






一、什么是Kylin?
Apache Kylin™是一个开源的、分布式的分析型数据仓库,提供Hadoop/Spark 之上的 SQL 查询接口及多维分析(OLAP)能力以支持超大规模数据,最初由 eBay 开发并贡献至开源社区。
通过Kylin,可以实现超大数据集的亚秒级查询。
另外一定要提的一点,Kylin是首个由中国人引导并完成开发的Apache顶级开源项目!
二、前提概要
在详细了解Kylin前,需要先了解以下几点知识。
OLAP(OnLine Analytical Processing)
OLAP名为联机分析处理,是用户可以快速,一致,交互地从各个方面更透彻的了解数据及信息。
维度:观察事物或分析数据时的角度,比如'时间'、'地点'、'产品类型'等,均为单一的角度。
维度层次:表示在同一维度概念上再次细分,例如'年-月-日','国家-市-区',均分为了三个层次。
维成员:表示当前层次,不再次细分时的具体某一成员,例如'2020年7月27日','中国-北京市-朝阳区'。
度量:在某一维度上所取到维成员的值。
OLAP按照存储器的数据存储格式又分为ROLAP、MOLAP和HOLAP。
ROLAP:基于关系型模型存放数据,事实表与维度表间有外键关联。在查询时使用SQL即可完成不同维度下的查询,不需要预计算。
MOLAP:基于多维数组存放数据,它是OLAP的最初形态。在查询之前需要对数据进行预处理,并将结果以cube的存放在数组中。
HOLAP:目前为止,业界还未对HOLAP进行统一定义。HOLAP它是ROLAP和MOLAP的混合结果,高度聚合的数据使用MOLAP存放,而颗粒度更细的数据则使用ROLAP的形式存放。
Kylin使用的就是MOLAP。
星型模型 & 雪花模型
星型模型 & 雪花模型 星型模型(Star Schema)是数据仓库维度建模中常用的数据模型之一。它的特点是 一张事实表,以及一到多个维度表,事实表与维度表通过主外键相关联,维度表之间 没有关联,就像许多小星星围绕在一颗恒星周围,所以名为星型模型。 另一种常用的模型是雪花模型(SnowFlake Schema),就是将星型模型中的某些维 表抽取成更细粒度的维表,然后让维表之间也进行关联,这种形状酷似雪花的的模型 称为雪花模型。
三、Kylin主要理念
Kylin的核心就是空间换时间。
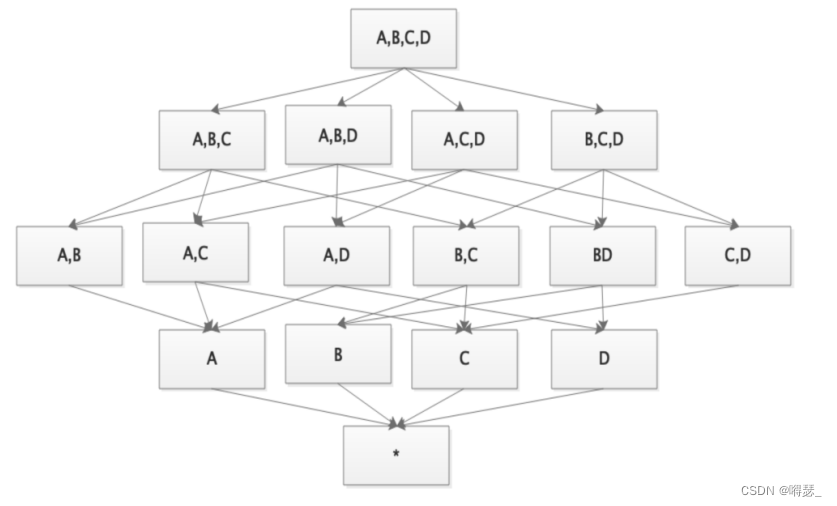
下图中,一共有4个维度。除去0维,一共有15种情况。Kylin在预计算这15种情况时,第一种'A,B,C,D'这种情况由原始数据聚合而成,之后每层先通过MR计算'A,B,C,D'-'A,B,C','A,B,D','A,C,D','B,C,D'这种情况的结果,并根据维度逐级递减。每层递减时,每层的计算均为上一层MR任务结果的基础上再次进行计算。
四、Kylin架构
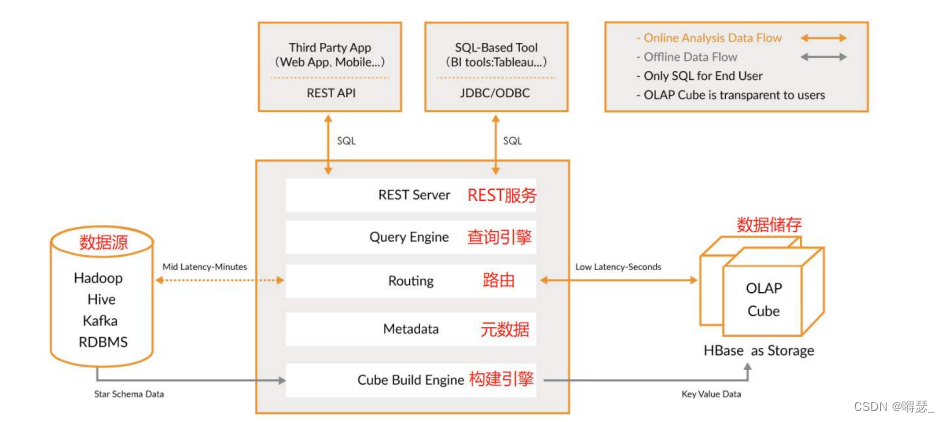
上图是Apache官方给出的Kylin架构图。
REST Server层:用户程序访问Kylin的入口。实现用户通过程序对Kylin进行访问,可实现Cube的创建、查询、获取元数据及权限配置等操作。
Query Engine层:用户在预计算生成Cube后,查询层可以快速响应用户的查询动作,并将结果返回给用户。
Routing层:路由层设计之初是为了在查询未预计算Cube的数据时可以转而直接查询Hive,但由于Cube查询仅几秒的时间就可以返回数据,而查询Hive表通常需要十几秒秒甚至几分钟到几十分钟,导致用户体验会变的极差。因此在后来Kylin默认配置关闭了此项功能。
Metadata层:Metadata层主要是Kylin的一些元数据,比如最重要的Cube信息等等。
Cube Build Engine层:Cube构建层主要负责数据的预计算并生成Cube,包括MR任务及其他java api等。
Kylin是依靠于Hadoop生态系统之上应用程序。它的数据来源为Hive表或Kafka流式数据以及其他关系型数据库中的数据。通过构建引擎,将预计算生成的Cube数据存到Hbase中,以供快速的查询响应。















 3838
3838











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









