






必应搜索:
使用库:requests;bs4
目标:
- 分析必应的url
- 获取信息,解析为BeautifulSoup对象
- 提取信息,输出信息
- 源代码放在最后
1.分析URL:
https://cn.bing.com/search?#搜索URL
q=000#搜索内容
form=ANNTH1#国内版ANNTH1、国际版BESBTB
......#其余参数为特殊的验证码,不影响结果
建立 类 bi:
import requests
from bs4 import BeautifulSoup
class bi:
def make_url(self,q):
return 'https://cn.bing.com/search?q=' + q
2.获取信息:
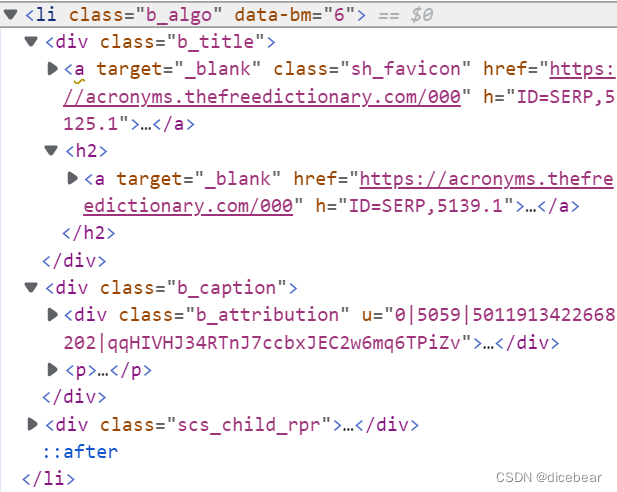
右键检查,我们发现所有信息都位于第一个’ol’标签中。

class bi:
def find(self):
u = self.make_url(q)#构造URL
r = requests.get(u)#发送GET请求获取信息
soup = BeautifulSoup(r.text, 'html5lib')
#用BeautifulSoup,html5lib进行解析,html5lib需要下载(不需要导入)
#pip install html5lib
all_ = soup.find('ol')#第一个<ol>
a=all_.find_all('li')#<ol>下所有<li>存储到列表
return a
3.提取信息:
循环列表提取信息
li架构
介绍文本
标题文本
class bi:
def get(self,q):
a=self.find()
things = []
for tag in a:
try:
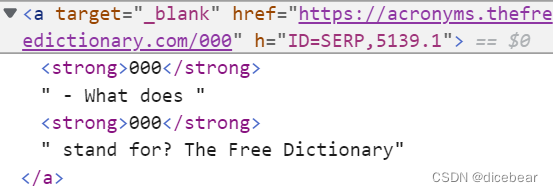
item1 = tag.find(class_='b_title')
url = item1.find('h2').find('a')['href']
#页面的网址
icon = item1.find('a').find('img')['src']
# 页面的图标
title = item1.text#只需要其中的文本内容
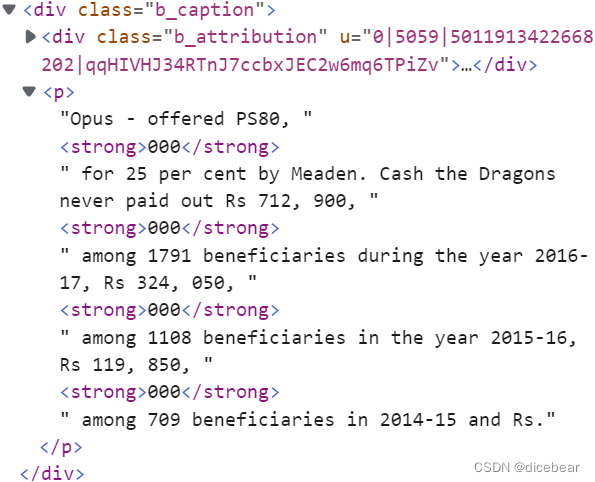
item2=tag.find(class_='b_caption')
text=item2.find('p').text
#介绍内容
thing = {'title': title, 'url': url, 'text':text, icon: 'icon'}
#把信息存入字典
things.append(thing)
#把字典加入列表
except:
pass
#有的信息架构特殊,使程序不报错
return things
4.old源代码:
import requests
from bs4 import BeautifulSoup
class bi:
def make_url(self,q):
return 'https://cn.bing.com/search?q=' + q
def find(self):
u = self.make_url(q)#构造URL
r = requests.get(u)#发送GET请求获取信息
soup = BeautifulSoup(r.text, 'html5lib')
#用BeautifulSoup,html5lib进行解析,html5lib需要下载(不需要导入)
#pip install html5lib
all_ = soup.find('ol')#第一个<ol>
a=all_.find_all('li')#<ol>下所有<li>存储到列表
return a
def get(self,q):
a=self.find()
things = []
for tag in a:
try:
item1 = tag.find(class_='b_title')
url = item1.find('h2').find('a')['href']
#页面的网址
icon = item1.find('a').find('img')['src']
# 页面的图标
title = item1.text#只需要其中的文本内容
item2=tag.find(class_='b_caption')
text=item2.find('p').text
#介绍内容
thing = {'title': title, 'url': url, 'text':text, icon: 'icon'}
#把信息存入字典
things.append(thing)
#把字典加入列表
except:
pass
#有的信息架构特殊,使程序不报错
return things
if __name__=='__main__':
n=bi()
a=input('Bing\n必应搜索:')
for i in n.get(a):
print(i['title'])
print(i['url'])
print(i['text'])
print('_'*100+'\n')
5.new源代码
import requests
from bs4 import BeautifulSoup
class bing:
def __init__(self):
'''
bing请求类
Dict:
header
Function:
__init__(self)
make_url(self,q,data='chinese',pagenum='1')
jx(self,url)
Returns
-------
None.
'''
self.header = {
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36 Edg/108.0.1462.76'
}
def make_url(self,q,data='chinese',pagenum='1'):
'''
生成必应url
Parameters
----------
q : str
关键字
data : str, optional
'chinese' or 'english'. The default is 'chinese'.
pagenum : str, optional
The default is '1'.
Returns
-------
url.
'''
if data != 'chinese' and data != 'english':
assert data != 'chinese' and data != 'english', '不支持中英文以外的文字'
if data == 'chinese':
urls = 'https://cn.bing.com/search?q='+q+'&form=ANSPH1'
elif data == 'english':
urls = 'https://cn.bing.com/search?q='+q+'&FORM=BESBTB&ensearch=1'
if pagenum == '1':
return urls
r = requests.get(urls,headers = self.header)
s = BeautifulSoup(r.text,'html5lib')
page = s.find('li',class_ = 'b_pag')
pages = page.find_all('li')
pageurls = {}
for i in pages:
try:
pageurls[i.text] = i.find('a')['href']
except:
pass
try:
return pageurls[pagenum]
except:
return urls
def jx(self,url):
'''
请求并解析url
Parameters
----------
url : str
usually from function make_url.
Returns
-------
None.
'''
r = requests.get(url,headers = self.header)
s = BeautifulSoup(r.text,'html5lib')
lis = s.find_all('li',class_ = 'b_algo')
rlist = []
# data = {'title':'','js':'','url':'','icon_url':''}
for i in lis:
data = {}
data['title'] = i.find('div',class_ = 'b_title').find('h2').text
data['url'] = i.find('div',class_ = 'b_title').find('h2').find('a')['href']
try:
data['js'] = i.find('p').text # .find('div',class_ = 'b_caption')
except:
data['js'] = 'no js'
try:
data['icon_url'] = i.find('div',class_ = 'b_title').find('a').find('div',class_ = 'rms_iac')['data-src']
except:
data['icon_url'] = 'no icon'
rlist.append(data)
return rlist
if __name__ == '__main__':
k = bing()
url = k.make_url('bs4')
rlist = k.jx(url)
for i in rlist:
for j in i:
print(i[j])
print('\n')















 937
937











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









