






本项目是基于计算机视觉的端到端交通路口智能监控系统.采用的设计架构由SRS流媒体服务器、GPU服务器、Local客户端三部分组成.可将远端视频流通过rtmp协议传输到流媒体服务器,然后经过目标检测等一些列算法对视频进行分析,最后在本地客户端查看分析结果.项目主要用Python实现,流媒体服务器采用开源的SRS实时视频服务器搭建,GPU服务器使用YOLO模型实现道路目标如人、车、交通灯等物体的识别,同时还支持并发连接.客户端基于PyQt5进行开发.
1、项目介绍
项目背景:智能交通监控系统采用识别技术进行分析,有异常状况发生(比如,当有行人闯红灯时、路口车辆和行人流量过大,导致堵塞交通时)就会自动通知交通管理人员.
基于以上背景,我简要介绍一下本项目的设计架构.
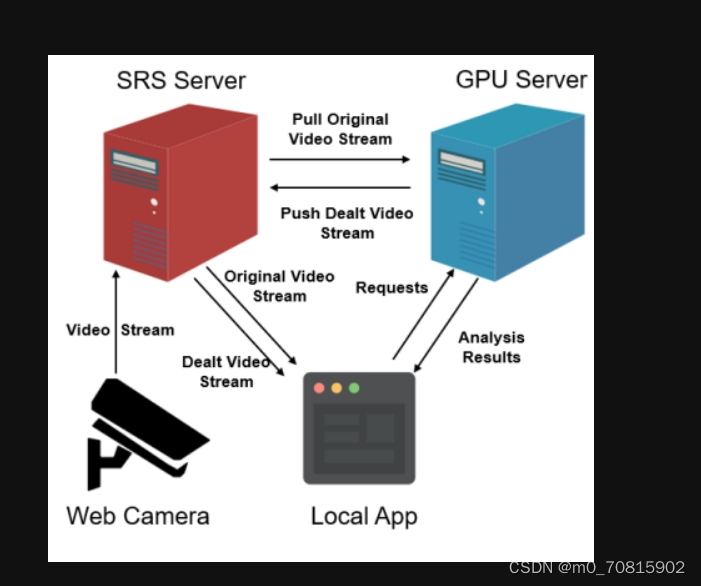
项目主要由三个模块组成,分别是:SRS流媒体服务器,云端GPU服务器,本地客户端.
首先,网络摄像机将交通路口的监控视频实时上传到SRS流媒体服务器。
然后,当SRS流媒体服务器有视频流输入时,云端GPU服务器拉取原始视频流,然后通过YOLO等目标检测算法对视频进行分析和处理,然后将处理后的视频推流到SRS服务器。
对于本地客户端,一方面可以直接从流媒体服务器拉流,查看远端网络摄像机的实时监控画面。另一方面,本地客户端也可以选择和远端的服务器通过进行通信(基于选择器 I/O复用库,支持并发连接),获取服务器对监控视频的分析结果,比如路口的车流量、人流量等。同时,当选择与GPU服务器连接时,本地客户端也将更换流地址,拉取处理后的视频流.Socketrtmp
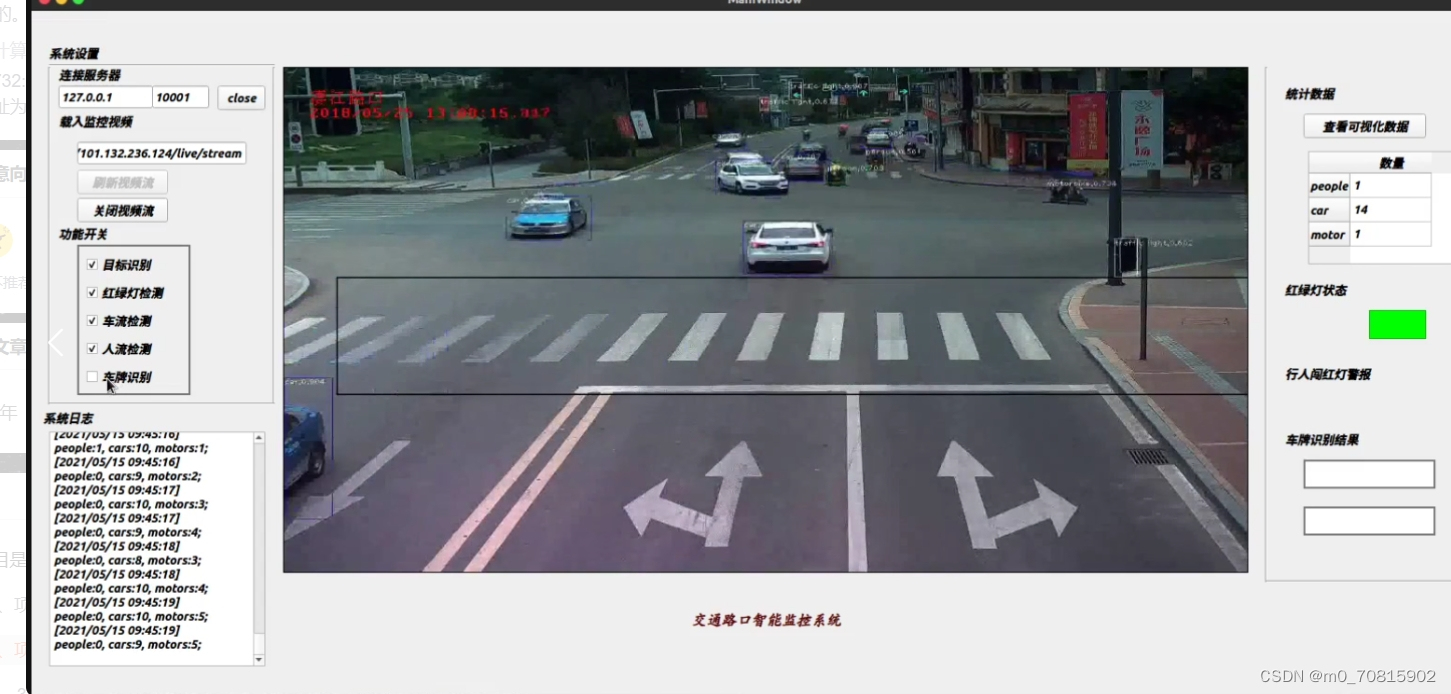
2、项目演示
3.安装环境依赖
进入目录内
cd Intelligent-Traffic-Based-On-CV
创建python虚拟环境
python3 -m venv .
激活虚拟环境
source bin/activate
安装python依赖包
pip install -r requirements.txt
4、部分代码结构说明
-
scripts_2 : python脚本
- server_selector.py : 服务端脚本
-
# -*- coding:utf-8 -*- # ffmpeg -re -stream_loop -1 -i traffic.flv -c copy -f flv rtmp://101.132.236.124/live/livestream # rtmp://101.132.236.124/live/stream import selectors import socket import pickle import json import sys import threading import multiprocessing import subprocess as sp import time import torch from video_demo import target_detect, target_detect_2, traffic_light_detect, classNum_detect from darknet import Darknet from plateRecognition import recognize_plate, drawRectBox from detect import detect_car_color import cv2 class ServerAchieve: def __init__(self): self.mysel = selectors.DefaultSelector() self.keep_running = True self.result_queue = multiprocessing.Queue(maxsize=10) self.server_tcp_thread = threading.Thread(target=self.connectClient, daemon=True) self.server_tcp_thread.start() self.cap = cv2.VideoCapture("rtmp://101.132.236.124/live/livestream") print("cap init is completed") # self.recognize_thread = threading.Thread(target=self.tt1, daemon=True) # self.recognize_thread.start() # multiprocessing.set_start_method(method='spawn') # init # 视频读取多进程队列 self.video_queue = multiprocessing.Queue(maxsize=10) #self.function_queue = multiprocessing.Queue(maxsize=2) self.deal_data_queue = multiprocessing.Queue(maxsize=10) video_process = [multiprocessing.Process(target=self.readVideo), multiprocessing.Process(target=self.dealVideo,), multiprocessing.Process(target=self.dealData,)] #multiprocessing.Process(target=self.plateDeal)] for process in video_process: process.daemon = True process.start() for process in video_process: process.join() def plateDeal(self): while True: # print("plate_recognize\n") frame = self.video_queue.get() # 车牌识别 # data_dict['plate_info_list'] = recognize_plate(data_dict['frame']) r_p = recognize_plate(frame) if (len(r_p)): print("have plate") print(r_p[0]) def readVideo(self): while True: while(self.cap.isOpened()): if True:#self.function_queue.get()['target_detect_is_open']: ret, frame = self.cap.read() if not ret: print("Opening camera is failed") break self.video_queue.put(frame) if self.video_queue.qsize() > 4: self.video_queue.get() else: # 让另一个进程读取图片 time.sleep(0.01) def dealData(self): # 闯红灯行人数, # 红绿灯 # 行人数 车辆数 摩托数 # result_dict = {'pedestrians_num':'', 'traffic_light_color':'', 'people_num':0, 'cars_num':0, 'motors_num':0, 'plate_info_list':[], 'data_h':True} i = 0 while True: data_dict = self.deal_data_queue.get() # print("get deal data") traffic_light_color = traffic_light_detect(data_dict['output'], data_dict['frame']) result_dict['plate_info_list'] = data_dict['plate_info_list'] # result_dict['plate_info_list'] = recognize_plate(data_dict['frame']) people_num, cars_num, motors_num = classNum_detect(data_dict['output']) result_dict['pedestrians_num'] = data_dict['pedestrians_num'] result_dict['traffic_light_color'] = traffic_light_color result_dict['people_num'] = people_num result_dict['cars_num'] = cars_num result_dict['motors_num'] = motors_num self.result_queue.put(result_dict) if self.result_queue.qsize() > 3: self.result_queue.get() else: time.sleep(0.01) pass def dealVideo(self): # 只有客户端选择check box时,才可以进行推流.(在进入这个函数之前) rtmpUrl = "rtmp://101.132.236.124/live/stream" # Get video information fps = int(self.cap.get(cv2.CAP_PROP_FPS)) width = int(self.cap.get(cv2.CAP_PROP_FRAME_WIDTH)) height = int(self.cap.get(cv2.CAP_PROP_FRAME_HEIGHT)) # ffmpeg command command = ['ffmpeg', '-y', '-f', 'rawvideo', '-vcodec','rawvideo', '-pix_fmt', 'bgr24', '-r', '7', '-s', "{}x{}".format(width, height), # '-r', str(fps), '-i', '-', '-pix_fmt', 'yuv420p', '-f', 'flv', rtmpUrl] print("deal Video process!") # 管道配置 p = sp.Popen(command, stdin=sp.PIPE) # while not self.function_queue.get()['target_detect_is_open']: # time.sleep(1) # 加载模型 CUDA = torch.cuda.is_available() print("Loading network.....") model = Darknet("../yolov3/cfg/yolov3.cfg") #self.model = Darknet("../yolov3/cfg/yolov2-tiny.cfg") model.load_weights("../yolov3/weights/yolov3.weights") #self.model.load_weights("../yolov3/weights/yolov2-tiny.weights") print("Network successfully loaded") model.net_info["height"] = 416 inp_dim = int(model.net_info["height"]) assert inp_dim % 32 == 0 assert inp_dim > 32 if CUDA: model.cuda() # 将模型迁移到GPU model.eval() data_dict = {'frame':None, 'output':None, 'pedestrians_num':None, 'plate_info_list':[]} i = 0 while True: frame = self.video_queue.get() data_dict['frame'] = frame.copy() data_dict['plate_info_list'] = [] # 车牌识别 # if(i == 30): # # data_dict['plate_info_list'] = recognize_plate(data_dict['frame']) # if (len(recognize_plate(data_dict['frame']))): # print("have plate") # print(recognize_plate[0]) # i = 0 # i += 1 output, orign_img, frame, pedestrians_num = target_detect(model, frame) data_dict['output'] = output data_dict['pedestrians_num'] = pedestrians_num self.deal_data_queue.put(data_dict) p.stdin.write(frame.tostring()) # traffic_light_color = traffic_light_detect(output, orign_img) # people_num, cars_num, motors_num = classNum_detect(output) # plate_info_list = recognize_plate(orign_img) # result_dict['pedestrians_num'] = pedestrians_num # result_dict['traffic_light_color'] = traffic_light_color # result_dict['people_num'] = people_num # result_dict['cars_num'] = cars_num # result_dict['motors_num'] = motors_num # # result_dict['plate_info_list'] = plate_info_list #self.result_queue.put(result_dict, block=False) #self.result_queue.get() def socketRead(self, connection, mask): empty_dict = {'empty':'empty'} result_dict = {'pedestrians_num':'', 'traffic_light_color':'', 'people_num':0, 'cars_num':0, 'motors_num':0, 'plate_info_list':'', 'data_h':False} client_address = connection.getpeername() client_data = connection.recv(1024) if client_data: # 可读的客户端 socket 有数据 if client_data.decode() != "exit": if self.result_queue.empty(): # print("waiting send...111") result_json = json.dumps(result_dict) connection.sendall(result_json.encode()) # 回馈信息给客户端 else: # print("waiting send...222") callback_json = json.dumps(self.result_queue.get()) connection.sendall(callback_json.encode()) # 回馈信息给客户端 print("read ......") else: print('closing.....') self.mysel.unregister(connection) connection.close() # print('read({})'.format(client_address)) else: # 如果没有数据,释放连接 print('closing.....') print('closing.....') print('closing.....') print('closing.....') print('closing.....') print('closing.....') print('closing.....') print('closing.....') print('closing.....') print('closing.....') print('closing.....') self.mysel.unregister(connection) connection.close() # 告诉主进程停止 # self.keep_running = False def socketAccept(self, sock, mask): # "有新连接的回调" new_connection, addr = sock.accept() print('accept({})'.format(addr)) new_connection.setblocking(False) self.mysel.register(new_connection, selectors.EVENT_READ, self.socketRead) def connectClient(self): server_address = ('127.0.0.1', 10001) print('starting up on {} port {}'.format(*server_address)) server = socket.socket(socket.AF_INET, socket.SOCK_STREAM) server.setsockopt(socket.SOL_SOCKET,socket.SO_REUSEADDR,1) server.setblocking(False) server.bind(server_address) server.listen(5) self.mysel.register(server, selectors.EVENT_READ, self.socketAccept) while True: print('waiting for I/O') for key, mask in self.mysel.select(timeout=1): callback = key.data callback(key.fileobj, mask) def show_frame(self): pass # cv2.imshow('frame', self.frame) # cv2.waitKey(self.FPS_MS) if __name__ == '__main__': sa = ServerAchieve() while True: try: # sa.show_frame() pass except AttributeError: pass - client_selector.py main_window.py sub_window.py : 客户端PyQt5界面
- bbox.py darknet.py video_demo.py util.py : YOLO相关代码
-
from __future__ import division import torch import random import numpy as np #import cv2 def confidence_filter(result, confidence): conf_mask = (result[:,:,4] > confidence).float().unsqueeze(2) result = result*conf_mask return result def confidence_filter_cls(result, confidence): max_scores = torch.max(result[:,:,5:25], 2)[0] res = torch.cat((result, max_scores),2) print(res.shape) cond_1 = (res[:,:,4] > confidence).float() cond_2 = (res[:,:,25] > 0.995).float() conf = cond_1 + cond_2 conf = torch.clamp(conf, 0.0, 1.0) conf = conf.unsqueeze(2) result = result*conf return result def get_abs_coord(box): box[2], box[3] = abs(box[2]), abs(box[3]) x1 = (box[0] - box[2]/2) - 1 y1 = (box[1] - box[3]/2) - 1 x2 = (box[0] + box[2]/2) - 1 y2 = (box[1] + box[3]/2) - 1 return x1, y1, x2, y2 def sanity_fix(box): if (box[0] > box[2]): box[0], box[2] = box[2], box[0] if (box[1] > box[3]): box[1], box[3] = box[3], box[1] return box def bbox_iou(box1, box2): """ Returns the IoU of two bounding boxes """ #Get the coordinates of bounding boxes b1_x1, b1_y1, b1_x2, b1_y2 = box1[:,0], box1[:,1], box1[:,2], box1[:,3] b2_x1, b2_y1, b2_x2, b2_y2 = box2[:,0], box2[:,1], box2[:,2], box2[:,3] #get the corrdinates of the intersection rectangle inter_rect_x1 = torch.max(b1_x1, b2_x1) inter_rect_y1 = torch.max(b1_y1, b2_y1) inter_rect_x2 = torch.min(b1_x2, b2_x2) inter_rect_y2 = torch.min(b1_y2, b2_y2) #Intersection area if torch.cuda.is_available(): inter_area = torch.max(inter_rect_x2 - inter_rect_x1 + 1,torch.zeros(inter_rect_x2.shape).cuda())*torch.max(inter_rect_y2 - inter_rect_y1 + 1, torch.zeros(inter_rect_x2.shape).cuda()) else: inter_area = torch.max(inter_rect_x2 - inter_rect_x1 + 1,torch.zeros(inter_rect_x2.shape))*torch.max(inter_rect_y2 - inter_rect_y1 + 1, torch.zeros(inter_rect_x2.shape)) #Union Area b1_area = (b1_x2 - b1_x1 + 1)*(b1_y2 - b1_y1 + 1) b2_area = (b2_x2 - b2_x1 + 1)*(b2_y2 - b2_y1 + 1) iou = inter_area / (b1_area + b2_area - inter_area) return iou def pred_corner_coord(prediction): #Get indices of non-zero confidence bboxes ind_nz = torch.nonzero(prediction[:,:,4]).transpose(0,1).contiguous() box = prediction[ind_nz[0], ind_nz[1]] box_a = box.new(box.shape) box_a[:,0] = (box[:,0] - box[:,2]/2) box_a[:,1] = (box[:,1] - box[:,3]/2) box_a[:,2] = (box[:,0] + box[:,2]/2) box_a[:,3] = (box[:,1] + box[:,3]/2) box[:,:4] = box_a[:,:4] prediction[ind_nz[0], ind_nz[1]] = box return prediction def write(x, batches, results, colors, classes): c1 = tuple(x[1:3].int()) c2 = tuple(x[3:5].int()) img = results[int(x[0])] cls = int(x[-1]) label = "{0}".format(classes[cls]) color = random.choice(colors) cv2.rectangle(img, c1, c2,color, 1) t_size = cv2.getTextSize(label, cv2.FONT_HERSHEY_PLAIN, 1 , 1)[0] c2 = c1[0] + t_size[0] + 3, c1[1] + t_size[1] + 4 cv2.rectangle(img, c1, c2,color, -1) cv2.putText(img, label, (c1[0], c1[1] + t_size[1] + 4), cv2.FONT_HERSHEY_PLAIN, 1, [225,255,255], 1); return img - detect.py : 颜色检测
- plateRecognition.py preprocess.py HyperLPRLite.py : 车牌检测相关代码
-
#coding=utf-8 import cv2 import numpy as np from keras import backend as K from keras.models import * from keras.layers import * import tensorflow as tf chars = [u"京", u"沪", u"津", u"渝", u"冀", u"晋", u"蒙", u"辽", u"吉", u"黑", u"苏", u"浙", u"皖", u"闽", u"赣", u"鲁", u"豫", u"鄂", u"湘", u"粤", u"桂", u"琼", u"川", u"贵", u"云", u"藏", u"陕", u"甘", u"青", u"宁", u"新", u"0", u"1", u"2", u"3", u"4", u"5", u"6", u"7", u"8", u"9", u"A", u"B", u"C", u"D", u"E", u"F", u"G", u"H", u"J", u"K", u"L", u"M", u"N", u"P", u"Q", u"R", u"S", u"T", u"U", u"V", u"W", u"X", u"Y", u"Z",u"港",u"学",u"使",u"警",u"澳",u"挂",u"军",u"北",u"南",u"广",u"沈",u"兰",u"成",u"济",u"海",u"民",u"航",u"空" ] class LPR(): def __init__(self,model_detection,model_finemapping,model_seq_rec): self.watch_cascade = cv2.CascadeClassifier(model_detection) self.modelFineMapping = self.model_finemapping() self.modelFineMapping.load_weights(model_finemapping) self.modelSeqRec = self.model_seq_rec(model_seq_rec) self.graph = tf.get_default_graph() def computeSafeRegion(self,shape,bounding_rect): top = bounding_rect[1] # y bottom = bounding_rect[1] + bounding_rect[3] # y + h left = bounding_rect[0] # x right = bounding_rect[0] + bounding_rect[2] # x + w min_top = 0 max_bottom = shape[0] min_left = 0 max_right = shape[1] if top < min_top: top = min_top if left < min_left: left = min_left if bottom > max_bottom: bottom = max_bottom if right > max_right: right = max_right return [left,top,right-left,bottom-top] def cropImage(self,image,rect): x, y, w, h = self.computeSafeRegion(image.shape,rect) return image[y:y+h,x:x+w] def detectPlateRough(self,image_gray,resize_h = 720,en_scale =1.08 ,top_bottom_padding_rate = 0.05): if top_bottom_padding_rate>0.2: print ("error:top_bottom_padding_rate > 0.2:",top_bottom_padding_rate) exit(1) height = image_gray.shape[0] padding = int(height*top_bottom_padding_rate) scale = image_gray.shape[1]/float(image_gray.shape[0]) image = cv2.resize(image_gray, (int(scale*resize_h), resize_h)) image_color_cropped = image[padding:resize_h-padding,0:image_gray.shape[1]] image_gray = cv2.cvtColor(image_color_cropped,cv2.COLOR_RGB2GRAY) watches = self.watch_cascade.detectMultiScale(image_gray, en_scale, 2, minSize=(36, 9),maxSize=(36*40, 9*40)) cropped_images = [] for (x, y, w, h) in watches: x -= w * 0.14 w += w * 0.28 y -= h * 0.15 h += h * 0.3 cropped = self.cropImage(image_color_cropped, (int(x), int(y), int(w), int(h))) cropped_images.append([cropped,[x, y+padding, w, h]]) return cropped_images def fastdecode(self,y_pred): results = "" confidence = 0.0 table_pred = y_pred.reshape(-1, len(chars)+1) res = table_pred.argmax(axis=1) for i,one in enumerate(res): if one<len(chars) and (i==0 or (one!=res[i-1])): results+= chars[one] confidence+=table_pred[i][one] confidence/= len(results) return results,confidence def model_seq_rec(self,model_path): width, height, n_len, n_class = 164, 48, 7, len(chars)+ 1 rnn_size = 256 input_tensor = Input((164, 48, 3)) x = input_tensor base_conv = 32 for i in range(3): x = Conv2D(base_conv * (2 ** (i)), (3, 3))(x) x = BatchNormalization()(x) x = Activation('relu')(x) x = MaxPooling2D(pool_size=(2, 2))(x) conv_shape = x.get_shape() x = Reshape(target_shape=(int(conv_shape[1]), int(conv_shape[2] * conv_shape[3])))(x) x = Dense(32)(x) x = BatchNormalization()(x) x = Activation('relu')(x) gru_1 = GRU(rnn_size, return_sequences=True, kernel_initializer='he_normal', name='gru1')(x) gru_1b = GRU(rnn_size, return_sequences=True, go_backwards=True, kernel_initializer='he_normal', name='gru1_b')(x) gru1_merged = add([gru_1, gru_1b]) gru_2 = GRU(rnn_size, return_sequences=True, kernel_initializer='he_normal', name='gru2')(gru1_merged) gru_2b = GRU(rnn_size, return_sequences=True, go_backwards=True, kernel_initializer='he_normal', name='gru2_b')(gru1_merged) x = concatenate([gru_2, gru_2b]) x = Dropout(0.25)(x) x = Dense(n_class, kernel_initializer='he_normal', activation='softmax')(x) base_model = Model(inputs=input_tensor, outputs=x) base_model.load_weights(model_path) return base_model def model_finemapping(self): input = Input(shape=[16, 66, 3]) # change this shape to [None,None,3] to enable arbitraty shape input x = Conv2D(10, (3, 3), strides=1, padding='valid', name='conv1')(input) x = Activation("relu", name='relu1')(x) x = MaxPool2D(pool_size=2)(x) x = Conv2D(16, (3, 3), strides=1, padding='valid', name='conv2')(x) x = Activation("relu", name='relu2')(x) x = Conv2D(32, (3, 3), strides=1, padding='valid', name='conv3')(x) x = Activation("relu", name='relu3')(x) x = Flatten()(x) output = Dense(2,name = "dense")(x) output = Activation("relu", name='relu4')(output) model = Model([input], [output]) return model def finemappingVertical(self,image,rect): resized = cv2.resize(image,(66,16)) resized = resized.astype(np.float)/255 res_raw= self.modelFineMapping.predict(np.array([resized]))[0] res =res_raw*image.shape[1] res = res.astype(np.int) H,T = res H-=3 if H<0: H=0 T+=2; if T>= image.shape[1]-1: T= image.shape[1]-1 rect[2] -= rect[2]*(1-res_raw[1] + res_raw[0]) rect[0]+=res[0] image = image[:,H:T+2] image = cv2.resize(image, (int(136), int(36))) return image,rect def recognizeOne(self,src): x_tempx = src x_temp = cv2.resize(x_tempx,( 164,48)) x_temp = x_temp.transpose(1, 0, 2) y_pred = self.modelSeqRec.predict(np.array([x_temp])) y_pred = y_pred[:,2:,:] return self.fastdecode(y_pred) def SimpleRecognizePlateByE2E(self,image): images = self.detectPlateRough(image,image.shape[0],top_bottom_padding_rate=0.1) res_set = [] for j,plate in enumerate(images): plate, rect =plate image_rgb,rect_refine = self.finemappingVertical(plate,rect) res,confidence = self.recognizeOne(image_rgb) res_set.append([res,confidence,rect_refine]) K.clear_session() return res_set















 98
98











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









