






集合:作用:存储多个同一类型的数据
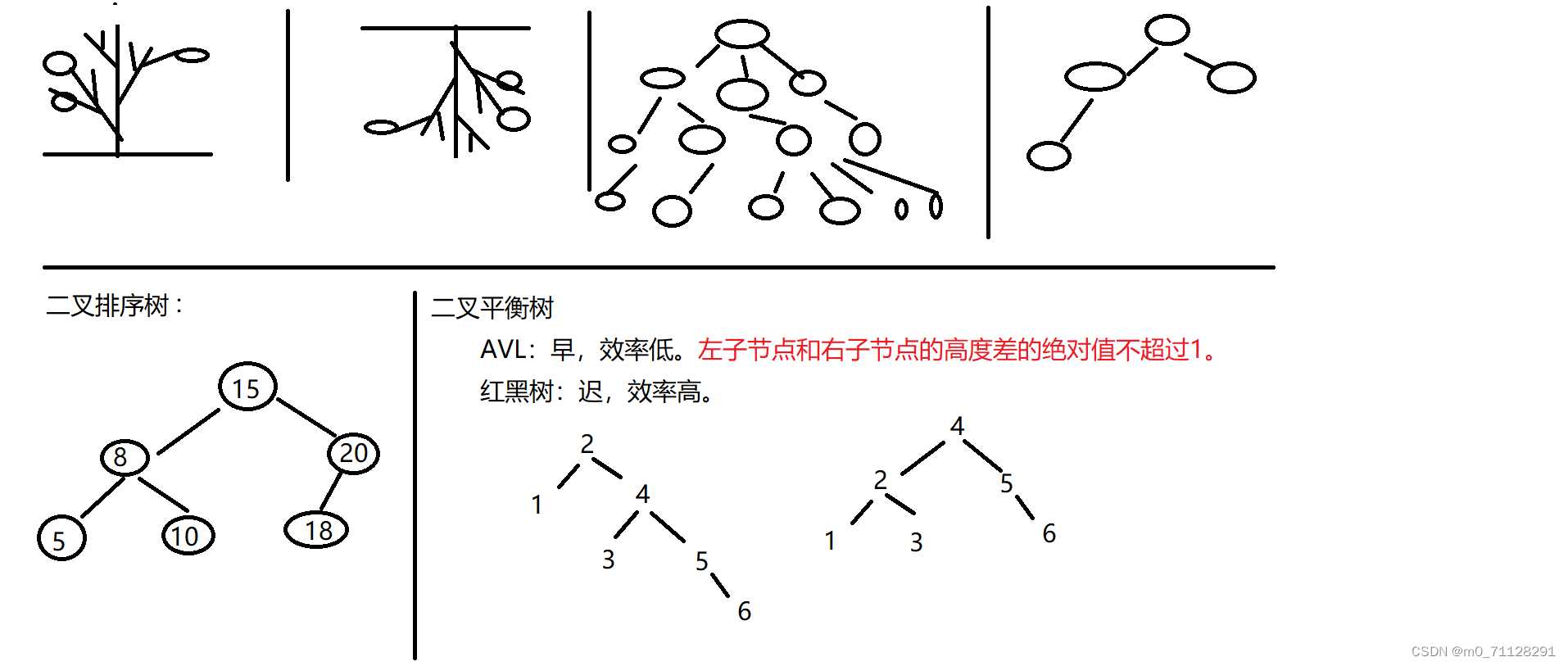
数据结构:数组的组织方式。
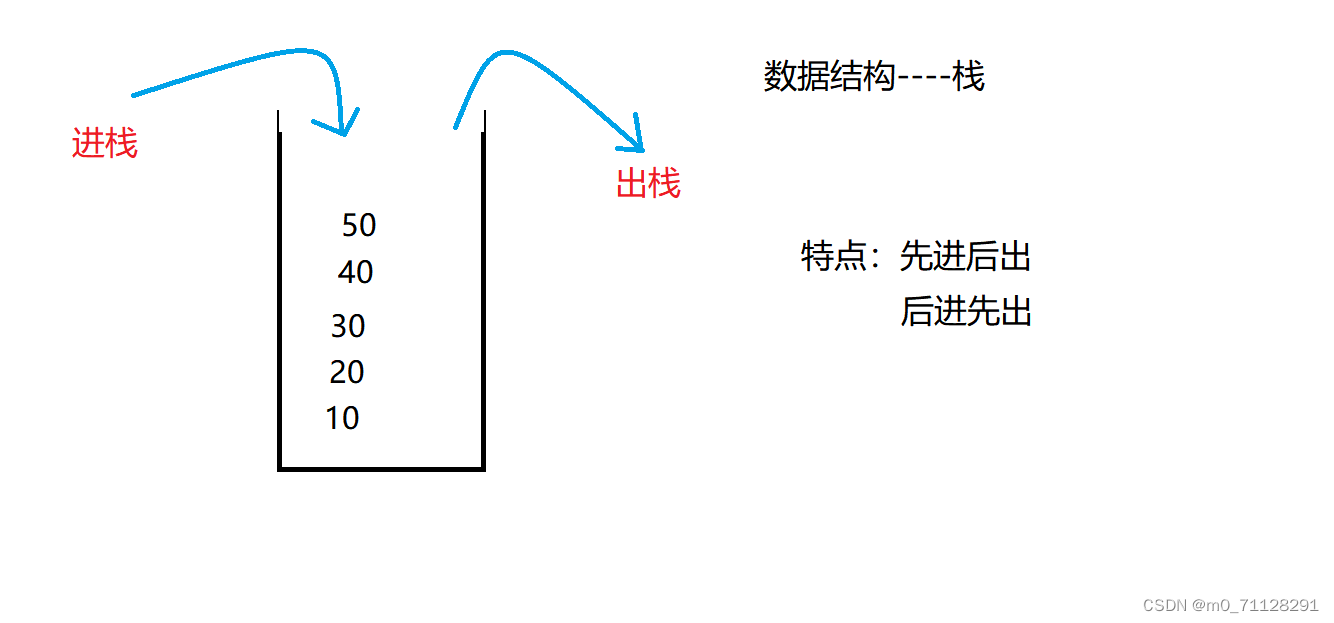
栈:先进先出
队列:先进后出
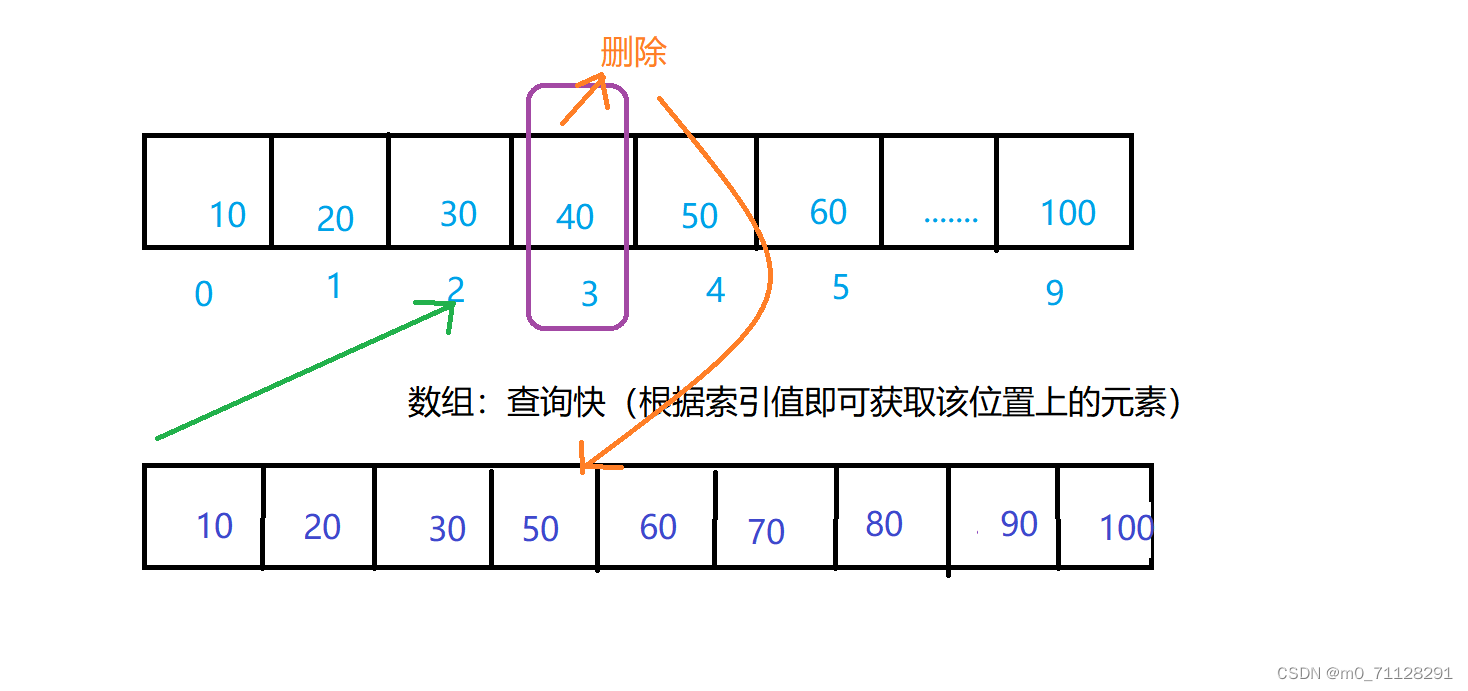
数组;查询快,增删慢(根据索引值获取元素快)。必须是一块连续的空间
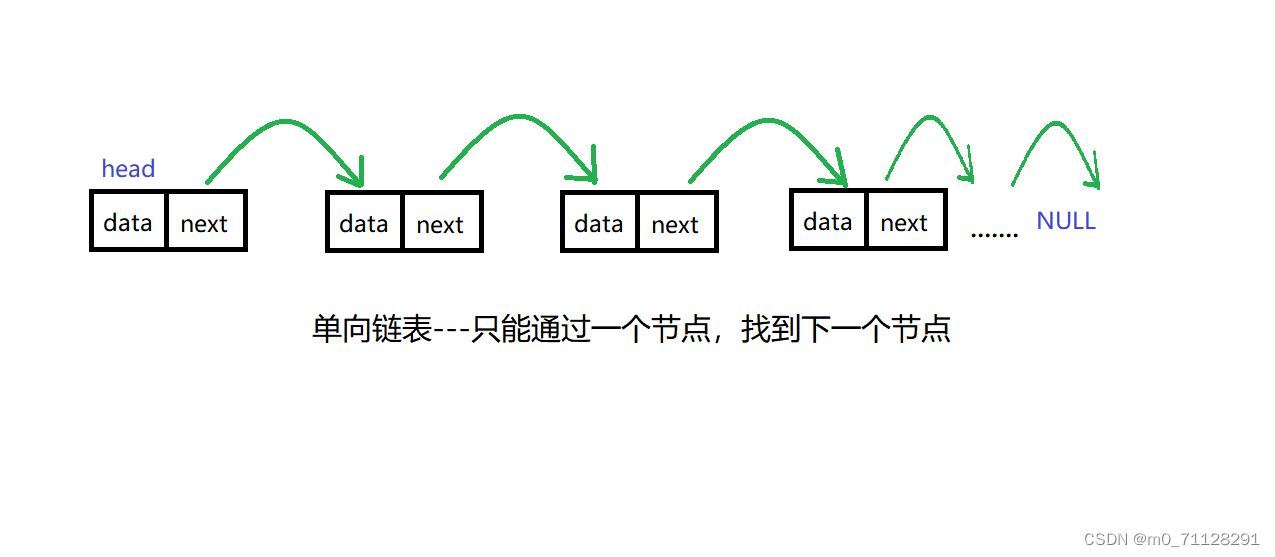
链表:查询慢,增删快
单向:只能通过一个节点找到下一个节点
双向:可以通过一个节点找到它的上一个或者下一个节点
红黑树:查询和增删都比快
栈
队列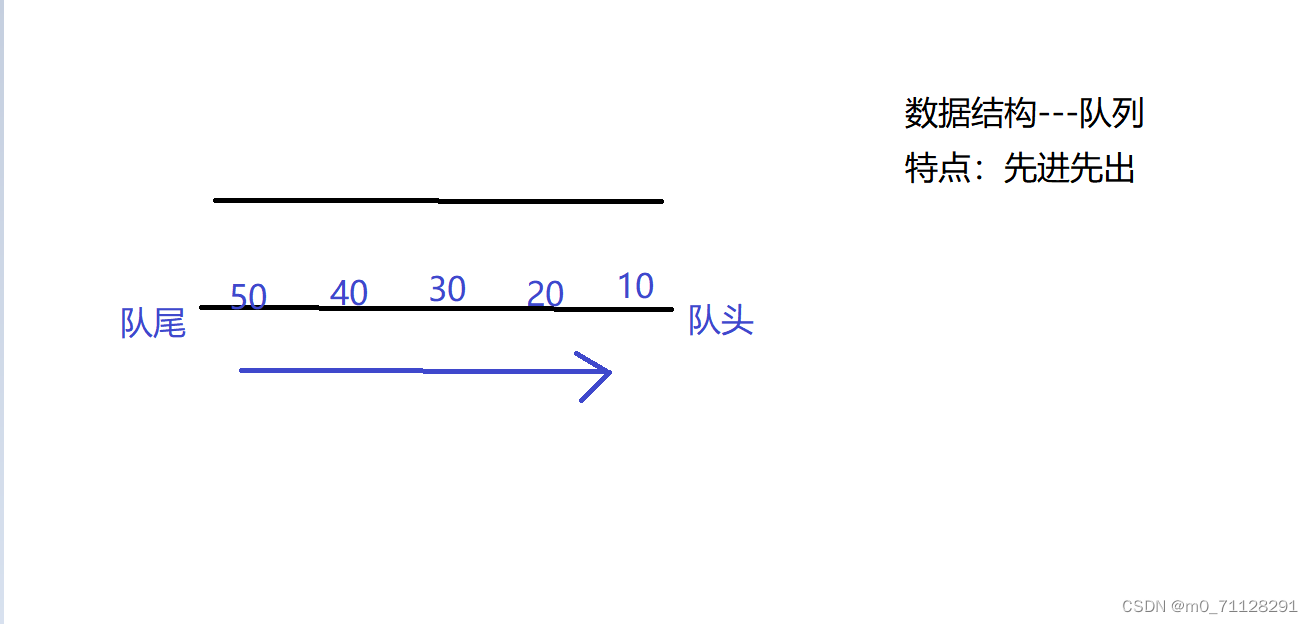
单向链表
双向链表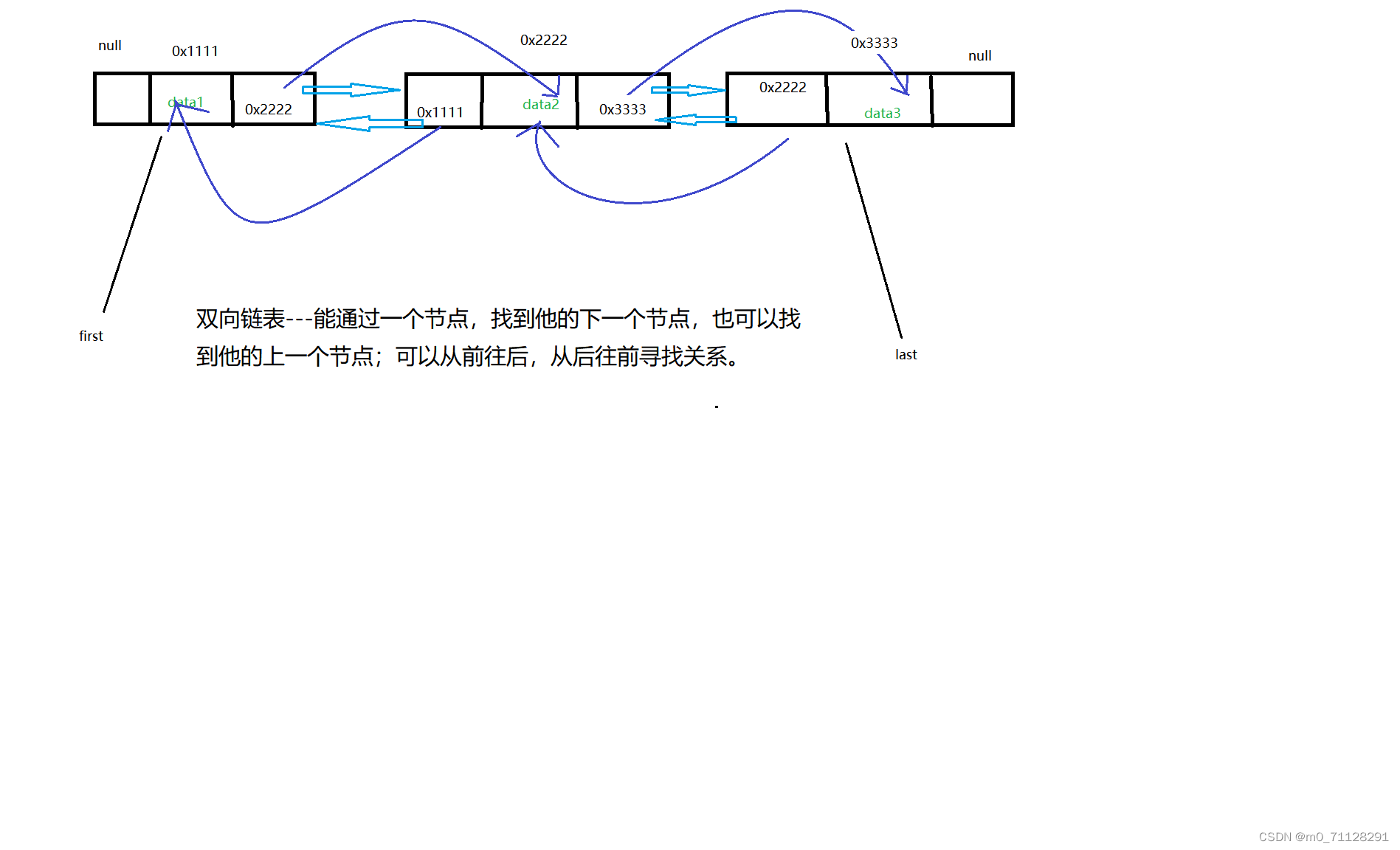
红黑树
数组
单列集合(collection总接口
List接口:特点:有索引值,有序,元素可重复
常用实现类:
ArrayList:底层数据结构是数组。
特点:查询快,增删慢,线程不安全,效率高。
LinkedList:底层数据结构是链表。
特点:查询慢,增删快。
Vector(不常用):底层是数组,和ArrayList比较线程安全,效率低。
Set接口:特点:没有索引值,元素不可重复。
常用实现类:
HashSet:底层数据结构是哈希表。
特点:无序,线程不安全,效率高。
、 LinkedHashSet:底层数据结构是链表+哈希表。
特点:有序。
TreeSet:底层数据结构是红黑树。
特点:可排序。
Collection<E>接口的主要用法:
boolean add(E e);//添加元素
boolean remove(Object obj);//删除元素
boolean contains(Object obj);//判断该集合是否包含该元素
boolean isEmpty();//判断集合是否为空,空:true,非空:false
void clear();//清空集合
int size();//求集合中元素的个数
Object[] toArray();//把集合转为数组
Iterator<E> iterator();//获取迭代器
Iterator<E>接口:
E next();//获取元素
boolean hasNext();//判断是否有下一个元素
ArrayList<String> array=new ArrayList<>();
//添加元素
array.add("张三");
array.add("李四");
array.add("王五");
array.add("赵六");
//删除元素
boolean b=array.remove("张三");
System.out.println(array);
System.out.println(b);//true
b=array.remove("张三");
System.out.println(b);//false
//获取元素的个数
int arr=array.size();
System.out.println(arr);
//判断集合中是否有该元素
b=array.contains("李四");
System.out.println(b);//turn
//把集合转化为数组
String str = array.toString();
System.out.println(str);
//判断集合中是否为空
boolean c = array.isEmpty();
System.out.println(c);//false
//清空集合
array.clear();
System.out.println(array);
System.out.println(array==null);//false
遍历集合的方式:获取迭代器和增强for
注意:通过迭代器遍历集合时,不能通过集合对象进行增删操作,迭代器有一个删除方法,
可以通过迭代器的删除方法进行删除。增强for的底层也是迭代器。
迭代器:
Collection<String> c=new ArrayList<>();
c.add("张三");
c.add("李四");
c.add("王五");
Iterator<String> iterator = c.iterator();
while(iterator.hasNext()) {
String str=iterator.next();
System.out.println(str);
if(str.equals("张三")) {
iterator.remove();
}
}
System.out.println(c);
增强for: 语法:for(数据类型 变量名:要遍历的集合名){ };
Collection<String> c = new ArrayList<>();
c.add("张三");
c.add("李四");
c.add("王五");
for(String str:c) {
System.out.println(str);
}
collection总接口:
List接口下和索引值有关的方法:
E get(int index);//获取索引值位置元素
E remove(int index);//根据索引值位置删除元素,返回被删除的元素
E set(int index,E e);//替换对应索引值位置的元素,返回被替换的元素
void add(int index,E e);//添加元素到对应索引值位置
int indexof(object obj);//获取元素首次出现的位置,没有的话返回-1
int lastindexof(object obj);//获取元素最后一次出现的位置
List<String> list=new ArrayList<>();
list.add("aa");
list.add("bb");
list.add("cc");
list.add("dd");
list.add("ee");
//添加元素到索引值为0
list.add(0, "111");
System.out.println(list);
//删除索引值为0的元素
String remove = list.remove(0);
System.out.println("被删除的元素是:"+remove);//111
//获取索引值为0的元素
String string = list.get(0);
System.out.println(string);//aa
//替换索引值为0的元素
String set = list.set(0, "中国");
System.out.println("被替换的元素是:"+set);//aa
System.out.println(list);
LinkedList独有的和首尾有关的方法:
void addFirst(E e);//把元素添加到头部
void addlast(E e);//把元素添加到尾部
E getFirst();//获取头部的元素
E getlast();//获取尾部的元素
E removeFirst();//删除头部的元素
E removelast();//删除尾部的元素
LinkedList<String> list=new LinkedList<>();
list.add("aa");
list.add("bb");
list.add("cc");
list.add("dd");
list.add("ee");
//添加元素到头部和尾部
list.addFirst("aaa");
list.addLast("eee");
System.out.println(list);
//删除头部和尾部的元素
String first = list.removeFirst();
String removeLast = list.removeLast();
System.out.println(first);
System.out.println(removeLast);
//获取头部和尾部的元素
String first2 = list.getFirst();
String last = list.getLast();
System.out.println(first2);//aa
System.out.println(last);//ee
Set接口:set没有在collection的基础上扩展功能,方法就是Collection<E>接口中的功能。
双列集合(Map总接口)
特点:1.一个元素是由一个key和一个value部分组成
2.k,v可u哦是任意引用数据类型
3.k不能重复(重复的判断和Set一样:覆盖重写hashcode和equalse方法),通过v排序
常用实现类:
HashMap:底层是哈希表
特点:无序,线程不安全,效率高,k,v可以是null
LinkedHashMap:底层是链表+哈希表
特点:有序
TreeMap:底层是红黑树
特点:可排序
Hashtable:不常用,线程安全,效率低(k,v,不能是null),功能和HashMap相似
常用方法:
V put(K k,V v);//添加元素,如果K存在返回被替换的V,K不存在,返回null
V remove();//根据kk删除整个键值对,若不存在则返回null
V get(Object key);//根据K获取V,若不存在返回null
boolean inEmpty();//判断集合是否为空,空true,非空false
void clear();//清空集合
boolean containsKey(Object key);//判断集合中是否包含Key
boolean containsValue(Object value);//判断集合中是否包含value
Set<K> KeySet();//获取所用的Key
Set<Entry<K,V>> entrySet();//获取所用的Entry
collection<V> values();//获取所有的value
int size();//获取集合中元素的个数
Entry<K,V>接口:
K getKey();
V getValue();
Map<String,Double> map=new HashMap<>();
//新增
map.put("张三", 78.0);
System.out.println(v);//null
v=map.put("张三丰", 88.0);
System.out.println(v);//null
System.out.println(map);
//删除整个元素,返回V
Double remove = map.remove("张三");
System.out.println(remove);//78.0
remove = map.remove("李四");
System.out.println(remove);//null
//获取
v=map.get("张三丰");
System.out.println(v);//88.0
v= map.get("李四");
System.out.println(remove);//null
//判断k是否存在
boolean b = map.containsKey("张三");
System.out.println(b);//false
//判断V是否存在
boolean c = map.containsValue(34.9);
System.out.println(c);//false
//判断集合是否为空
boolean d = map.isEmpty();
System.out.println(d);//false
//清空集合
map.clear();
d = map.isEmpty();
System.out.println(d);//true
System.out.println(map==null);//false
遍历集合的方式:
1.获取所有的K,根据K获取V
Map<String,Double> map=new HashMap<>();
map.put("张三", 70.0);
map.put("张三丰", 80.0);
map.put("张三疯了", 90.0);
//获取所有的k
Set<String> set = map.keySet();
System.out.println(set);
for(String str:set) {
//根据K获取V
Double d=map.get(str);
System.out.println(str+"---"+d);
}
2.获取所有的Entry,获取迭代器,获取K和V。
Map<String,Double> map = new HashMap<>();
map.put("张三", 90.0);
map.put("张三丰", 99.0);
map.put("张三疯了", 90.0);
//获取所有Entry
Set<Entry<String,Double>> set = map.entrySet();
Iterator<Entry<String, Double>> iterator = set.iterator();
while(iterator.hasNext()) {
Entry<String, Double> entry = iterator.next();
String key = entry.getKey();
Double value = entry.getValue();
System.out.println(key+"--"+value);
}















 1787
1787











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









