






自然语言处理(Natural Language Processing,NLP)研究的是如何通过机器学习等技术让计算机学会处理人类语言,乃至实现终极目标——理解人类语言或人工智能
自然语言与编程语言
词汇量
自然语言中的词汇量比编程语言中的关键词丰富
结构化
自然语言是非结构化的,而编程语言是结构化的。所谓结构化,指的是信息具有明确的结构关系
歧义性
自然语言含有大量歧义,但在编程语言中,则不存在歧义性
容错性
自然语言哪怕错得再离谱,人们还是可以猜出它大概的意思。而在编程语言中,必须保证拼写绝对正确、语法绝对规范
易变性
编程语言的变化要缓慢温和得多,而自然语言则相对迅速嘈杂一些
简略性
自然语言往往简洁、干练。
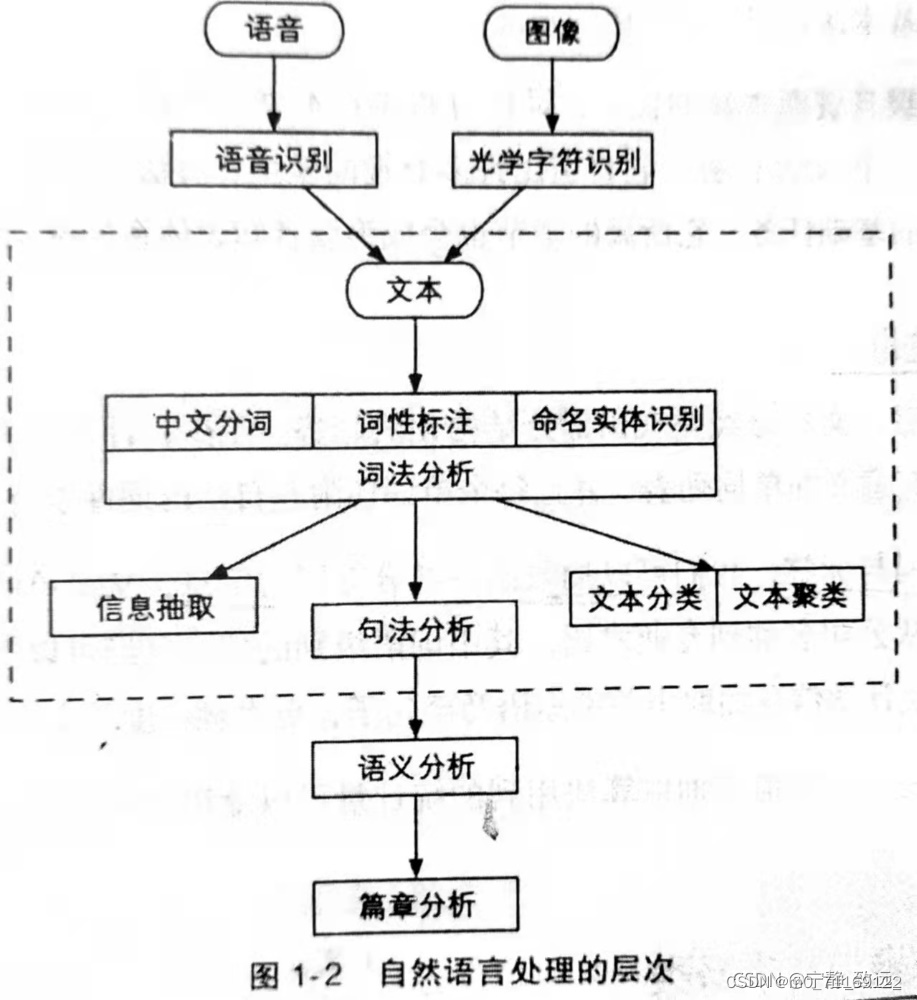
自然语言处理的层次
语音、图像和文本
自然语言处理的输入源一共有3个,即语音、图像和文本
中文分词、词性标注和命名实体识别
统称词法分析
中文分词:将文本分隔为有意义的词语
词性标注:确定每个词语的类别和浅层的歧义消除
命名实体识别:识别出一些较长的专有名词
信息抽取
词法分析之后,根据这些单词和标签,抽取出一部分有用的信息
文本分类和文本聚类
在词法分析之后进行
文本分类:把许多文档分门别类地整理一下
文本聚类:把相似地文本归档到一起,或者排除重复的文档,而不关心具体类别
句法分析
词性分析之后,再获取句子的主谓宾结构等\n语义分析和篇章分析
句法分析之后,进行词义消歧、语义角色标注和语义依存分析
其他高级任务
综合性任务
自然语言处理的流派
基于规则的专家系统
规则,指的是由专家手工制定的确定性流程。规则系统比较成功的案例:波特词干算法(Porter stemming algorithm)
规则系统显得僵硬、死板和不稳定
基于统计的学习方法
统计:在语料库上进行的统计
语料库:人工标注的结构化文本
以举例子的方式让机器自动学习这些规律。然后机器将这些规律应用到新的、未知的例子上去
历史
基础研究→规则系统→统计方法→深度学习
规则和统计
语言学知识的作用有两方面:
帮助我们设计更简洁、高效的特征模板
在语料库建设中发挥作用
实际运行的系统在预处理和后处理的部分依然会用到一些手写规则
传统方法与深度学习
深度学习在自然语言处理领域中的基础任务上发力并不大。另一方面,深度学习涉及大量矩阵运算,需要特殊计算硬件的加速,因此性价比不高
机器学习
什么是机器学习
机器学习就是让机器学会算法的算法。称被学习的算法为模型
模型
模型是对现实问题的数学抽象,由一个假设函数以及一系列参数构成
特征:事物的特点转化的数值
特征模板:自动提取特征的模板
特征工程:挑选特征和设计特征模板
数据集
样本:例子
数据集:例子组成的习题集,在自然语言处理领域称为语料库
监督学习
附带标准答案,让机器先做一遍题,然后与标准答案作比较,最后根据误差纠正模型的错误。每一遍学习称作一次迭代。迭代学习的过程称为训练。机器得出结论的过程称为预测
无监督学习
只给机器学习,却不告诉其参考答案。其中不含标准答案的习题集被称为无标注(unlabeled)的数据集。无监督学习一般用于聚类和降维
降维:将样本点从高维空间变换到低维空间的过程。如果样本具有n个特征,则样本对应着n+1维空间中的一个点,多出来的维度是给假设函数的因变量用的。如果我们想要让这些样本点可视化,则必须将其降维到二维或者三维。\n\n有一些降维算法的中心思想是,降维后尽量不损失信息,或者说让样本在低维空间中每个维度上的方差都尽量大(其实就是考虑剔除无用或者影响不大的特征)
其他类型的机器学习算法、半监督学习:如果我们训练多个模型,然后对同一个实例执行预测,会得到多个结果。如果这些结果多数一致,则可以将该实例和结果放到一起作为新的训练样本,用来扩充训练集
强化学习:一边预测,一边根据环境的反馈规划下次决策
















 5645
5645











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











