







一、K近邻(KNN)算法基础概念
1.1 什么是K近邻算法?
K近邻(K-Nearest Neighbors, KNN)是一种简单而强大的机器学习分类算法,属于监督学习类型。它的核心思想是:
"物以类聚,人以群分" - 相似的对象更可能属于同一类别
1.2 算法工作原理
- 计算距离:对于一个新数据点,计算它与训练集中所有点的距离
- 找邻居:找到距离最近的K个邻居(K值由用户指定)
- 投票决策:根据K个邻居的类别投票,确定新数据点的类别

1.3 KNN特点
| 优点 | 缺点 |
|---|---|
| 简单直观,易于理解 | 计算量大,对大数据集效率低 |
| 无需训练(惰性学习) | 对特征的尺度敏感 |
| 可以处理多分类问题 | K值选择敏感 |
二、Scikit-Learn中的KNeighborsClassifier详解
2.1 关键代码字段
导入模块
from sklearn.neighbors import KNeighborsClassifier- 从Scikit-Learn的
neighbors模块导入K近邻分类器类
创建模型实例
knc = KNeighborsClassifier(n_neighbors=k)knc:模型对象变量名n_neighbors=k:指定K值,即邻居的数量(最重要参数)
训练模型(拟合)
knc.fit(X, Y)X:训练数据的特征(n维数组或矩阵)Y:训练数据的标签(1维数组)
预测新数据
Y_predict = knc.predict(X_test)X_test:需要预测的数据Y_predict:预测结果(分类标签)
2.2 参数详解
除了n_neighbors外,KNeighborsClassifier还有几个重要参数:
| 参数名 | 作用 | 默认值 | 常用值 |
|---|---|---|---|
weights | 邻居的权重 | 'uniform' | 'distance'(距离反比权重) |
metric | 距离度量标准 | 'minkowski' | 'euclidean'(欧式距离),'manhattan'(曼哈顿距离) |
algorithm | 计算最近邻的算法 | 'auto' | 'kd_tree','ball_tree','brute' |
leaf_size | 树结构的叶子大小 | 30 | 10-100 |
p | 闵可夫斯基距离参数 | 2 | 1(曼哈顿),2(欧式) |
三、完整示例代码
3.1 基础示例(根据图片内容)
# 1. 导入所需库
from sklearn.neighbors import KNeighborsClassifier
import numpy as np
# 2. 准备训练数据
# 注意:实际数据应是二维数组,每行一个样本,每列一个特征
X = np.array([[1, 1], # 点A
[1, 2], # 点B
[2, 2], # 点C
[2, 3]]) # 点D
Y = np.array([0, # A的类别
0, # B的类别
1, # C的类别
1]) # D的类别
# 3. 创建KNN模型并设置参数
# 选择k=3,即寻找最近的3个邻居
knc = KNeighborsClassifier(n_neighbors=3)
# 4. 训练模型(拟合数据)
knc.fit(X, Y)
# 5. 准备测试数据
# 一个新点:坐标(1.5, 1.5)
X_test = np.array([[1.5, 1.5]])
# 6. 预测新点的类别
Y_predict = knc.predict(X_test)
# 7. 打印预测结果
print("预测分类结果:", Y_predict) # 输出:[0] 或 [1] 取决于具体距离计算3.2 可视化解析
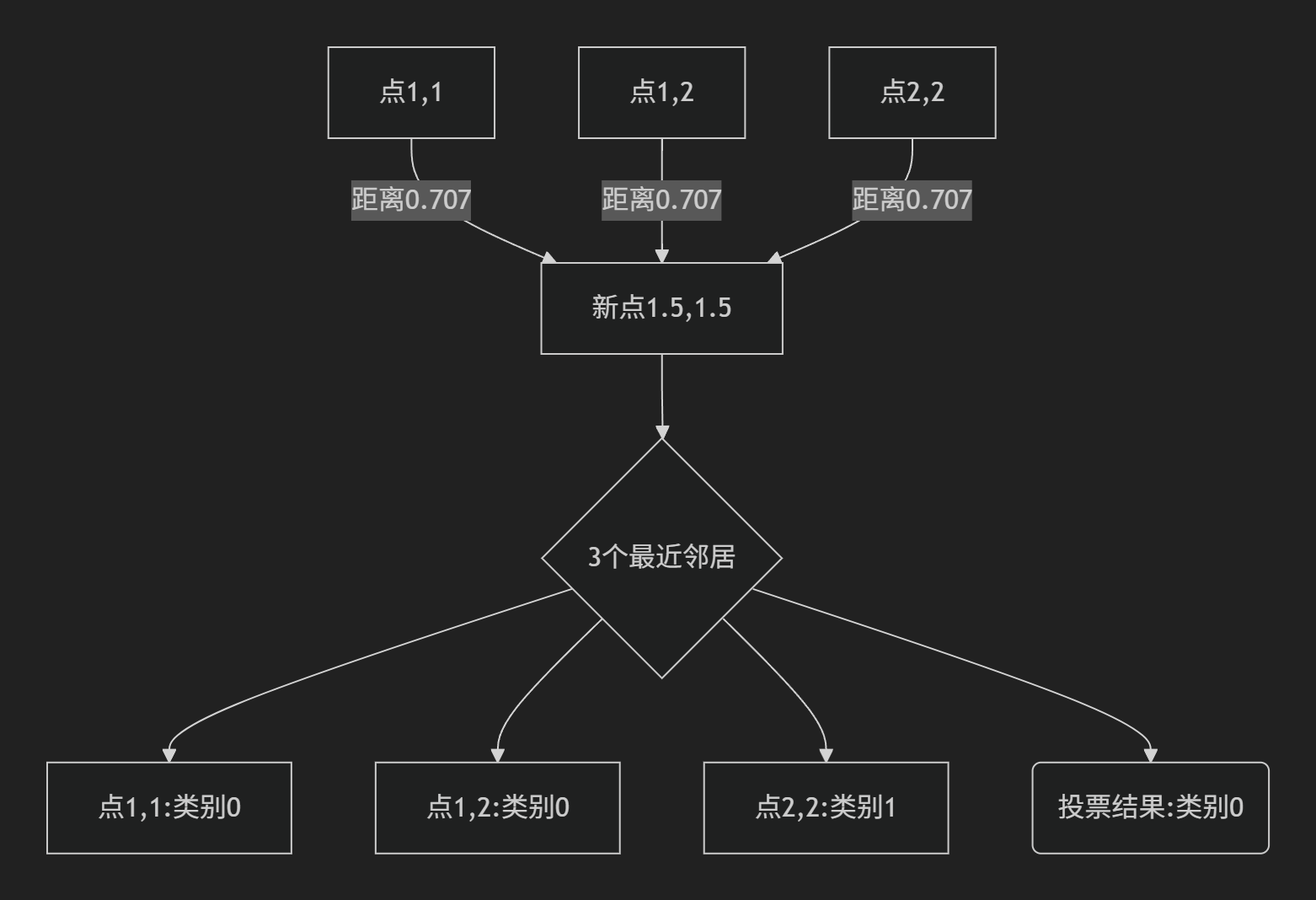
在这个例子中:
- 有三个点到新点
(1.5, 1.5)的距离都是0.707:(1,1):类别0(1,2):类别0(2,2):类别1
- 类别0有两票,类别1有一票 -> 新点被分为类别0
3.3 鸢尾花数据集实战
# 1. 导入所需库
from sklearn.neighbors import KNeighborsClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 2. 加载鸢尾花数据集
iris = load_iris()
X = iris.data # 特征(花瓣和花萼的尺寸)
y = iris.target # 目标(花的品种)
# 3. 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=42
)
# 4. 创建KNN分类器
knn = KNeighborsClassifier(n_neighbors=5) # 使用5个邻居
# 5. 训练模型
knn.fit(X_train, y_train)
# 6. 预测测试集
y_pred = knn.predict(X_test)
# 7. 评估模型准确率
accuracy = accuracy_score(y_test, y_pred)
print(f"模型准确率: {accuracy:.2%}")
# 8. 预测新样本
new_sample = [[5.1, 3.5, 1.4, 0.2]] # 新花样本的特征
prediction = knn.predict(new_sample)
print(f"预测类别: {iris.target_names[prediction][0]}") # 输出花品种名称四、K值选择与模型优化
4.1 如何选择合适的K值?
K值对模型性能影响巨大:
- K太小(如K=1):模型过于敏感,容易过拟合
- K太大(如K=N):模型过于平滑,失去细节
K值选择策略:
import matplotlib.pyplot as plt
from sklearn.model_selection import cross_val_score
# 测试不同K值的准确率
k_range = range(1, 31)
k_scores = []
for k in k_range:
knn = KNeighborsClassifier(n_neighbors=k)
scores = cross_val_score(knn, X, y, cv=10, scoring='accuracy')
k_scores.append(scores.mean())
# 绘制K值与准确率关系图
plt.figure(figsize=(12, 6))
plt.plot(k_range, k_scores)
plt.xlabel('K值')
plt.ylabel('交叉验证准确率')
plt.title('KNN分类器的K值选择')
plt.grid(True)
plt.show()4.2 特征缩放的重要性
KNN对特征的尺度很敏感,需要进行特征标准化:
from sklearn.preprocessing import StandardScaler
# 创建标准化器
scaler = StandardScaler()
# 在训练集上拟合并转换
X_train_scaled = scaler.fit_transform(X_train)
# 在测试集上转换(不重新拟合)
X_test_scaled = scaler.transform(X_test)
# 使用标准化后的数据训练KNN模型
knn.fit(X_train_scaled, y_train)
accuracy = knn.score(X_test_scaled, y_test)
print(f"标准化后准确率: {accuracy:.2%}")4.3 距离加权KNN
距离加权可以改善模型性能,给更近的邻居更高权重:
# 创建加权KNN模型
knn_weighted = KNeighborsClassifier(
n_neighbors=10, # 增加邻居数量
weights='distance' # 使用距离反比权重
)
knn_weighted.fit(X_train, y_train)
accuracy_weighted = knn_weighted.score(X_test, y_test)
print(f"加权KNN准确率: {accuracy_weighted:.2%}")五、KNN算法应用场景
KNN在实际中非常灵活,适用于多种场景:
-
推荐系统:
- 根据相似用户的喜好推荐商品
# 伪代码示例 similar_users = knn.kneighbors([current_user_features], n_neighbors=5) recommendations = similar_users_most_purchased_items() -
图像识别:
- 简单的图像分类(手写数字识别)
from sklearn.datasets import load_digits digits = load_digits() X, y = digits.data, digits.target # 使用KNN分类手写数字... -
异常检测:
- 识别偏离大多数模式的点
# 伪代码示例 distances = knn.kneighbors(X, return_distance=True) outliers = np.where(distances > threshold) -
医疗诊断:
- 基于相似病例的症状判断疾病类型
# 伪代码示例 new_patient_symptoms = [fever, cough, pain_level] disease_prediction = knn.predict([new_patient_symptoms])
六、总结与学习建议
KNN核心要点总结
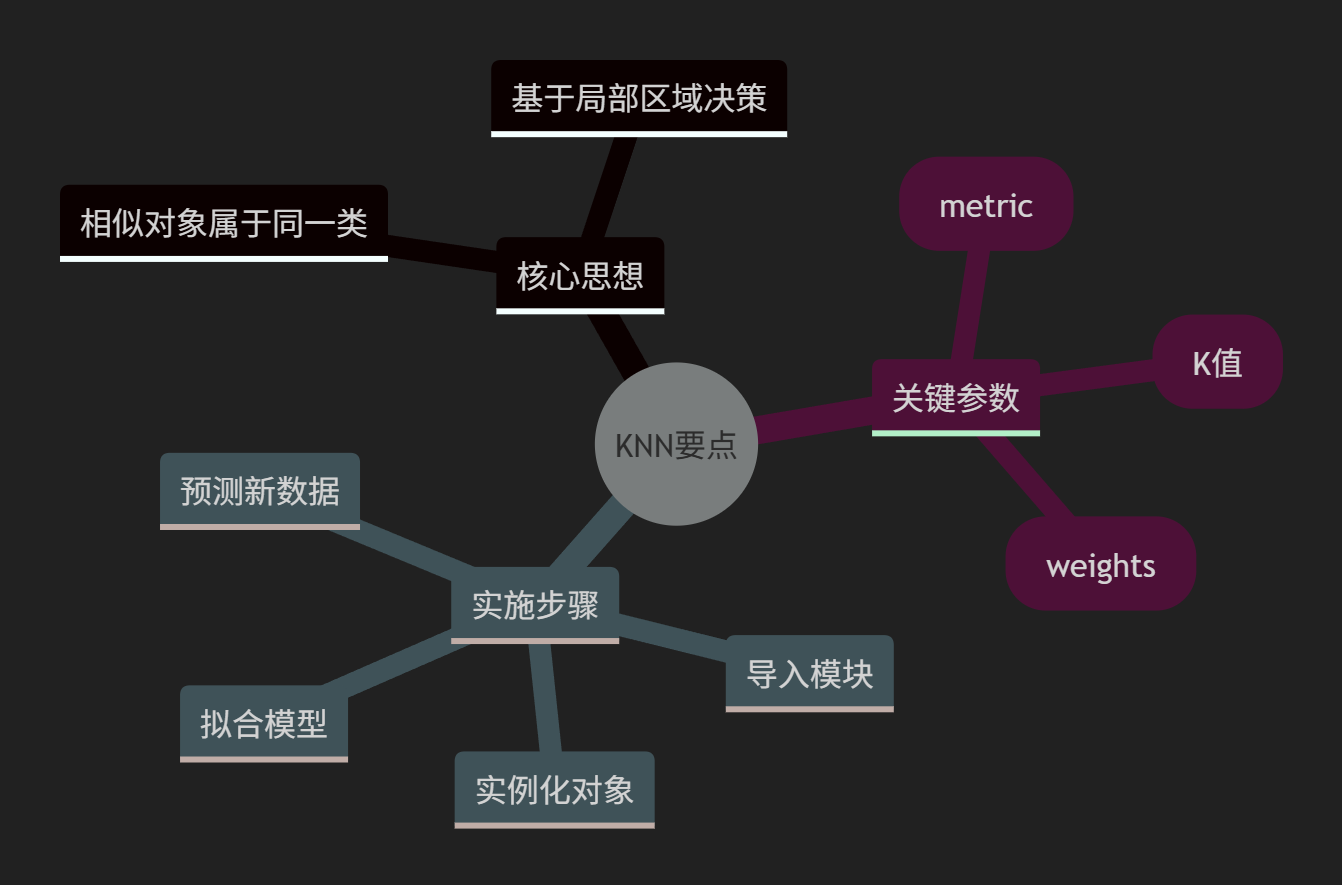
学习建议
-
动手实践:
- 在Jupyter Notebook中运行示例代码
- 尝试修改参数观察效果变化
-
可视化学习:
# 二维数据分类边界可视化 from mlxtend.plotting import plot_decision_regions plt.figure(figsize=(10, 6)) plot_decision_regions(X_train[:, :2], y_train, knn) plt.xlabel(iris.feature_names[0]) plt.ylabel(iris.feature_names[1]) plt.title('KNN分类边界') plt.show() -
探索进阶应用:
- 使用
kneighbors_graph构建邻居图 - 结合KNN和距离进行异常检测
- 在分布式环境下部署大规模KNN
- 使用


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









