






Hadoop介绍
Hadoop是一个开源的分布式计算框架,用于处理大规模数据集的存储和处理。它基于Google的MapReduce和Google文件系统(GFS)的思想,并使用Java语言编写。Hadoop的主要特点是高可靠性、可扩展性和高效性。
安装步骤
JDK安装
1.解压jdk压缩包(所有虚拟机都需安装)
tar -zxvf /root/jdk-8u131-linux-x64..gz -C /export/servers//export/servers/为解压后的目录
重命名jdk
mv jdk1.8.0_161 jdk2.配置环境变量
vi /etc/profileexport JAVA_HOME=/export/servers/jdk
export PATH=$PATH:$JAVA_HOME/bin
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
其中JAVA_HOME为jdk解压后的路径(写自己的路径)
#使配置生效
source /etc/profile
#查看是否生效
java -versionHadoop安装
解压安装包,并配置环境变量(与JDK安装配置大致一样)
#解压hadoop
tar -zxvf /root/hadoop-2.10.1.tar.gz -C /export/servers/
#配置hadoop环境变量
vi /etc/profile
export HADOOP_HOME=/export/servers/hadoop-2.10.1
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
#
使配置文件生效
source /etc/profile
#
查看是否配置成功
hadoop version
免密登录
1.配置hosts文件
在文件添加三台虚拟机的IP和主机名
vi /etc/hosts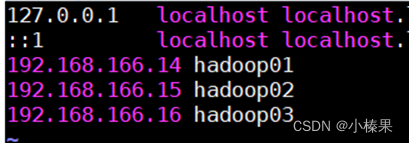
2.ssh免密登录-生成密钥(四次回车)
ssh-keygen -t rsa将本机的公钥文件复制到其他虚拟机上(需要在全部开机的情况下)
在hadoop01(主机名)上执行,先输入yes,后输入对应主机的密码,多台虚拟机配置操作相同。
ssh-copy-id hadoop01
ssh-copy-id hadoop02
ssh-copy-id hadoop03
在虚拟机hadoop02,hadoop03都需要执行,保证三台主机都能够免密登录。

用ssh命令查看是否免密登录成功。
Hadoop配置
进入主节点配置目录
cd /export/servers/hadoop-2.7.4/etc/hadoop/需要注意的是hadoop安装下的etc文件而不是根目录下的etc文件
1.修改hadoop-env.sh文件
vi hadoop-env.sh
export JAVA_HOME=/export/servers/jdk
路径改成自己的jdk安装路径
2.修改core-site.xml文件
vi core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop01:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/export/servers/hadoop-2.10.1/tmp</value>
</property>
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
</configuration>用于指定namenode地址在机器master上,数据存储目录。
3.修改hdfs-site.xml文件
vi hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop03:50090</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/export/servers/hadoop-2.10.1/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/export/servers/hadoop-2.10.1/tmp/dfs/data</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>指定HDFS副本的数量(一般为3),不能超过机器节点数,设置secondary namenode配置所在的IP和端口(这里设置的是第三台机器)
4.修改mapred-site.xml文件
修改临时文件
cp mapred-site.xml.template mapred-site.xml将临时文件变为有效文件,在对其进行修改配置
vi mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>指定MapReduce运行时框架,这里指定在yarn上
5.修改yarn-site.xml文件
vi yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop01</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>指定yarn集群的管理者(resourcemanger)的地址
6.修改slaves文件
vi slaves
hadoop01
hadoop02
hadoop037.发送文件
将主节点中配置好的文件和hadoop目录copy给子节点
scp /etc/profile hadoop02:/etc/profile
scp /etc/profile hadoop03:/etc/profile
#包括jdk,hadoop环境变量配置文件
scp -r /export/ hadoop02:/
scp -r /export/ hadoop03:/
#并在其他两台虚拟机生效环境配置
source /etc/profileHadoop格式化
在主节点格式化文件系统(successfully formatted 格式化成功)
hdfs namenode -format

在主节点启动所有HDFS进程
start-dfs.sh
start-yarn.sh
或者整体启动
start-all.sh用jps命令查看进程
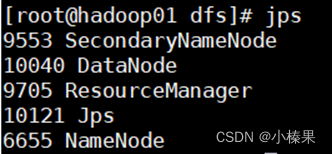
查看datanode,namenode是否正常存在。















 2060
2060

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









