









雪崩效应介绍:
通过图上来讲解会更通俗易懂
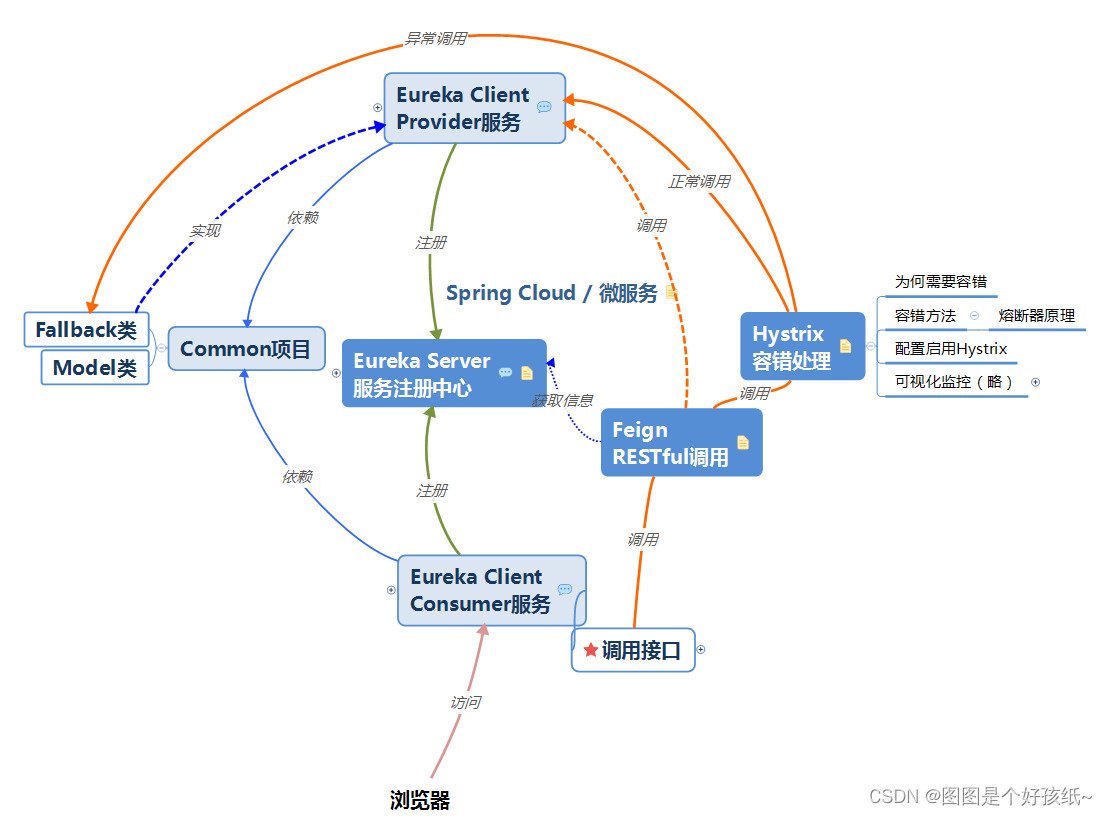
首先浏览器通过客户端(消费者)去服务注册中心区去问客户端(提供者)在哪里,它会通过调用接口去调用我们的提供者,这时我们可以使用Feign Restful 的方式调用,但在调用的时候呢,有可能会调用不到,这时候呢,就会出现熔断,在调用提供者的时候虽然调用不到,但还是得及时的去响应别人,为什么要及时响应别人呢?
就比如我去银行排队存钱,前面有一百多号人,一个人需要5分钟或者更久,我可能等不了那么久,等个20分钟就撤人了,那如果你写程序没有将我撤出来,那么会按最大时间去等待,还有个残剩很多次,刚好就在我撤人的那个点,也就是崩掉的那个点,很多人涌进来,那么这个时候就有可能造成我们的服务器雪崩那么我们称这种现象为:雪崩
那么自己服务器崩掉还是小事,但是可能会引起其他服务器一起雪崩,因为很多人都堆积在我撤回来的那个点,一直在那等待,尝试,拥挤,那么这个服务器因为占着的模块的人数越来越多,那么就有可能导致我的其他服务器一起连锁崩掉,就称为:连环雪崩
熔断器
1、为什么需要熔断器?
在分布式中,我们会根据业务或功能将项目拆分为多个服务单元,各个服务单元之间通过服务注册和订阅的方式相互依赖和调用功能,随着项目和业务的不断拓展,服务单元数量也逐渐增多,相互之间的依赖关系也越来越复杂
这时候,可能会有某个服务单元出现问题或网络原因依赖调用出错或延迟,此时如果调用该依赖的请求不断增加,那么要调用该服务的服务将都会等待或者出现故障
如果后续连锁反应越来越多,Servlet容器的线程资源会被消耗完毕,导致服务瘫痪。服务与服务的依赖会导致服务之间的故障传播,从而迎来"雪崩效应"。为了解决这种每个点或多个点的故障,就有了熔断器的出现。
2、什么是熔断器?
熔断器就相当于电路中的保险丝、保护器,它可以实现快速失败,如果它在某一段时间里侦测到许多类似的错误,它将不再访问远程服务器,会强迫以后的访问都会快速失败,从而防止某个服务不断地尝试执行可能会失败的操作
它会使服务继续执行而不用等待修正错误,或者浪费CPU时间去等到长时间的超时产生,从而进入回路方法。熔断器也可以使服务能够诊断错误是否已经修正,如果已经修正,服务会再次尝试调用操作。
3、修改消费者工程
修改消费者工程中的application.yml文件
设置启用熔断器
feign.hystrix.enabled=true 在消费者工程中增加一个UserFeignClientFallback类实现UserFeignClient接口
@Component
public class UserFeignClientFallback implements UserFeignClient {
@Override
public String login(User user) {
return "登录异常 使用溶断器处理得到到用户: "+user;
}
}接下来UserFeignClient接口中配置UserFeignClientFallback的实现,如下:
@FeignClient(name="user-provider",fallback=UserFeignClientFallback.class)
public interface UserFeignClient {
@RequestMapping(value = "/login",method = RequestMethod.POST)
public String login(@RequestBody User user) throw Exception
}最后重新启动提供者和消费者测试
重新访问
http://localhost:6666/userLogin?userName=老王&age=18用户的数据显现
从提供者收到结果是:提供者login2,返回success ~~~ 老王 18但接下来测试熔断器是否生效,可以把提供者(user-provider)停止服务。继续访问测试
登录异常 使用溶断器处理得到到用户: 老王 18这样表示SpringCloud中的Hystrix熔断器生效了
















 463
463











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











