







目录
标准I/O
一.系统调用和用户程序编程接口
1.系统调用
操作系统负责管理和分配所有的计算机资源。为了更好的服务于应用程序,操作系统提供了一组特殊接口--系统调用,通过这组接口用户程序可以使用操作系统内核提供的各种功能,如分配内存,创建进程,实现进程之间的通讯等。(通过程序直接访问计算机资源是很不安全的!!)
2.用户程序编程接口
其实在实际的开发中我们是不直接使用系统调用接口的,而是使用API(用户程序编程接口)原因如下:
1.系统调用接口功能太过简单,无法满足程序需求
2.不同操作系统的系统调用接口不兼容,移植困难。
什么是用户程序编程接口呢,一般我们理解为各种库(C库等)中的函数,这些函数可以直接调用来实现一些功能,提高了代码复用率和可移植性
3.文件的分类
基本分为两类:二者在物理存储上没有区别(对于计算机来说都是二进制方式处理),逻辑上有差别(文件的编码方式不同)
1.文本文件(ASCII码文件):文件中的内容是用ASCII码或者字符来显示的
2.二进制文件:文件中存放的内容是二进制数据
Linux文件分类:
1.普通文件:-
2.目录文件:d
3.管道文件:p
4.套接字文件:s
5.链接文件:l
6.块设备文件:b
7.字符设备文件:c
二.标准I/O概述
1.标准I/O的由来
标准IO其实指的就是ANSI C中定义的用于I/O操作的一系列函数。
2.流的含义
标准IO的核心对象就是流。当用标准IO打开一个文件时,就会创建一个FILE结构体来描述该文件。
每一个应用程序会默认定义三个文件流指针:stdin,stdout,stderr.
stdin:标准输入流
stdout:标准输入流
stderr:标准错误输出流
man手册:
man 1:查看shell命令
man 2:查看系统调用
man 3:查看C标准库
3.标准IO的缓存类型
1.全缓存
文件的读写一般都会采用全缓存的形式,在这种情况下,当填满缓存区后才进行实际的IO操作。
刷新条件:1.使用fflush刷新。2.缓存区满。3.程序结束
2.行缓存
标准输入和标准输出采用的方式。
刷新条件:1.遇到\n
2.使用fflush刷新
3.程序结束。
4.缓存区满
3.无缓存
标准错误输出使用的方式。在对流的读写时会立刻操作实际的文件,使出错信息可以立刻显示在终端上。
三.标准IO编程
1.流的打开fopen
| 所需头文件 | #include <stdio.h> |
| 函数原型 | FILE* fopen(const char* path,const char* mode) |
| 函数参数 | path:包含要打开的文件路径及文件名 |
| mode:文件打开方式 | |
| 函数返回值 | 成功:返回文件流指针,该指针可以认为指向一个文件,可以利用它简介操作文件 |
| 失败:NULL |
mode取值表
| r或rb | 打开只读文件,不会创建新文件,默认从开头进行读取 |
| r+或r+b | 打开可读写文件,不会创建新文件,默认从开头进行读取 |
| w或wb | 打开只写文件,若文件存在则文件长度为0(清空),若文件不存在则建立该文件,从头写入 |
| w+或w+b | 打开可读写文件,若文件存在则文件长度为0(清空),若文件不存在则建立该文件,从头写入 |
| a或ab | 以附件的方式打开只写文件,若不存在则建立该文件,存在则将写入的数据加到文件尾,原来的文件内容会保留 |
| a+或a+b | 以附加的方式打开可读写的文件,若文件不存在,则会建立该文件,如果文件存在,写入的数据会被加到文件尾,即文件原先的内容会被保留。 |
注:在每个选项中加入b字符用来告诉函数库打开的文件为二进制文件,而非纯文本文件。在Linux系统下r和rb其实是没有什么去别的,但是在window平台下有区别!!例:window平台下换行符为\r\n,若用文本文件形式解读会被解释为一个换行符\n,如果按二进制文件来解读,则会正常读取两个字节
2.流的关闭fclose
| 所需头文件 | #include <stdio.h> |
| 函数原型 | int fclose(FILE *stream); |
| 函数参数 | stream:已打开的流指针 |
| 函数返回值 | 成功:0 |
| 失败:EOF |
3.错误处理perror和strerror
| 所需头文件 | #include <stdio.h> |
| 函数原型 | void perror(const char* s); |
| 函数参数 | s:在标准错误流上输出的信息 例:perror("fail to open"); |
| 函数返回值 | 无 |
| 所需头文件 | #include <string.h> #include <errno.h> |
| 函数原型 | char* strerror(int errnum) |
| 函数参数 | 错误码 |
| 函数返回值 | 错误码对应的错误信息 |
4.流的读写
(1)按字符(字节)输入(读)/输出(写)
读fgetc/getc
| 所需头文件 | #include <stdio.h> |
| 函数原型 | int fgetc(FILE* stream) int getc(FILE* stream) |
| 函数参数 | stream:要输入的文件流 |
| 函数返回值 | 成功:返回当前读取的字符 |
| 失败:EOF(或者到文件末尾) |
代码如下:
写 putc/fputc
| 所需头文件 | #include <stdio.h> |
| 函数原型 | int putc(int c,FILE* stream) int fputc(int c,FILE* stream) |
| 函数参数 | c:要输出的字符 stream:要输出的文件流可以为stdout |
| 函数返回值 | 成功:要输出的字符c 失败:EOF |
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include <strings.h>
int main()
{
//只读方式打开1.txt
FILE *fp = fopen("1.txt", "a");
if(fp == NULL)
{
printf("fopen failed\n");
return -1;
}
//向文件写入内容.
int ret = fputc('r', fp);
if(ret == EOF)
{
printf("fputc failed\n");
return -1;
}
printf("end of file-------\n");
return 0;
}(2)按行输入(读)/输出(写)
| 所需头文件 | #include <stdio.h> |
| 函数原型 | char* gets(char* s) char* fgets(char*s,int size,FILE* stream) |
| 函数参数 | s:存放输入字符串的缓冲区首地址 |
| size:输入的字符串长度 | |
| stream:对应的文件流指针 | |
| 函数返回值 | 成功:返回字符串首地址s |
| 失败或到达文件末尾:返回NULL |
代码例子如下:
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include <strings.h>
int main()
{
char str[32];
FILE *fp = fopen("1.txt", "r");
if(fp == NULL)
{
printf("fopen failed\n");
return -1;
}
//gets(str); //不做越界检查.
//fgets(str, 32, stdin);
if(NULL == fgets(str, sizeof(str), fp))
{
printf("fgets failed\n");
return -1;
}
printf("%s", str);
return 0;
}注意:
1.gets函数容易造成缓冲区溢出,不推荐使用!!!!
2.fgets是从指定的流中读取一行数据,当遇到\n时表示一行结束,或者读取size-1个字符后返回(如果size比文件中一行数据个数小时,会默认在后面加\0表示字符串结束)所以不能保证每次都能读出一行!!!
3.当size-1的值大于一行的个数时,遇到\n正常结束,并且读取的内容包含\n,两种清空都要以\0为结束标志。
| 所需头文件 | #include <stdio.h> |
| 函数原型 | int puts(const char* s) int fputs(const char* s,FILE* stream) |
| 函数参数 | s:存放输出字符串的缓冲区首地址 |
| stream:对应的文件流指针 | |
| 函数返回值 | 成功:返回s |
| 失败:返回NULL |
代码例子:
* #include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include <strings.h>
int main()
{
char str[32];
FILE *fp = fopen("1.txt", "w");
if(fp == NULL)
{
printf("fopen failed\n");
return -1;
}
if(EOF == fputs("hello", fp))
{
printf("fputs failed\n");
return -1;
}
return 0;
}
(3)以指定大小为单位读写文件
| 所需头文件 | #include <stdio.h> |
| 函数原型 | size_t fread(void* ptr,size_t size,size_t nmemb,FILE* stream) |
| 函数参数 | ptr:存放读入记录的缓冲区首地址,可以为任意指针类型 |
| size:读取的每个数据的字节大小 | |
| nmemb:读取的数据个数 | |
| stream:要读取的文件流 | |
| 函数返回值 | 成功:返回实际读取的nmemb数目 |
| 失败或文件末尾:0或者比nmemb小的数字 |
代码:
struct data
{
int num;
char ch;
char name[20];
};
int main()
{
char buf[64] = {"hello"};
struct data s = {12, '\0', "hjk"};
struct data s2;
FILE *fp = fopen("2.txt", "wb+");
if(fp == NULL)
{
printf("fopen failed\n");
return -1;
}
int ret = fwrite(&s, sizeof(s), 1, fp);
if(ret == 0)
{
printf("fwrite failed\n");
return -1;
}
fclose(fp);
fp = fopen("2.txt", "rb");
ret = fread(&s2, sizeof(s2), 1, fp);
if(ret == 0)
{
if(feof(fp) != 0)
{
printf("end of file\n");
}
else
{
printf("fread failed\n");
return -1;
}
}
printf("%d--%s--%c\n", s2.num, s2.name, s2.ch);
return 0;
}| 所需的头文件 | #include <stdio.h> |
| 函数原型 | size_t fwrite(const void*ptr,size_t size,size_t nmemb,FILE*stream) |
| 函数参数 | ptr:存放写入记录的缓冲区首地址 |
| size:写入的每个记录数据的大小 | |
| nmemb:写入的数据个数 | |
| stream:要写入的文件流 | |
| 函数返回值 | 成功:返回实际写入的nmemb数目 |
| 失败:返回:0或则比nmemb小的数目 |
注:
1.feof():判断是否到达文件末尾
if(feof(fp)!=0)
2.ferror():判断文件是否出错
if(ferror(fp)!=0)
(4)格式化输入/输出函数
| 所需头文件 | #include <stdio.h> |
| 函数原型 | int fscanf(FILE* fp,const char* format,.......) int sscanf(char* buf,const char* format,........) |
| 函数传入值 | format:输入格式 |
| fp:作为输入的流 | |
| buf:作为输入的缓冲区 | |
| 函数返回值 | 成功:输出字符数 |
| 失败:EOF |
| 所需头文件 | #include <stdio.h> |
| 函数原型 | int fprintf(FILE* fp,const char* format,.......) int sprintf(char* buf,const char* format,......) |
| 函数参值 | format:输出的格式 |
| fp:接收输出的流 | |
| buf:接收输出的缓存区 | |
| 函数返回值 | 成功:输出字符数(sprintf返回存入数组的字符数) |
| 失败:EOF |
代码:
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include <strings.h>
int main(int argc, char *argv[])
{
int tmp = 35;
int hum = 56;
int light = 1026;
char name[20] = "ioioio";
int num = 12;
char env[1024] = {0};
FILE *fp = fopen("1.txt", "a");
if(fp == NULL)
{
printf("failed\n");
return -1;
}
char info[1024] = {0};
sprintf(info, "name:%s,num:%d", name, num);
printf("%s\n", info);
sprintf(env, "tmp:%d hum:%d light:%d\n", tmp, hum, light);
//printf("%s", env);
if(EOF == fputs(env, fp))
{
printf("fputs failed\n");
return -1;
}
fclose(fp);
return 0;
}5.流的定位
| 所需头文件 | #include <stdio.h> |
| 函数原型 | int fseek(FILE* stream,long offset,int whence) |
| 函数参数 | stream:要定位的文件流 |
| offset:相对于基准值的偏移量 | |
| whence: SEEK_SET 代表文件起始位置 SEEK_END 代表文件结束位置 SEEK_CUR 代表文件当前读写位置 | |
| 函数返回值 | 成功;0 |
| 失败:EOF |
| 所需头文件 | #include <stdio.h> |
| 函数原型 | long ftell(FILE* stream) |
| 函数参数 | stream:要定位的文件流 |
| 函数返回值 | 成功:返回当前读写位置 |
| 失败:EOF |
案例:用定位操作判断一个文件大小
#include <stdio.h>
int main(int argc, char *argv[])
{
FILE* fp;
if(argc!=2)
{
printf("Usage:%s<filename1>",argv[0]);
return -1;
}
if((fp=fopen(argv[1],"r"))==NULL)
{
perror("fail open\n");
return -1;
}
fseek(fp,0,SEEK_END);//将文件定位到末尾
printf("The size of %s is %ld\n",argv[1],ftell(fp));
return 0;
} 案例:用读写操作复制一个文件
代码如下:
#include <stdio.h>
#include <string.h>
#define N 64
int main(int argc, char *argv[])
{
char arr[N]={0};
int n;
//文件从命令行进行输入
FILE *fp1=fopen(argv[1],"r");
FILE *fp2=fopen(argv[2],"w");
//命令行参数必须为三个
if(argc!=3)
{
printf("Usage:%s<filename1><filename2>",argv[1]);
return -1;
}
if(fp1==NULL)
{
printf("open fail\n");
return -1;
}
//打开文件失败
if(fp2==NULL)
{
printf("open fail\n");
fclose(fp1);//关闭文件
return -1;
}
//循环读写文件,直到文件末尾退出循环
while((n=fread(arr,sizeof(char),N,fp1))>0)
{
fwrite(arr,sizeof(char),n,fp2);//n为每次读取的字节个数,不能为数组大小以免没有读到那么多
//数据,那么就会在原文件后面添加一些数据。
}
fclose(fp1);
fclose(fp2);
return 0;
} 文件IO
Linux文件IO其实就是系统提供的接口我们又称为系统调用。那么它与标准IO相比有什么区别呢?
文件IO和标准IO的区别
标准IO属于c库函数
1、接口是由C标准(ANSI C标准)提供的,与语言以及程序有关
2、又被称为高级IO(所谓的高级就是带缓存的IO)!!!
3、一样可以用于所有普通文件的读写操作.
文件IO---> 系统调用
1、接口使用操作系统(POSIX标准)提供, 与操作系统有关
2、又被称为低级IO(不带缓存的IO)
3、Linux系统下有的特殊类型文件只能用文件IO来操作,例如: 管道、设备文件等
文件IO接口
1.文件打开和关闭
| 所需头文件 | #include <sys/stat.h> #include <fcntl.h> |
| 函数原型 | int open(const char* pathname,int flags,int perms); |
| 函数参数 | pathname:被打开的文件名 |
| O_RDONLY:以只读方式打开文件 | |
| O_WRONLY:以只写方式打开文件 | |
| O_RDWR:以读写方式打开文件 | |
| O_CREAT:如果该文件不存在,就创建一个新的文件,并用第三个参数为其设置权限 | |
| O_APPEND:以添加方式打开文件,在写文件时,文件读写位置自动只想文件的末尾,即将写入的数据添加到文件末尾。 | |
| O_TRUNC:若文件已经存在,那么就会删除文件中所有数据,并且设置文件大小为0 | |
| O_NOCTTY:使用本参数,若打开的是终端文件,那么该终端不会成为当前进程的控制终端。 | |
| perm:新建文件的存取权限用八进制表示,R/W/X分别表示读写执行权限 rw-rw-r--: 0664 | |
| 函数返回值 | 成功:返回文件描述符 |
| 失败:返回-1 | |
| 所需头文件 | #include <unistd.h> |
| 函数原型 | int close(int fd); |
| 函数输入值 | fd:文件描述符 |
| 函数返回值 | 0:成功 |
| -1:出错 |
2.文件读写
| 所需头文件 | #include <unistd.h> |
| 函数原型 | ssize_t read(int fd,void* buf,size_t count) |
| 函数传入值 | fd:文件描述符 |
| buf:指定存储器读出数据的缓存区 | |
| count:指定读出的字节数 | |
| 函数返回值 | 成功:读到的字节数 |
| 0:已到达文件末尾 | |
| -1:出错 |
| 所需头文件 | #include <unistd.h> |
| 函数原型 | ssize_t write(int fd,void* buf,size_t count) |
| 函数传入值 | fd:文件描述符 |
| buf:指定存储器写入数据的缓冲区 | |
| count:指定读书的字节数 | |
| 函数返回值 | 成功:已写的字节数 |
| -1:出错 |
3.文件定位
| 所需头文件 | #include <unistd.h> #include <sys/types.h> |
| 函数原型 | off_t lseek(int fd,off_t offset,int whence) |
| 函数传入值 | fd:文件描述符 |
| offset:相对于基准点whence的偏移量,以字节为单位,正数向前移,负数向后移 | |
| whence: | |
| SEEK_SET:文件起始位置 | |
| SEEK_CUR:文件当前读写位置 | |
| SEEK_END:文件的结束位置 | |
| 函数返回值 | 成功:文件当前读写位置 -1:出错 |
案例:给bmp格式图片打码:
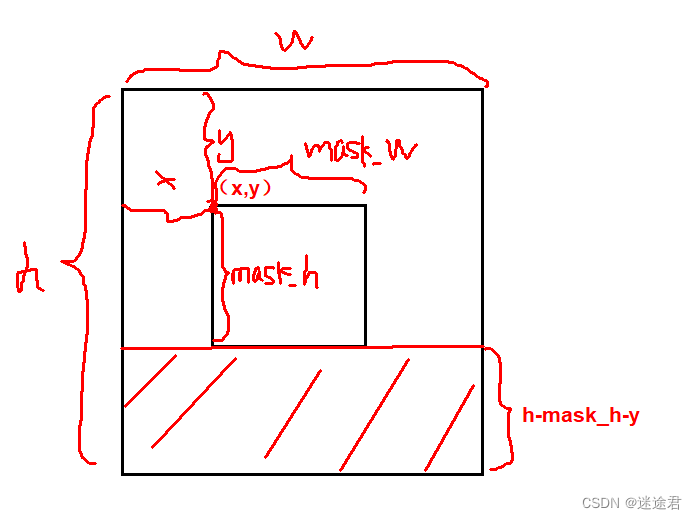
代码如下:
#include <stdio.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <sys/types.h>
#include <stdlib.h>
#include <string.h>
//三原色结构体类型定义
typedef struct color
{
unsigned char B;//蓝
unsigned char G;//绿
unsigned char R;//红
}COLOR;
int main(int argc, char *argv[])
{
//打开目标文件,命令行传参
int src=open(argv[1],O_RDWR);
int n;
//命令行参数个数必须为8个
if(argc!=8)
{
//提示参数输入格式
printf("Usage:%s<file1><file2><x><y><w><h><len>",argv[0]);
return -1;
}
//打开文件失败
if(-1==src)
{
perror(argv[1]);
return -1;
}
//创建文件并打开
int dst=open(argv[2],O_RDWR | O_CREAT | O_TRUNC,0666);
if(-1==dst)
{
perror(argv[2]);
return -1;
}
//定义一个数组存放文件数据
char buff[1024*1024*4]={0};
//读取目标文件
n=read(src,buff,sizeof(buff));
//将图片高度宽度取出,从18字节开始
int* pw=(int*)&buff[18];
int* ph=(int*)&buff[18+4];
int w=*pw;//图片的宽
int h=*ph;//图片的高
int x=atoi(argv[3]);//开始的像素宽度
int y=atoi(argv[4]);//开始的像素高度
int mask_w=atoi(argv[5]);//马赛克区域宽度
int mask_h=atoi(argv[6]);//马赛克区域高度
int mask_len=atoi(argv[7]);
int num=0,cut=0;
COLOR temp[100],color;//保存三原色
int l=54;//BMP前54个字节为头部,所以指向54
l=l+3*(w*(h-y-mask_h)+x);//加入起始位置后我们的起始偏移量如图所示
int i,j;
for(i=0;i<mask_h;i++)
{
for(j=0;j<mask_w;j++)
{
if(j%mask_len==0)//将LEN*LEN个像素点变成一个颜色
{
if(i%mask_len==0)
{
color.B=buff[l];
color.G=buff[l+1];
color.R=buff[l+2];
temp[cut]=color;//保存前一行的像素值
cut++;
}
else
{
color=temp[num];//在高度为10的像素内使用一种颜色
num++;
}
}
buff[l]=color.B;
buff[l+1]=color.G;
buff[l+2]=color.R;
l=l+3;
}
l=l+3*(w-mask_w);//偏移到下一行
cut=0;
num=0;
}
write(dst,buff,n);///将打马赛克的BUFF写入文件
close(src);//关闭文件
close(dst);
return 0;
} 动态库和静态库
什么是库呢?我们可以把它看作是可执行文件的二进制形式。可以加载到内存进行,当你想要把你写的算法给别人使用但又不想别人知道源码,往往采用库的方式,而库又分为静态库和动态库,接下里我们分别介绍他们的用法和区别。
1.静态库
1.在编译阶段被链接
2.生成的可执行文件体积较大(链接了静态库)
3.可执行文件的移植方便(库已经链接好了)
编译静态库:
用法:ar [选项] 【libxx.a】【目标文件1.o】【目标文件2.o】.....
选项:c:创建一个库,不管以前是否存在。r:替换库中重名的,已经存在的模块。s:建立索引方式,可以快速查找库中模板。
例: ar crs libmy.a fun1.o fun2.o
编译时需要指明库的路径,使用 -L与 -l来完成
例: gcc test.c -L ./ -lmyfun -L ./day2/ -lmyfun2
-L:表示需要链接库,后续紧跟库的路径
-l:紧跟库的名字 不需要加lib 和后缀 .a
2.动态库
1.在运行阶段被链接。
2.生成的可执行文件体积较小。
3.可执行文件的移植不方便(运行时需要库,所以还需要移植库)。
编译动态库
用法: 1.先生成目标文件 gcc -c -fPIC fun.c(-fPIC:创建与地址无关的编译程序,表示当动态库里的模板被链接到程序中时,放在任意地址都可以)
2. gcc -shared -o libmyfun.so fun1.o fun2.o...
程序运行链接动态库方式:
1.将动态库移动到/usr/lib 或 /lib下(注意不要覆盖系统自带的库!!)
2.临时修改环境变量LD_LIBRARY_PATH=./ ./a.out 只在当前有效。
3.添加 /etc/ld.so.conf.d/xxx.conf文件,把库所在路径添加到xxx.conf文件末尾,并执行ldconfig刷新。这样操作,加入的目录下的所有库文件都可见。
补充知识点:
EOF : 是一个宏,C中宏定义 #define EOF -1;
为什么不直接返回-1,而是返回EOF呢?
既然返回的是一个字节,为什么返回值确用4字节的int表示,不用unsigned char这1个字节类型表示,或直接用char类型表示哪?
原因就是出在返回值要能表示-1.unsigned char表示无符号的,而这返回值,需要是-1才可以表示文件读到末尾了,那可以char类型表示-1,但是-1在char类型中表示的值为0xff,然而它本身就是一个字节的内容,如果文件中的一个字节是0xff,难道就认为文件结束,这是不合理的,用int作返回值,就不会出现这个问题,-1用int表示为0xffffffff;而字节值如果0xff这它返回的int值就会是0x000000ff,这样就可以区别开字节值为0xff和文件结束标识EOF.















 2159
2159











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









