







目录
数据结构的基本概念
数据对像:具有相同性质(特征)的数据的集合
数据元素:数据元素是数据的基本单位,通常作为一个整体进行考虑和处理
数据项:由若干数据项组成,数据项是构成数据元素的不可分割的最小单位(数据域,字段,列,属性)
数据类型:
1.原子类型:其值不可再分的数据类型,如int char float double
2.结构类型:其值可以再分解为若干成分的数据类型
数据结构的三要素

逻辑结构:组织数据的方法
(是我们想象出来的)
1.集合
2.线性结构
3.树形结构
4.网状结构
物理结构,存储结构:存储数据的方法
(内存中如何存储)
1.顺序存储:连续的存储空间
2.链式存储:存储单元可以是连续的,也可以不连续,一般需要一个指针存放后继结点的地址。
3.索引存储
4.散列存储
数据的运算:操作数据的方法
算法
算法的基本概念
算法是指解决方案的准确而完整的描述,是一系列解决问题的清晰指令。目的是为了更有效处理数据,提高数据运算效率。
算法的特征
有穷性,确定性,可行性,输入,输出
算法设计的要求
正确性,可读性,健壮性,高效率与低存储
算法效率的评估
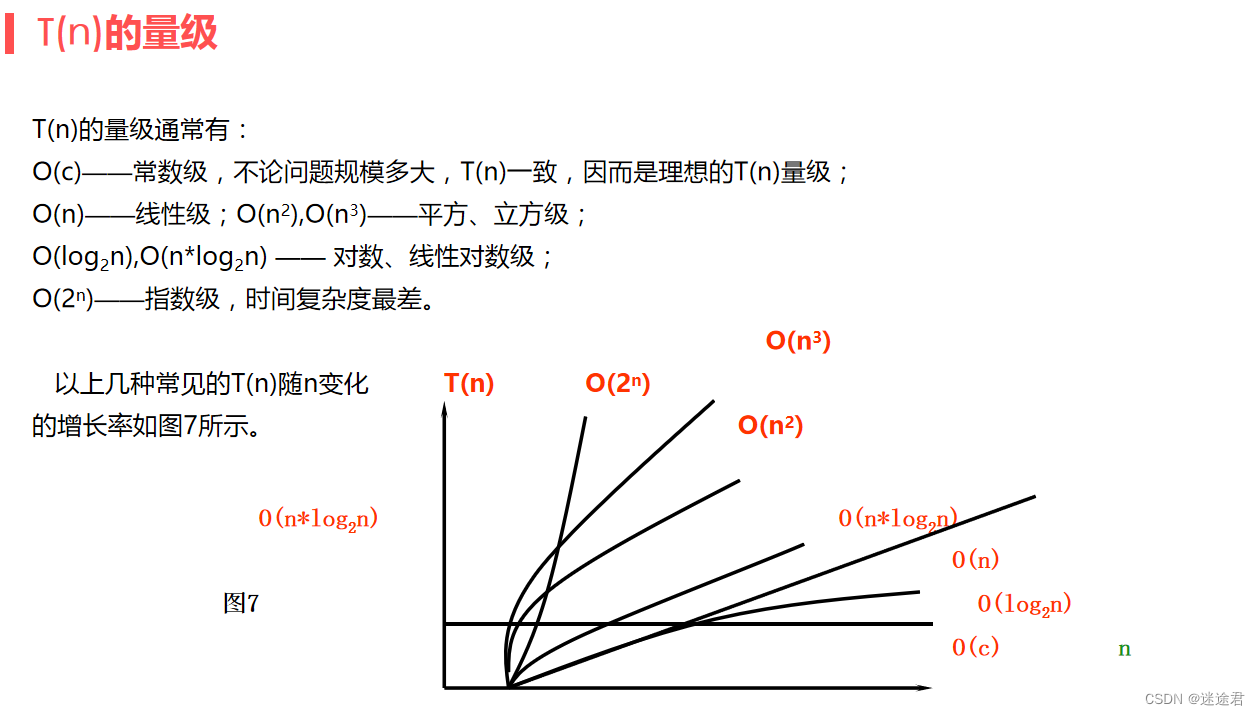
1.时间复杂度
运行一个算法时,程序代码被执行的总次数,程序代码的执行总次数一般与问题规模有关。
推导方法:
用常数1取代运行时间中的所有加法常数,再修改后的运行次数函数中,只保留最高阶项,如果最高阶项存在且不是1,则去掉与这个项目相乘的常数,得到的结果就是时间复杂度。
有一些常见函数的时间复杂度希望你能记住!!
冒泡排序的时间复杂度为O(n^2)
二分查找的时间复杂度为O(以2为底n的对数)
斐波那契递归的时间复杂度为O(2^n)
2.空间复杂度
空间复杂度是指算法消耗的内存空间,也是问题规模n的函数
递归函数的空间复杂度
递归函数嵌套的调用自己,函数的参数和局部变量占用的内存空间在递去的过程中会持续增长,在归来的时候才逐层释放。当递归的深度达到一定量级,可能会造成栈空间内存不足的情况。
线性结构
线性表
1.基本概念:最简单常用的数据结构,是具有相同特性 的n个数据元素(记录,节点)的有限序列。
2.表中的元素具有相同特性意味着相同的数据类型。不同特性的数据用不同的表
3.表中的元素是一个有限的集合,不能无限
4.序列可以理解为顺序,不能理解为有序或已排序
5.ai是表中的第i个元素,i时元素在表中的位序(从1到n)
6.a1是表头元素,an是表尾元素
7.除头结点外,每个结点有且仅有一个直接前驱,除尾结点外,每个结点有且仅有一个直接后继。
8.可用于区分不同元素的数据项称之为关键字(主键)
顺序表
(静态顺序表类似数组,大小设定后无法修改)
1.创建一个静态顺序表的基本步骤是怎么样的呢?下面我们用一个程序来实际说明一下!
首先我们需要构造一个顺序表类型,这里需要注意我用到了typedef来将结构体名和int重新取了别名,这样如果我们需要储存其他类型的数据例如double 我们可以直接在最上面进行修改,而不需要去下面一行一行修改。
#define SIZE 100//宏定义表的大小
typedef int data_t;//将int重命名为data_t,方便阅读使用
//构造顺序表类型
typedef struct list{
data_t data[SIZE];//表的存储空间
int last;//当前表尾元素指针
}seqlist;
随后我们写了一个创建顺序表的函数,注意因为我们要将顺序表的地址传回主函数方便操作,所以定义类型用了结构体指针类型。这里需要注意的是,由于使用malloc函数分配的内存地址里的内容是没有清空的,所以我们一般会使用memset函数进行清空,而且也要判断分配内存空间是否成功哦!!
seqlist* create_seqlist()
{
//给顺序表开辟空间
seqlist* head=(seqlist *)malloc(sizeof(seqlist));
//判断开辟空间是否成功
if(NULL==head)
return NULL;//不成功返回NULL
//将开辟的空间里的内容清空
memset(head->data,0,sizeof(head->data));
head->last=-1;//顺序表为空
return head;//返回顺序表首地址
}在创建了顺序表后我们还需要实现一些基本的功能,首先要判断顺序表是否为空,我们通过整型变量last的值来判断,在开始创建时我们将last赋值为-1,如果顺序表为空,则last不会发生改变,反之会改变!!(这里分享一个小技巧在判断语句中,可以将常量写在左边以免自己粗心少写了一个=,因为一个=是赋值符号,由于不能给常量赋值所以系统会报错,方便你改正!)
//判空
int seqlist_is_empty(seqlist *head)
{
if(NULL==head)//判断head是否传递成功
return -1;
return( (head->last == -1)?1:0);
}在实现判空之后我们当然也需要判断顺序表是否满了,因为我们在进行增加数据的时候如果顺序表已经满了就无法再添加数据了,last加1就为表的长度,如果等于我们开始给顺序表定义的长度,那么说明顺序表已经满了!!
//判满
int seqlist_is_full(seqlist *head)
{
if(NULL == head)
return -1;
return ((head->last+1 == SIZE)?1:0);
}求表长度也很简单吧!就是last+1
//求表长
int get_length_seqlist(seqlist *head)
{
if(NULL==head)
return -1;
return(head->last+1);
}接下来我们要插入一个数据该怎么操作呢?首先利用判满函数判断是否已经满了,如果没有满,将要插入的位置传到我们编写的插入函数中,从后往前依次将数据后移,最后将那个数据插入到需要的那个位置即可!
//按位置下标插入数据
int insert_seqlist_by_pos(seqlist *head,int pos,data_t vlu)
{
if(NULL==head)
return -1;
//判满
if(1==(seqlist_is_full(head)))
return -2;
//判断位置合法性
int len=get_length_seqlist(head);
if(pos < 0 || pos > len)
return -3;
//给插入的数据移位置
int i;
for(i=head->last;i>=pos;i--)
{
head->data[i+1]=head->data[i];
}
//插入数据
head->data[pos]=vlu;
head->last++;
return 0;
}那么如何根据下标来删除对应的数据呢,只需要将该位置后面的数据依次往前覆盖就行了。
//按下标位置删除数据
int delete_seqlist_by_pos(seqlist *head,int pos)
{
//判断head
if(NULL==head) return -1;
//判断表是否为空
if(1==(seqlist_is_empty(head)))
return -2;
//判断位置合法性
int len=get_length_seqlist(head);
if(pos< 0 || pos> (head->last))
return -3;
int i;
//从目标位置开始后一位依次往前覆盖
for(i=pos;i<head->last;i++)
{
head->data[i]=head->data[i+1];
}
head->last--;
return 0;
}然后,我们再来实现一个打印顺序表的功能函数吧,很简单用for循环遍历顺序表就ok拉。
//打印表
int showList(seqlist *head)
{
if(NULL==head)
return -3;
int i=0;
if(1==seqlist_is_empty(head))
{
printf("seqlist is empty\n");
return 0;
}
int len=get_length_seqlist(head);
for(i=0;i<len;i++)
{
printf("%d ",head->data[i]);
}
printf("\n");
return 0;
}接下来我们写一段通过位置来查找数据的代码
//按位置查找数据
data_t find_seqlist_by_pos(seqlist *head,int pos)
{
if(NULL==head) return -1;
//判空
if(1==seqlist_is_empty(head))
return -1;
int len=get_length_seqlist(head);
//判断位置合法性
if(pos<0 || pos>len-1)
return -1;
return head->data[pos];
}通过值来查找也很简单就可以实现
//按值查找数据
int find_seqlist_by_data(seqlist *head,int val)
{
//判空
if(1==seqlist_is_empty(head))
return -1;
int i=0;
//利用循环判断,返回下标
for(i=0;i<=head->last;i++)
{
if(val==head->data[i])
return i;
}
return -1;
}按值来删除数据,很简单通过之前查找函数我们找到该值的下标,然后通过删除函数进行删除就可以了。
//按值删除数据
int delete_seqlist_by_data(seqlist *head,int val)
{
if(1==seqlist_is_empty(head))
return -1;
int i=0;
int pos= find_seqlist_by_data(head,val);
delete_seqlist_by_pos(head, pos);
return 0;
}修改数据
//按位置修改
int change_seqlist_by_pos(seqlist *head,int pos,data_t nem_val)
{
if(NULL==head) return -1;
if(1==seqlist_is_empty(head))
return -1;
int len=get_length_seqlist(head);
if(pos<0 || pos>len-1)
return -1;
head->data[pos]=nem_val;
return 0;
}清空表
//清空表
int clear_seqlist(seqlist *head)
{
if(NULL==head) return -1;
head->last=-1;
return 0;
}销毁表
//销毁表
void destory_seqlist(seqlist **seq)
{
if(NULL==*seq)
return;
free(*seq);
*seq=NULL;
}进行排序
//冒泡排序(升序)
int sort_seqlist(seqlist *head)
{
if(1==seqlist_is_empty(head))
return -1;
int len=get_length_seqlist(head);
int i,j;
for(i=0;i<len-1;i++)
{
for(j=0;j<len-1-i;j++)
{
if(head->data[j]>head->data[j+1])
{
head->data[j]^=head->data[j+1];
head->data[j+1]^=head->data[j];
head->data[j]^=head->data[j+1];
}
}
}
return 0;
}上面我们对顺序表进行了增查改删排等等操作,对于顺序表的基本操作应该能掌握了把,如果没有思路,可以画图思考一下这些功能是如何实现的,对于一些问题我们也需要先在纸上进行画图思考算法,而不是拿起题就开始敲代码!!!理清思路之后再敲吧!!
思考一下,在我们对顺序表进行增删等操作时,是不是进行了大量的数据移位操作,这就是顺序表的不足之处:1.顺序表要求系统提供一片较大的连续存储地址。2.顺序表的大小无法修改。3.在进行数据处理时,会涉及到大批量数据移动操作。
所以我们之后会使用他的升级版链表来改进。















 1640
1640











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









