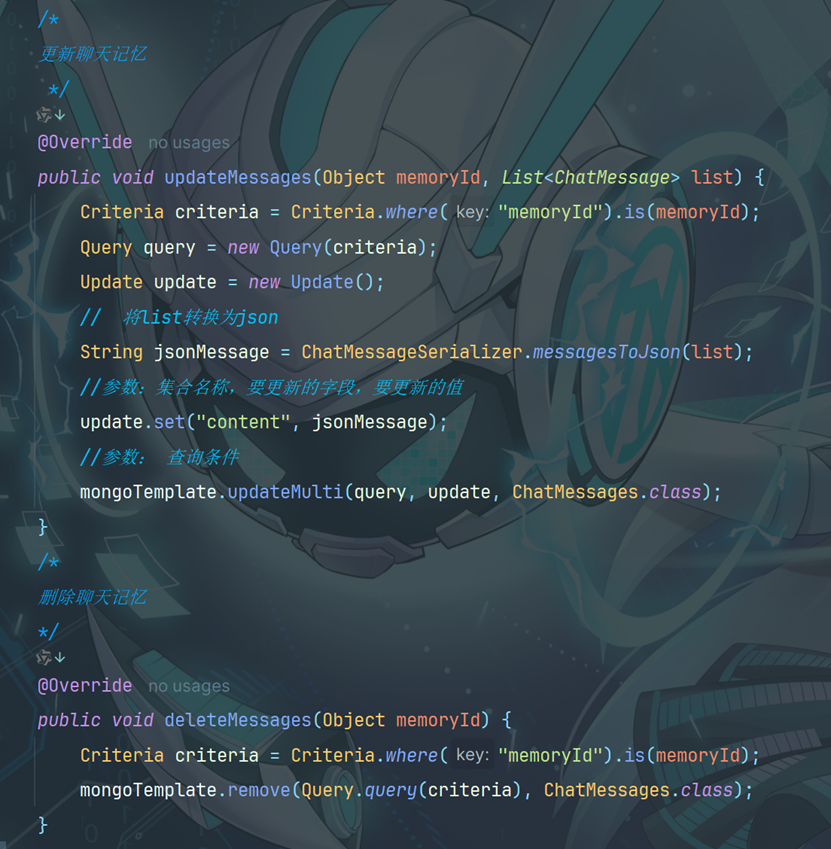
6.2 创建持久化类
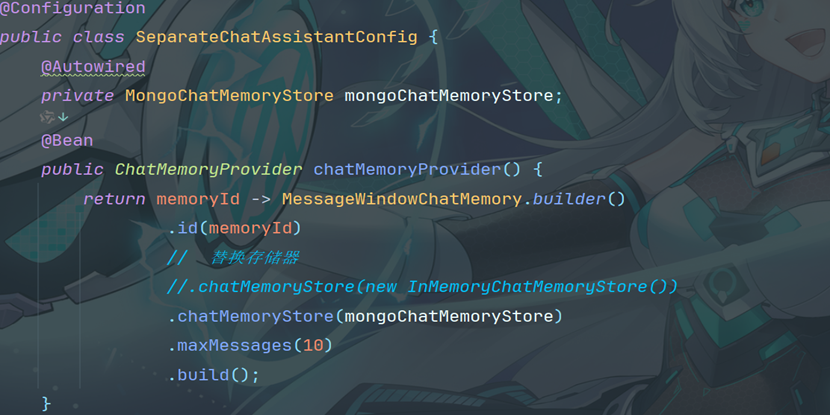
6.3 完善配置类
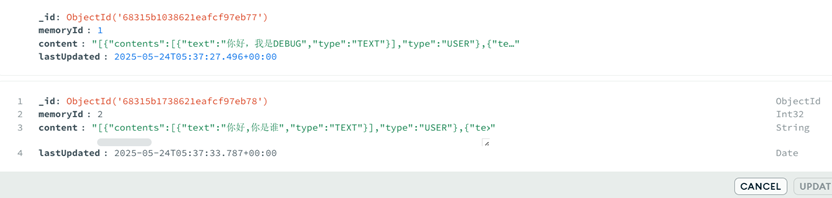
6.4 运行Test5测试方法测试即可
消息已经正确以json格式存储在了mongoDB中
7.提示词PromptTest
7.1 系统提示词
系统提示词 @SystemMessage 设定角色,塑造AI助手的专业身份,明确助手的能力范围
7.1.1配置@SystemMessage
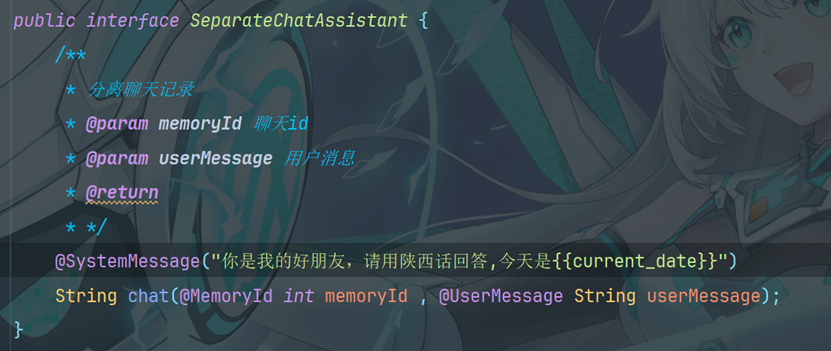
@SystemMessage 的内容将在后台转换为 SystemMessage 对象,并与 言模型(LLM)。 SystemMessaged的内容只会发送给大模型一次。 UserMessage 一起发送给大语 如果修改了SystemMessage的内容,新的SystemMessage会被发送给大模型,之前的聊天记忆会失效
7.1.2编写测试方法
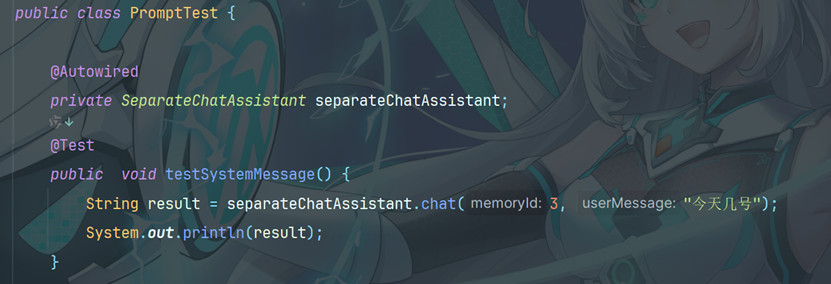
输出结果
JVM:

MongoDB:
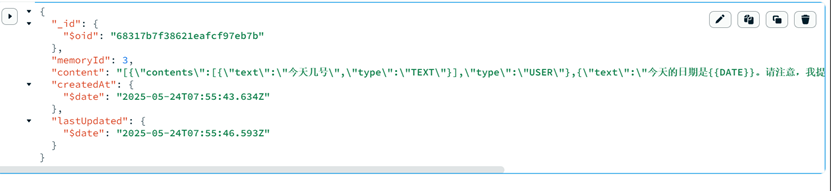
7.1.3 从资源中加载提示模板
@SystemMessage 注解还可以从资源中加载提示模板
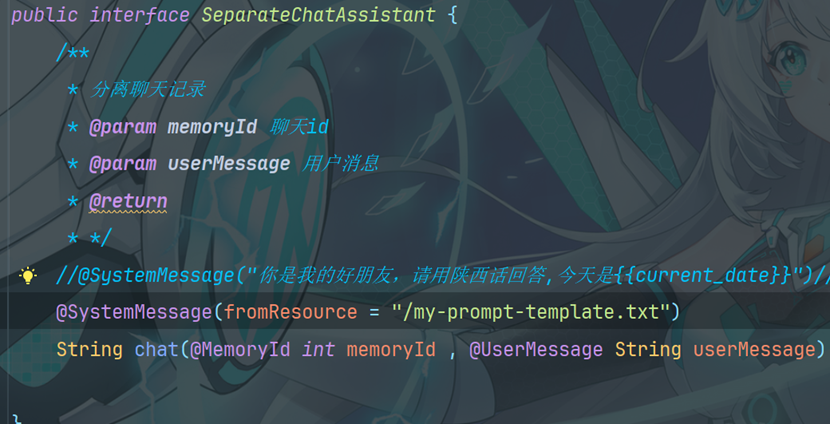 my-prompt-template.txt
my-prompt-template.txt

7.1.4用户提示词模板
@UserMessage:获取用户输入
在M emoryChatAssistant 的 chat 方法中添加注解

7.1.5编写测试方法
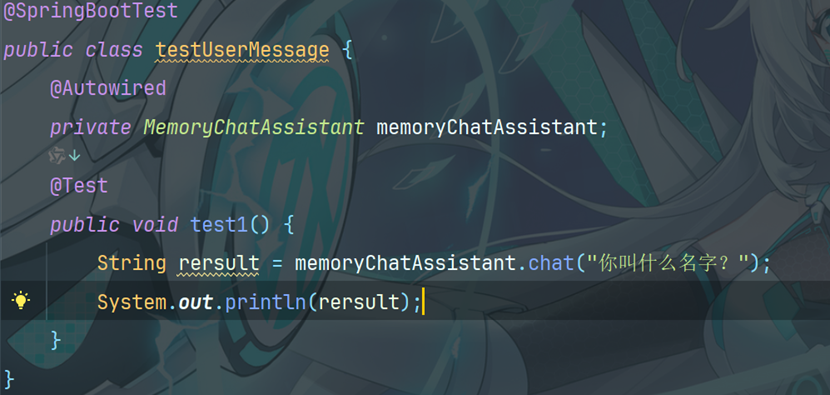
输出

7.2指定参数名称
@V 明确指定传递的参数名称

7.3多个参数情况
如果有两个或两个以上的参数,必须要用@V,在 SeparateChatAssistant 中定义方法

7.3.1 编写测试方法
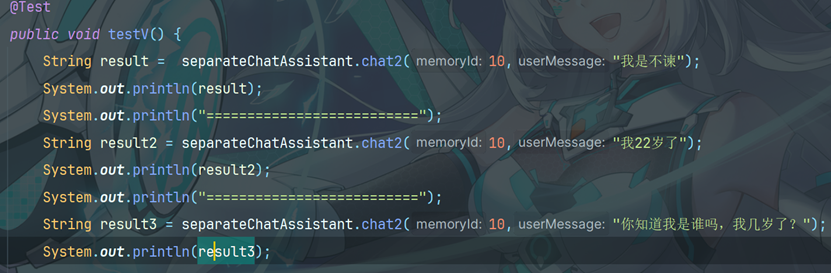
输出

7.4 @SystemMessage和@V
也可以将 @SystemMessage 和 @V 结合使用 在S eparateChatAssistant 中添加方法
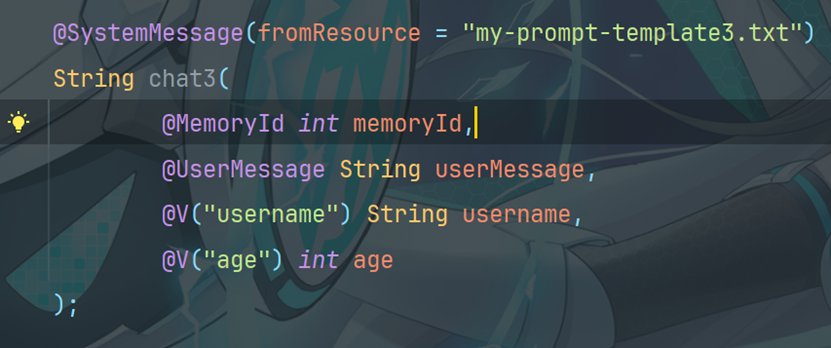
7.4.1 编写测试方法

输出

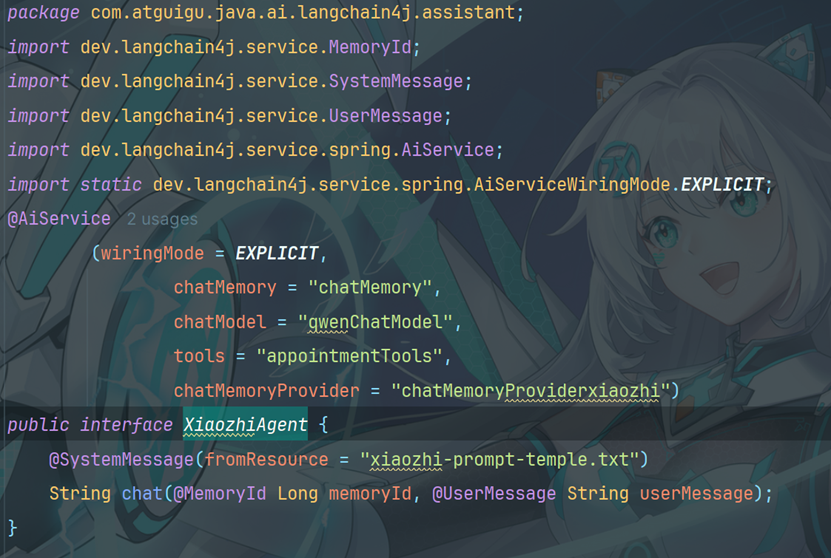
8.创建清影小智
8.1创建小智接口
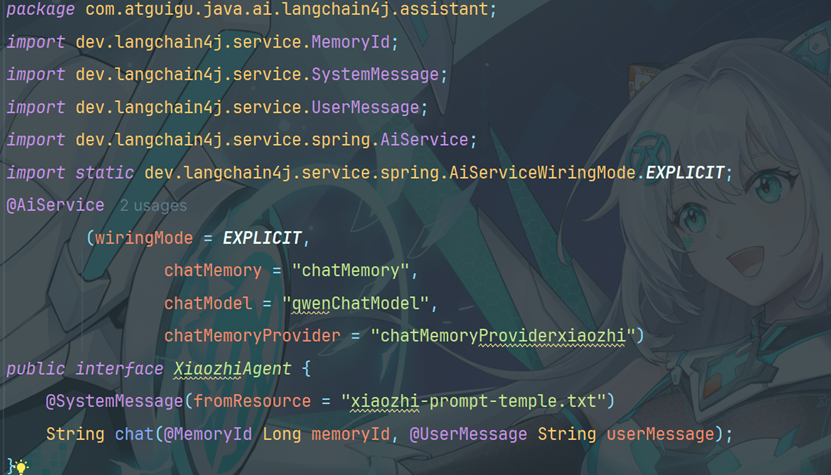
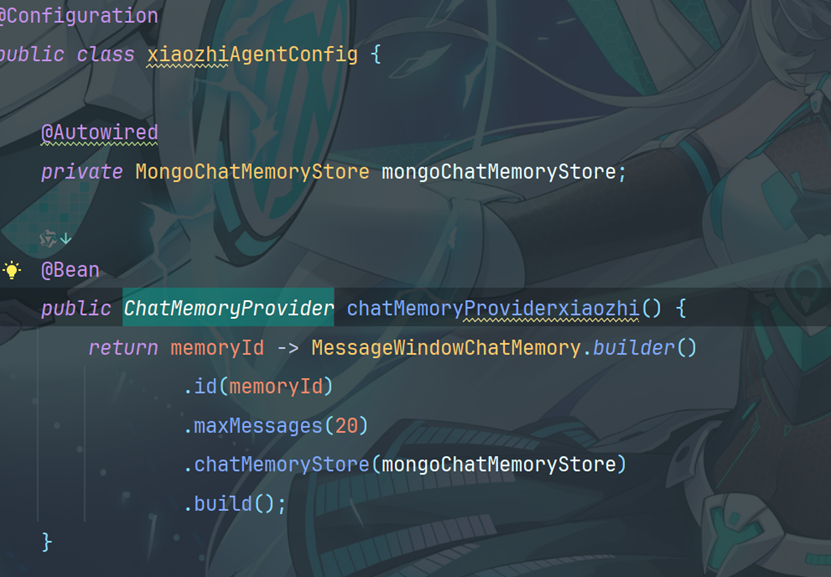
8.2创建小智配置类
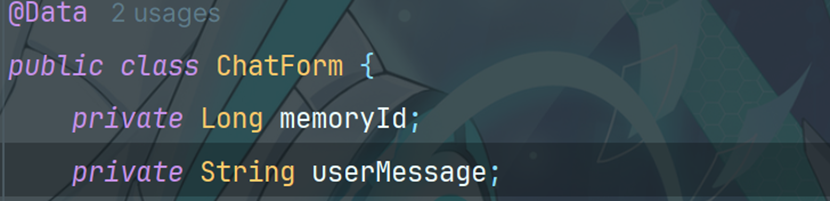
8.3创建小智实体类
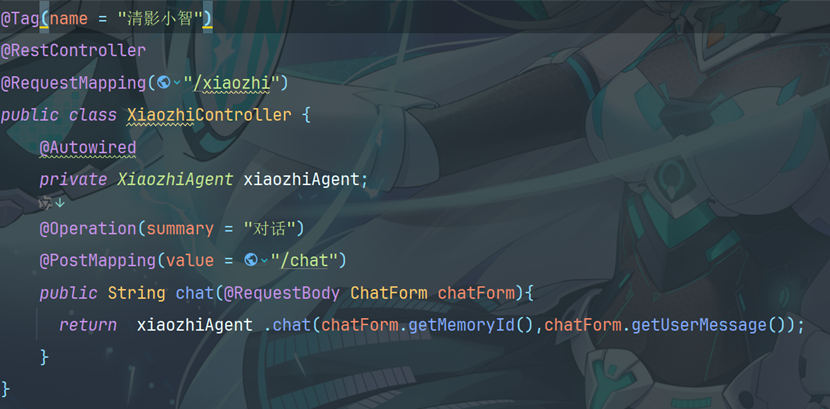
8.4创建小智控制器类
8.5创建xiaozhi-prompt-temple.txt

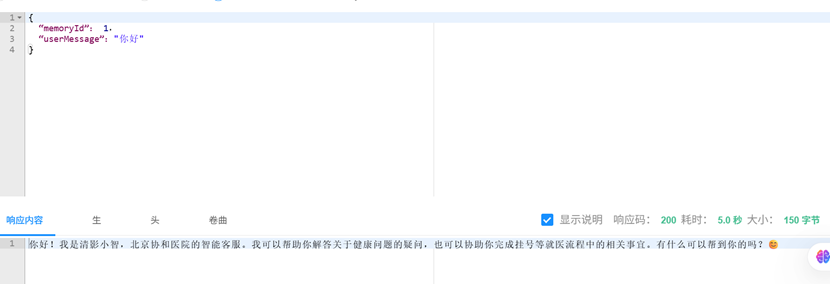
8.6 通过swagger和启动类测试
9. Function Calling 函数调用
Function Calling 函数调用 也叫 Tools 。工具大语言模型本身并不擅长数学运算。如果应用场景中偶尔会涉及到数学计算,我们可以为它提供 一个 “数学工具”。当我们提出问题时,大语言模型会判断是否使用某个工具。
9.1创建工具类
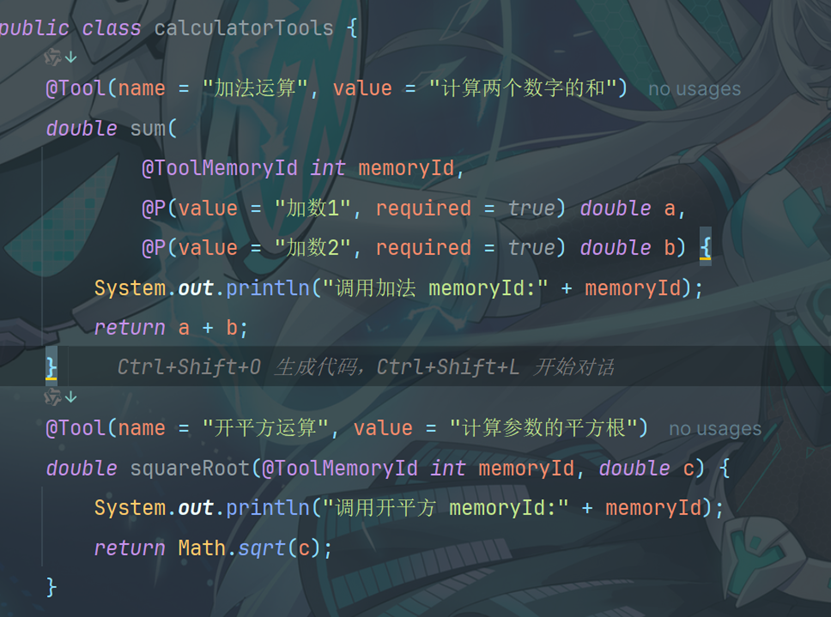
1.@Tool 注解有两个可选字段: name(工具名称):工具的名称。如果未提供该字段,方法名会作为工具的名称。 value(工具描述):工具的描述信息。 根据工具的不同,即使没有任何描述,大语言模型可能也能很好地理解它
2、@P 注解 方法参数可以选择使用 @P 注解进行标注。 @P 注解有两个字段: value:参数的描述信息,这是必填字段。 required:表示该参数是否为必需项,默认值为true
3、@ToolMemoryId true ,此为可选字段。 如果你的AIService方法中有一个参数使用 @MemoryId 注解,那么你也可以使用 @Tool 方法中的一个参数。提供给AIService方法的值将自动传递给 @ToolMemoryId 注解 @Tool 方法。如果你有多个用户, 或每个用户有多个聊天记忆,并且希望在 @Tool 方法中对它们进行区分,那么这个功能会很有用。
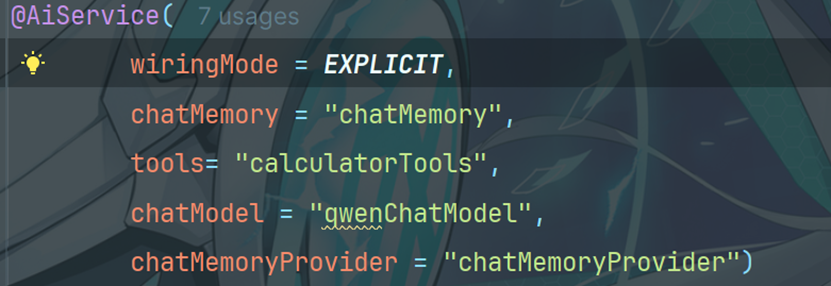
9.2配置工具类
9.3 编写测试类
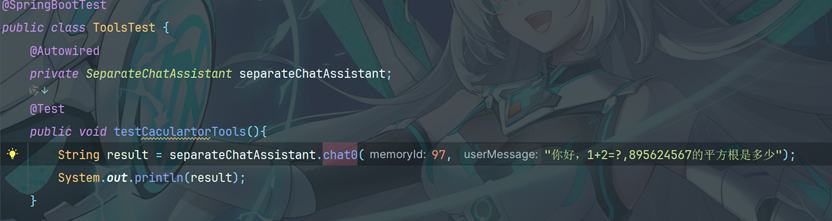
输出:

10.优化清影小智
实现清影小智的查询订单、预约订单、取消订单的功能
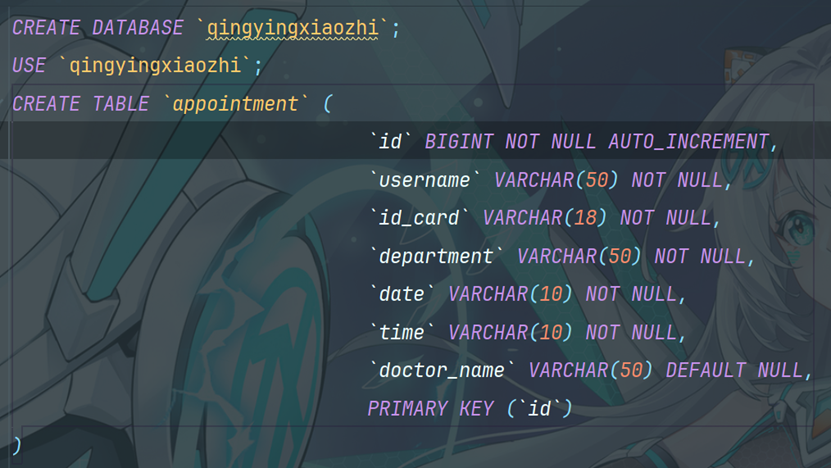
10.1 创建Mysql数据库表
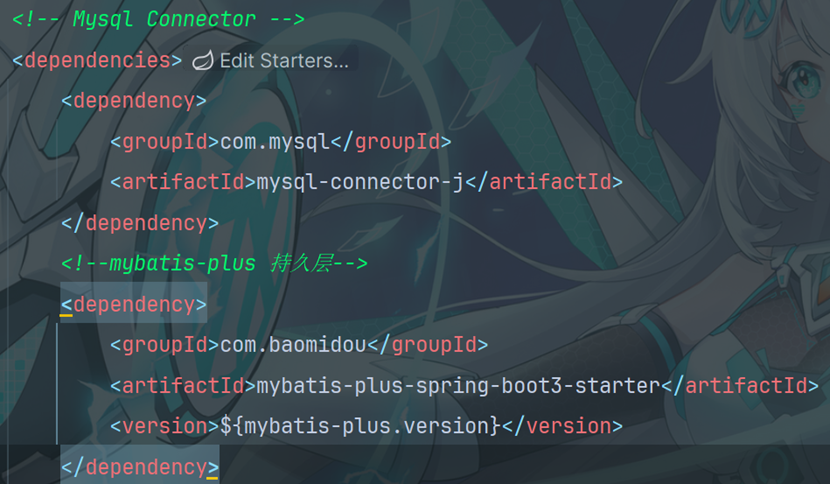
10.2 引入依赖
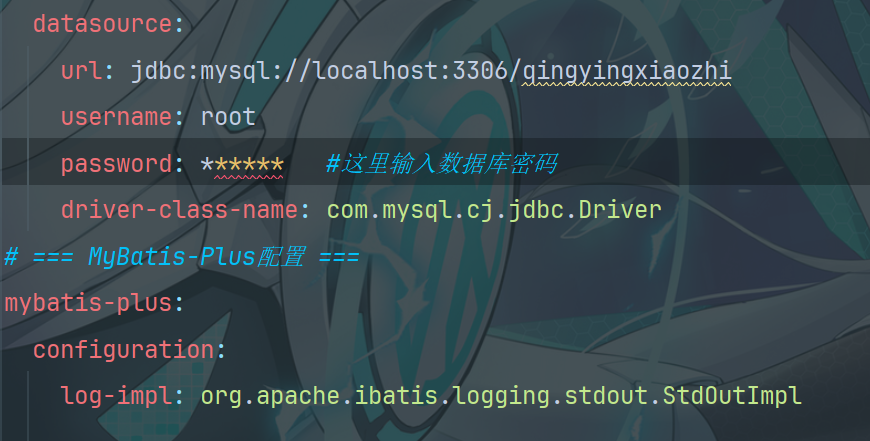
10.3 配置数据库连接
10.4创建实体类

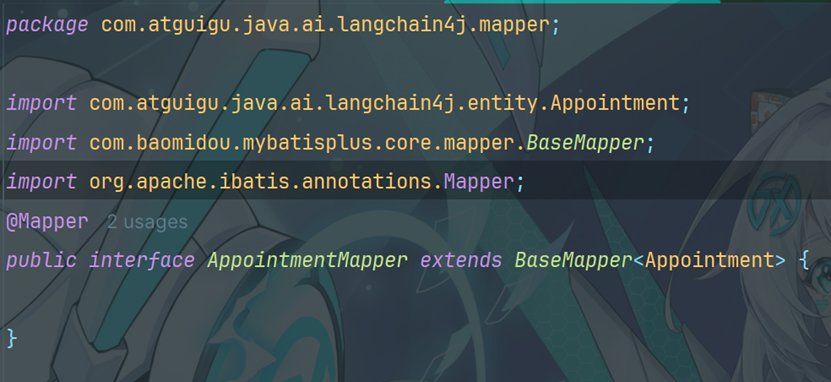
10.5Mapper
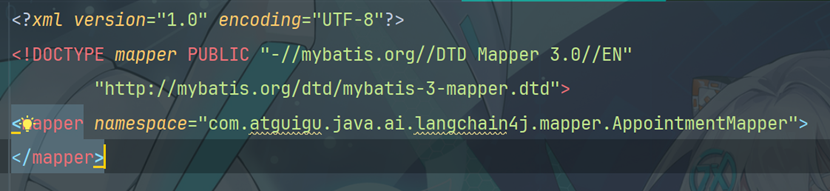
10.5.1 映射文件
10.6 创建服务层接口
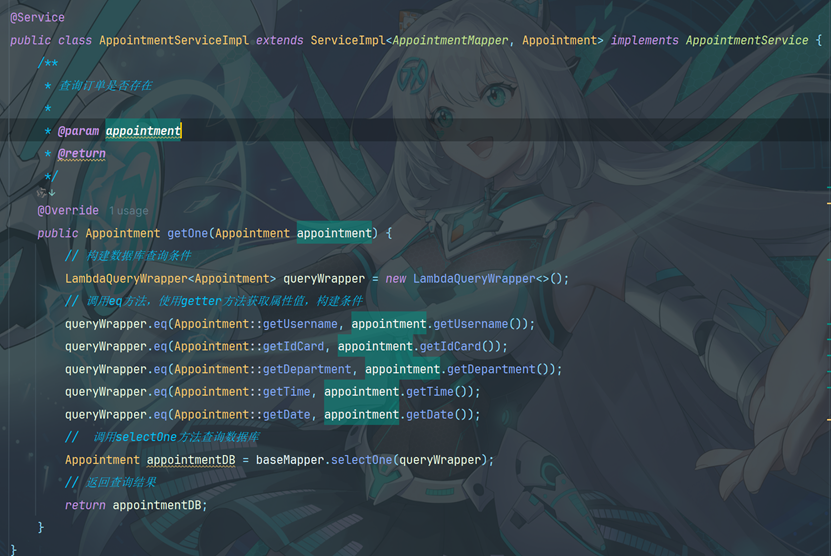
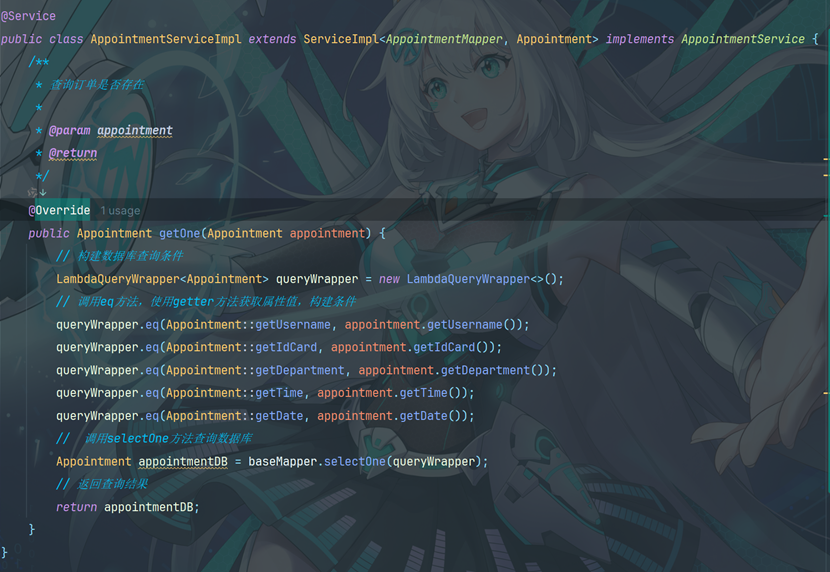
10.7 创建接口实现类
10.8创建测试方法
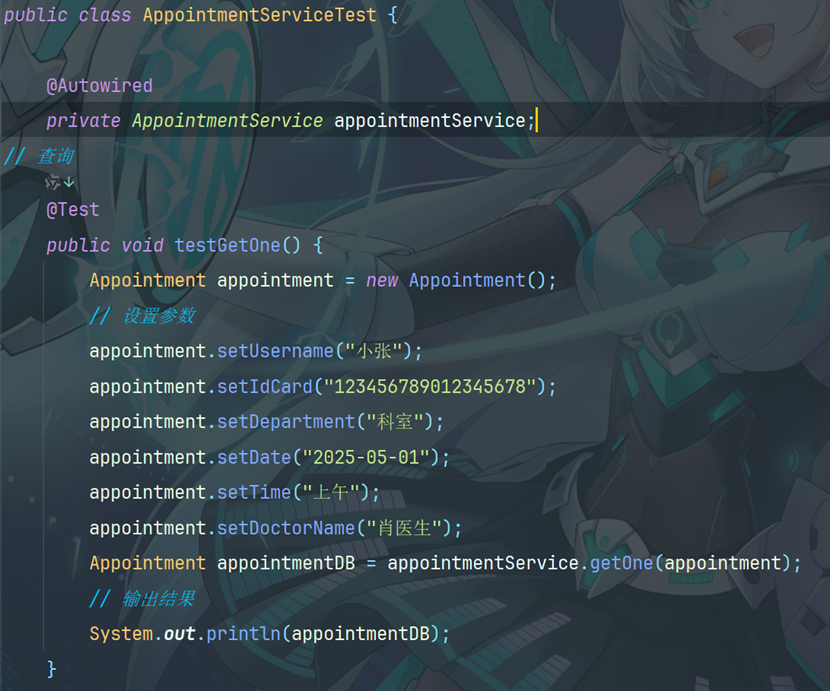
输出:

10.9 完善功能
10.9.1 创建Tools工具类
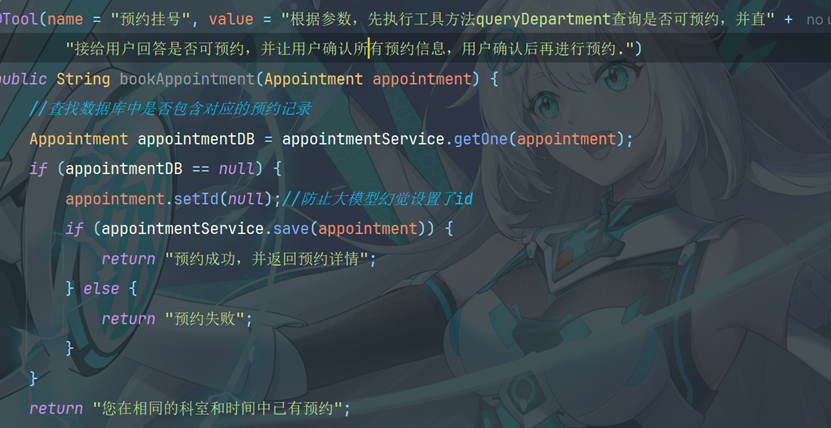
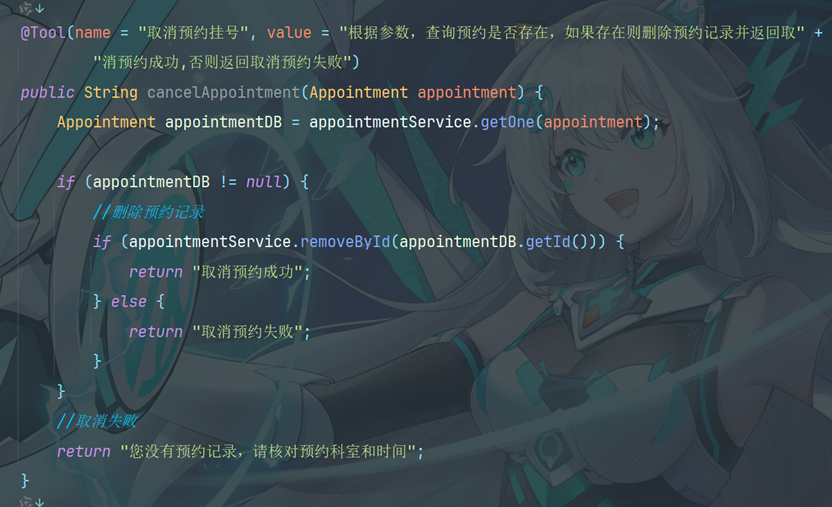

10.9.2 配置工具类
10.9.3 运行
运行结果:

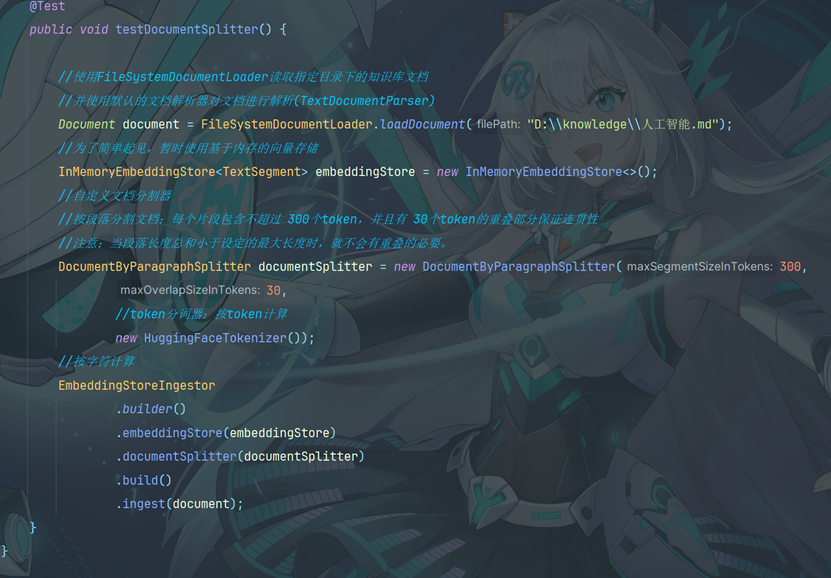
10.9.4文档分割器Document Splitter
LangChain4j 有一个 “文档分割器”(DocumentSplitter)接口,并且提供了几种开箱即用的实现方式:
按段落文档分割器(DocumentByParagraphSplitter)
按行文档分割器(DocumentByLineSplitter)
按句子文档分割器(DocumentBySentenceSplitter)
按单词文档分割器(DocumentByWordSplitter)
按字符文档分割器(DocumentByCharacterSplitter)
按正则表达式文档分割器(DocumentByRegexSplitter)
递归分割:DocumentSplitters.recursive (...) 默认情况下每个文本片段最多不能超过300个token
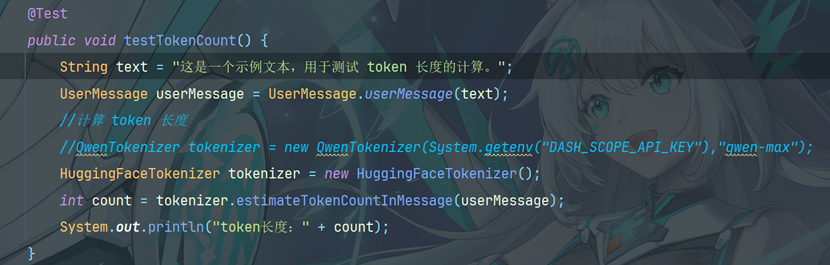
10.9.5 试向量转换和向量存储
Embedding (Vector) Stores 常见的意思是 “嵌入(向量)存储” 。在机器学习和自然语言处理领域, Embedding 指的是将数据(如文本、图像等)转换为低维稠密向量表示的过程,这些向量能够保留数据 的关键特征。而 Stores 表示存储,即用于存储这些嵌入向量的系统或工具。它们可以高效地存储和检索 向量数据,支持向量相似性搜索,在文本检索、推荐系统、图像识别等任务中发挥着重要作用。
Langchain4j支持的向量存储
Comparison table of all supported Embedding Stores | LangChain4j
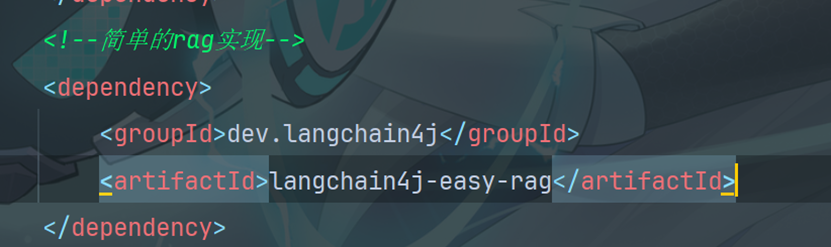
添加依赖:
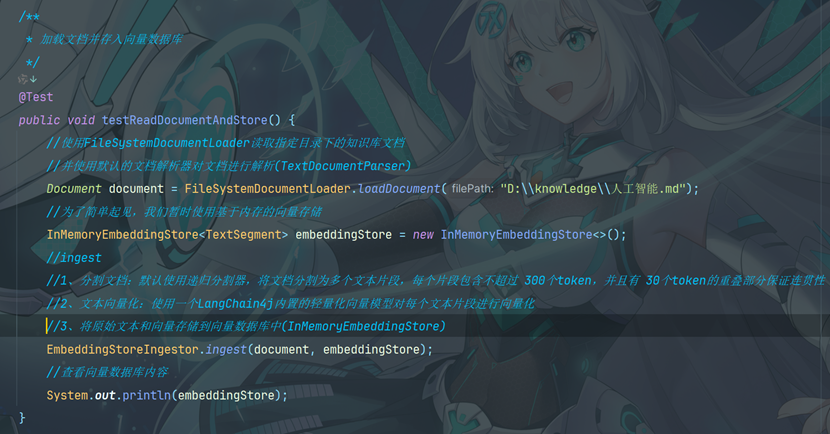
测试:
10.9.6工作方式
实例化一个 “文档分割器”(DocumentSplitter),指定所需的 “文本片段”(TextSegment)大小,并 且可以选择指定characters 或token的重叠部分。 2. “文档分割器”(DocumentSplitter)将给定的文档(Document)分割成更小的单元,这些单元的性 质因分割器而异。例如,“按段落分割文档器”(DocumentByParagraphSplitter)将文档分割成段落 (由两个或更多连续的换行符定义),而 “按句子分割文档器”(DocumentBySentenceSplitter)使 用 OpenNLP 库的句子检测器将文档分割成句子,依此类推。 3. 然后,“文档分割器”(DocumentSplitter)将这些较小的单元(段落、句子、单词等)组合成 “文本 片段”(TextSegment),尝试在单个 “文本片段”(TextSegment)中包含尽可能多的单元,同时不 超过第一步中设置的限制。如果某些单元仍然太大,无法放入一个 “文本片段”(TextSegment) 中,它会调用一个子分割器。这是另一个 “文档分割器”(DocumentSplitter),能够将不适合的单 元分割成更细粒度的单元。会向每个文本片段添加一个唯一的元数据条目 “index”。第一个 “文本片 段”(TextSegment)将包含 index=0 ,第二个是 index=1 ,依此类推
模型上下文窗口可以通过模型参数列表查看:阿里云百炼
期望的文本片段最大大小
1. 模型上下文窗口:如果你使用的大语言模型(LLM)有特定的上下文窗口限制,这个值不能超过模 型能够处理的最大 token 数。例如,某些模型可能最大只能处理 2048 个 token,那么设置的文本片 段大小就需要远小于这个值,为后续的处理(如添加指令、其他输入等)留出空间。通常,在这种 情况下,你可以设置为 1000 - 1500 左右,具体根据实际情况调整。
2. 数据特点:如果你的文档内容较为复杂,每个段落包含的信息较多,那么可以适当提高这个值, 比如设置为 500 - 800 个 token,以便在一个文本片段中包含相对完整的信息块。相反,如果文档段 落较短且信息相对独立,设置为 200 - 400 个 token 可能就足够了。
3. 检索需求:如果希望在检索时能够更精确地匹配到相关信息,较小的文本片段可能更合适,这样 可以提高信息的粒度。例如设置为 200 - 300 个 token。但如果更注重获取完整的上下文信息,较大 的文本片段(如 500 - 600 个 token)可能更有助于理解相关内容。
重叠部分大小
- 上下文连贯性:重叠部分的主要作用是提供上下文连贯性,避免因分割导致信息缺失。如果文档 内容之间的逻辑联系紧密,建议设置较大的重叠部分,如 50 - 100 个 token,以确保相邻文本片段 之间的过渡自然,模型在处理时能够更好地理解上下文。 2. 数据冗余:然而,设置过大的重叠部分会增加数据的冗余度,可能导致处理时间增加和资源浪 费。因此,需要在上下文连贯性和数据冗余之间进行平衡。一般来说,20 - 50 个 token 的重叠是比 较常见的取值范围。 3. 模型处理能力:如果使用的模型对输入的敏感性较高,较小的重叠部分(如 20 - 30 个 token)可能 就足够了,因为过多的重叠可能会引入不必要的干扰信息。但如果模型对上下文依赖较大,适当增 加重叠部分(如 40 - 60 个 token)可能会提高模型的性能。 尚硅⾕ 例如,在处理一般性的文本资料,且使用的模型上下文窗口较大(如 4096 个 token)时,设置文本片段 最大大小为 600 - 800 个 token,重叠部分为 30 - 50 个 token 可能是一个不错的选择。但最终的设置还需 要通过实验和实际效果评估来确定,以找到最适合具体应用场景的参数值。
11. 在清影小智中实现RAG
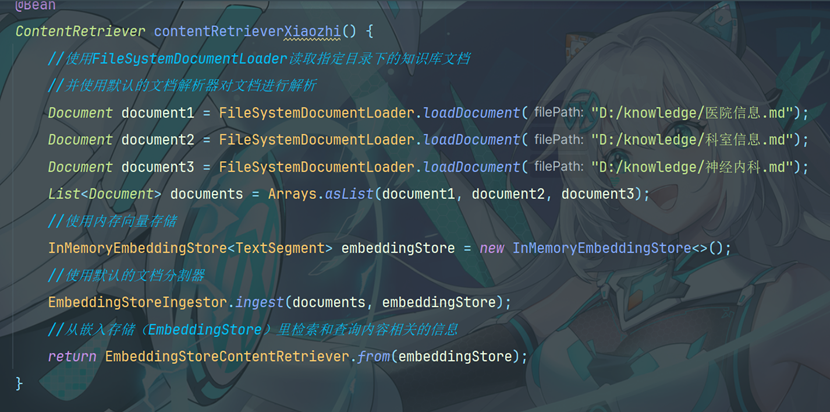
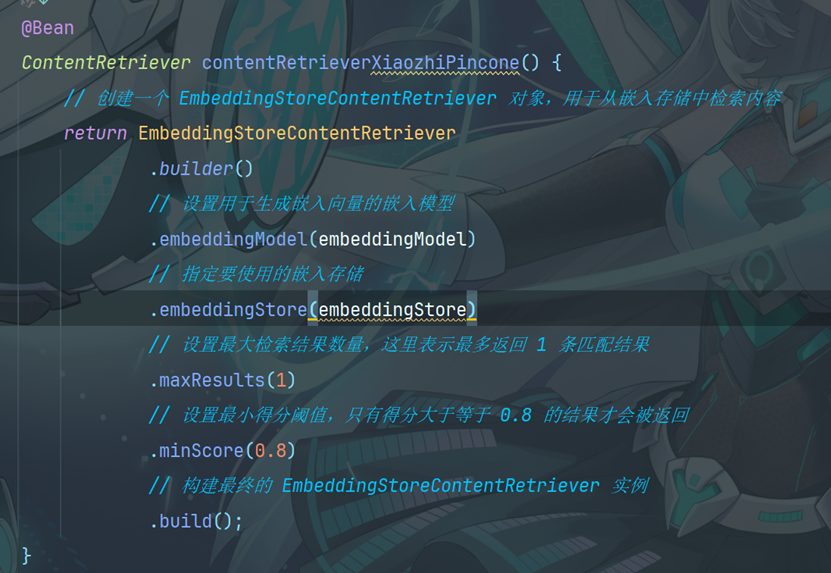
11.1 创建Bean对象
在xiaozhiAgentConfig中添加ContentRetriever
11.2 添加配置
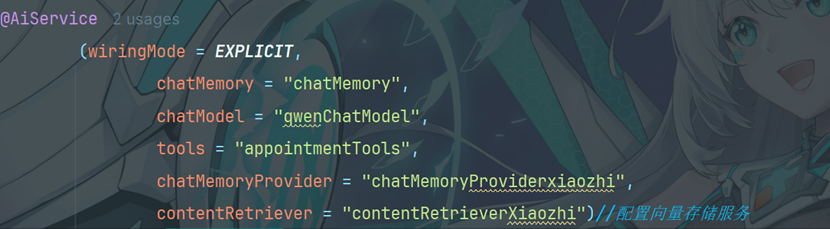
11.3 优化工具类的value提示

11.4 通过controller测试
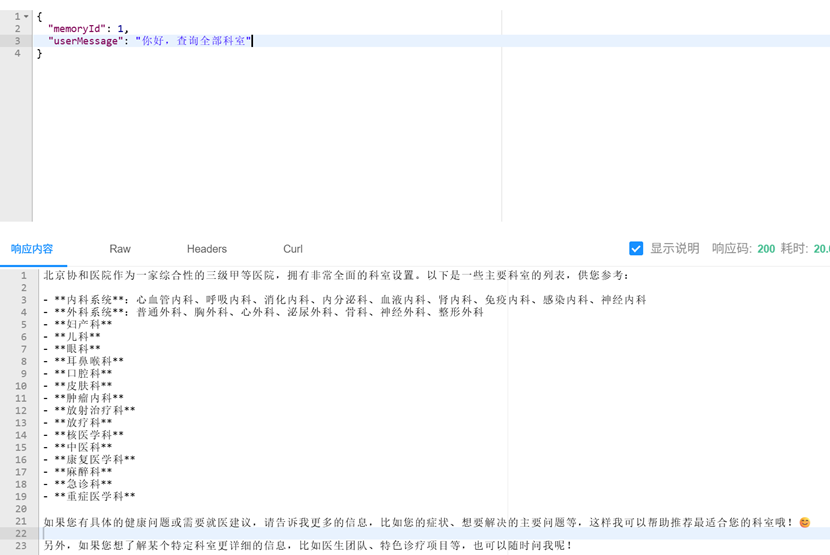
12. 向量模型和向量存储
12.1向量大模型
介绍 通用文本向量模型:
通用文本向量同步接口API详情_大模型服务平台百炼(Model Studio)-阿里云帮助中心
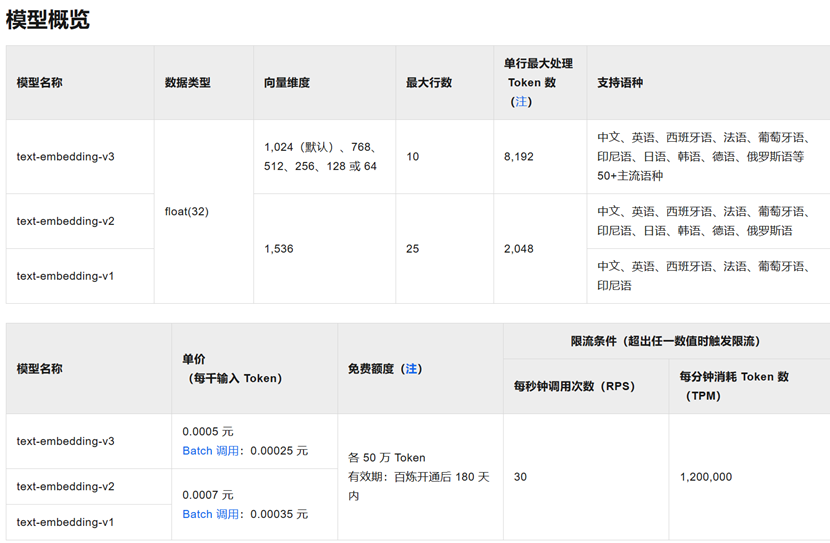
使用通用文本向量 text-embedding-v3,维度1024,维度越多,对事务的描述越精准,信息检索的精度越高
12.2配置向量模型
langchain4j.community.dashscope.embedding-model.api-key=${ALI_API_KEY} langchain4j.community.dashscope.embedding-model.model-name=text-embedding-v3
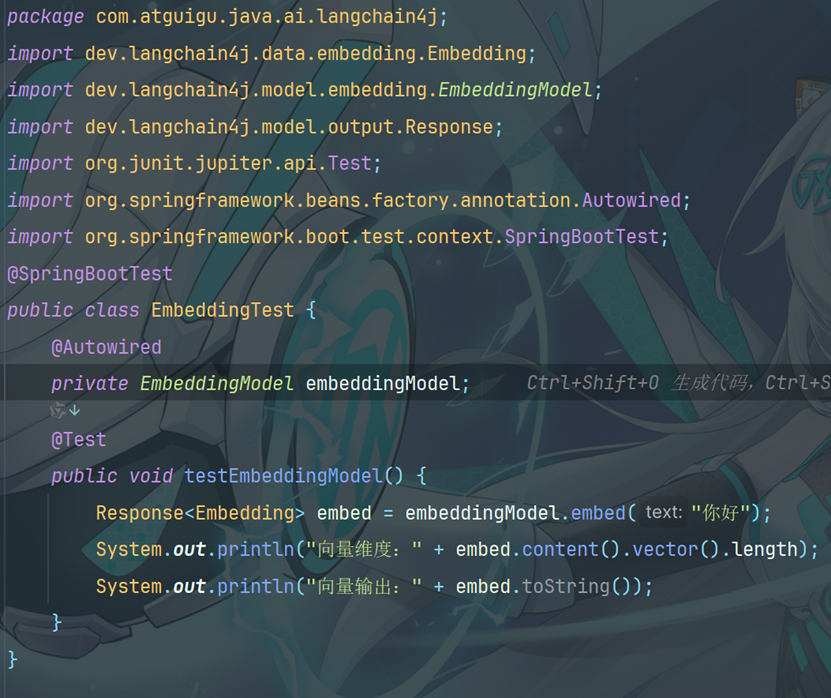
12.3文本向量化
12.4向量存储
12.4.1Pinecone简介
之前使用的是InMemoryEmbeddingStore作为向量存储,但是不建议在生产中使用基于内存的向量存 储。因此这里我们使用Pinecone作为向量数据库。
官方网站:The vector database to build knowledgeable AI | Pinecone
访问官方网站、注册、登录、获取apiKey且配置在环境变量中。
默认有2GB的免费存储空间
12.4.2 Pinecone的使用
得分的含义
在向量检索场景中,当我们把查询文本转换为向量后,会在嵌入存储( EmbeddingStore )里查找与之 最相似的向量(这些向量对应着文档片段等内容)。为了衡量查询向量和存储向量之间的相似程度,会 使用某种相似度计算方法(例如余弦相似度等)来得出一个数值,这个数值就是得分。得分越高,表明 查询向量和存储向量越相似,对应的文档片段与查询文本的相关性也就越高。 得分的作用 筛选结果:通过设置 minScore 阈值,能够过滤掉那些与查询文本相关性较低的结果。
在代码 里,minScore(0.8) 意味着只有得分大于等于 0.8 的结果才会被返回,低于这个阈值的结果会被 舍弃。这样可以确保返回的结果是与查询文本高度相关的,提升检索结果的质量。 控制召回率和准确率:调整 minScore 的值可以在召回率和准确率之间进行权衡。如果把阈值设 置得较低,那么更多的结果会被返回,召回率会提高,但可能会包含一些相关性不太强的结果,导 致准确率下降;反之,如果把阈值设置得较高,返回的结果数量会减少,准确率会提高,但可能会 遗漏一些相关的结果,使得召回率降低。在实际应用中,需要根据具体的业务需求来合理设置 minScore 的值
示例说明
假设我们有一个关于水果的文档集合,嵌入存储中存储了这些文档片段的向量。当我们使用 “苹果的营养 价值” 作为查询文本时,向量检索会计算查询向量与存储向量的相似度得分。如果 minScore 设置为 0.8,那么只有那些与 “苹果的营养价值” 相关性非常高的文档片段才会被返回,而一些只简单提及苹果但 没有详细讨论其营养价值的文档片段可能由于得分低于 0.8 而不会被返回
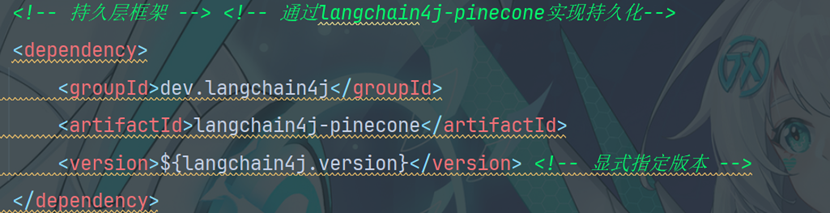
12.5集成Pinecon
引入相关依赖
12.6 测试向量存储
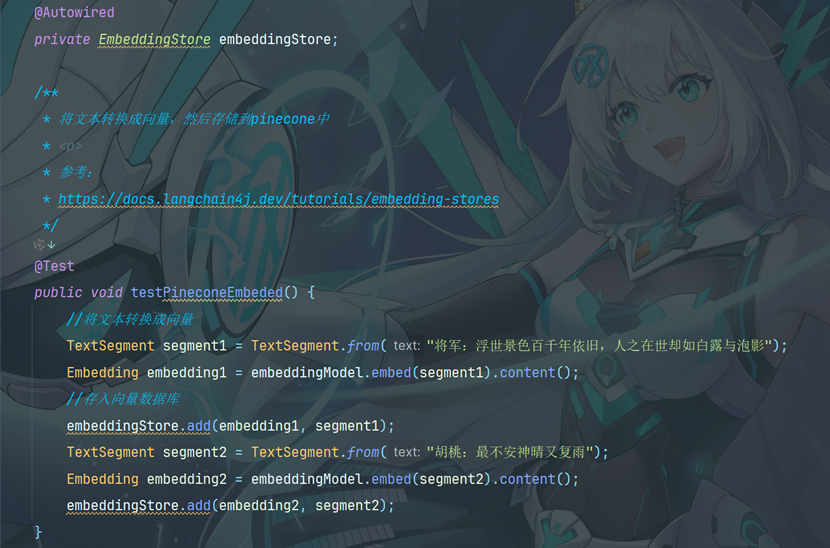
测试相似度匹配
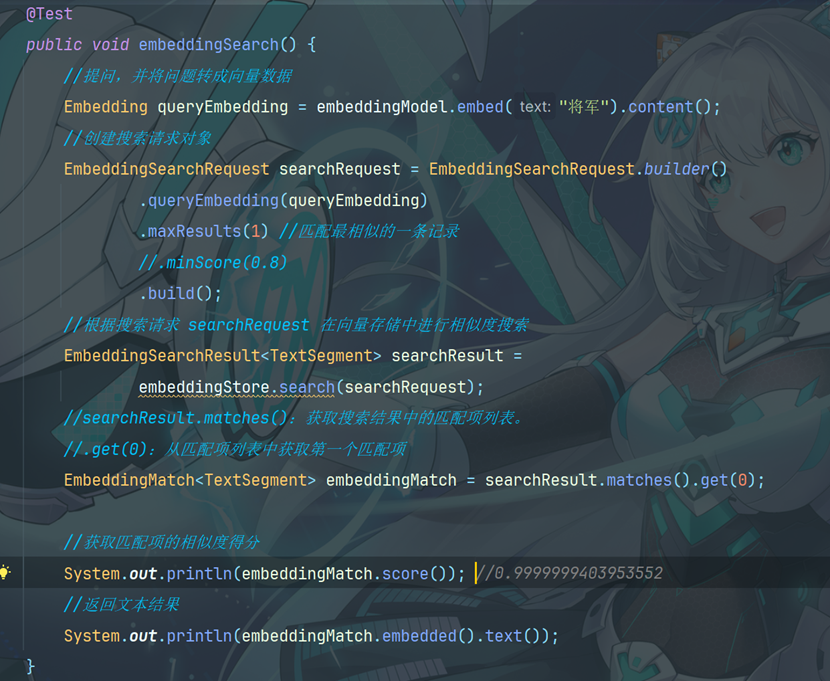
输出:

13.在清影小智中整合向量数据库
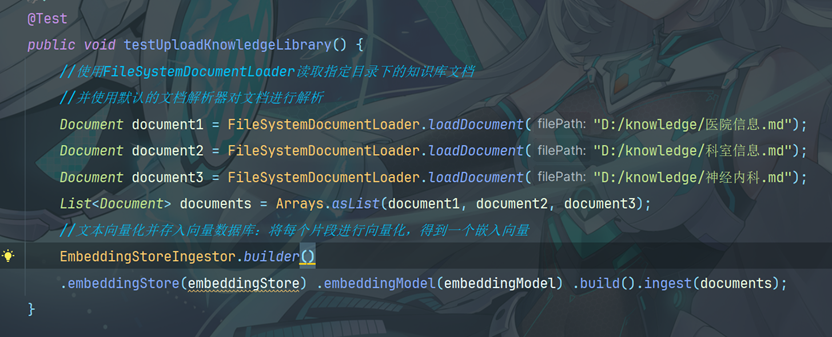
13.1上传知识库到Pinecone
13.2添加XiaozhiAgentConfig
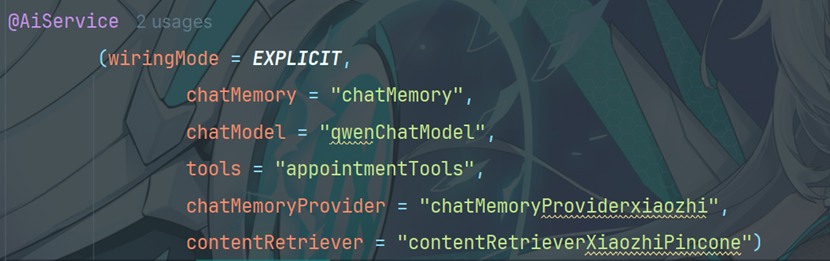
13.3 修改xiaozhiAgent
修改contentRetriever的配置为contentRetrieverXiaozhiPincone
14.改造流式输出
大模型的流式输出是指大模型在生成文本或其他类型的数据时,不是等到整个生成过程完成后再一次性 返回所有内容,而是生成一部分就立即发送一部分给用户或下游系统,以逐步、逐块的方式返回结果。 这样,用户就不需要等待整个文本生成完成再看到结果。通过这种方式可以改善用户体验,因为用户不 需要等待太长时间,几乎可以立即开始阅读响应。
14.1 添加依赖
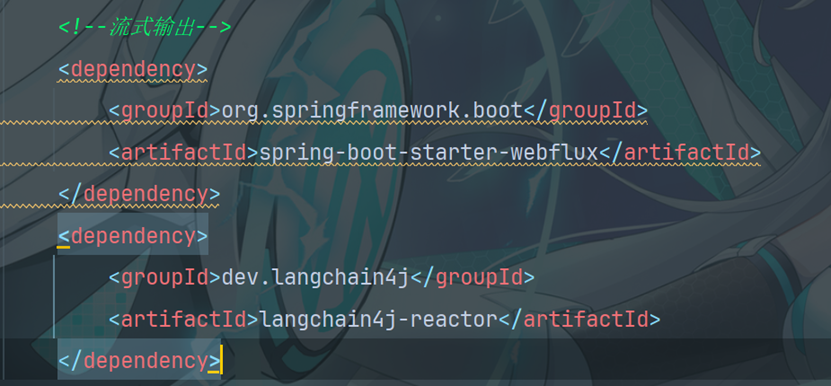
14.2配置大模型

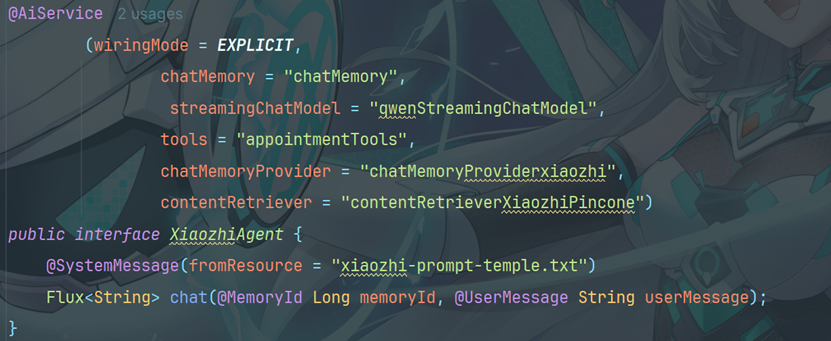
14.3 修改优化
修改 XiaozhiAgent 中 chatModel 改为 streamingChatModel = "qwenStreamingChatModel" `chat 方法的返回值为 Flux<String>
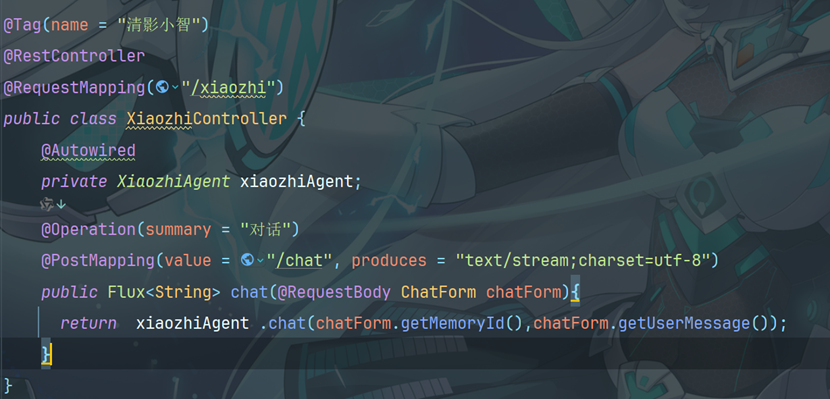
14.4修改Controller
将XiaozhiController 中 chat 方法的返回值修改为 Flux ,并添加 produces 属性
至此,清影小智开发完毕,可以通过运行主程序后,利用swagger在浏览器上输入
http://localhost:8080/doc.html进行完整功能测试

















 4229
4229

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









