









前言
数据一致性的问题,是搭建任何微服务及分布式系统都必须提前考虑的问题。原本以为微服务系统及分布式系统已经应用如此普遍,从理论到实践的讲解应该是已经烂大街才对。但是历经一周,查阅了无数篇文献资料发现,网上文献无外乎二种,一类是照抄论文定义,强行解释。此类文献还好,至少有理可循。另一类二手文献,直接不分青红皂白加以解释,实际解释效果前后矛盾百出。在这其中,不乏有部分精品文件,但也都死较为片面的阐述了数据一致性的部分内容,尚没有将数据一致性结合不同架构统一起来做完整的介绍。
恰巧,我是属于有问题,必须深究到底,不搞清楚事务内在逻辑就睡不踏实的性格,因而查阅了近百篇文献,写下了此文,尝试以通俗易懂的方式,讲清楚分布式系统数据一致性的问题。此文前后历经十余次增补内容,每次都是自以为对前序内容有了深入了理解,但后期发现理解有误。不得不说,数据一致性问题不愧是IT界的一大坑。
废话不多说了,开整!
软件架构的演进和分类
软件架构的演进
开篇为什么一开始要先聊分布式架构的演进分类呢?因为讲到数据一致性问题,就跑不开分布式架构的讨论,后续的讨论也都将基于这部分内容展开,此部分一到要搞明白。在这里,我们不介绍晦涩难懂的定义,直接对实际业务中,可能遇到的几种软件架构展开分析。我们常接触的软件架构,主要分为以下几种
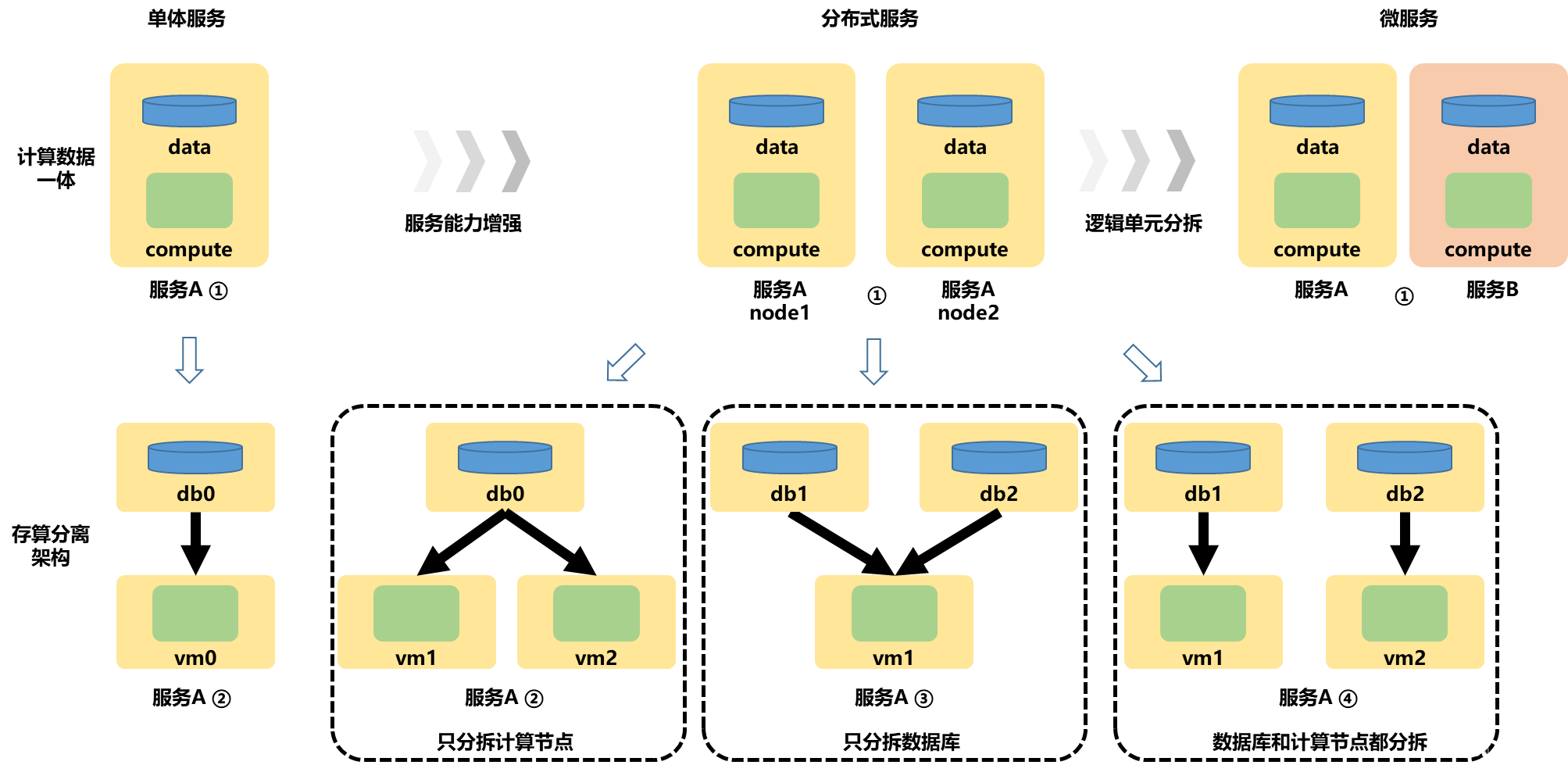
此处由于不是专门讨论软件架构的文章,所以以上所列架构主要用于理解后续文章内容,具体软件架构演进史请查阅其他文章。
-
首先看一下单体架构部分。有接触过编程的同学,对单体服务的②号架构比较熟悉,其特点是多个vm对应一个db。熟悉的原因是,这是标准的单体服务架构,但实际上,最早期的单体服务应该是①的状态,后来出现了存算分离的理论,才拆分出了计算节点(vm)和数据库(db),进而实现了计算能力与存储能力的解耦,以便二者可以互不影响的随时扩容。
-
当单体服务遭遇到大并发,高IO的场景的时候,此时存算分离不能解决这个问题的,进而最佳的思路就是扩容节点,所以关键问题是怎么扩
a)存算一体的架构下①,直接横向扩容。这种架构代理的问题是,假设我是一个高并发,计算密集的场景,实际来讲我的db io并不高,此时就会导致大量的存储能力浪费。同样,通过存算分离理论的引入,可以将服务分拆之后,再针对计算节点(vm)和数据库(db)分别进行横向扩容,进而出现了②、③和④这种架构。
b)先来看②和③架构,可以看到相比于①,只是在存算分离拆分后,分别对计算节点(vm)和数据库(db)分别进行横向扩容。在②架构中,各个vm都是相同代码部署,执行的都是同类的服务。而在③架构中,db1和db2的数据可以相同也可以不同(分析见后)。
c)再来看④,其实现的是一种计算与存储能力解耦后,各自横向扩容得到的架构。
-
既然分布式架构已经能够实现单体服务能力的增强了,那么微服务架构存在的意义是什么呢?
微服务架构并不是用于增强某个微服务能力的架构方案,本质上是为了在功能或者业务上实现解耦。比如订单功能和库存功能,如果都写在一个服务里,从代码维护的角度来看就是很复杂,而且无法解耦横向扩容。此时如果把这部分功能分拆成两个微服务,从业务逻辑上来看更清晰,单个功能模块扩容也更方便。
分布式架构与微服务架构的本质区别
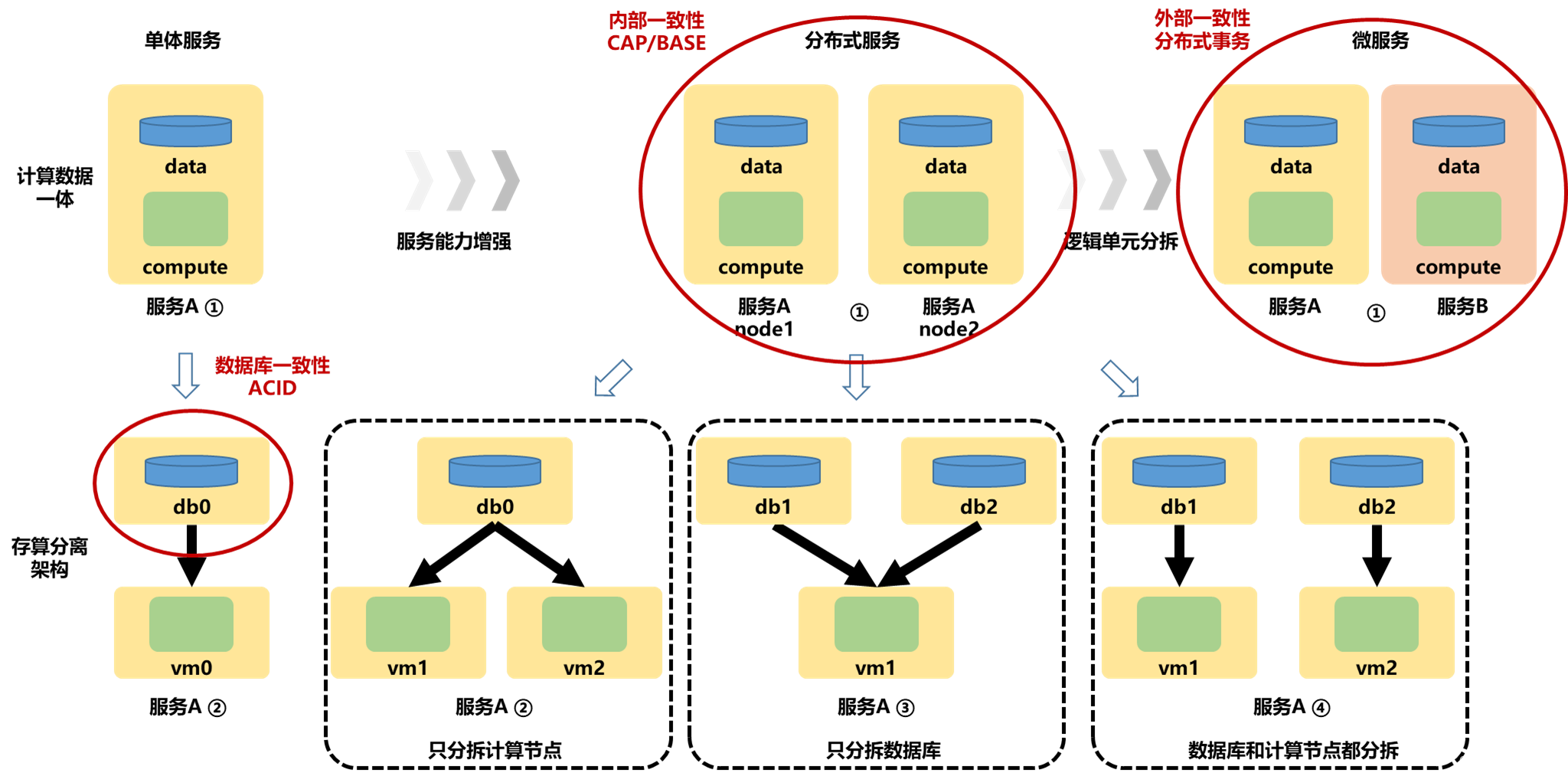
所以本质上分布式架构是对单体架构服务能力的一种增强,而微服务架构是将不同逻辑功能进行一种拆分。这个是逻辑上的划分,但是我们在软件架构层面去看,实际上对于分布式服务的①架构和微服务的①架构,发现每台vm上其实都是有数据和计算能力的。
- 只是对于分布式服务的①架构,我们是希望,每个节点上,数据在时时刻刻都是完全一样的(这就是内部一致性,避免造成混淆),
- 而在微服务的①架构中,我们并不会要求,整套微服务系统里面的节点数据都互相相同,这明显就丧失了服务拆分的意义。但是,我们却期望其中各个节点的数据是合理的或者说符合业务要求的(这就是外部一致性),什么是合理呢?比如A服务和B服务可以认为是两个账户系统,A向B转了100块,那A是不是少了100,B是不是多了100,这就是合理。
分布式架构下存算分离带来的问题
当在分布式架构下,实现存算分离架构后。计算节点由于部署的是相同的业务,直接实现横向扩展,不会带来新的问题。但是的当db多起来的时候,问题就多了(分布式服务①、③、④都会有这种问题)。搞清楚这些问题,就要搞清楚我们,引入多db的目的到底是为了什么
- 为了业务稳定性提升(db不宕机)
- 为了数据可靠性提升(数据容错性高)
- 为了存储量、性能提升(应付更大业务量)
如何解决上述问题呢?
- 对于目的1和目的2,最好的方案就是多个db存一份数据,这样子可以实现db间互为备份,互为校验。这样一个db挂了,另一个db立马顶上。
- 对于目的3,最好的方案是拆库拆表,此时多个db存储的数据就不同了。拆库拆表的实现一般是通过数据库中间件的方式实现的,此时本质上多个db可以理解为一个大db,可以等效于单体服务②(如果只有1个vm)或者分布式服务②处理
所以此处,本文我们不单独讨论分布式服务架构③中db数据不一致的情况,而是在讨论其他架构的情况下,顺便讨论了架构③。
但是当出现多个db要存同一份数据的时候,又出现了一个问题,即写入数据不一致的时候,在写入数据的时候我到底听谁的?比如此时假设db1收到写入a,db2收到写入b。这本质上是一个拜占庭问题,需要在做数据同步的时候解决。
- 解决方案一:只允许单写,此时这个问题就退化为单节点写入问题,mysql的主从(读写)同步方案就是采用类似方案
- 解决方案二:允许多写,此时需要解决拜占庭将军问题。业界raft、paxos、zab算法就能解决类似问题。mysql在5.7引入的group replication方案就是用的paxos解决此问题
一般来讲,很多时候以上手段都会结合起来使用(即多副本+主从同步/共识算法),既保障业务稳定性、数据容错性,又提升了系统性能,代价就是成本比较高。
数据一致性问题定义
好了,分布式架构和微服务架构我们基本介绍清楚了,接下来我们看一下数据一致性的定义。
定义
数据库一致性(单个db数据一致性):单实例数据库内部,不同事务间的数据能否实现一致(见ACID中的C)
内部一致性(服务内部一致性):单个微服务内部,不同vm间,数据能否实现一致(准确定义见CAP理论中的C)
外部一致性(微服务间一致性):整个系统,多个微服务之间的数据能否实现一致(尚无明确定义)
如何理解这种定义
要理解数据一致性的定义,首先要思考一个最重要的问题。数据一致性是不是就等价于说数据是相同的?
这是任何一个不了解数据一致性的人天然会产生的疑问。其实答案是否定的,而且在不同的范围内,数据一致性的定义是有不同的。数据一致性有广义和狭义的区别
- 狭义定义:在单个微服务内部,数据一致性意味着各个节点的数据完全相同
- 广义定义:在多个微服务系统间,数据的一致性意味着各个微服务数据合理
这种广义和狭义的区别,来源于对于分布式系统的理解不同。业界通常情况下,认为多个微服务组成的系统,也是一种广义的分布式系统,原因是认为他们共同在完成某种业务。但实际上来讲,他们并不是那种,各个节点都在执行相同任务的分布式服务系统。
其实数据一致性的问题,更应该理解为在不同范围下,数据的合理性问题
要理解数据一致性的定义,只需要理解在系统的不同的范围内,我们关注的是什么
-
数据库一致性:对于针对单一数据库实例的多个事务操作,我们关心的是数据库能否保证数据的正确读写
- 写入数据是不是正确(C)
- 写出是否成功(D)
- 多个事务执行时,写入顺序会不会乱(A,I)
-
内部一致性:对于单一的微服务,我们关心的是各vm间的运行关系
- 上一次写入的数据,本次是不是可以读取到
- 同一时间不同节点读取的数据是不是相同
-
外部一致性:对于完整的多微服务系统,我们关心的是微服务间能不能协作
- 数据写入时,是不是全部服务都能写入成功
- 多个事务执行时,写入顺序会不会乱
- 当发起数据读取的时候,多个微服务数据耦合后得到的结果,是否是正确结果。
针对各个范围内关注问题的不同,出现了数据一致性在不同范围内的不同定义,也产生了不同的理论及方案。
一致性的弱化定义
前面看到,在不同范围内,数据一致性的定义是不同的。但是在不同的一致性定义下,数据一致性还有强弱之分。原因是数据一致性(合理)即便可以达到,可能也需要一定的时间。这就导致了一致性有不同的实现标准
- 强一致性:数据更新成功后,「任意时刻」「所有相同请求」得到的数据都是一致的,一般采用同步的方式实现。
- 弱一致性:数据更新成功后,系统不承诺立即可以读到最新写入的值,也不承诺具体多久之后可以读到。
- 最终一致性:弱一致性的一种形式,数据更新成功后,系统不承诺立即可以返回最新写入的值,但是保证最终会返回上一次更新操作的值。
一般来说数据一致性,都指「强一致性」,所有的系统都追求强一致性,但是实现起来会有各种阻碍。
- 在单体服务系统中,通过本地事务就可以实现。因为db本身实现了ACID,所以,单db的情况下,只需要保证数据写入顺序,天然就能实现数据「强一致性」。
- 但在分布式服务中(单个微服务),CAP定理指出,一味追求的强一致性会出现问题,所以由BASE理论权衡后,经常实现的是「弱一致性」和「最终一致性」。
- 在微服务系统中,由于分布式事务自身的实现特点,以及单个微服务分布式系统内部存在的数据一致性问题,所以分布式事务实现的也更多是「弱一致性」和「最终一致性」。
如何实现数据一致性
数据一致性的实现方式如下
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-UUq35vYK-1660719512889)(/C:/Users/admin/AppData/Local/Temp/1658223354887.png)]](https://img-blog.csdnimg.cn/5d18801330794c19b4848cc88c88243d.png)
理论支持
不同数据一致性的理论支持如下
- 数据库一致性:通过ACID理论实现
- 内部一致性:系统内单个服务内部数据一致性,通过CAP定理、BASE理论实现
- 外部一致性:整个「系统」(多个服务)级别一致性,通过分布式事务实现。
实现方式
不同数据一致性的实现方式如下
- 数据库级别数据一致性:undolog redolog等手段
- 外部一致性:2PC,3PC,TCC,本地消息表
- 内部一致性:raft、paxos、zab等算法
对于外部一致性的保证,其实现主要有两种思路
- 多个微服务的操作统一成一个大事务统一提交(db层方案)
- 各个服务自己先提交自己的,如果有失败,在应用层补偿回来(应用层方案)
最令人疑惑的是内部一致性问题,我们对于分布式服务中的①、②、③、④四中架构分别分析。
- 首先分析②架构,此时是多个vm对应1个db。
- 在读的过程中,由于多个vm的数据全部都是读取的1个db数据,所以读的过程中,不会出现数据不一致问题
- 在写的过程中,此时写并发会使得数据写入顺序发生改变,可能会产生写入问题。如库存扣减,总共10个库存,两个扣减操作并发,A扣减10,B扣减10,此时如果顺序发生错误,可能会影响结果。解决方案是加锁,使其向像本地事务一样,排好顺序再处理。
- 对于架构①和架构④,本质上是等效架构,都是每个计算节点配相应的存储服务,只不过①配在了计算节点内部,④配在了计算节点外部,合并讨论。当每个计算节点,收到请求,都只能操作自己的db的时候。那么其操作一定要同步给其他节点,否则数据就会产生差异。因为当节点存储的数据不同的时候,每个节点就不可能提供相同的服务能力了。只要涉及到数据同步,就要考虑拜占庭将军问题的解决,要么就只能退化为单写节点。如果解决拜占庭问题,就得用raft、paxos、zab等共识算法
- 对于③架构,一个计算节点可以操作多个数据库,前面提到了如果多个db存的数据不一致的情况,可以等效于单体服务架构②或分布式服务架构②处理,所以此处只讨论多个db存的都是一样的情况,那么其实现方式同2,也要考虑拜占庭将军问题的解决,要么就只能退化为单写节点。如果解决拜占庭问题,就得用raft、paxos、zab等共识算法
所以我们发现,②架构一般保证数据读写顺序不出问题,就可以实现一致性。①、③和④架构下的问题,要么退化为单写,要么解决拜占庭将军问题。
存在意义
为什么要关注这么多的一致性呢?我们发现,当要保证一套业务系统(包含多个微服务)的数据一致性的时候,需要数据库一致性、内部一致性、外部一致性都考虑到。
- 数据库一致性保证了当对单一数据库进行多个事务操作的时候,数据的合理性。
- 内部一致性保证了,在给一个微服务的某个分布式节点a写入某个数据后,再从这个微服务任意节点读取这个数据,都能够顺利的读取到(可能不是立即读取)
- 外部一致性保证了,整个系统,在执行某个操作的时候,多个微服务合作是融洽的。比如某个操作要求,A服务向B服务和C服务写入某个数据,B和C都能进行数据操作。此时,当我需要读取B和C写入的数据的时候,B和C能够返回正确的数据。
我们发现,外部一致性是基于内部一致性实现的,而内部一致性是基于数据库级别一致性实现的
事务与数据一致性的定义及关系
事务的分类
- 1个服务使用1个数据源:本地事务 + 分布式锁(在多vm为服务中,添加的内部一致性保障)
1个服务使用多个数据源:全局事务(一般用的很少,因为可以把一个服务拆成多个)多个服务使用1个数据源:共享事务(不会这么使用,完全可以把多个服务合一)- 多个服务使用多个数据源:分布式事务。一般采用1个服务使用1个数据源,外加服务间rpc调用实现。
一般1个服务只会使用1个数据源(一个库),很少会出现1对多或多对一的场景。
- 1个服务对应多个数据源,此时也无法进行关联查询,不如直接拆库
- 多个服务使用1个数据源,说明这些服务业务强相关,直接抽象为1个服务效果更佳。
另外,由于事务分类主要作用于外部一致性,所以事务的分类里并没有讨论每个为服务中存在多个vm的情况,事务的分类也并不关心单个微服务内部究竟有多个vm。但比如1个服务使用1个数据源,在此服务中,也可以存在多个vm,同样会出现内部一致性问题。但此类问题不能通过分布式事务方案进行解决,一般需要配合分布式锁实现db的操作。
事务与一致性的关系
前面叙述了,事务是实现外部一致性,换而言之整个系统(包含多个微服务)数据一致性的手段。但外部一致性的达成,会受到很多因素的影响。
假设有3个服务,A调用B和C生成最终的result。我从希望从A拿到的数据是合理的,那么A从B和C拿到的数据就一定也要是合理的。因而我们发现
外部一致性,除了会受事务的处理操作影响,还会受到B、C的内部一致性影响。
内部一致性,除了受到单个微服务应用层代码的影响,还会受到db层一致性的影响。
因而,当内部一致性无法达到强一致的时候,外部一致性也很难达到强一致。换成人话就是,当单个微服务给的数据都不对的时候,多个微服务间的数据合理性就无从谈起。
数据库一致性(本地事务的解决方案)
理论支撑
ACID
ACID为事务必须满足的四个基本要素,一般用于指导「数据库事务」设计。一般A、I、D为手段,C为目的。
-
Atomicity(原子性):事务是一个不可分割的最小工作单位,一个事务中的所有操作,要么全部成功,要么全部回滚,
-
Consistency(强一致性):即所有操作是符合现实当中的期望的。
例如,A有300,B有200,A给B转账,此时A和B的转账是符合期望的,即A有200,B有300.
-
Isolation(隔离性):多个事务并发访问时,事务之间是隔离的,一个事务不应该影响其它事务运行效果。
-
Durability(持久性):事务处理结束后,对数据的修改就是永久的,即便系统故障也不会丢失。
解决方案
db的事务能力是通过undo log和redo log实现的
- A是通过 undo log 来实现的
- D是通过 redo log 来实现的
- I是通过 (读写锁+MVCC)来实现的
- C是通过以上三种属性来实现的
由于单vm问题,由于db层实现了事务能力,所以应用层要做的是将操作排好序,传递给db就能实现本地事务能力。而且在单vm场景下,实现数据强一致性不会引入其他问题,所以直接基于db能力可以实现强一致性
内部一致性问题解决方案
理论支撑
首先,在讨论理论之前,我们要理解一个问题,就是CAP应用范围到底是什么。很多人见到分布式事务上来就提CAP理论,实际上是有问题的。他们的问题在于,把分布式系统的广义定义和狭义定义搞混了。CAP理论解决的是,单个微服务内部各分布式节点的一致性问题,而不是微服务与微服务间的数据一致问题。CAP理论他跟分布式事务鸟关系都没有。这个问题也是困扰了我很久的一个问题。分布式事务的实现就是所有的分布式操作组建一个大事务,统一提交,或者各自提交之后,rollback的时候再补偿,跟CAP一点关系都没有!
举一个很简单的例子我有三个服务A,B,C,都各自只有一个节点。A的一个操作依赖于B写入一个数据1,C写入另一个数据2,B和C完全可以没有任何的联系,分区容错就更无从谈起。
CAP
一个分布式系统不可能同时满足 C, A, P ,只能满足其中两个
C:强一致性
论文中的定义
引用Seth Gilbert and Nancy Lynch的论文 中的定义
There must exist a total order on all operations such that each operation loks as if it were completed at a single instant. This is equivalent to requiring requests of the distributed shared memory to act as if they were executing on a single node, responding to operations one at a time.
所有的操作拥有一个顺序,这个顺序可以看作是在一个单机上完成的。对分布式内存的请求像处理单机请求一样,一次只响应一个操作请求。
理解一下,这段定义主要说的是
- 分布式系统的数据操作效果要和单节点系统效果一样
- 一次只执行一个操作更像是一个单线程操作
- 关注点在操作的执行顺序
综合起来看,如果所有分布式节点的数据都永远一致,一定能达到上述C的条件
网上定义阐述
看了很多CAP的文章,为什么网上对C的定义这么繁杂呢?
可以看到,前面论文中定义要求所有的操作拥有一个顺序,这个顺序可以看作是在一个单机上完成的,这句话只具有理论意义,但不具有工程意义。在工程中,什么情况下才算是满足这种要求呢?
实际上,在分布式系统中,可以通过分布式系统的多次读写来验证是否满足此定义。结合读写验证结果,网上演化出了很多对C的不同定义,如此处引用
all clients see the same data at the same time
所有客户端在同一时间(同类请求)看到的数据完全一致
read是一种验证数据的方式,当所有客户端在同一时间(同类请求)看到的数据完全一致,可以认为果所有分布式节点的数据都是一致的
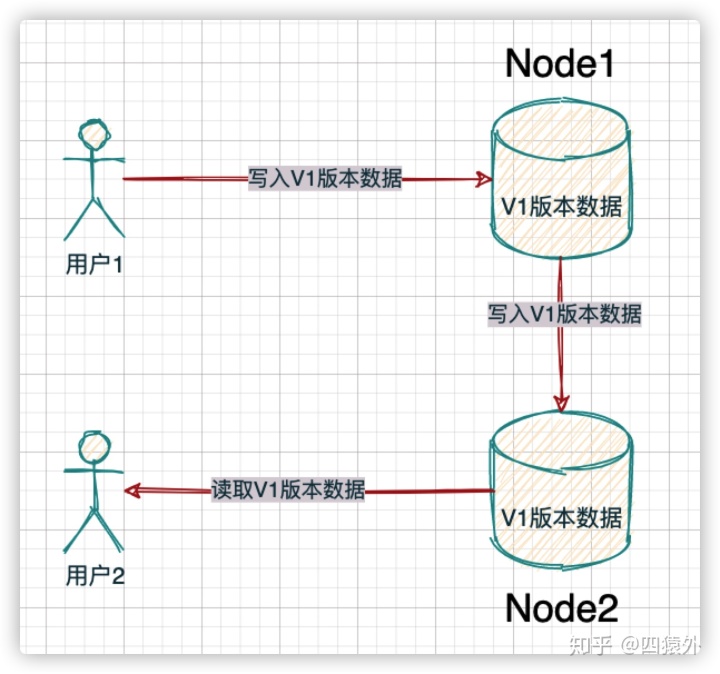
结论
满足一致性:「所有客户端」在「同一时间」read 的数据完全一致
不满足一致性:「有客户端」在「同一时间」read 的数据不一致
A:可用性
论文中的定义
For a distributed system to be continuously available, every request received by a non-failing node in the system must result in a response.
分布式系统可用,系统中非故障节点接收到的每个请求(无论是读请求还是写请求)都必须得到响应(给了响应,响应的对不对不重要)。
什么是非故障节点?
-
情况一:node级别部分崩溃,崩溃的node认为是故障节点,不参与可用性评估。
如果节点不能正常接收request了,比如宕机了,系统崩溃了,此时可以通过探活轻易排除这些节点。而其他节点依然能正常接收请求,那么可以认为系统依然是可用的,也就是说,部分宕机没事儿,不影响可用性指标。
-
情况二:node内部数据异常,这部分node还认为是正常非故障节点,参与可用性评估
数据异常最怕的不是宕机,因为宕机可识别,最怕的是业务异常,此时无法甄别。此时,我们只能认为这些无法摘除的节点为正常节点。如果节点能正常接收request,但是发现节点内部数据有问题,那么也必须返回结果,哪怕返回的结果是有问题的。
什么算是响应成功?
-
一定要返回一个值,这个值是否合理不在可用性讨论范围内。
比如,系统有两个节点,其中有一个节点数据版本是v0,另一个节点版本是v1,如果,一个read请求跑到了v0版本的节点上,抱歉,这个节点也不能拒绝,必须返回这个v0数据,即使它可能不太合理。
-
响应成功一般认为还应满足时延要求。(此条在定理中没有单独做要求)
返回结果应在合理的时间以内,这个合理的时间是根据业务来定的。比如,业务说必须 100 毫秒内返回,合理的时间就是 100 毫秒,需要 1 秒内返回,那就是 1 秒,如果业务定的 100 毫秒,结果却在 1 秒才返回,那么这个系统就不满足可用性
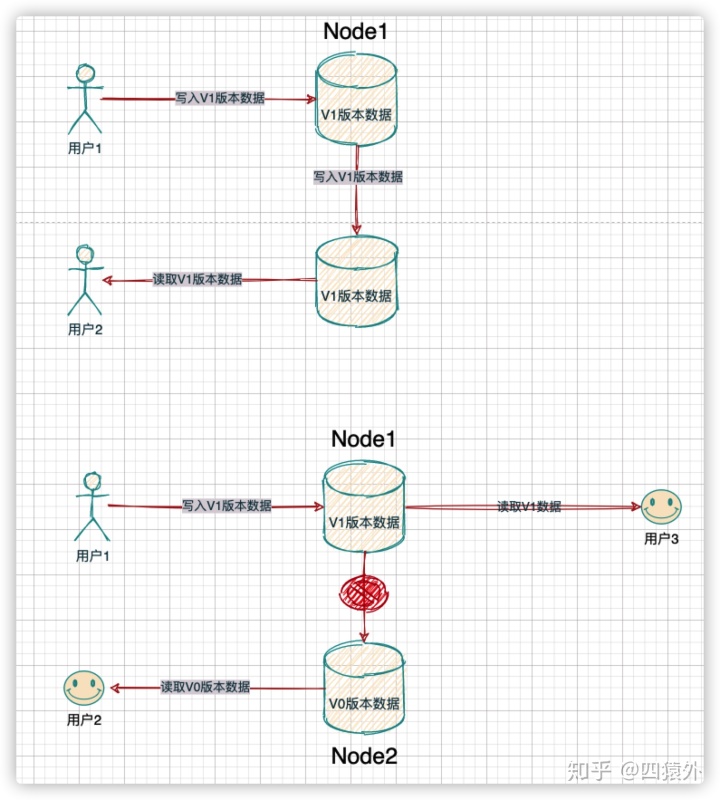
结论
满足可用性:所有的非故障node都给出了响应
不满足可用性:有非故障node没有给出响应
P :分区容错性
论文中的定义
In order to model partion tolerance, the network will be allowed to lose arbitrarily many messages sent from one node to another.
为了做到分区容错,网络要允许丢失任意从某个结点到另一结点的数据。(系统依然运行)
分区容错发生的两种可能
network故障导致的分区。此时服务都依然都在运行,都必须还在对外提供服务
我们的分布式存储系统有 A、B 两个节点。那么,当 A、B 之间由于可能路由器、交换机等底层网络设备出现了故障,A 和 B 通信出现了问题,这时候,就说 A 和 B 发生了分区。
什么是系统运行
当一个系统,哪怕只有一个node,仍能够处理各类请求的时候,就算是系统运行。只不过此时,不算是高可用。
结论
满足分区容错性:出现了分区问题,我们的分布式存储系统还需要继续运行。
不满足分区容错性:出现了分区问题后,分布式存储系统不能正常运行。
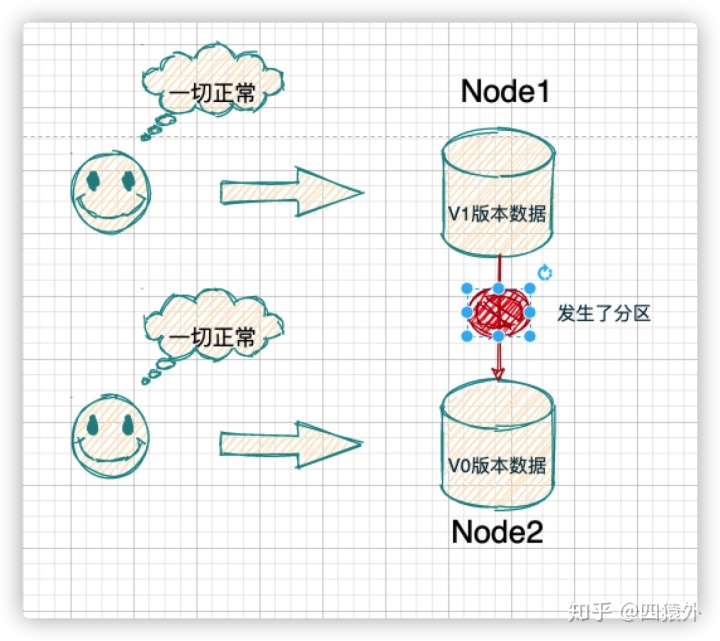
CAP理论权衡
在分布式系统内,P 是天然需要满足的,因为必须满足出现了分区问题,我们的分布式存储系统还需要继续运行,如果不满足P,一旦发生分区错误,整个分布式系统就会完全崩溃。
所以开源的分布式系统往往又被分为 CP 系统和 AP 系统
**CP 系统:**当一套系统在发生分区故障后,「客户端的任何请求都被卡死或者超时」,但是,系统的每个节点总是会返回一致的数据,经典的比如 Zookeeper。
**AP系统:**如果一套系统发生分区故障后,客户端依然可以访问系统,「但是获取的数据有的是新的数据,有的还是老数据」,经典的比如 Eureka。
可以看到,牺牲A常见的方式就是阻塞错误请求,牺牲C只需要不做数据校验同步即可。
CAP 就是告诉程序员们当分布式系统出现内部问题了,你要做两种选择:
- 要么让外部服务迁就你,像银行。( CP 系统,Zookeeper)
- 要么迁就外部服务,像外包公司。(AP系统,Eureka)
CAP常见误区
误解一:分布式系统必须放弃 C 或者 A 中的其中一个
当没有出现分区问题的时候,系统就应该有完美的数据一致性和可用性。只有在出现分区问题时,才需进行权衡。
(待补充)
BASE理论
即使无法做到强一致性,但每个应用都可以根据自身业务特点采用适当的方式来使系统达到最终一致性
-
Basically Available(基本可用):如何牺牲A
当分布式系统出现故障时,允许损失部分可用性,保证核心模块的可用性。这个很好理解,当出现故障时,首先考虑的肯定是核心模块,但也不是说要牺牲掉其他模块,只是在极端情况下对服务做的降级。
-
Soft state(软状态):如何牺牲C中的原子性
软状态指允许系统中的数据存在中间状态,并认为该中间状态的存在不会影响系统的整体可用性,即允许系统在不同节点的数据副本之间进行数据同步的过程存在延时。例如mysql的主从同步就是存在延时的,只要上游可以接受这种延时,就没有问题。
-
Eventually consistent(最终一致性):如何牺牲C中的强一致性
系统中的所有数据副本经过一定时间后,最终能够达到一致的状态。针对不同的业务,数据达到一致状态的容忍时间也是不同的。我注册之后,可以几秒钟就需要登陆,需要数据一致,但是发表一篇文章,几分钟之后达到一致性也不会有影响。
常见问题
ACID、CAP、BASE的关系
- ACID中的C和CAP以及BASE中的S并不是一个东西,原因在于不同的范围,造就了不同的合理性定义
- ACID是「数据库事务」的基本要素,一般只用于数据库层的一致性保证。
- CAP是一种C与其他性质的权衡「定理」,CAP 是学术理论,得到过证明。
- BASE是由于CAP定理不具备工程特性,进而基于CAP理论演化出的一种「工程权衡方案」
ACID和CAP中的C其实是一个东西吗
在了解ACID和CAP定理关系之前,我们需要先讨论一下ACID和CAP中的C其实是一个东西吗。
网上很多文章提到ACID中的C和CAP理论中的C不是一种东西,这里我们看一下二者的定义和理解。首先ACID是对事务基本要素的描述
ACID中C,引用wiki的定义
一致性(Consistency):在事务开始之前和事务结束以后,数据库的完整性没有被破坏。这表示写入的资料必须完全符合所有的预设约束、触发器、级联回滚等。
CAP中的C,引用Seth Gilbert and Nancy Lynch的论文 中的解释
Discussing atomic consistency is somewhat different than talking about an ACID database, as database consistency refers to transactions, while atomic consistency refers only to a property of a single request/response operation sequence. And it has a different meaning than the Atomic in ACID, as it subsumes the database notions of both Atomic and Consistent
CAP中的C和ACID中的C是不同的,ACID中的C涉及事务处理,但CAP中的C只讨论一系列读写操作顺序。同时原子一致性与ACID中的A也是不同的,CAP中的C更像是ACID中A和C的融合概念
所以ACID中的C和CAP中的C不是一个东西,原因在于其合理性定义不同
另外,其实上述都是在描述一件事,即「系统中数据的合理性」,ACID中的C是从系统内部数据的角度讨论合理性,CAP中的C是从数据执行顺序角度讨论合理性。在实际理解过程中,多数情况下没有必要过于锱铢必较,可以认为两者“一致”
解决方案
解决内部一致性问题其本质就是解决拜占庭将军问题。解决拜占庭将军问题有几种算法,PBFT、Pow、Raft、Paxos、Zab。PBFT、Pow一般用于区块链比较多,Paxos理解十分复杂,所以很难实现。Zab和Raft与原理相同,所以此处只介绍Raft算法
架构②:本地事务 + 分布式锁
由于内部一致性问题的特点,即当存在一个多vm的服务,读操作到底谁来做?写操作到底谁来做?一般通过使用本地事务+分布式锁的方式实现。本地事务负责保证事务的原子性,分布式锁用于保证事务处理的有序性。
Paxos、Raft、Zab算法(待补充)
外部一致性问题解决方案
分布式事务解决方案
「强一致性事务」实现方案一般都集中在「数据库层」,在业务层面实现的分布式事务方案,由于数据已经提交过,再通过补偿等方式回滚,很有可能会使业务读到脏数据,所以「业务层」实现的一般都是「弱一致性」。
所有分布式事务的解决方案都是将分布式事务解耦,将一个分布式事务,解锁为多个本地事务,通过引入「事务协调器」将多个本地事务进行重新组合
db层(强一致性事务)
2pc(2 phase commit)
方案
详细2PC方案可参见:https://zhuanlan.zhihu.com/p/91263461
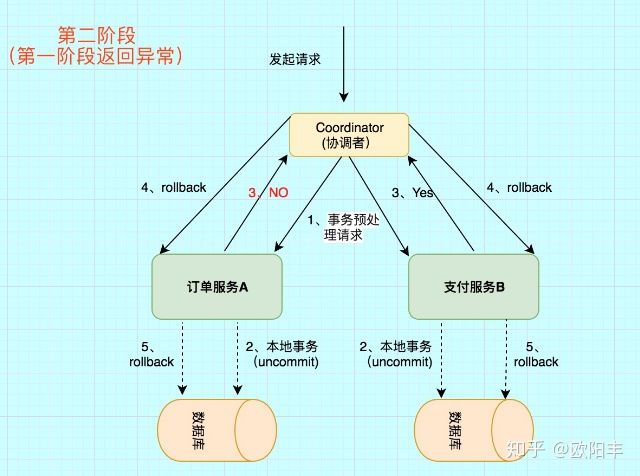
2PC引入一个「事务管理器(TM:Transaction Manager)」的角色来协调管理「事务参与者(Resource Manager)」的提交和回滚,二阶段分别指的是prepare和commit两个阶段。
(1)准备阶段:TM给每个RM发送Prepare消息,每个RM在本地执行事务,并写Undo/Redo log,此时本地事务没有commit。
(2)提交阶段:TM收到每个RM的执行success或者failed消息时,给RM发送回滚(Rollback)或提交(Commit)消息。RM根据Undo/Redo log执行Rollback操作,或直接commit。
原理
通过引入TM将分布式事务拆分为多个本地事务,然后通过本地事务的redo log/undo log来实现回滚等能力。
问题
-
性能问题:在执行分布式事务过程中,全程TM和RM的资源都被加锁,直到结束才释放,对性能影响较大。
-
死锁问题:由于prepare执行完成后,RM都处于阻塞状态,一旦TM发生故障,所有的RM都会死锁。
-
单点故障问题:
1) TM正常,RM宕机
此时,其他RM和TM不知道故障RM的情况,不知道是否进行到下一阶段。
解决方案: TM引入超时机制,如果TM在超过指定的时间还没有收到参与者的反馈,事务就失败,向所有节点发送终止事务请求。
2) TM宕机,RM正常
TM相当于是个裁判,无论哪个阶段TM宕机,都没人发送commit、rollback等指令,事务都没法继续下去。
解决方案: 引入TM备份,同时TM需记录操作日志.当检测到TM宕机一段时间后,TM备份取代TM,并读取操作日志,向所有RM询问状态。
3) TM和RM都宕机
- 发生在第一阶段: 因为第一阶段,所有RM都没有真正执行commit,所以只需重新在剩余的RM中重新选出一个TM,新的TM在重新执行第一阶段和第二阶段就可以了。
- 发生在第二阶段 并且 有部分RM已经执行完commit操作。就好比这里订单服务A和支付服务B都收到TM 发送的commit信息,开始真正执行本地事务commit,但突发情况,A commit成功,B挂了。这个时候目前来讲数据是不一致的。2PC 无法解决这个问题。
3pc(3 phase commit)
方案
详细2PC方案可参见:https://zhuanlan.zhihu.com/p/91263461
3pc相较于2pc有两个改动点。
-
2pc给TM引入超时,当RM没有反馈时,可以主动发起rollback,3pc给RM也加入了超时,避免当协TM崩溃时,RM不能及时释放锁,造成业务阻塞。
避免了RM在长时间无法与协调者节点通讯(TM挂掉了)的情况下,无法释放资源的问题,因为RM自身拥有超时机制会在超时后,自动进行本地commit从而进行释放资源。而这种机制也侧面降低了整个事务的阻塞时间和范围。
-
3PC把2PC的prepare阶段再次一分为二,这样三阶段提交就有CanCommit、PreCommit、DoCommit三个阶段。
通过CanCommit、PreCommit、DoCommit三个阶段的设计,相较于2PC而言,多设置了一个缓冲阶段保证了在最后提交阶段之前各RM节点的状态是一致的
应用层(最终一致性方案)
tcc(try confirm cancel)
方案
详细方案可参见:http://t.zoukankan.com/clarino-p-13281843.html
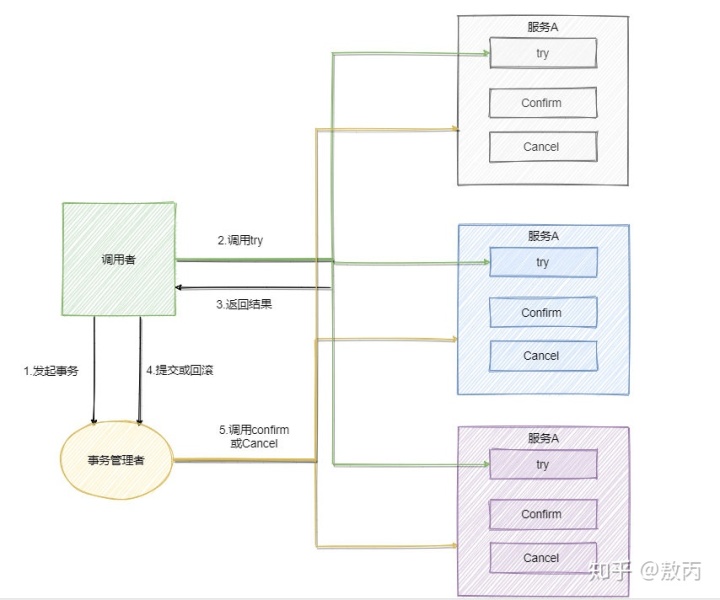
TCC 指的是Try - Confirm - Cancel,tcc方案一般会定义一个事务管理者,来执行confirm或cancel。事务管理者实现逻辑比较复杂,一般选用现有的框架,如开源的框架主要有:ByteTCC,tcc-transaction,himly。
- Try 指的是预留,即资源的预留和锁定,注意是预留不是直接使用。
- Confirm 指的是确认操作,这一步其实就是真正的执行了。
- Cancel 指的是撤销操作,可以理解为把「预留阶段」的动作撤销了。
Try 阶段:主要用于锁定资源,预操作。如库存提前冻结。
比如用户下单的操作,需要扣减库存,同时增加用户积分
- 某产品
现有库存有100,此订单购买2,可以保持原有库存不变,在一个单独的冻结库存字段里,设置一个2,表示库存冻结2。如果有其他扣减库存的线程,可以通过使用现有库存-冻结库存进行库存校验,但查询实际库存时,使用现有库存,类似设置一个缓存字段 - 某用户
现有积分为100,下单赠送10,可以保持原有积分不变,在一个单独的冻结积分字段里,设置一个10,表示有10个积分准备增加。
Confirm/Cancel阶段:针对锁定资源进行确认/取消操作(清空缓存)
- Confirm:缓存清空,数据合并到
现有xx数据字段中 - Cancel:清空缓存
原理
TCC 是一种补偿性事务思想,通过定义错误补偿方案,来实现事务回滚。
TCC与2PC本质上是一类方案,只不过2PC方案在db层实现,利用了db本地事务的undo/redo log能力实现数据回滚,而TCC方案在应用层实现,只能通过业务代偿实现回滚,而应用层的代偿全都需要手动自定义。
本地消息表(最常用)
这种方案会有一张「本地消息表」再结合「MQ」实现分布式事务。
「本地消息表」用于pub是否向MQ发消息成功,消息表中状态有0-未发送,1-已发送。
「MQ」负责异步存储sub待执行消息。
方案
以pub订单创建、sub扣除库存为例。(实现代码可见下方)
-
pub方:插入订单记录时,同步(在同一事务中)保存一条消息到pub的本地消息表(orderMapper)中,状态字段变为未0-发送。此步失败直接抛异常
-
pub方:在第1步执行成功的基础上,立即尝试在与1同一线程中将消发送到 MQ,尽量确保时效性。
发送成功:调用confirm回调,修改本地消息表(orderMapper)中的状态字段为1-已发送
发送失败:跳过,问题不大,此线程不再处理,后面有定时线程刷新
-
设置一条定时补偿任务,轮询扫描订单的本地消息表,找出所有未发送的记录,进行消息发送。
----------至此已可保证消息必进MQ,pub的本地消息表(orderMapper)已用完----------
-
sub方:处理stock扣减库存的操作,并同步保存一条信息到sub的本地消息表(stockMapper)中,对于操作失败的消息重新放回MQ,由其他消费者处理即可,不抛异常
必须采用手动ack机制+重试机制,业务处理失败可以将消息重新放回MQ
接收到消息后需进行幂等性判断,避免重试过程中,多次执行业务操作
orderMapper中保存待发送到MQ的信息,用于消息发送重试
stockMapper中保存已处理信息,用于幂等性验证
异常分析
- 如果第1步失败,订单记录插入失败,但是本地消息表中无内容,可以认为订单创建失败
- 如果第2步失败,第2步存在的意义在于在订单记录插入后,尽快把MQ发出去,但是有可能会失败,但是失败问题也不大,后面会有定时线程刷新尝试重新发送
- 如果第3步失败,定时线程再次发送失败,过一段时间后会重试。此时可以记录发送次数。可以定期人工查看多次发送的数据,进行手工处理。
- 如果第4步失败,操作失败的消息重新放回MQ,供其他sub消费
原理
将分布式事务解耦,拆分成本地事务进行处理。
代码分析
1. pub订单创建
/**
* 创建订单、订单消息、发生消息到 MQ
*/
@Slf4j
@Service
public class OrderServiceImpl {
@Resource
private ClientStock clientStock;
// pub订单本地信息表
@Resource
private OrdersMapper ordersMapper;
@Resource
private OrdersMessageMapper ordersMessageMapper;
@Resource
private RabbitTemplate rabbitTemplate;
/**
* 插入订单记录 和 订单消息表 要保证原子性
*/
@Transactional(rollbackFor = Exception.class)
public boolean createOrder(String orderId) {
// 添加订单记录
Orders orders = new Orders();
orders.setName("蚂蚁课堂");
orders.setOrderCreatetime(new Date());
orders.setOrderState(0);
orders.setOrderMoney(10.0);
orders.setOrderId(orderId);
int flage = ordersMapper.insert(orders);
OrdersMessage ordersMessage = null;
if (flage == 1) {
// 订单记录插入成功
// 本地消息表,添加待加入MQ消息体
Map<String, Object> map = new HashMap<>();
map.put("orderId", orderId);
ordersMessage = new OrdersMessage();
ordersMessage.setId(0);
ordersMessage.setMessageBody(MapperUtils.ObjectToJson(map));
ordersMessage.setStatus(0); // 状态为0表示,消息未发送
ordersMessage.setCreateTime(new Date());
flage = ordersMessageMapper.insert(ordersMessage);
if (flage != 1) {
// 本地消息表添加失败,直接异常
throw new RuntimeException("回滚事务!");
}
}
if(flage == 1 && ordersMessage != null){
// 本地消息表添加成功,且添加订单记录成功
// 注册回调函数
this.rabbitTemplate.setConfirmCallback(new RabbitTemplate.ConfirmCallback() {
@Override
public void confirm(CorrelationData correlationData, boolean ack, String s) {
log.info("消息是否发送成功--->" + ack);
if (ack) {
// 消息发送成功,更改消息表的状态为已发送
log.info("消息发送成功,更改消息表中的状态....");
String id = correlationData.getId();
OrdersMessage ordersMessage = new OrdersMessage();
ordersMessage.setId(Integer.valueOf(id));
ordersMessage.setStatus(1);
ordersMessageMapper.updateByPrimaryKeySelective(ordersMessage);
}
}
});
this.rabbitTemplate.setMandatory(true);
// 向MQ中发送本地消息表中内容
this.rabbitTemplate.convertAndSend("stockExchange","direct.key",ordersMessage.getMessageBody(),
new CorrelationData(ordersMessage.getId() + ""));
// 消息发送成功
return true;
}
// 消费发送失败,不采用
return false;
}
}
2. 后台定时任务,扫描本地消息表
/**
* 定时任务补偿,频次不要太高,主要是为了补偿发 MQ 失败的
*/
@Slf4j
@Component
public class MqSchedule{
@Resource
private OrdersMessageMapper ordersMessageMapper;
@Resource
private RabbitTemplate rabbitTemplate;
@Scheduled(cron = "0/2 * * * * ?")
public void scheduleScanLocalMessage() {
log.info("扫描消息表开始...."+System.currentTimeMillis());
// 查询所有等待发送的消息
Example example = new Example(OrdersMessage.class);
example.createCriteria().andEqualTo("status", 0);
List<OrdersMessage> ordersMessages = ordersMessageMapper.selectByExample(example);
// 对结果轮询发送
ordersMessages.forEach(item -> {
log.info("开始发送本地消息表里面的数据.........");
// 注册回调函数(同pub订单创建中的回调函数)
this.rabbitTemplate.setConfirmCallback(new RabbitTemplate.ConfirmCallback() {
@Override
public void confirm(CorrelationData correlationData, boolean ack, String s) {
log.info("消息是否发送成功--->" + ack);
// 消息发送成功了
if (ack) {
log.info("消息发送成功,更改消息表中的状态....");
// 更改消息表的状态为已发送
String id = correlationData.getId();
OrdersMessage ordersMessage = new OrdersMessage();
ordersMessage.setId(Integer.valueOf(id));
ordersMessage.setStatus(1);
ordersMessageMapper.updateByPrimaryKeySelective(ordersMessage);
}
}
});
this.rabbitTemplate.setMandatory(true);
// 向MQ中发送本地消息表中内容
this.rabbitTemplate.convertAndSend("stockExchange","direct.key",item.getMessageBody(),
new CorrelationData(item.getId() + ""));
});
}
}
3. sub库存消费MQ中内容
/**
* 库存,消费 MQ 消息
*/
@Component
@Slf4j
public class ListenerMessage {
// sub库存本地信息表
@Resource
private StockMapper stockMapper;
@RabbitListener(bindings = {
@QueueBinding(
exchange = @Exchange(value = "stockExchange"),
value = @Queue(value = "stockQueue"),
key = "direct.key"
)
})
@Transactional(rollbackFor = Exception.class)
public void listenerStock(@Payload String messageBody, @Headers Map<String, Object> headers, Channel channel)
throws IOException {
log.info("接收到消息,进行手动签收...接收到的消息内容为----->" + messageBody);
Map map = MapperUtils.JsonToObject(messageBody, Map.class);
String orderId = map.get("orderId").toString();
// 幂等性验证
Example example = new Example(Stock.class);
example.createCriteria()
.andEqualTo("orderId", orderId);
// 检测幂等性,如果stockMapper中已有此记录,表明该记录已处理,直接把MQ信息干掉
Long deliveryTag = (Long) headers.get(AmqpHeaders.DELIVERY_TAG);
if (stockMapper.selectCountByExample(example) > 0) {
log.info("重复消费触发了....");
try {
channel.basicAck(deliveryTag, false);
} catch (Exception e) {
try {
channel.basicNack(deliveryTag, false, false);
} catch (IOException ex) {
ex.printStackTrace();
}
}
return;
}
// 新增一条减库存记录
Stock stock = new Stock();
stock.setOrderId(orderId);
stock.setStock(100);
int flag = stockMapper.insert(stock);
// 插入成功,返回MQ已消费信息
if (flag == 1) {
log.info("新增一条减库存记录成功.....分布式事务完成....");
try {
channel.basicAck(deliveryTag, false);
} catch (Exception e) {
try {
channel.basicNack(deliveryTag, false, false);
} catch (IOException ex) {
ex.printStackTrace();
}
}
}
}
}
以上各种分布式事务解决方案适用场景
- 相比数据库层的2PC和3PC方案,业务层方案可以「跨数据库、跨不同的业务系统」来实现事务
- TCC基于业务补偿操作,但是业务层开发量相较本地消息表方案更大,对业务的侵入较大,业务耦合性较高
- 本地消息表结合MQ的方式,要引入MQ,需要解决MQ的可靠性问题。
- 业务层方案会涉及大量重试操作,要实现接口的幂等性
Seata组件方案
seata是SpringCloudAlibaba开源的一套分布式事务组件,应用比较简单。seata提供了4种事务模式 AT、TCC、SAGA 和 XA 事务模式,其中 XA 模式实现的是刚性事务(强一致),AT、TCC、SAGA 模式实现的都是柔性事务(最终一致性),seata默认采用的是AT模式。
详细的2PC、TCC模式的理解可见:https://blog.csdn.net/m0_70651612/article/details/125609575?spm=1001.2014.3001.5501
AT模式(应用层2PC方案,只能实现最终一致性)
AT模式最常用,本质上是一种2PC模式的变种。
- 2PC模式操作在db层,利用db的事务能力(undo log/redo log),实现回滚操作。但是2PC的问题在于,在分布式事务未整体提交之前,所有的RM资源,全部都被加锁,只有在commit或rollback才会解锁,极大降低了并发性能。
AT模式尝试像2PC一样,使用二阶段提交分布式事务,并且采用类似db事务回滚处理,即undolog的方式解决补偿问题,但是undo log建立在单独一张表,实际相当于在应用层实现了undo的逻辑,因此本质上是一种应用层分布式事务的解决方案。所以只能实现弱一致性。
AT模式像2PC模式一样也分两个阶段,但在第一阶段完成后,就直接提交事务,释放所有资源锁。
-
一阶段:业务数据和回滚日志记录在同一个本地事务中提交,释放本地锁和连接资源。
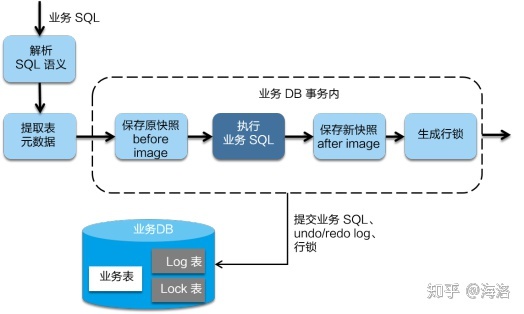
1)Seata 会拦截“业务 SQL”,首先解析 SQL 语义,找到“业务 SQL”要更新的业务数据
2)在业务数据被更新前,将其保存成“before image”
3)然后执行“业务 SQL”更新业务数据,在业务数据更新之后,再将其保存成“after image”
4)最后生成[行锁]。
提交业务sql,并将before image和after image保存到自定义undo log中,以上操作全部在一个数据库事务内完成,这样保证了一阶段操作的原子性。
-
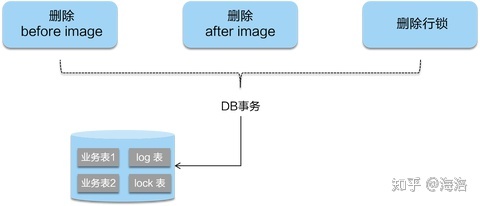
二阶段:分布式事务整体commit/rollback,由于一阶段db事务已提交,所以此时二阶段操作与一阶段操作异步,提高执行效率。
-
commit:二阶段如果是提交的话,因为“业务 SQL”在一阶段已经提交至数据库, 所以 Seata 框架只需将一阶段保存的快照数据和行锁删掉,完成数据清理即可。
-
-
-
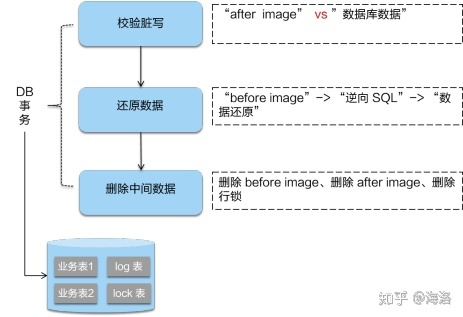
rollback问题:在2PC中,rollback是通过db内置的undolog实现的。在TCC中,rollback是通过自定义补偿操作实现的。AT融合了二者特点,AT模式会在db中建一张自定义undo log表(与db本地事务用的那张不同,非db内置的那张),seata会将业务数据在更新前后的before image和after image数据镜像组织成回滚日志,备份在 UNDO_LOG 表中,用于回滚。
回滚方式便是用“before image”还原业务数据;但在还原前要首先要校验脏写,对比“数据库当前业务数据”和 “after image”,如果两份数据完全一致就说明没有脏写,可以还原业务数据,如果不一致就说明有脏写(比如,当db分布式事务一阶段运行完,二阶段要rollback前,数据又被做了修改),出现脏写就需要转人工处理。
-
-
XA模式(标准2PC方案,实现强一致性)
XA模式就是一个标准的2PC方案,2PC的传统方案是在db层面实现的,如 Oracle、MySQL 都支持 2PC 协议,为了统一标准减少行业内不必要的对接成本,需要制定标准化的处理模型及接口标准,国际开放标准组织 Open Group 定义了分布式事务处理模型DTP。DTP 模型定义TM和RM之间通讯的接口规范叫 XA,简单理解为数据库提供的 2PC 接口协议,基于数据库的 XA 协议来实现 2PC 又称为 XA 方案。
Saga模式(TCC变种,实现最终一致性)
saga模式本质上是一种TCC模式变体,TCC模式是在业务维度,定义一个try、confirm、cnacel,当try操作出现失败,直接调用cancel补偿。而saga相当于是将补偿动作,定义到了各个服务中,对每个服务的操作都分别定义正向操作和逆向补偿操作。在分布式事务的执行过程中,如果任何一个正向操作执行失败,那么分布式事务会退回去执行前面各参与者的逆向回滚操作,回滚已提交的参与者,使分布式事务回到初始状态。
综上,可以看到TCC和Saga模式都涉及大量的自定义操作开发,工作量大,逻辑复杂。标准的XA方案,由于自愿长时间独占的问题,会较大的降低业务并发性能。因此四种方案中,AT方案能够较好地解决分布式事务问题,但是由于柔性事务的性质,可能在使用过程中,出现脏读等问题,脏写等问题,此问题是柔性事务的通病,无法避免。
参考资料
https://blog.csdn.net/slslslyxz/article/details/105949127
https://www.zhihu.com/search?type=content&q=AT%E6%A8%A1%E5%BC%8F%E5%92%8C2PC
https://www.zhihu.com/search?type=content&q=AT%E6%A8%A1%E5%BC%8F%E5%92%8C2PC
https://www.jianshu.com/p/945824381904
https://seata.io/zh-cn/docs/user/quickstart.html
https://wenku.baidu.com/view/5748d1153a68011ca300a6c30c2259010202f3f0.html
https://www.zhihu.com/search?type=content&q=AT%E6%A8%A1%E5%BC%8F%E5%92%8C2PC
参考资料
https://zhuanlan.zhihu.com/p/386324224
https://users.ece.cmu.edu/~adrian/731-sp04/readings/GL-cap.pdf
https://www.zhihu.com/search?type=content&q=cap%E7%90%86%E8%AE%BA%E6%80%8E%E4%B9%88%E7%90%86%E8%A7%A3
https://www.zhihu.com/search?q=%E5%88%86%E5%B8%83%E5%BC%8F%E4%BA%8B%E5%8A%A1%E8%A7%A3%E5%86%B3%E6%96%B9%E6%A1%88&utm_content=search_history&type=content
https://www.jianshu.com/p/3b7da1ebe03c
https://zhuanlan.zhihu.com/p/91263461















 253
253











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









